MySQL从入门到精通高级篇(二十八)子查询优化,排序优化,GROUP BY优化和分页查询优化
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL从入门到精通高级篇(二十八)子查询优化,排序优化,GROUP BY优化和分页查询优化相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2.网上优质的Python题库很少,这里给大家推荐一款非常棒的Python题库,从入门到大厂面试题👉点击跳转刷题网站进行注册学习
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 6. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
文章目录
1. 简介
上一篇文章我们介绍了 1024程序员节|【MySQL从入门到精通】【高级篇】(二十七)外连接和内连接如何进行查询优化呢?join的原理了解一波,这篇文章我们接着来学习,本文主要学习的是子查询优化,排序优化,GROUP BY优化以及分页查询优化。
测试数据
- 测试表 student表中有50万条数据
- 测试表 class表中有1万条数据
1.子查询优化
mysql从4.1版本开始支持子查询,使用子查询可以进行SELECT 语句的嵌套查询,即一个SELECT 查询的结果作为另一个SELECT 语句的条件。子查询可以一次性完成很多逻辑上需要多个步骤才能完成的SQL操作。
子查询是MySQL的一项重要的功能,可以帮助我们通过一个SQL语句实现比较复杂的查询。但是,子查询的执行效率不高。 原因:
- 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询。
- 子查询的结果集存储在临时表,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
在MySQL中,可以使用连接(JOIN)查询来替代子查询。 连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
举例1:查询学生表中是班长的学生信息
- 使用子查询
-- 查询学生表中是班长的学生信息
CREATE INDEX idx_monitor ON class(monitor);
-- 使用子查询
EXPLAIN SELECT * FROM student stu1 WHERE stu1.stuno IN(SELECT monitor FROM class c WHERE monitor IS NOT NULL);

这里可以看出使用使用子查询的耗时是 。0.33秒。
接下来看下使用多表关联查询
-- 使用多表关联查询
EXPLAIN SELECT stu1.* FROM student stu1 JOIN class c ON c.monitor IS NOT NULL AND stu1.stuno=c.monitor;

可以看出使用多表关联查询的比子查询要耗时,两个表的索引情况如下,在student表中的stuno字段没有添加索引,所以关联的时候会比较耗时。
给student表的stuno字段添加索引
CREATE INDEX idex_stuno ON student(stuno);
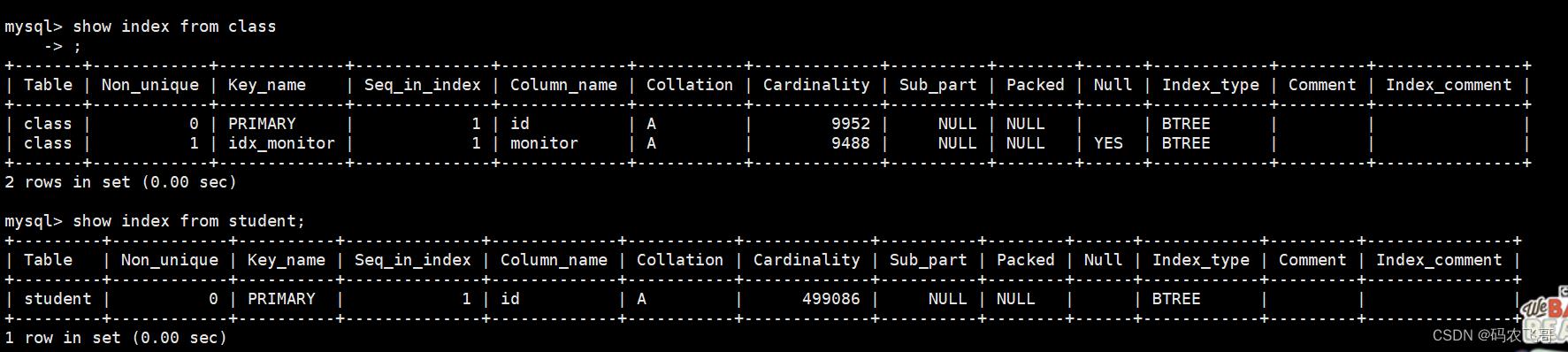
下面就给student表中的stuno字段添加索引再看下效果。两者的速度都比较快

如果子查询的表数据比较少,子查询的结果比较少的话可以使用子查询。否则可以考虑使用多表关联,但是关联的字段必须要建立索引,比如关联查询效果比子查询还要差。
举例2:取所有不为班长的同学
SELECT SQL_NO_CACHE * FROM student stu1 WHERE stu1.stuno NOT IN(SELECT monitor FROM class c WHERE monitor IS NOT NULL);
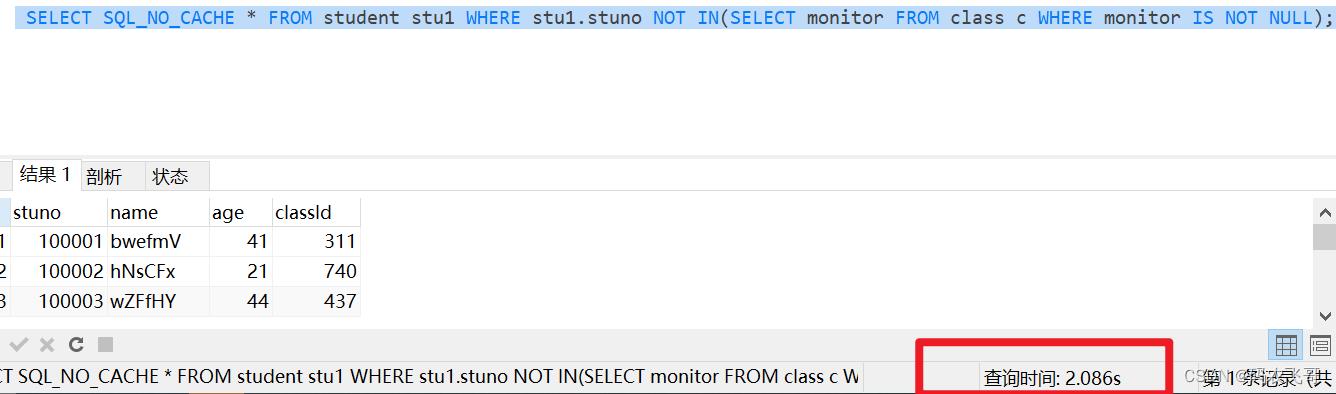
可以看出使用关联查询的效果非常差,查询时间高达2.086s。
SELECT SQL_NO_CACHE stu1.* FROM student stu1 LEFT JOIN class c ON stu1.stuno=c.monitor AND c.monitor IS NULL ;
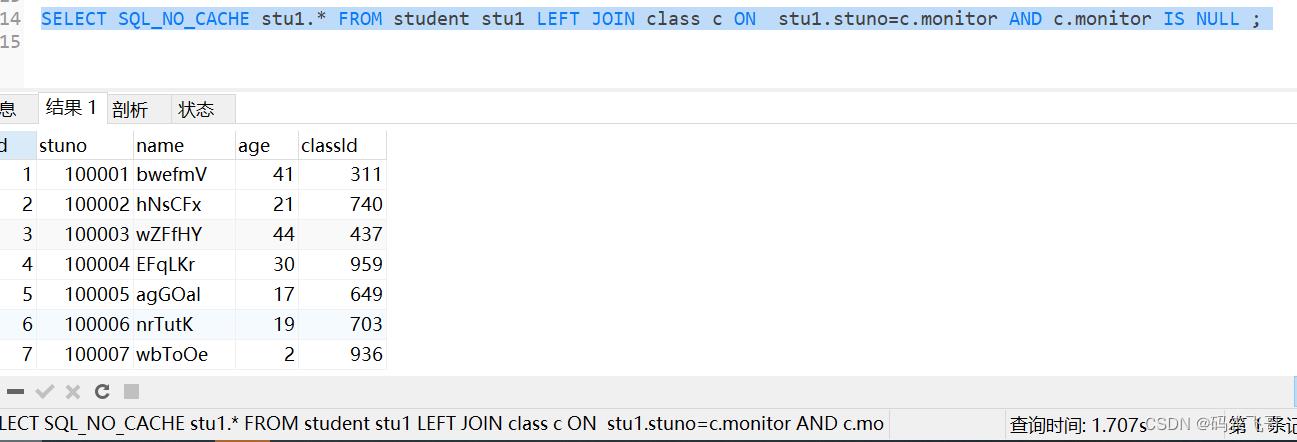
使用关联查询则好一点。
2. 排序优化
问题:在WHERE条件字段上加索引,但是为什么在ORDER BY字段上还要加索引呢?
回答:在MySQL中,支持两种排序方式,分别为FileSort和Index排序。
- Index排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。
- FileSort排序则一般在内存中进行排序,占用CPU比较多,如果待排结果较大,会产生临时文件I/O到磁盘进行排序的情况,效率较低。
过程一:删除两个表的索引,写一个普通的排序查询
ALTER TABLE student DROP INDEX idex_stuno;
ALTER TABLE class DROP INDEX idx_monitor;
-- 过程一
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classId;
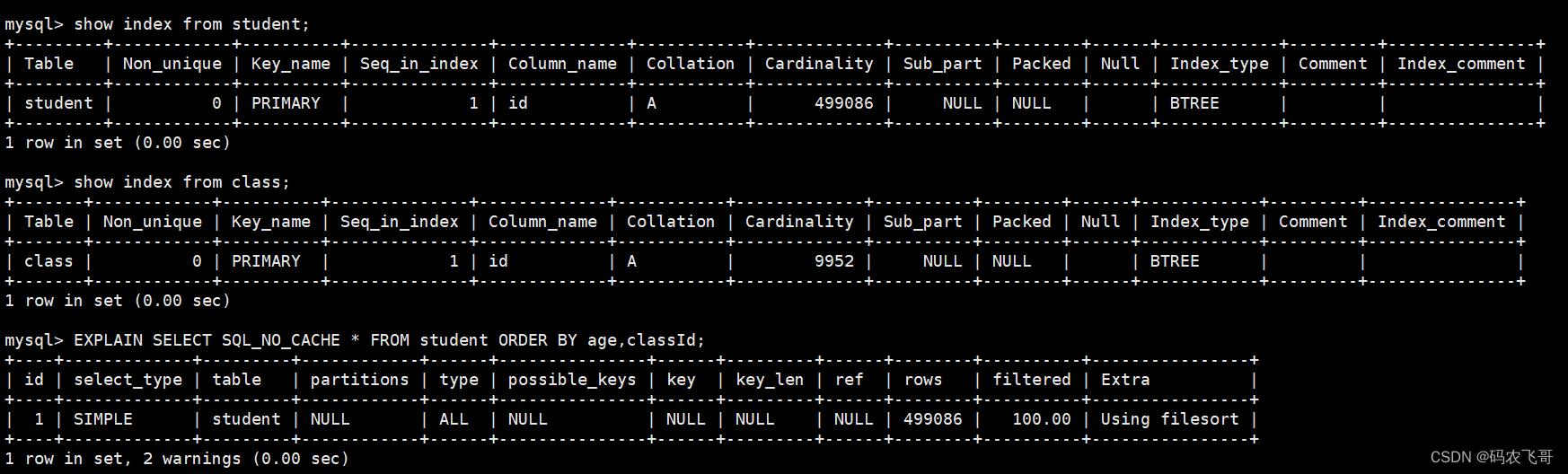
可以看出没有索引的情况下,排序使用的是 filesort 排序,也就是在内存中排序。
过程二,创建索引,order by时不limit,索引失效
下面在student表中创建idx_age_classid_name索引。
CREATE INDEX idx_age_classid_name ON student(age,classId,`name`);
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classId;
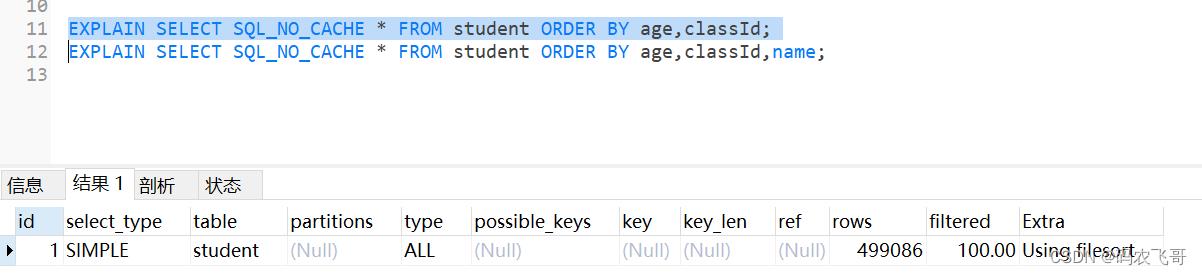
可以看出使用的排序方式还是 filesort的方式,也就以为着索引失效了。
增加limit过滤条件,使用上索引了。
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age,classId LIMIT 1000;
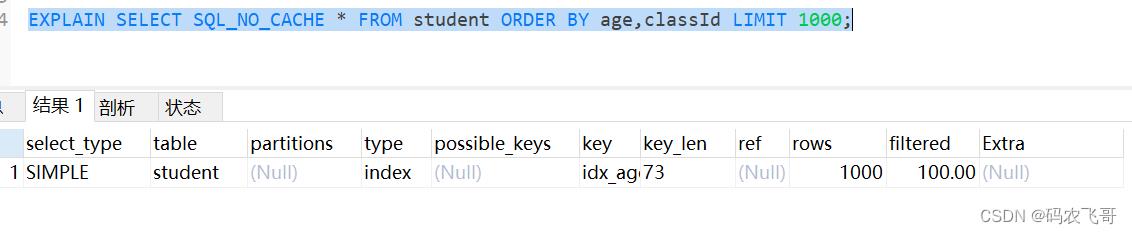
过程三:ORDER BY时顺序错误,索引失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student ORDER BY age DESC,classId LIMIT 1000;

过程五:无过滤,不索引

SHOW INDEX FROM student;
# 索引有效
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classId;
#索引有效
EXPLAIN SELECT * FROM student WHERE age=45 ORDER BY classId LIMIT 10;
# 索引无效
EXPLAIN SELECT * FROM student WHERE classId=45 ORDER BY classId LIMIT 10;
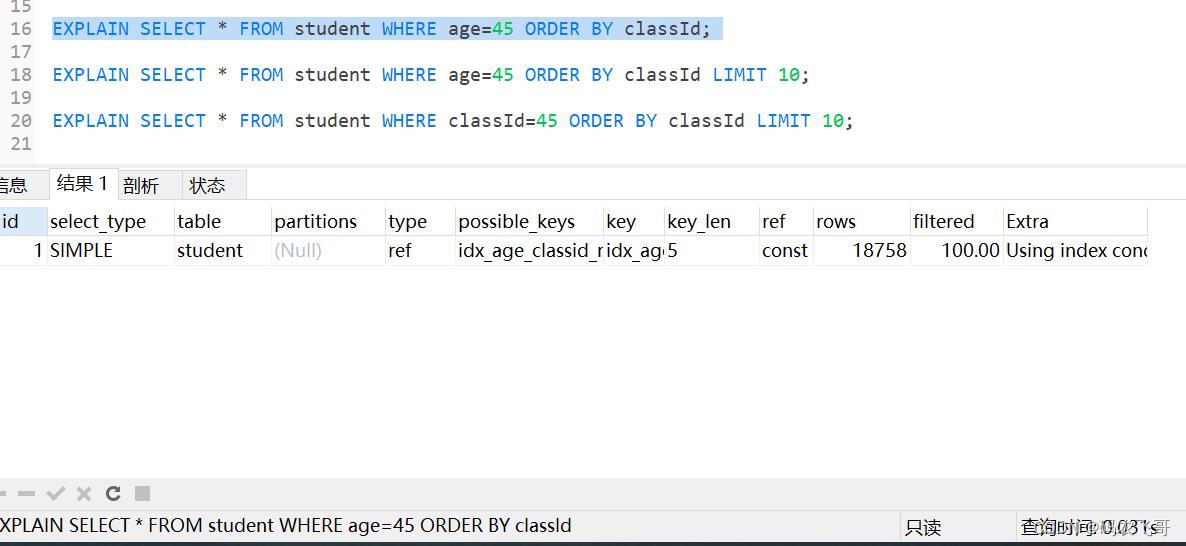

优化建议:
- SQL中,可以在WHERE子句和ORDER BY子句中使用索引,目的是WHERE子句中避免全表扫描,在ORDER BY子句避免使用FileSort排序。,当然,某些情况下全表扫描,或者FileSort排序不一定比索引慢。但总的来说,我们还是要避免,以提高查询效率。
- 尽量使用Index完成ORDER BY排序。如果WHERE和ORDER BY 后面是相同的列就使用单索引列;如果不同就使用联合索引。
- 无法使用Index时,需要对FileSort方式进行调优。
小结
INDEX a_b_c(a,b,c)
ORDER BY 能使用索引最左前缀
- ORDER BY a
- ORDER BY a,b
- ORDER BY a,b,c
- ORDER BY a DESC,b DESC,c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by能使用索引
- WHERE a=const ORDER BY b,c
- WHERE a=const AND b=const ORDER BY c
- WHERE a=const ORDER BY b,c
- WHERE a=const AND b>const ORDER BY b,c
不能使用索引进行排序
-ORDER BY a ASC,b DESC,c DESC /*排序不一致*/
- WHERE b=const ORDER b,c /*丢失a索引*/
- WHERE a=const ORDER BY c /*丢失b索引*/
- WHERE a=const ORDER BY a,d /*d不是索引的一部分*/
- WHERE a in (...) ORDER BY b,c /*对于排序来说,多个相等条件也是范围查询*/
排序优化实战
ORDER BY子句,尽量使用index方式,避免使用FileSort方式排序。
执行案例前先清除student上的索引,只留主键:
场景:查询年龄为30岁的,且学生编号小于101000的学生,按用户名称排序
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND stuno<101000 ORDER BY NAME;

结论:type是ALL,即最坏的情况,Extra里出现了Using filesort也是最坏的情况,优化是必须的。
优化思路:
方案一:为了去掉filesort我们可以把索引建成如下这样:
CREATE INDEX idx_age_name ON student(age,`name`);
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND stuno<101000 ORDER BY NAME;

这样就优化掉了using filesort。
3. GROUP BY优化
- group by 使用索引的原则几乎跟order by一致,group by即使没有过滤条件用到索引,也可以直接使用索引。
- group by先排序在分组,遵照索引建的最佳左前缀法则
- 当无法使用索引列,增大max_length_for_sort_data 和sort_buffer_size 参数的设置
- where效率高于having,能写在where限定的条件就不要写在having中了
- 减少使用order by,和业务沟通能不排序就不排序,或者将排序放在程序端去做,order by、group by、distinct这些语句较为耗费CPU,数据库的CPU资源极其宝贵。
- 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保存在1000行以内,否则SQL会很慢。
4. 优化分页查询
一般分页查询时,通过创建覆盖索引能够比较好地提高性能。一个常见又非常头疼的问题就是limit 200000,10,此时需要MySQL排序前200010记录,仅仅返回200000~200010 的记录,其他记录丢弃,查询排序的代价非常大。
EXPLAIN SELECT * FROM student LIMIT 200000,10;

这里全表扫描,共计扫描了499086条数据。
优化思路一:
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容。
EXPLAIN SELECT * FROM student t,(SELECT id FROM student ORDER BY id LIMIT 200000,10) t1
WHERE t.id=t1.id;

优化思路二:
该方案适用于自增的表,可以将limit查询转换成某个位置的查询。
EXPLAIN SELECT * FROM student WHERE id>200000 LIMIT 10;

总结
以上是关于MySQL从入门到精通高级篇(二十八)子查询优化,排序优化,GROUP BY优化和分页查询优化的主要内容,如果未能解决你的问题,请参考以下文章