如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch相关的知识,希望对你有一定的参考价值。
在今天的这篇文章中,我想介绍如何在 Linux 及 MacOS 上进行安装 Elasticsearch。Elasticsearch 的安装是非常直接的。在今天的这篇文章中,我们介绍如果直接从已经编译好的档案(.tar.gz)中来直接安装 Elasticsearch。如果大家想对 Elasticsearch 有一个大概的了解,请参照我的文章 “Elasticsearch 简介”。在你进行安装之前,你可以参阅 Support Matrix | Elastic 以了解你的系统是否适合安装 Elasticsearch 以及哪个版本的 Elasticsearch。
此软件包可在 Elastic 许可下免费使用。 它包含开源和免费商业功能以及付费商业功能。 开始为期30天的试用,试用所有付费商业功能。 有关弹性许可级别的信息,请参阅 “订阅”页 面。
可以在 Download Elasticsearch 页面上找到最新的稳定版 Elasticsearch。 其他版本可在 “历史版本” 页面上找到。
注意:Elasticsearch 包含来自 JDK 维护者(GPLv2 + CE)的捆绑版 OpenJDK。 要使用你自己的Java版本,请参阅 JVM 版本要求。大家如果想学习如何在 Ubuntu/Linux 上安装 JAVA,请参阅我的文章 “如何在 Ubuntu 上安装 Java”。Java 的版本不可以低于1.7_55。从 Elastic 7.0开始,我们可以不安装 JAVA。安装包包含一个相匹配的 JAVA 版本在里面。
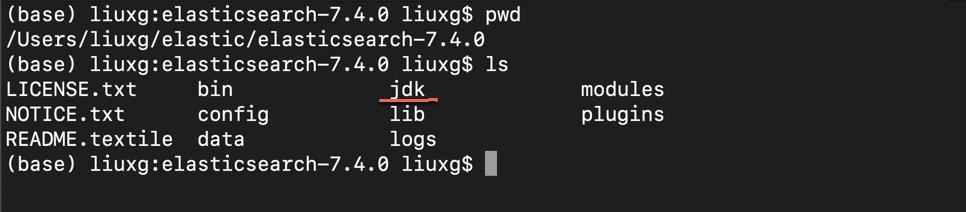
Elastic Stack 8.x 安装
Elastic Stack 8.x 由于全面启动了安全设置,在一些步骤上稍微有些差异。Elastic Stack 8.0 的按照请参考如下的几篇文章尽管下面的安装步骤基本适用。
下载并安装 Linux 归档文件
在如下的安装中,我们以 7.3.0 来为例进行安装。在实际的安装中,可以替换命令行中的 7.3.0,并用最新的发行版本号来代替,比如 7.5.1。如果你想直接从网站上下载你想要的版本,你可以直接在 Past Releases of Elastic Stack Software | Elastic 进行下载。
可以按如下方式下载和安装 Elasticsearch v7.3.0 的 Linux 归档文件:
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.0-linux-x86_64.tar.gz
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.0-linux-x86_64.tar.gz.sha512
$ shasum -a 512 -c elasticsearch-7.3.0-linux-x86_64.tar.gz.sha512
$ tar -xzf elasticsearch-7.3.0-linux-x86_64.tar.gz
$ cd elasticsearch-7.3.0/ 在上面的第三行,比较下载的 .tar.gz 存档的 SHA 和发布的校验和,该校验和应输出 elasticsearch- version -linux-x86_64.tar.gz:OK。这个是为了校验下载的文件是正确的。
上面的最后一行所在的目录代表 $ES_HOME。在下面的表述中我们使用它来进行表述我们的安装目录。
或者,你可以下载以下软件包,其中仅包含 Apache 2.0 许可代码:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-oss-7.3.0-linux-x86_64.tar.gz
针对 DEB 安装包的安装,可以参阅另外一篇文章 “Elasticsearch:使用 Debian 软件包安装 Elasticsearch”。
Virtual memory
Elasticsearch 默认使用 mmapfs 目录存储其索引。 默认的操作系统对 mmap 计数的限制可能太低,这可能会导致内存不足异常。
在 Linux 上,你可以通过以 root 用户身份运行以下命令来增加限制:
sysctl -w vm.max_map_count=262144要永久设置此值,请更新 /etc/sysctl.conf 中的 vm.max_map_count 设置。配置完毕后,我们可以使用如下的命令来使之起作用:
sysctl -p要在重新引导后进行验证,请运行
sysctl vm.max_map_countRPM 和 Debian 软件包将自动配置此设置。 不需要进一步的配置。
注意:由于 Elasticsearch 的迭代比较快,所以你可以在下载最新的版本进行安装。最新的版本可以在地址找到:Download Elasticsearch Free | Get Started Now | Elastic | Elastic
下载并安装 MacOS 的存档
可以按如下方式下载和安装 Elasticsearch v7.3.0 的 MacOS 存档:
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.0-darwin-x86_64.tar.gz
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.0-darwin-x86_64.tar.gz.sha512
$ shasum -a 512 -c elasticsearch-7.3.0-darwin-x86_64.tar.gz.sha512
$ tar -xzf elasticsearch-7.3.0-darwin-x86_64.tar.gz
$ cd elasticsearch-7.3.0/ 在上面的第三行,比较下载的. tar.gz 存档的 SHA 和发布的校验和,该校验和应输出 elasticsearch- version -linux-x86_64.tar.gz:OK。这个是为了校验下载的文件是正确的。
上面的最后一行所在的目录代表 $ES_HOME。在下面的表述中我们使用它来进行表述我们的安装目录。
或者,你可以下载以下软件包,其中仅包含 Apache 2.0 许可代码:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-oss-7.3.0-linux-x86_64.tar.gz
下载并安装 Windows .zip 文件
从以下位置下载 Elasticsearch v7.3.1 的 .zip 存档:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.1-windows-x86_64.zip
或者,你可以下载以下软件包,其中仅包含 Apache 2.0 许可证下提供的功能:
用你最喜欢的解压缩工具解压缩它。 这将创建一个名为 elasticsearch-7.3.1 的文件夹,我们将其称为 %ES_HOME%。 在终端窗口中,cd 到 %ES_HOME% 目录,例如:
cd c:\\elasticsearch-7.3.1在 Windows 下时,请打开具有管理员权限的 Command Prompt 来启动 Elasticsearch:
bin\\elasticsearch.bat从命令行运行 Elasticsearch
可以从命令行启动 Elasticsearch,如下所示:
./bin/elasticsearch默认情况下,Elasticsearch在前台运行,将其日志打印到 STDOUT,并可以通过按 Ctrl-C 来停止。
有两个重要的配置选项
- elasticsearch.yml(文件位于安装目录下的 config 子目录):path.data: /data/elasticsearch
-
jvm.options:-Xms512m, 配置 JVM 的内存大小的
如果你想你的 Elasticsearch 绑定你电脑上的所有网络接口,而不是仅仅 localhost,那么你需要修改 config/elasticsearch.yml 文件中的如下设置:
network.host: 0.0.0.0
discovery.type: single-node通过设置 network.host 为 0.0.0.0,它表明 Elasticsearch 可以绑定电脑的任何 IP 地址。你可以使用私有地址 http://<private_ip>:9200 来进行访问。当然你可以通过 http://localhost:9200 来进行访问。在上面,我们设置 discovery.type 为 single-node,它表明是一个单节点的集群。如果不设置这个,那么你的单节点集群可能不能启动。
我们可以通过如下的方法在命令行中配置这两个选项:
$ ./bin/elasticsearch -E path.data=/data/elasticsearch或者:
$ ES_JAVA_OPTS="-Xms512m" ./bin/elasticsearch或者
$ ES_JAVA_OPTS="-Xms512m -Xmx512m" ./bin/elasticsearch我们也可以使用如下的方法来覆盖默认的 node 名字为 elasticsearch:
$ ./bin/elasticsearch -E node.name=mynodename这个对于我们启动两个或多个不同的节点来做 replica 的部署测试,是非常有用的。
启用系统索引的自动创建
一些商业功能会在 Elasticsearch 中自动创建系统索引。 默认情况下,Elasticsearch 配置为允许自动创建索引,不需要其他步骤。 但是,如果在 Elasticsearch 中禁用了自动索引创建,则必须在 elasticsearch.yml 中配置 action.auto_create_index,以允许商业功能创建以下索引:
action.auto_create_index: .monitoring*,.watches,.triggered_watches,.watcher-history*,.ml*重要提示:
如果你使用的是 Logstash 或 Beats,则很可能在 action.auto_create_index 设置中需要其他索引名称,具体值取决于你的本地配置。 如果你不确定环境的正确值,可以考虑将值设置为 *,这将允许自动创建所有索引。
Docker 安装
如果你想通过 docker 进行安装,请参照我的文档 “Elastic:用 Docker 部署 Elastic 栈”。通过 docker-compose 的使用,我们可以一次性安装 Elastic 栈里的多个软件。
对于 Docker 的安装,你可以参照我的另外一篇文章“Elasticsearch:从零开始安装 Elasticsearch 并使用 Python 装载一个 CSV 并读写它” 来部署你的 Elasticsearch 及 Kibana。
从命令行运行 Elasticsearch
可以从命令行启动 Elasticsearch,如下所示:
./bin/elasticsearch默认情况下,Elasticsearch 在前台运行,将其日志打印到标准输出(stdout),并可以通过按 Ctrl-C 来停止。
注意:与 Elasticsearch 一起打包的所有脚本都需要一个支持数组的 Bash 版本,并假设 Bash 在 /bin/bash 中可用。 因此,Bash 应该直接或通过符号链接在此路径上可用。
检查 Elasticsearch 是否已运行
你可以通过向 localhost 上的端口 9200 发送 HTTP 请求来测试你的 Elasticsearch 节点是否正在运行:
GET /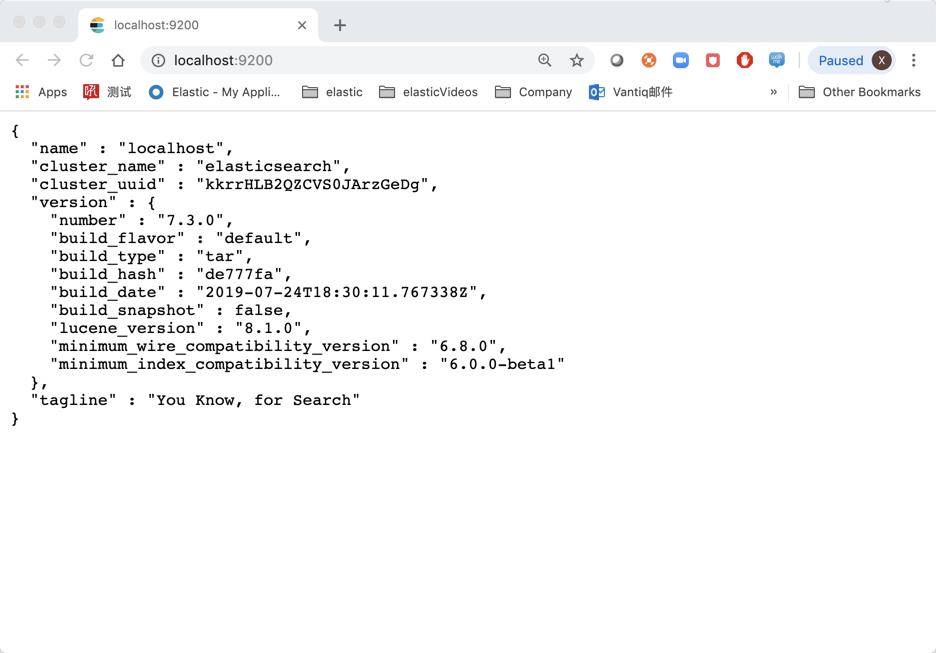
可以使用命令行上的 -q 或 --quiet 选项禁用日志打印到 stdout。
除了上面用浏览器的方式来检查我们的 Elasticsearch 是否正确运行以外,我们还可以通过如下的命令行来运行:
curl 'http://localhost:9200/?pretty'
从上面我们可以看出来,在默认的情况下我们已经创建了一个名字叫做 “elasticsearch” 的集群。
如果你为自己的集群已经创建安全访问,你可以使用如下的方式来运行上面的 curl 指令:
curl -XGET "http://elastic:password@localhost:9200/"或者:
curl -u elastic:password -XGET "http://localhost:9200/"这里的 elastic 及 password 分别为访问 Elasticsearch 的用户名及密码。关于如何配置安全,请阅读我的文章 “设置 Elastic 账户安全”。
对于熟悉 Postman 的开发者来说,我们可以很方便地使用 Postman 和 Elasticsearch 一起使用起来。它是一个很好的调试工具:
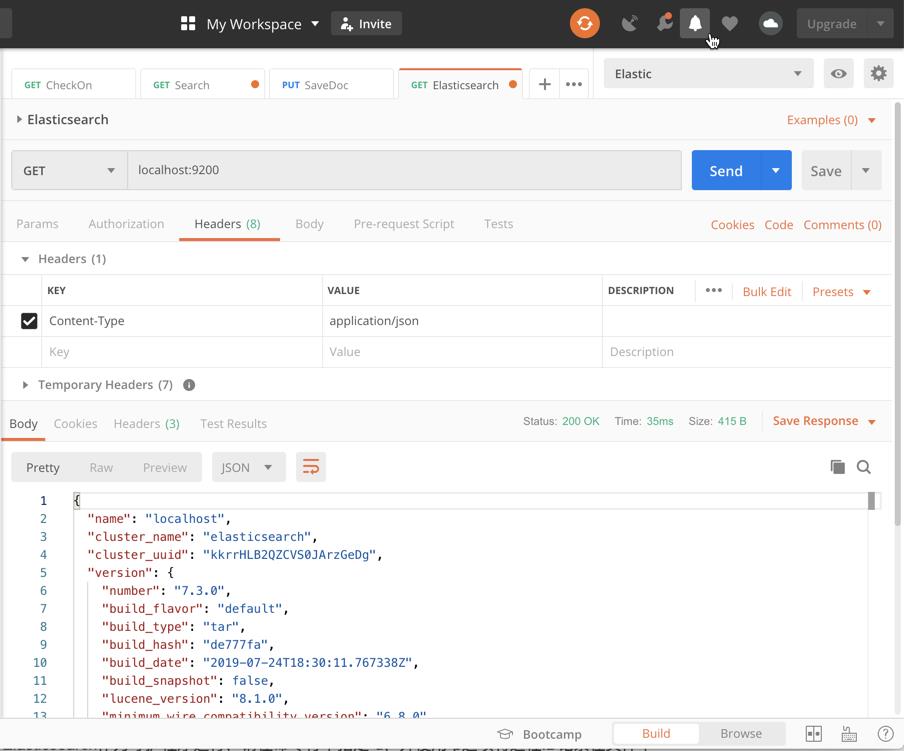
我们可以使用 Postman 工具在没有 Kibana 的情况下使用。如果你对这个感兴趣的话,你可以阅读我的文章 “Elastic:使用Postman来访问Elastic Stack”。
作为守护进程运行
要将 Elasticsearch 作为守护程序运行,请在命令行中指定 -d,并使用 -p 选项将进程 ID 记录在文件中:
./bin/elasticsearch -d -p pid上面的这个命令把运行的进程存放于一个叫做 pid 的文件之中,为了方便下面的终止。在上面 Elasticsearch 运行于后台 (daemon)。可以在 $ES_HOME/logs/ 目录中找到日志消息。
要关闭 Elasticsearch,请终止 pid 文件中记录的进程 ID:
$ pkill -F pid或者使用如下的命令来终止它的运行:
$ kill `cat pid`我们也可以通过如下的 jps (Java Virtual Machine Process Status Tool)来查看 Elasticsearch 的运行:
jps | grep Elasticsearch上面会显示当前 Elasticsearch 运行的进程 ID:

我们可以通过如下的命令来终止 Elasticsearch 的运行:
kill -9 6253RPM 和 Debian 软件包中提供的启动脚本负责为你启动和停止 Elasticsearch 进程。
检查日志文件以确保该过程已关闭。 你将看到文本 Native controller 进程已停止,停止,关闭,在文件末尾附近关闭:
$ pwd
/Users/liuxg/elastic/elasticsearch-7.3.0/logs
(base) liuxg:logs liuxg$ ls *.log
elasticsearch.log
elasticsearch_deprecation.log
elasticsearch_index_indexing_slowlog.log
elasticsearch_index_search_slowlog.log
gc.log
在上面,我看可以看到有一个叫做 elasticsearch.log 的文件。我们可以通过如下的命令来查看 Elasticsearch 的日志(在 Elasticsearch 的安装目录运行):
tail logs/elasticsearch.log在命令行上配置 Elasticsearch
默认情况下,Elasticsearch 从 $ES_HOME/config/elasticsearch.yml 文件加载其配置。 配置 Elasticsearch 中介绍了此配置文件的格式。
也可以在命令行中使用 -E 语法指定可在配置文件中指定的任何设置,如下所示:
./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1这种情况特别适合同样一个 Elasticsearch 的安装运行多个 Elasticsearch 的实例,这样我们可以轻松建立 replica。
我们也可以通过如下的方式来配置 http.host 的值:
./bin/elasticsearch -d -Ecluster.name=my_cluster -Enode.name=node_1 -E http.host="localhost","mac"上面的命令也可以用如下的方式进行表达:
./bin/elasticsearch -d -E cluster.name=my_cluster -E node.name=node_1 -E http.host="localhost","mac"请注意在 -E 及参数之间多了一个空格。
请注意在上面的 Mac 及 localhost 都是可以 ping 到的地址。
你在自己的电脑上可以通过 /etc/hosts 文件来指定它的地址。这样我们的 Elasticsearch 会被 http://localhost:9200 及 http://mac:9200 来访问。
提示:通常,应将任何群集范围的设置(如 cluster.name)添加到 elasticsearch.yml 配置文件中,而可以在命令行上指定任何特定于节点的设置(如 node.name)。
多节点部署
在很多时候,我们想在同一个机器上模拟多个节点的部署。你可以参阅文章 “Elastic:如何在一个机器上同时模拟多个节点”。
安装文件目录布局
归档分发完全是独立的。 默认情况下,所有文件和目录都包含在 $ES_HOME 中 - 解压缩归档时创建的目录。
这非常方便,因为你不必创建任何目录来开始使用 Elasticsearch,卸载 Elasticsearch 就像删除 $ES_HOME 目录一样简单。 但是,建议更改 config 目录,数据目录和 logs 目录的默认位置,以便以后不删除重要数据。
| 类型 | 描述 | 默认位置 | 设置 |
| home | Elasticsearch 主目录或 $ES_HOME | 通过解压缩归档创建的目录 | |
| bin | 二进制脚本包括用于启动节点的 elasticsearch 和用于安装插件的 elasticsearch-plugin | $ES_HOME/bin | |
| config | 配置文件包括 elasticsearch.ym | $ES_HOME/config | ES_PATH_CONF |
| data | 节点上分配的每个索引/分片的数据文件的位置。 可以容纳多个位置。 | $ES_HOME/data | path.data |
| logs | log 文件位置 | $ES_HOME/logs | path.logs |
| plugins | 插件文件位置。 每个插件都将包含在一个子目录中。 | $ES_HOME/plugins | |
| repo | 共享文件系统存储库位置。 可以容纳多个位置。 文件系统存储库可以放在此处指定的任何目录的任何子目录中。 | 没有配置 | path.repo |
| script | 脚本文件的位置 | $ES_HOME/scripts | path.scripts |
如何修改 logging 的配置
在通常的情况下,我们不需要做任何的修改,标准的 logging 就已经工作的很好。更改日志级别对于检查错误或了解由于配置错误或奇怪的插件行为而导致的故障很有用。 详细日志可以使用 Elasticsearch 社区来帮助解决此类问题。如果你需要调试 Elasticsearch 服务器或更改日志记录的工作方式(即远程发送事件),则需要更改 log4j2.properties 文件。这个文件位于 config 子目录下。
更改日志记录设置所需的步骤如下:
1)要发出 Elasticsearch 可能产生的每种日志记录,你可以更改当前的根级别日志记录,如下所示:
rootLogger.level = info2)这需要更改为以下内容:
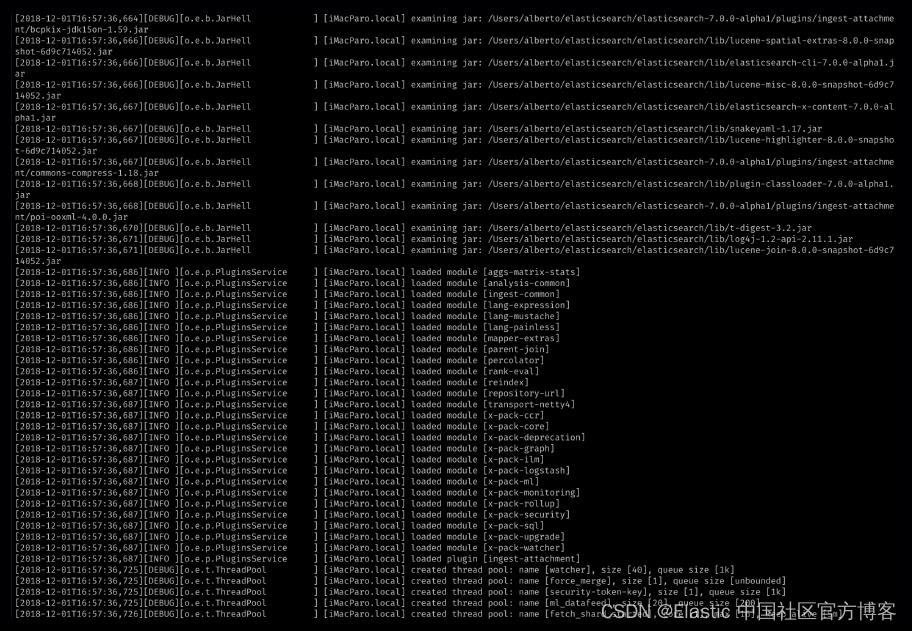
rootLogger.level = debug3)如果你从命令行启动 Elasticsearch(使用 bin/elasticsearch -f),你应该会看到很多信息,如下所示,这些信息并不总是有用(调试意外问题除外):
设置安全账户
如果我们在部署时,不希望我们的部署对所有的人使用。我们只希望对有账户的用户进行访问,那么我们可以对我们的 Elastic 进行设置安全。这个需要用到 x-pack 相关的功能。具体安装请参阅我的另外一篇文章 “Elasticsearch:设置 Elastic 账户安全”。
下一步
你现在已经设置了测试 Elasticsearch 环境。 在开始认真开发或使用 Elasticsearch 投入生产之前,你必须进行一些额外的设置:
- Learn how to configure Elasticsearch.
- Configure important Elasticsearch settings.
- Configure important system settings.
我们可以接下来安装 Kibana。Kibana 有一个 Web 界面。它可以帮助我们展示及分析我们的数据。同时也可以帮我们很方便地通过用户界面的方式来把我们的数据输入到 Elasticsearch 里的数据库中。请参阅文章:
如果你想在云上部署一个 Elastic 的集群,那么你可以阅读我一下的两篇文章:
Elastic Stack 简介及安装
参考:
【1】Past Releases of Elastic Stack Software | Elastic
以上是关于如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch的主要内容,如果未能解决你的问题,请参考以下文章