在STM32F4平台上实现算法仿真和集成
Posted NiceBT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在STM32F4平台上实现算法仿真和集成相关的知识,希望对你有一定的参考价值。
1. 引言
在设计消费类音频产品的系统框架时,一般的思路是选用MCU+DSP双芯片分别满足驱动外设+数字音频处理的需求。以双通道立体声音箱为例,一颗主频在100MHz左右的MCU搭配一颗ADI的入门级音频处理DSP,即可基本满足需求。此类方案灵活性高,但硬件BOM成本较高,且算法开发工作的通用性不高。
随着嵌入式平台主芯片性能的不断提高,用一颗MCU同时满足驱动外设和数字音频处理的构想已经成为了现实,这里起到关键作用的即是FPU(浮点运算单元)。有代表性的MCU是ST公司出品的STM32F4系列。
The ARM® Cortex®-M4-based STM32F4 MCU series leverages ST’s NVM technology and ART Accelerator™ to reach the industry’s highest benchmark scores for Cortex-M-based microcontrollers with up to 225 DMIPS/608 CoreMark executing from Flash memory at up to 180 MHz operating frequency.
With dynamic power scaling, the current consumption running from Flash ranges from 89 µA/MHz on the STM32F410 up to 260 µA/MHz on the STM32F439.
The STM32F4 series consists of eight compatible product lines of digital signal controllers (DSC), a perfect symbiosis of the real-time control capabilities of an MCU and the signal processing performance of a digital signal processor (DSP):
STM32F4系列的芯片架构如下:
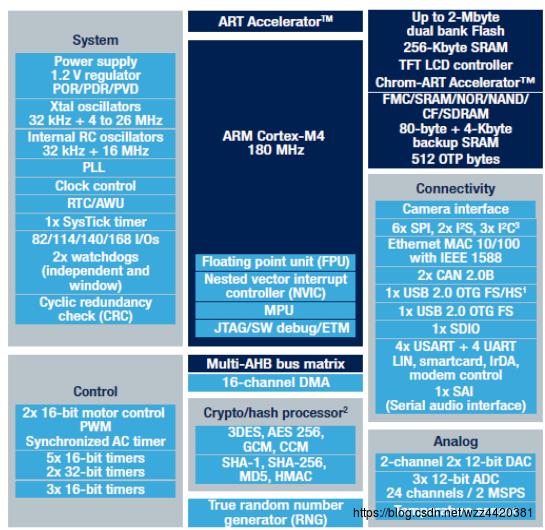
有了FPU的加持,STM32F4在执行浮点运算时的效率有了数倍的提升。使其能够高效地执行数字音频处理算法,让我们有机会打造一个具备成本优势的数字音频系统解决方案。
更加重要的是,STM32F4平台上可以运行基于通用C代码编写的算法,平台的兼容性很强,集成的难度不高。
2. 搭建算法仿真环境
2.1. 准备硬件环境
- STM32F4-Discovery开发板一块(淘宝链接:https://detail.tmall.com/item.htm?spm=a230r.1.14.6.6c7b48a3zvbckO&id=13633447391&ad_id=&am_id=&cm_id=140105335569ed55e27b&pm_id=&abbucket=5)
- win7 系统笔记本一台
2.2. 准备软件环境
- 注册ST官网账号(https://my.st.com/cas/login?service=https://my.st.com/content/my_st_com/en.html)
- 安装matlab 2016b
- 安装STM32_MAT_TARGET_V4.4.1(https://www.stmcu.com.cn/Designresource/design_resource_detail/file/257356/lang/EN/token/aed5f1eb46fe801f5bb9cf583c850341)。安装完成后,找到MATLAB\\STM32\\路径下的《STM32_MAT-TARGET_HandsOn》,按步骤操作。
安装过程中踩过的几个坑:
- 有可能需要安装“jdk-10.0.1_windows-x64_bin.exe”
- 有可能需要安装jre,下载后解压到“JRE\\jdk-10.0.1”
- 有可能不能识别开发板的串口,需重启电脑进入“禁用数字签名认证模式”
- matlab simulink工程运行时需选定串口,如果是Discovery板,需将PA2设为TX,将PA3设为RX
2.3. 系统框架
仿真系统的框架如下:
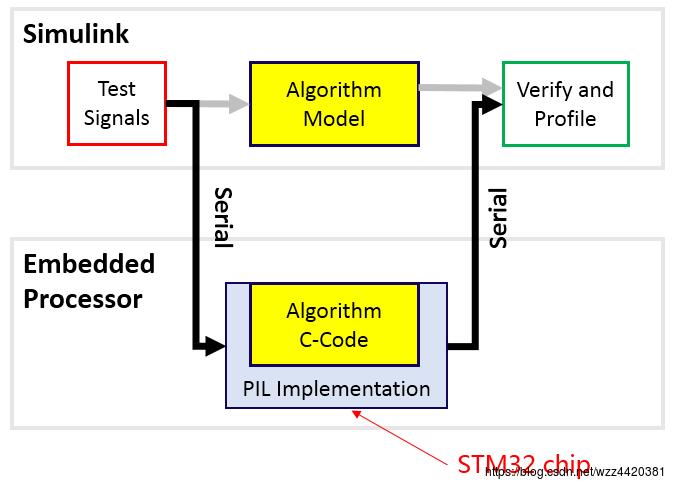
simulink将标准输入文件通过串口给到STM32F4,在其计算完成后再通过串口将数据返回。STM32返回的数据与simulink中运行的algorithm model的输出进行bit-by-bit的对比,如果结果满足预期,即代表算法在目标平台的运行结果是可接受的。这里的algorithm model可以是simulink提供的通用模块,也可以是由C代码封装了mex接口后经simulink调用。
2.4. 仿真profile
仿真阶段有两个重要的目标,一个是对标simulink的PC平台与STM32平台的计算结果,另一个是得到算法在目标平台的资源消耗情况。其中比较重要的指标是算法执行效率,即一次运算消耗的时钟周期数。
我们来简单看一下ST官方给出的例程是如何精确测试算法的执行效率的。算法仿真结束后,在matlab命令行输入executionProfile.report,可查询到如下信息:

其中最重要的信息是单次函数执行时间。这个时间是如何得到的呢,原理是在STM32 MCU内部,每次执行算法模块前会先打开以ns为单位的定时器,在算法执行完毕后关闭,将定时器的值与计算结果一并通过串口发送给matlab。
2.5. 仿真评估基线
在评估我们自己的算法的执行效率前,需要有一个公认的参照物,以明确我们算法在平台上运行的性能的优劣。
CMSIS DSP算法库是ARM官方推出的一个算法库(官方链接:http://www.keil.com/pack/doc/CMSIS/DSP/html/index.html)。其提供了高效、丰富的数字信号处理模块,并针对ARM Cortex-M4芯片架构进行了深度优化。STM32F系列MCU基于ARM Cortex-M4芯片架构,与CMSIS DSP算法库完美适配。
通过精确测量CMSIS DSP算法库提供的biquad算法模块消耗的系统时钟数,得到参照物。arm_biquad_cascade_df1_f32模块消耗的系统时钟数如下:

可以观察到一个现象,即每次调用算法处理的数据越多,算法的执行效率越高。代价是系统的音频延迟会随之增加,因为需要在算法处理前缓冲更多的数据。
3. 集成算法
在完成了算法的仿真后,我们需要将算法集成到合适的音频驱动框架中,使算法能够真正产品化。
STM32官方提供了cubeMX工具,能够方便地生成驱动代码,例如一个能够在STM32F4-Discovery开发板上运行的USB audio示例。详细内容参考博客链接(https://blog.csdn.net/flydream0/article/details/53120307)。
在顺利跑完上述博客的流程后,得到一个可以正常播放USB音频流的demo例程,但这离我们能将算法集成进来还有很长的一段距离。首先这个例程的的驱动框架不支持大数据块在I2S DMA TX中断里做算法处理,其次也不支持将数据块在while(1)中处理,因此我们需要改进这个框架。
这里介绍一个ST官方推荐的音频驱动框架audio weaver(官方链接https://www.st.com/en/development-tools/st-audioweaver.html)。audio weaver框架的音频驱动部分的示意图如下:
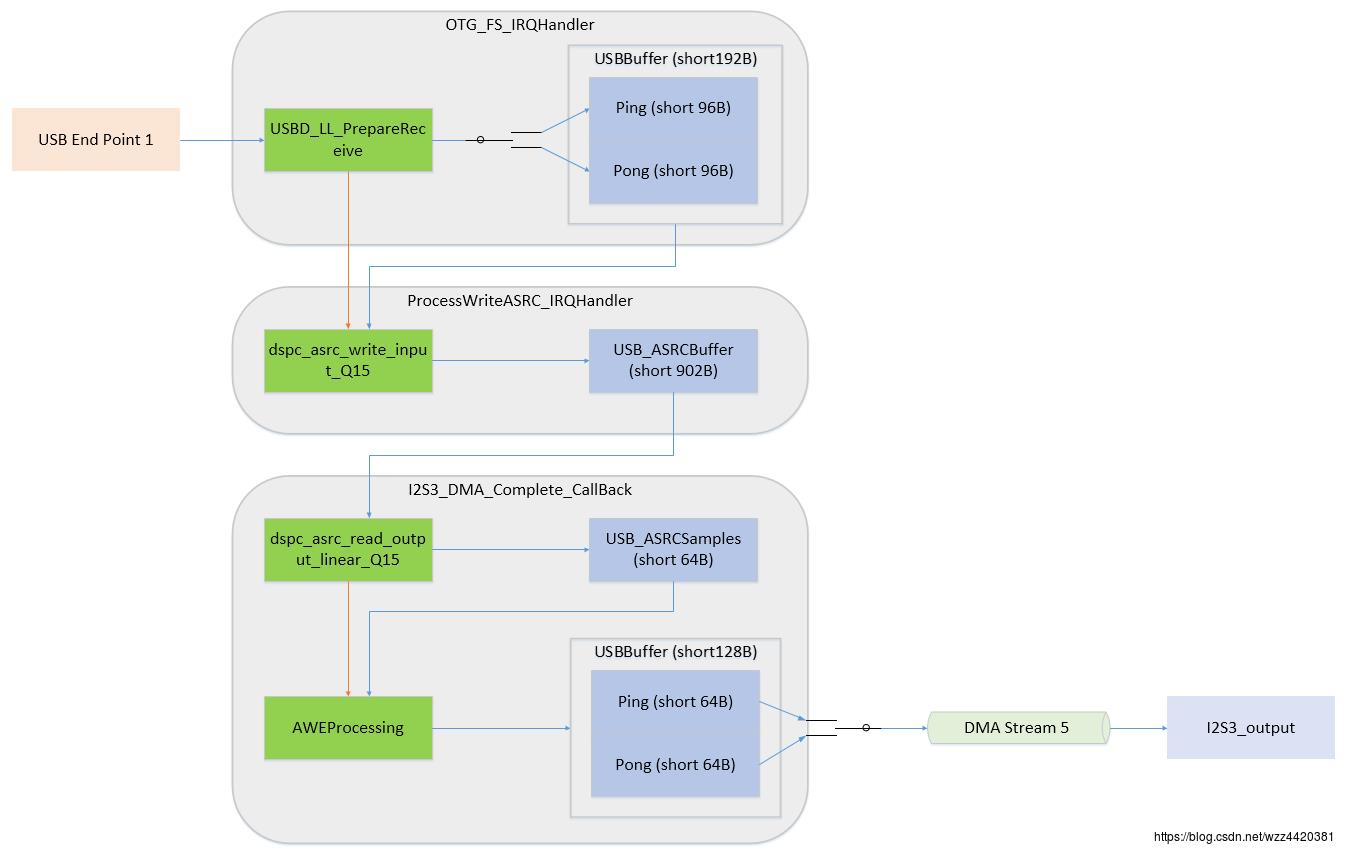
可以看到,这个框架的USB输入和I2S输出端都运用了ping-pong buffer,可有效利用内存。USB的数据经过采样率转换后,缓存在ASRC的buffer里。I2S的DMA通道在每次完成传输后,会主动从ASRC的buffer里取出合适数量的数据来处理,处理完成后写入到I2S的ping-pong buffer。
我们测试了此框架可以在USB下行I2S播放+单PDM麦克风采集的驱动负载的情况下,承担最多120个32位浮点biquad的处理需求。同时这个audio weaver工具支持图形化的调音工具,有点类似sigmaDSP的调音方法,唯一的遗憾是,免费版无法保存调音配置,需每次上电重新导入。
4. 总结
在进行STM32F4平台的算法仿真和集成的过程中,头一次体会到了驱动和算法之间难舍难分的关系,更认识到软件架构的优劣直接影响到平台性能的整体发挥。
由此感悟到所谓35岁是IT人才的发展瓶颈只不过是一句职场谣言。只要找对了路子,35岁正是技术精进和突破的大好时机。在此与各位坚持在某个行业或领域的朋友共勉:唯有水滴才能石穿。
以上是关于在STM32F4平台上实现算法仿真和集成的主要内容,如果未能解决你的问题,请参考以下文章