Ubuntu22.04使用kubeadm安装k8s 1.26版本高可用集群
Posted 上海一亩地
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ubuntu22.04使用kubeadm安装k8s 1.26版本高可用集群相关的知识,希望对你有一定的参考价值。
目录
阿里云ACK集群的架构

ACK集群升级的时候有预检步骤,可以看出他们就是使用的kubeadm部署的高可用集群,集群的证书有效期为一年,所以如果中间不执行升级操作,则一年到期后集群不可用。
ACK的亮点就在于,相比自由化部署,ACK为k8s master集群创建了一个小型SLB实例,Backend服务器指向master的6443端口。这样的好处是即使master瘫痪,网络也是正常的,易于排查。
ACK实例的创建过程如下
创建vpc和交换机。阿里云的vswitch交换机最多支持子网掩码16,既一台虚拟交换机最多能承受65535个ip的流量。
创建k8s集群,创建过程中需要规定vswitch,两个负载均衡器(一个用于访问集群,一个用于ingress),Service的二级域名,容器运行时,集群是否需要公网ip,工作负载的子网网段等信息。
创建过程需要20分钟,创建好后即可开箱使用。
安装前的准备
kubeadm部署高可用集群官方文档:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
主机规划
| 主机名 | IP地址 | 用途 | 算力规划 |
|---|---|---|---|
| k8s-haproxy01 | 192.168.1.11 | k8s集群小负载均衡器 | 1C2GB |
| k8s-haproxy02 | 192.168.1.12 | k8s集群小负载均衡器 | 1C2GB |
| master01 | 192.168.1.13 | k8s master主节点 | 2C4GB |
| master02 | 192.168.1.14 | k8s master主节点 | 2C4GB |
| master03 | 192.168.1.15 | k8s master主节点 | 2C4GB |
| loadbalance01 | 192.168.1.16 | 应用服务大负载均衡器 | 2C4GB |
| loadbalance02 | 192.168.1.17 | 应用服务大负载均衡器 | 2C4GB |
| loadbalance03 | 192.168.1.18 | 应用服务大负载均衡器 | 2C4GB |
| loadbalance04 | 192.168.1.19 | 应用服务大负载均衡器 | 2C4GB |
| worker01 | 192.168.1.20 | k8s工作负载节点 | 8C32GB |
| worker02 | 192.168.1.21 | k8s工作负载节点 | 8C32GB |
| 无 | 192.168.1.10 | VIP(小负载均衡的入口IP) | 无 |
基线准备
所有Linux必须满足防火墙、ipvs、流量转发或其他安全要求才能用于k8s部署,这一类型的准备工作叫做l基线准备。
所有机器都要完成如下配置,配置完成后最好打个系统快照。
# root密码一致
sudo passwd root
# 配置静态ip,如果你的机器是cloud init出来的就不用改了
vi /etc/netplan/00-network-manager.yaml
# 修改完后,重启网络
netplan apply
# 安装vim和ssh
apt update
apt -y install vim openssh-server openssh-client git
# 允许ssh通过密码访问root
vim /etc/ssh/sshd_config
# 修改两行
PermitRootLogin yes
PasswordAuthentication yes
# 修改后重启ssh
systemctl restart ssh
systemctl enable ssh
# 同步时间
timedatectl set-timezone Asia/Shanghai
# 如果你的机器无法访问公网,则上面的命令无法使用,需要在内网中部署chronyd时间服务器。
# 关闭防火墙
ufw disable
# 关闭swap
swapoff -a
vim /etc/fstab
去掉带swap的一行
#-----------------------以下配置为k8s容器运行时对linux系统内核的要求,必须做!
# 本机网桥流量导入iptables表中过滤
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
EOF
# 配置生效
sysctl --system
# 开启 IPVS
# 顺带启动 br_netfilter 和 overlay,这两个是官方文档要求的。
# k8s的service有两种代理模式,一种是iptables,另一种是IPVS,IPVS的性能更强。
apt -y install ipset ipvsadm
cat > /etc/modules-load.d/k8s.conf << EOF
ip_vs
ip_vs_lc
ip_vs_lblc
ip_vs_lblcr
ip_vs_rr
ip_vs_wrr
ip_vs_sh
ip_vs_dh
ip_vs_fo
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
ip_tables
ip_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
xt_set
br_netfilter
nf_conntrack
overlay
EOF
# 重启让内核配置生效
reboot
# hosts文件不用配置,不用vim /etc/hosts/
# 以后添加机器难道还要修改hosts不成?网上的各种教程都让你配hosts,用脚指头想想OK?
# 你可以部署一个内网的DNS服务器,实现FQDN服务。
如下是官方文档截图,证明我不是在瞎配。

所有k8s master、worker节点安装kubeadm+kubectl+kubelet
- 官方文档要求所有k8s相关节点的hostname、MAC地址和网卡product_uuid都不相同,每台节点具备唯一的MAC和uuid。
查看主机名
hostname
查看MAC:
ip link
查看uuid
cat /sys/class/dmi/id/product_uuid
- 确保所有master节点的6443端口没有被占用
nc 127.0.0.1 6443
# 命令没有任何返回,表示6443端口没有被占用。
- 二进制包安装containerd
从kubernetes 1.24开始,kubelet不在支持docker,所以我们需要安装containerd作为容器运行时。cri-cni包里有全部containerd集成到k8s的组件。

# 下载二进制包
wget https://github.com/containerd/containerd/releases/download/v1.6.14/cri-containerd-cni-1.6.14-linux-amd64.tar.gz
# 解压
tar -zxf cri-containerd-cni-1.6.14-linux-amd64.tar.gz
# 解压出3个目录:etc、opt、usr
# 安装
cp usr/local/bin/* /usr/local/bin/
cp etc/systemd/system/containerd.service /usr/lib/systemd/system/
# 生成配置文件
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml
# 修改配置文件
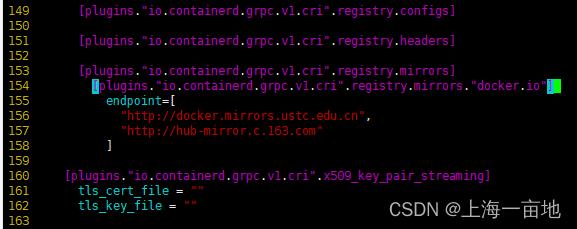
vim /etc/containerd/config.toml
-------------------------------------------
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6" # 61行
[plugins."io.containerd.grpc.v1.cri".registry.mirrors] # 153行
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"] # 缩进2个空格,在153行下新增
endpoint=[
"http://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com"
]
# 重启containerd
systemctl daemon-reload
systemctl restart containerd.service
systemctl enable containerd.service
# 查看ctr和containerd的版本
ctr version
-----------------------------
ctr github.com/containerd/containerd v1.6.14
root@master01:~# ctr version
Client:
Version: v1.6.14
Revision: 9ba4b250366a5ddde94bb7c9d1def331423aa323
Go version: go1.18.9
Server:
Version: v1.6.14
Revision: 9ba4b250366a5ddde94bb7c9d1def331423aa323
UUID: 7dffa579-f530-4f67-a0c6-57135c477ed4
相关截图


- 单独安装runc和安全计算模式库libseccomp

wget https://github.com/opencontainers/runc/releases/download/v1.1.4/runc.amd64
cp runc.amd64 /usr/local/bin/runc
chmod +x /usr/local/bin/runc
runc -v
# 安装libseccomp
apt -y install libseccomp-dev
- 安装CNI网络组件
CRI是k8s调度容器运行时的统一接口,默认已经集成到containerd1.15版本及以上中。而CNI就是CRI与Containerd之间的网络连接器。
由于在config.toml中默认的CNI安装路径是/opt/cni/bin/,所以我们就安装在这里。
wget https://github.com/containernetworking/plugins/releases/download/v1.1.1/cni-plugins-linux-amd64-v1.1.1.tgz
mkdir -p /opt/cni/bin/
tar -zxf cni-plugins-linux-amd64-v1.1.1.tgz -C /opt/cni/bin/
- 一切准备就绪,可以安装kubeadm、kubectl、kubelet了。
官方apt镜像如下

但是很可惜,镜像地址是google.com,中国大陆有墙访问不了,所以需要使用国内阿里云镜像。虽然ubuntu22.04代号是jammy但是目前kubernetes的apt库最高是xenial,只能用它了。
# 创建apt库
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl
sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg http://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list
# 安装
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
# 锁定版本,防止这些包被升级
sudo apt-mark hold kubelet kubeadm kubectl
创建集群负载均衡器HAproxy
Kubernetes官方文档中关于kubeadm创建高可用的教程中写道:首先创建一个负载均衡器,后端服务器端口6443.

安装keepalived 和haproxy
在两台haproxy主机上执行命令,安装keepalived和haproxy
apt -y install haproxy keepalived
配置haproxy
haproxy的功能是负载均衡器,通过访问haproxy的ip和暴露端口就能随机访问一个kube-apiserver,实现负载均衡。将frontend的流量随机的导入backend的负载均衡。
两台haproxy主机进行如下配置,两台主机配置相同。
vim /etc/haproxy/haproxy.cfg
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
# Default SSL material locations
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
# See: https://ssl-config.mozilla.org/#server=haproxy&server-version=2.0.3&config=intermediate
ssl-default-bind-ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384
ssl-default-bind-ciphersuites TLS_AES_128_GCM_SHA256:TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256
ssl-default-bind-options ssl-min-ver TLSv1.2 no-tls-tickets
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
frontend kube-apiserver
mode tcp
bind *:6443
option tcplog
default_backend kube-apiserver
listen stats
mode http
bind *:8888
stats auth admin:password
stats refresh 5s
stats realm HAproxy\\ Statistics
stats uri /stats
log 127.0.0.1 local3 err
backend kube-apiserver
mode tcp
balance roundrobin
server master01 192.168.1.13:6443 check
server master02 192.168.1.14:6443 check
server master03 192.168.1.15:6443 check
haproxy的配置文件中,global和defaults的是默认就有的,不用修改。所以在文件末尾添加frontend、listen stats、backend就行了。
frontend:入口,本机对外暴露的端口和允许ip。*表示任何ip都允许访问。有的k8s安装教程中将haproxy和kube-apiserver安装在同一台linux中,apiserver已经将6443端口给占用了,则frontend中bind得换一个端口,可以写 *:9443。本文的haproxy部署在独立的linux中,所以直接暴露6443就好了。
阿里云也是这么干的,对外暴露6443端口。如果你手头不是很宽裕,那就将haproxy和apiserver部署在一起吧。

backend:反向代理,连接后端服务的负载均衡。server的IP地址就是3台master节点的IP。
listen stats 监控面板的端口、用户名、密码。
配置完成后重启haproxy。
systemctl restart haproxy
浏览器登录http://<haproxy主机的ip>:8888/stats即可登录状态面板查看haproxy的状态,用户名和密码参见配置文件中 stats auth那一行。
目前尚未部署kube-apiserver,所以没有backend存活。

配置keepalived
haproxy的功能类似nginx,其实就是一个反向代理和负载均衡的功能。我们为了实现高可用,往往部署了多个haproxy,但是haproxy主机的ip各不相同,我们需要用一个虚拟ip作为访问入口,将haproxy合并起来,这就需要keepalived。
keepalived的功能就是存活检查,将VIP绑定到一个存活的haproxy上,如果当前haproxy瘫痪,自动将VIP绑定到其他haproxy上。keepalived的功能类似于网卡聚合里面的mode1 active-backup,资源利用率比较低。多个haproxy存活时也只能同时使用1个haproxy,所以是小负载均衡。
如果配置ingress的大型负载均衡,则使用nginx+LVS+keepalived模式,让多个nginx同时参与工作。
在配置keepalived前,先查看本机的主网卡设备名

我的是eth0,这个网卡名称将会写入keepalived配置文件中的,所以一定要查看。如果你是用docker容器部署keepalived,则默认网卡名称是ens33。
编写keepalived配置文件如下
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs
router_id LVS_1
script_user root
enable_script_security
vrrp_script checkhaproxy
script "/etc/keepalived/check-haproxy.sh"
interval 2
weight -5
fall 2
rise 1
vrrp_instance VI_1
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
virtual_ipaddress
192.168.1.10
authentication
auth_type PASS
auth_pass password
track_script
checkhaproxy
配置讲解:state MASTER只能有一台,其他haproxy主机一律配置成BACKUP。所以本案例中haproxy01配置成MASTER,haproxy02配置成BACKUP。interface是VIP桥接的网卡设备名称,这要与linux主网卡名保持一致。virtual_ipaddress就是VIP地址。
配置文件中有一个状态检查的shell脚本/etc/keepalived/check-haproxy.sh,需要在启动keepalived之前创建好。
vim /etc/keepalived/check-haproxy.sh
#!/bin/bash
# grep 6443这里,如果你的haproxy中的frontend中配置的是其他端口,则需要修改成对应端口
# count变量的值就是6443端口的frontend个数,如果大于0就正常退出(exit 0),否则异常退出。
count=`netstat -apn|grep 6443|wc -l`
if [ $count -gt 0 ]
then
exit 0
else
exit 1
fi
为shell脚本添加执行权限
chmod +x /etc/keepalived/check-haproxy.sh
重启keepalived,reboot linux,并测试VIP是否能通:
systemctl restart keepalived
systemctl enable keepalived
# 配置完linux后,最好重启以下服务器
reboot
# 启动好后,ping一下VIP。
ping 192.168.1.10
PING 192.168.1.10 (192.168.1.10) 56(84) bytes of data.
64 bytes from 192.168.1.10: icmp_seq=1 ttl=64 time=0.034 ms
64 bytes from 192.168.1.10: icmp_seq=2 ttl=64 time=0.028 ms
64 bytes from 192.168.1.10: icmp_seq=3 ttl=64 time=0.027 ms
^C
--- 192.168.1.10 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2055ms
rtt min/avg/max/mdev = 0.027/0.029/0.034/0.003 ms
# 测试 VIP到 haproxy 6443端口的连通性
nc -v 192.168.1.10 6443
Connection to 192.168.1.10 6443 port [tcp/*] succeeded!
如果ping不通,说明配置有问题,查看报错
systemctl status keepalived
到此,HAproxy小负载均衡器就实现了,以后通过VIP:6443访问K8S集群。
kubeadm部署第一台master节点
kubeadm init如果填写的是某台主机的ip地址,则创建的是单机版的k8s。如果填写的是负载均衡器的IP地址,则创建的是高可用集群。主要区别在于创建的CA证书不同。单机版的CA证书不支持高可用集群。
先尝试下载k8s的所有容器镜像,这样稍后init速度会很快。kubeadm默认从google镜像仓库下载容器镜像,又会被墙,所以指定从阿里云下载容器镜像。
每台master和worker节点执行下面这个命令:
kubeadm config images pull \\
--image-repository registry.aliyuncs.com/google_containers \\
--cri-socket=unix:///var/run/containerd/containerd.sock
# docker的cri接口地址是unix:///var/run/cri-dockerd.sock
在master01上执行如下命令,创建第一台control plane。由于从kubernetes 1.24开始,kubelet不在支持docker,所以我们选择containerd作为容器运行时。kubelet的这次升级将直接连接containerd,移除了shim和dockerd相关代码,没有中间商赚差价。

先在master01上执行如下命令,创建k8s集群版,然后其他master服务器加入这个集群
# 命令格式 kubeadm init --control-plane-endpoint "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT" --upload-certs
kubeadm init \\
--control-plane-endpoint "192.168.1.10:6443" \\
--image-repository registry.aliyuncs.com/google_containers \\
--upload-certs --cri-socket=unix:///var/run/containerd/containerd.sock
创建不要1分钟,且成功:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.1.10:6443 --token 5utynu.c7fim1jqkawqg7pk \\
--discovery-token-ca-cert-hash sha256:9a5569b481e0574ef45620449c5b69f8632183274a4e59b7ef246a64db151fcf \\
--control-plane --certificate-key a99e6c08b1a18f2f636d8e7d0a793ecda35b74ff5b3ab91e63a3f9221749853e
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.10:6443 --token 5utynu.c7fim1jqkawqg7pk \\
--discovery-token-ca-cert-hash sha256:9a5569b481e0574ef45620449c5b69f8632183274a4e59b7ef246a64db151fcf
其中master节点加入集群的命令
kubeadm join 192.168.1.10:6443 --token 5utynu.c7fim1jqkawqg7pk --discovery-token-ca-cert-hash sha256:9a5569b481e0574ef45620449c5b69f8632183274a4e59b7ef246a64db151fcf --control-plane --certificate-key a99e6c08b1a18f2f636d8e7d0a793ecda35b74ff5b3ab91e63a3f9221749853e
worker节点加入集群的命令
kubeadm join 192.168.1.10:6443 --token 5utynu.c7fim1jqkawqg7pk -discovery-token-ca-cert-hash sha256:9a5569b481e0574ef45620449c5b69f8632183274a4e59b7ef246a64db151fcf
Calico网络组件一键安装
此时通过 kubectl get nodes 能发现,所有的worker都是not ready状态,原因是网络组件没有安装,集群没有Service功能。
通过calico的官方yaml文件能一次安装所有calico组件,包括daemon set、deployment、service 、rbac认证等等,难度高,但是都是全自动化的。
kubectl apply -f "https://docs.projectcalico.org/manifests/calico.yaml"
安装完成
此时集群全部完成,可以正常使用,如果担心证书,可以研究一下kubeadm更新集群CA证书的方法。你也可以安装一个Dashboard。
以上是关于Ubuntu22.04使用kubeadm安装k8s 1.26版本高可用集群的主要内容,如果未能解决你的问题,请参考以下文章