通用文档信息提取模型浅析
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通用文档信息提取模型浅析相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2.网上优质的Python题库很少,这里给大家推荐一款非常棒的Python题库,从入门到大厂面试题👉点击跳转刷题网站进行注册学习
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 6. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
文章目录
1. 前言与痛点
我们在工作生活中经常需要提取图片中的文字,比如小伙伴给你发了一张发票,你需要将发票中的文字信息录入到系统中,传统的方式都是照着图片中的文字手动录入,这种方式低效又容易出错,想必财务小伙伴对此深有体会。
那么有没有一种高效、便捷、快速识别提取图片中文字的方式呢?答案当然是有的。OCR就是专门用来识别提取文档图像中文字的技术。类似于人通过眼睛的视觉方式来接收外界信息一样,OCR技术就相当于是计算机(AI技术)的眼睛,它可以通过视觉感知技术识别并提取文档图像中的文字。然而目前复杂文档图像的识别问题似乎已经成为 AI 技术落地中的瓶颈,文档图像作为一种非结构化数据,其分析识别面临一些技术难点:
- 文档图像版式复杂,结构多样:
文档图像版式多种多样,文本行方向,形状,字体风格和颜色各不相同,这就要求图像识别技术能够适应各种不同的文档图像版式。
自然场景下图像的背景也是非常复杂,有的图像因为光照或者拍照角度的原因,导致OCR难以准确定位提取图片中的文字。
有的文档严重变形,文档质量退化非常严重,如下图产生了极大的摩尔纹,为图像识别带来了极大的困难。
- 关键信息提取及结构化理解困难:
身份证、护照、行驶证、驾驶证、港澳通信证等证照类别,及增值税发票、普通发票、小票、合同等文档被篡改后无法检测出是否真实,PS智能检测在反欺诈、合规风控等领域意义重大。如下图证件修改过字和有效期数字,这为识别带来了新的困难。

虽然,目前市面上有很多OCR技术方案,但是没有任何一款产品可以可以同时实现在多场景、多任务类型、多语言环境下高效稳定地处理。有些产品专注于文档处理和转换;有些产品可以很方便地对屏幕文本截图识别,但却无法处理手写文本;有些产品面面俱到却效果不佳。一次偶然的机会,我通过CSDN平台了解并体验了一款让我惊艳的智能文档处理和OCR识别的产品平台。合合信息:它的官网号称为“扫描全能王”、“名片全能王”提供文字识别引擎。

合合信息为文档结构化理解的痛点提供了一系列的新技术。合合信息实现了通用NLP抽取, 它基于自研NLP信息抽取技术,无需配置与训练,可对单页/多页、任意版式文档,智能分析与提取客户自定义关键信息。 推荐使用场景:各种证件、票据、非标文档以及合同/标书/保单/网页截图等各类电子文档。
2. 通用信息提取模型技术分析
1. 技术介绍
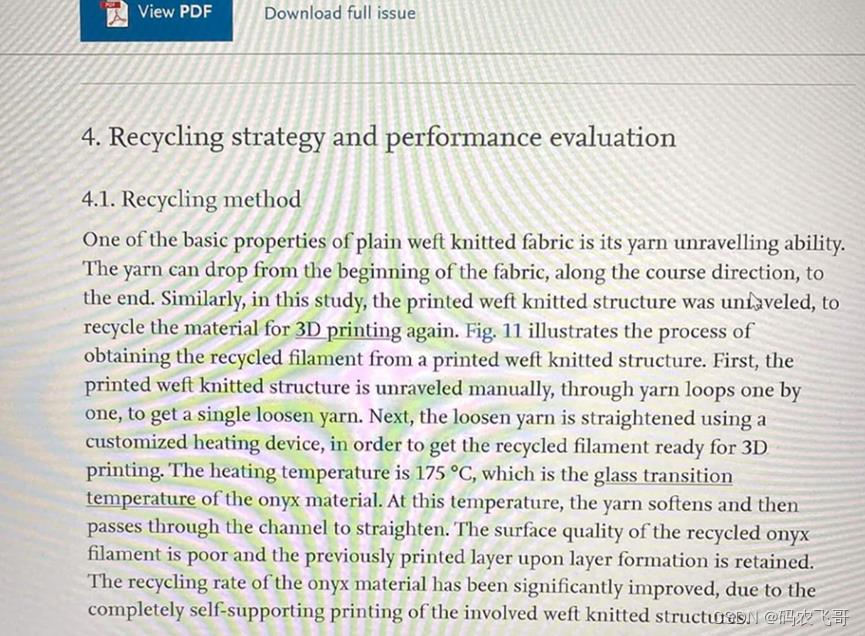
当提取文档信息并归纳这些信息的时候,首先需要获取版面元素,这些元素包括文本、印章、页眉、页脚、表格、水印、二维码、条形码、公式、Logo等等。接着对提取的版面元素进行信息识别,最后对信息进行蒸馏得到关键信息并结构化,这个过程称为信息抽取(Information Extraction, IE)。上述步骤可以使用合合信息提出的通用信息提取框架中的技术来逐步完成。合合信息提出Layout Detection+OCR+NLP+GNN的端到端文档信息提取及结构化理解框架,有效的解决了行业相关痛点,利用通用信息提取技术使得文档智能成为可能。如下图所示:
2. 原理分析
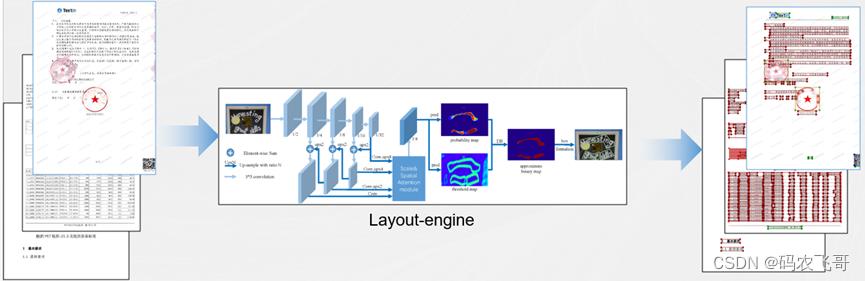
如上图所示:整个框架的模块表现为端到端的输入与输出,不同模块间相互传递监督信号,有效的提高了模型的整体预测效果。合合通用文档信息提取框架通过将文档类别与信息元素之间解耦,能够推理学习空间位置语义并准确捕捉跨模态文档信息,轻松应对各类复杂文档。有效的提高了框架对于不同类别文档识别的通用性与准确性。并将文档智能推向了更高层面的工业应用。
下面为各个模块的进行详细介绍。
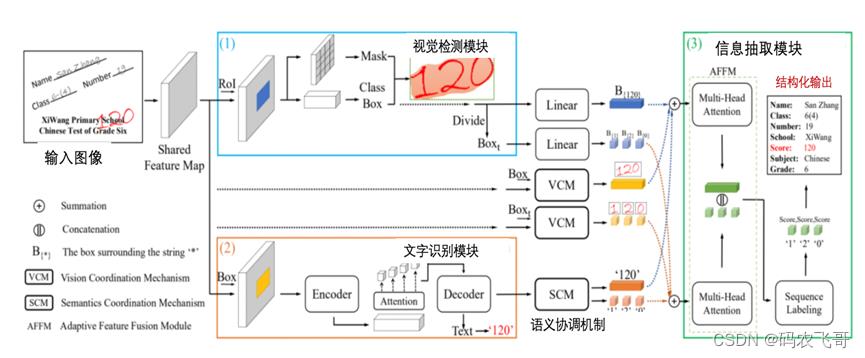
1. Layout Detection(视觉检测模块):
文档版面元素是文档理解的基础,合合信息提出Layout Engine作为框架的视觉检测模块,首先检测出文档中的各个元素,包括文本、印章、页眉、页脚、表格、水印、二维码、条形码、公式、Logo等。该模块通过下采样、上采样以及attention模块获取图像多尺度、空间以及通道相关的特征。最后采用point-wise的方式获取文档元素的heatmap区域,可以有效的提取各种形状以及各类信息的元素区域。
2. OCR(文字识别模块):
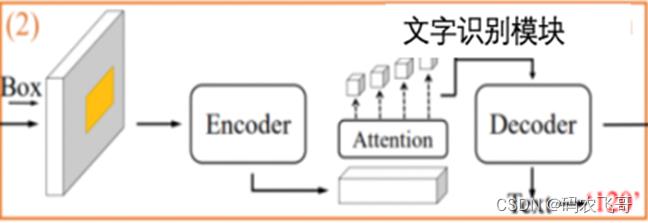
提取出文档各个部分的元素之后,采用OCR模块进行元素中信息识别。该模块对提取出的文档元素图像进行编码,再通过attention模块加强图像内部信息的联系,最后通过解码器得到文档元素的信息识别。
3. NLP(语义协调模块):
利用语义模型对OCR识别出的信息进行语义合理性推理,从而调整信息内容,提高信息识别的准确率。合合信息基于自研NLP信息抽取技术,无需配置与训练,可对单页/多页、任意版式文档,智能分析与提取客户自定义关键信息。推荐使用场景:各种证件、票据、非标文档以及合同/标书/保单/网页截图等各类电子文档。

4. GNN(信息提取模块):
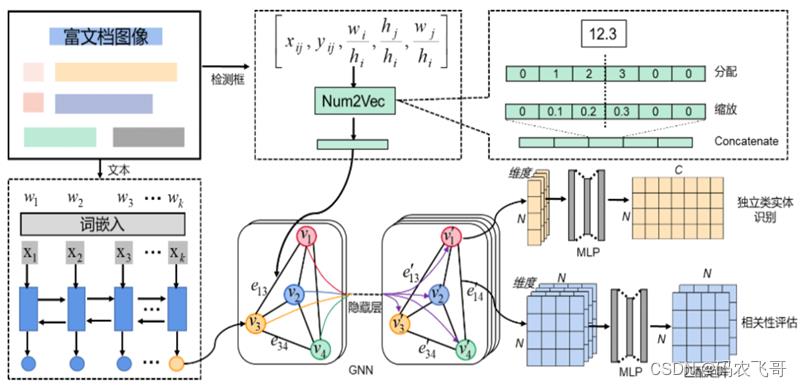
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础。
很多学习任务都需要处理图数据,这些数据包含了元素之间丰富的关系信息。 建模物理系统,学习分子指纹,预测蛋白质界面,以及疾病分类都需要模型从图形输入中学习。在文本、图像等非结构化数据学习等领域,对提取出的句子依赖树、图像场景图等结构进行推理是一个重要的研究课题,也需要图形推理模型。
图神经网络(GNN)是一种连接主义模型,它通过在图的节点之间传递消息来获取图的依赖性。与标准神经网络不同的是,图神经网络保留了一种状态,这种状态可以用任意深度表示邻居的信息。
文档版面元素之间正是包含了丰富的关系信息,因此自然的联想到使用GNN网络对版面元素进行建模。该模块利用文本+图像(文档元素ROI)多模态信息输入到GNN(图神经网络模型),图像信息编码作为GNN的边,即元素间的关系;文本信息编码作为GNN的节点,即元素信息。最后通过MLP(多层感知机)对元素进行信息类别的判定以及元素间相关性评估。最终完成对文档的信息抽取并结构化输出。
3. 技术效果
合合信息自研NLP通用信息提取框架在如下领域都取得了非常良好的效果。
3.1. 通用文字识别
合合信息通过领先的深度学习技术,对各种表格,图片,文档、证件、面单等多种通用场景进行快速、精准的检测和识别,支持简体中文/繁体中文/英文/数字/西欧主流语言/东欧主流语言等共52种语言,同时支持印刷体、手写体、倾斜、折叠、旋转等。
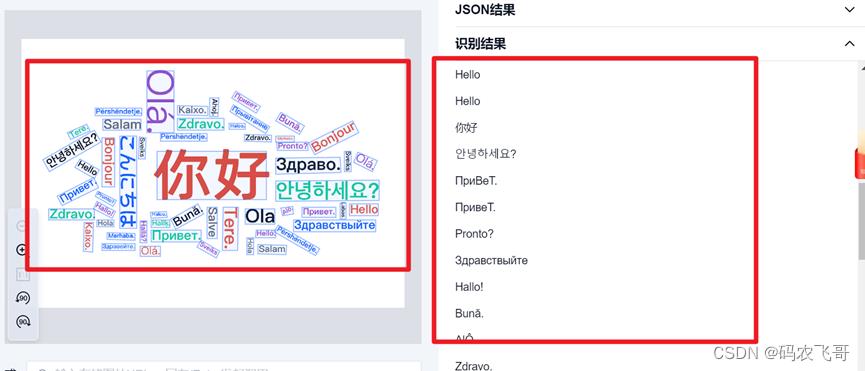
如下图所示是各种不同语言的【你好】,这些字体大小不同,排版不同(有的倾斜,有的横排,有的竖排),语言不同。但是合合信息的通用文字识别功能可以非常轻松将图片中所有的文字信息识别出来。识别结果如下图所示:
3.2. 通用表格信息提取
合合信息的通用表格识别功能支持识别图片/PDF格式文档中的表格内容,包括有线表格、无线表格、合并单元格表格,同时支持单张图片内的多个表格内容识别,返回各表格的表头表尾内容、单元格文字内容及其行列位置信息。如下图是一个普通的表单图片:
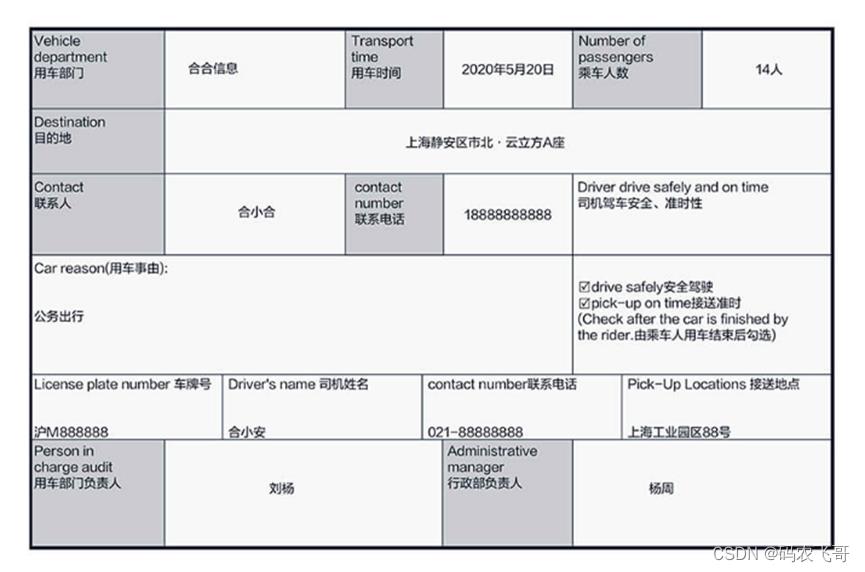
最终的识别结果如下图所示:

3.3. 印章检测
合合信息印章检测功能可以识别并提取图像中的印章,以及辨认印章的所属单位支持检测并识别多行业合同文件和票据中的印章,结构化返回票据等样本上单个/多个印章上文字,支持红章/黑章,常规印章(圆章/方章等),可控制印章切图外扩留白范围。

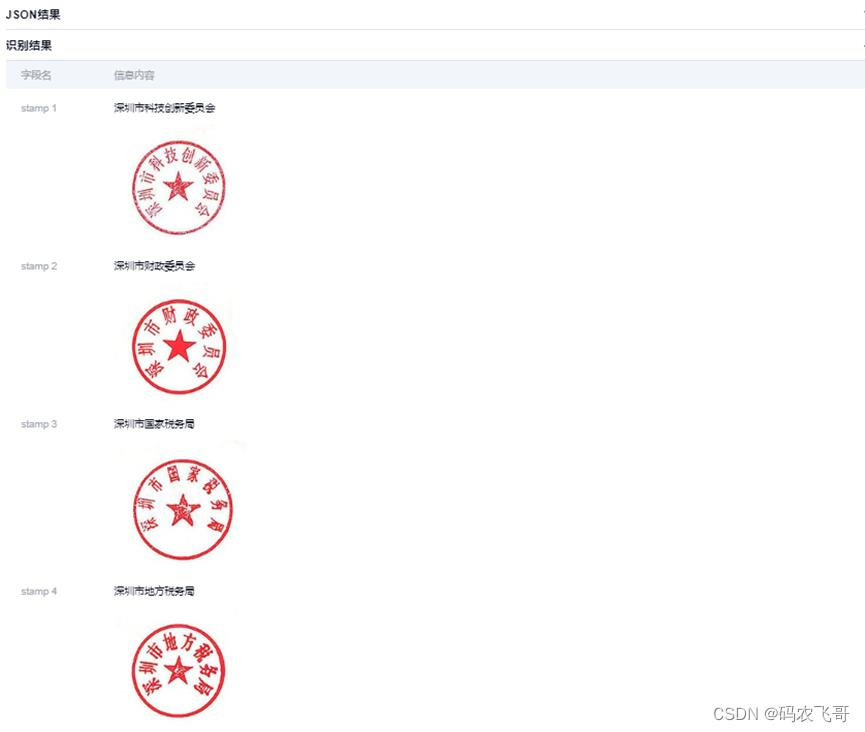
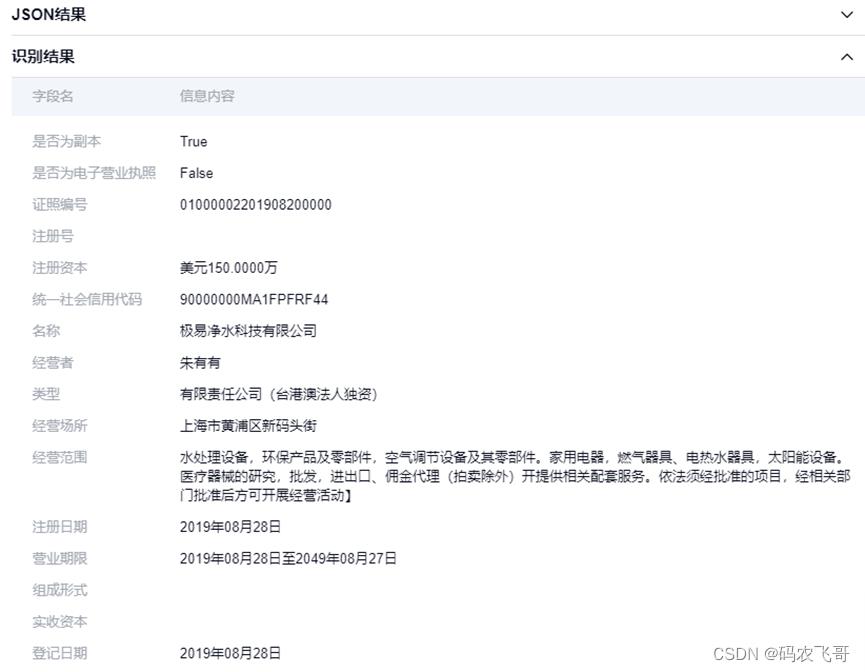
3.4. 营业执照检测
合合信息支持检测并识别多行业合同文件和票据中的印章,结构化返回票据等样本上单个/多个印章上文字,支持红章/黑章,常规印章(圆章/方章等),可控制印章切图外扩留白范围。可识别营业执照上的文字信息,包括社会信用代码、注册号、企业名称、企业类型、企业法人、注册资本、经营范围等字段。

3.5. 办公文档识别
合合信息可对办公文档的图片版面进行分析,输出图、表、列表、文本、水印、页眉页脚、印章、公式的位置及文字,并输出分版块内容的OCR识别结果,支持52种语言,手写、印刷体混排多种场景。识别效果如下图所示:

4. 总结
文档智能化分析确实存在很多问题,导致了产品落地困难,只有解决或改善相关问题,才能有效并高效地进行工业化应用。合合信息致力于解决所遇到的问题,通过深耕问题产生的背后原因,最终完成自研通用信息提取框架,覆盖文字、文档、表格、印章、二维码、公式等多种通用场景,提供全球50+主流语言的印刷体、手写体的高精度识别能力。可用于纸质文档电子化、办公文档/报表识别、教育类文本识别、快递面单识别。

合合信息专注于智能文字识别、图像处理、自然语言处理(NLP)、知识图谱、大数据挖掘等技术。基于自主研发的领先的智能文字识别及商业大数据核心技术,为全球 C 端用户和多元行业 B 端客户提供数字化、智能化的产品及服务。
合合信息 C 端产品方面的落地非常成熟,扫描全能王(智能扫描及文字识别 APP)、名片全能王(智能名片及人脉管理 APP)、启信宝(企业商业信息查询 APP)这些耳熟能详的产品覆盖了全球百余个国家和地区的亿级用户。
以上是关于通用文档信息提取模型浅析的主要内容,如果未能解决你的问题,请参考以下文章