由 Elasticsearch 空间换时间的线上问题说开去......
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由 Elasticsearch 空间换时间的线上问题说开去......相关的知识,希望对你有一定的参考价值。
1、线上实战问题
请教一下各位朋友,关于 ngram 的 slop 影响搜索结果?
1、前置条件:
商品A的SPUCodeText为:OWBB050C99JER0021001
商品B的SPUCodeText为:VSA00293ABBLACKFW2022
商品C的SPUCodeText为:2WHGG0VNT03HHFC99FW2022
2、现况:搜索商品A的SPUCodeText编码:OWBB050,slop设置为49-54无法查询出该商品;slop设置为55及其以上的值,才可以查询出商品A;
3、追求目标:搜索SPUCodeText任意一组4个数字及其以上的组合,即可查询出该商品?
篇幅原因,省去了 DSL 定义和查询语句。
——题目来源:死磕Elasticsearch 知识星球https://t.zsxq.com/08rmVBnhA
2、问题释义
大前提:商品码的存储类似之前咱们视频讲过的手机号的存储,传统的分词器(默认的 standard、中文的 ik_max_word 等)都无法搞定。
需要借助于 Ngram 自定义分词实现。
那么问题来了:Ngram 分词后的数据,用 match_phrase + slop 检索出现了问题,必须 slop 设置很大才可以搞定!
什么原因导致的呢?有没有更为简洁的方法?
3、Elasticsearch 空间换时间
啥叫空间换时间,拿当下世界杯的例子一看就明白。
如下解说员说的:“15人才能打赢”。15人比正常的11人远多4人,这就是多了空间,而换取了时间或结果。当然,比赛事实远非解说员所说。

Elasticsearch 中 Ngram 分词本质就是空间换时间的方式,以极小的粒度切分文档,空间存储激增、写入速度会受到影响,但换来了检索效率的提升!
4、精简问题后的实现
PUT /products-001
"settings":
"max_ngram_diff": 40,
"analysis":
"analyzer":
"ruishan_ngram_analyzer":
"filter": [
"lowercase"
],
"type": "custom",
"tokenizer": "ruishan_ngram_tokenizer"
,
"tokenizer":
"ruishan_ngram_tokenizer":
"token_chars": [
"letter",
"digit"
],
"min_gram": 3,
"type": "ngram",
"max_gram": 40
,
"mappings":
"properties" :
"id" :
"type" : "keyword"
,
"sPUCodeText" :
"type" : "text",
"analyzer" : "ruishan_ngram_analyzer"
PUT products-001/_bulk
"index":"_id":1
"id":1,"sPUCodeText":"OWBB050C99JER0021001"
"index":"_id":2
"id":2,"sPUCodeText":"VSA00293ABBLACKFW2022"
"index":"_id":3
"id":3,"sPUCodeText":"2WHGG0VNT03HHFC99FW2022"
GET products-001/_search
"query":
"bool":
"must": [
"match":
"sPUCodeText":
"query": "OWBB050"
]
看如下结果,一个 match 就可以搞定了!
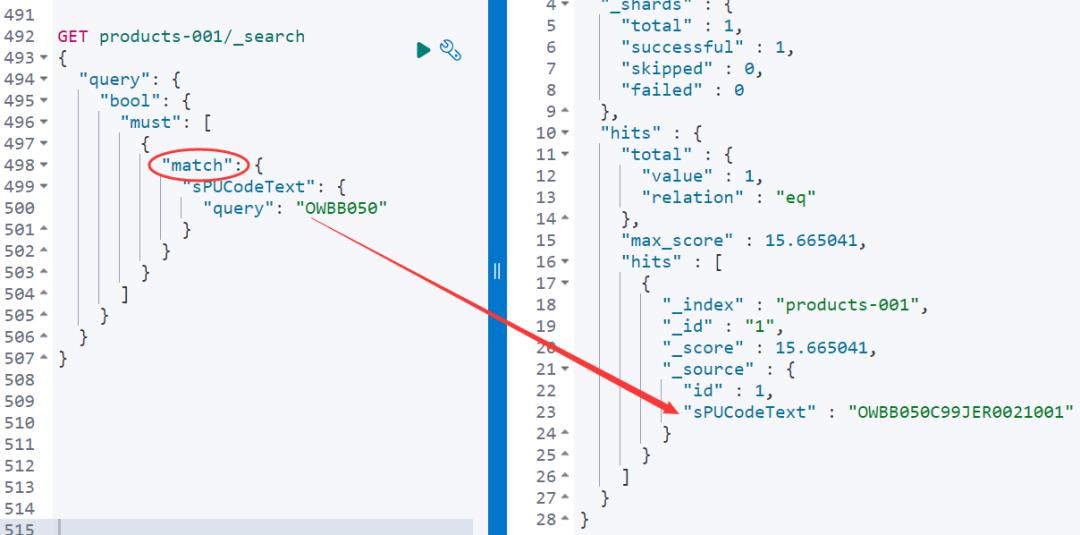
再来,match_phrase 可以不?
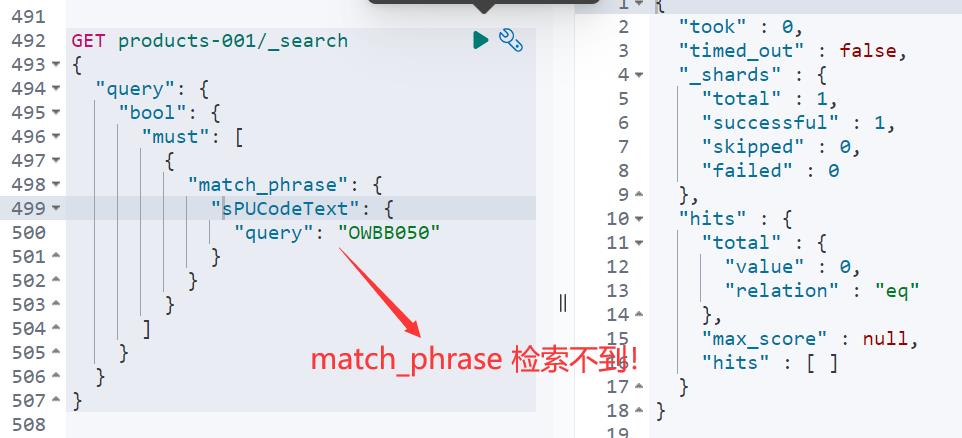
那么match_phrase 加上较大的 slop 呢?能搞定吗?!
经反复测验,需要slop 至少设置 52 才可以搞定,如下所示。
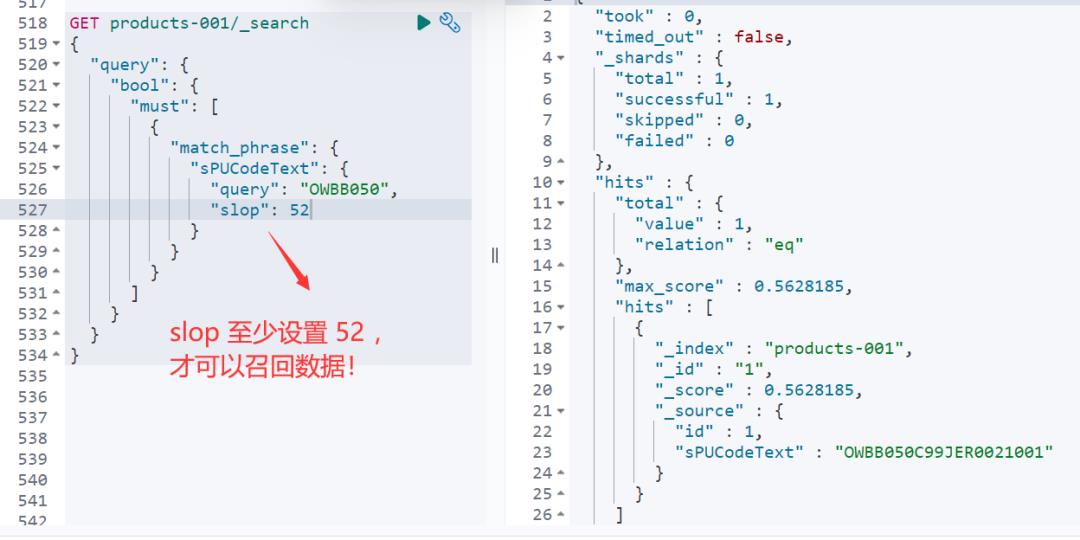
为什么呢?为什么是 52 呢?
5、match_phrase 短语匹配检索的本质?
通俗点说:query 部分待检索语句(如开篇:OWBB050)的分词结果要和文档(如:OWBB050C99JER0021001)中的分词结果顺序和位次完全一致才可以!
可以通过 analyzer api 查看分词结果,如下所示:
POST products-001/_analyze
"field": "sPUCodeText",
"text": ["OWBB050C99JER0021001"]

分词后的词项单元,“OWBB050”如下图左侧所示,“OWBB050C99JER0021001”如下图右侧所示。
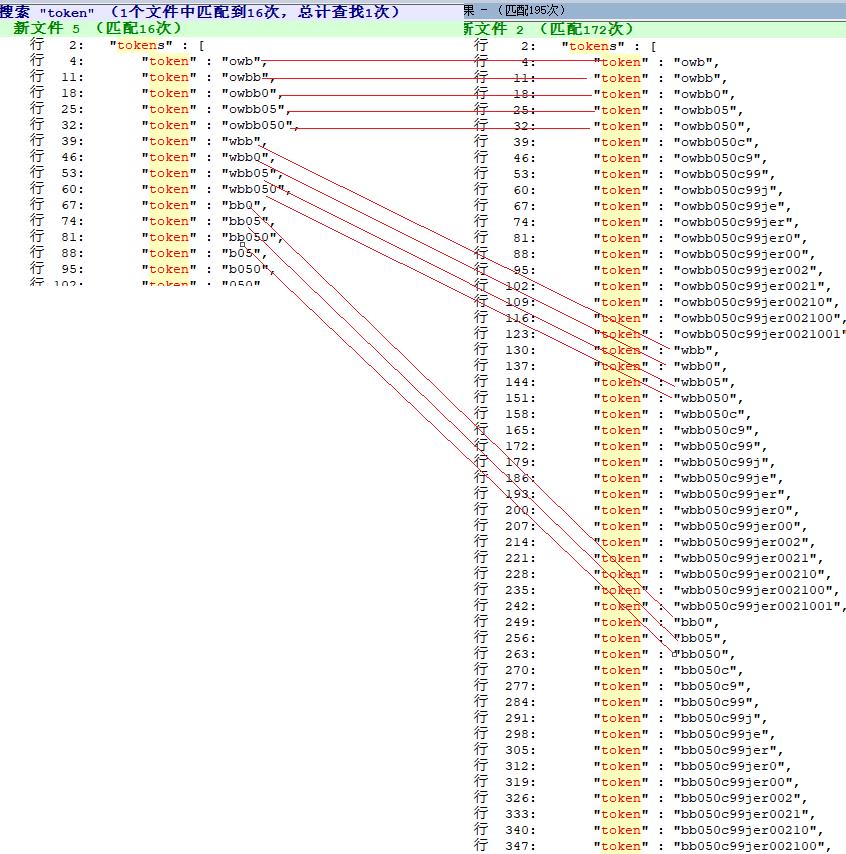
两者并不一致,这是导致无法匹配的原因,也就是有偏差!
6、match_phrase 短语检索下参数 slop 本质
一个图彻底搞明白!
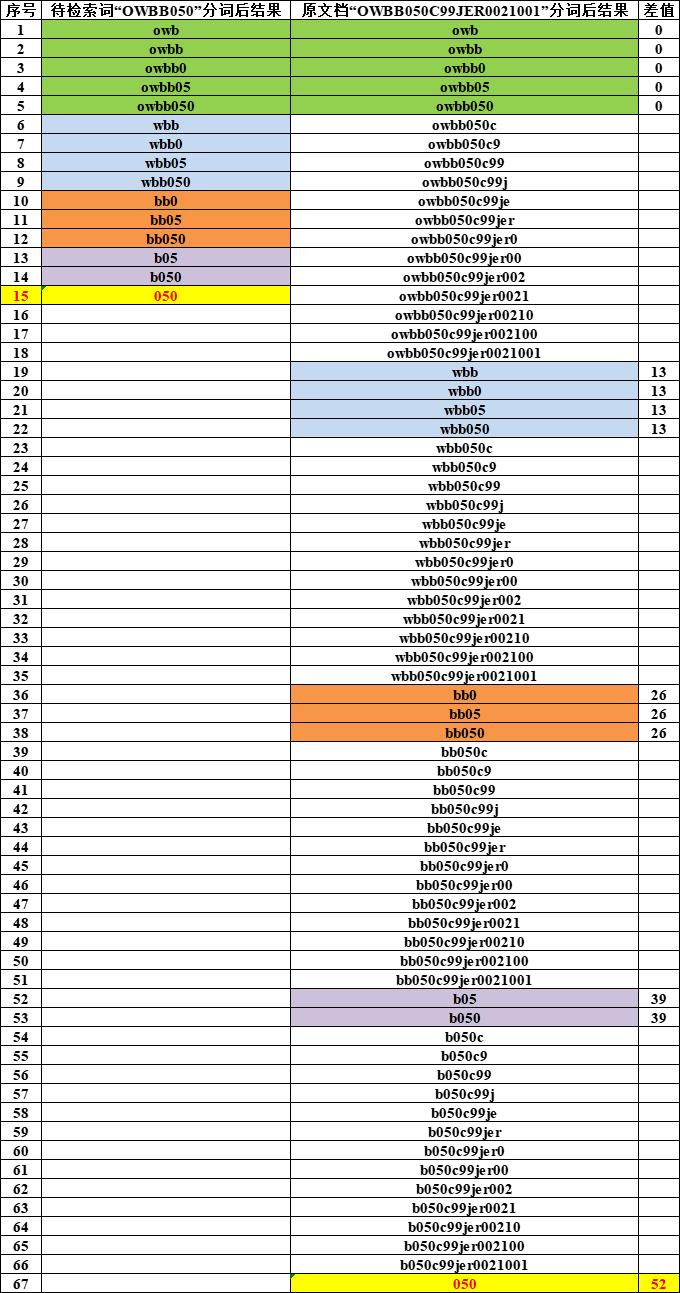
相同颜色代表:待检索词和源文档中分词结果一样的词项。
最大差值的计算方法,比如:分词后的词项“050”,在待检索词中位次为 15, 在源文档“OWBB050C99JER0021001”为67。
差了:67-15=52。
所以,slop 补齐这个最大的差值 52,就可以实现检索和数据的召回!
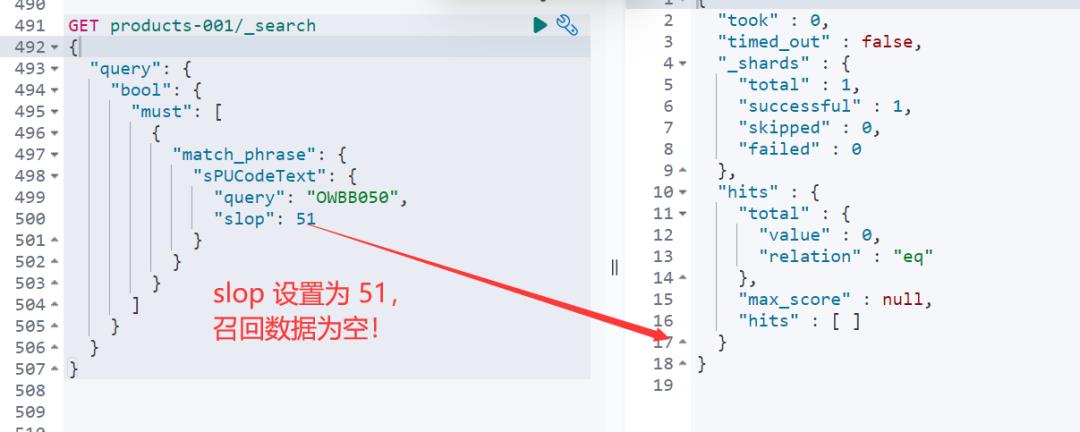
slop 设置为 51,就不可以!至少 52 或者52以上才可以召回数据。
7、小结
类似 Ngram 分词后,我们已经在空间层面下足了功夫!就没必要时间层面、检索层面下功夫了!
直接 match 检索必然能检索到结果!
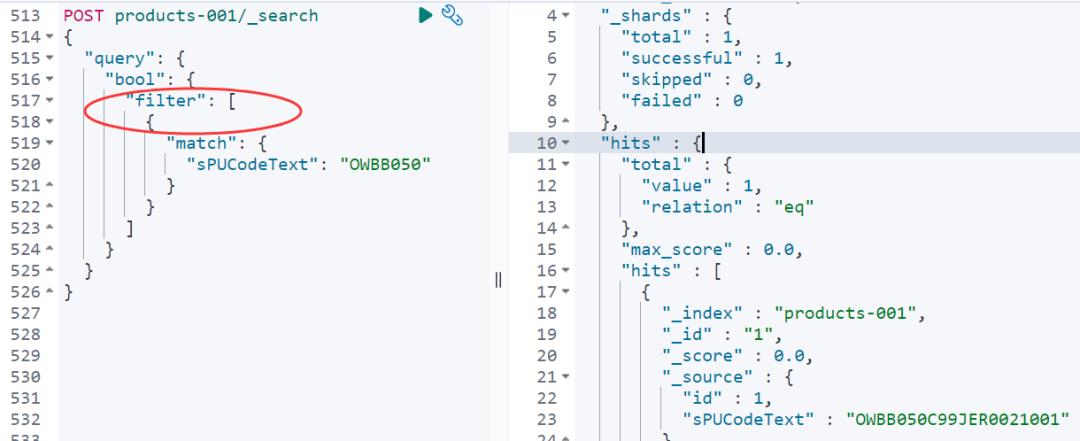
如上的写法 filter 是可以走缓存的,推荐使用。
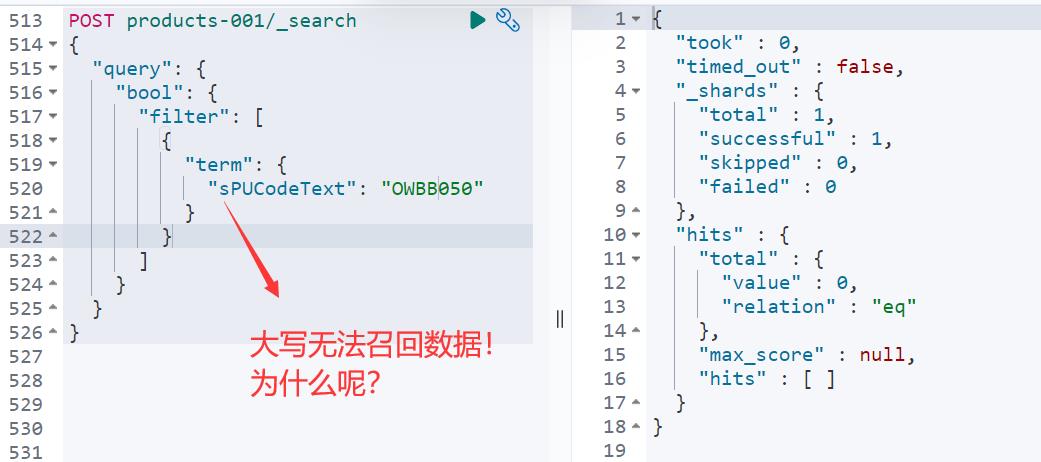
那,有没有更快的写法呢?
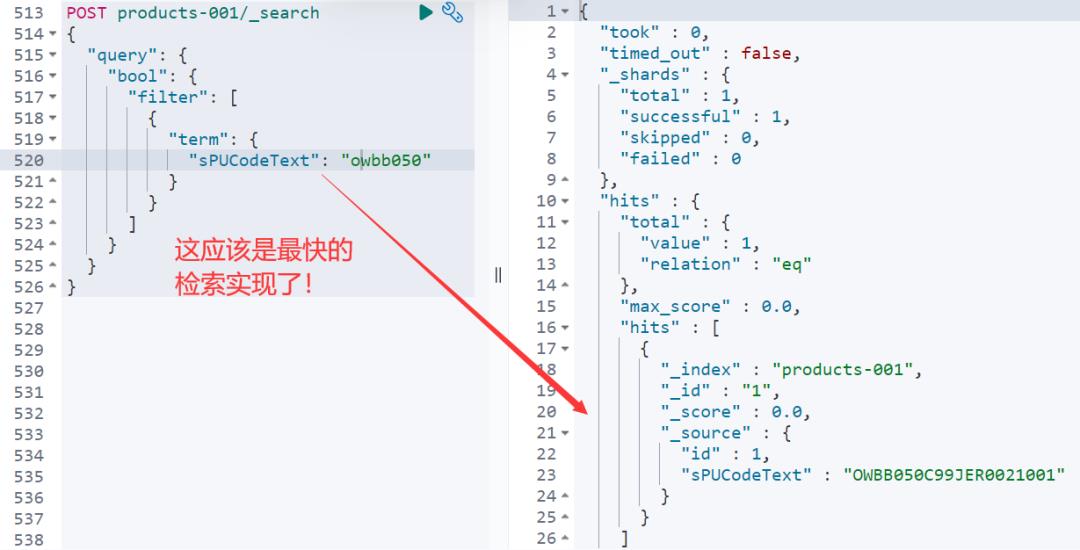
仔细的同学会发现,“OWBB05”都变成小写“owbb05”才可以召回数据,而直接大写直接 term 检索无法召回数据!
为什么呢?留给大家留言思考!
推荐阅读

更短时间更快习得更多干货!
和全球 1800+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
以上是关于由 Elasticsearch 空间换时间的线上问题说开去......的主要内容,如果未能解决你的问题,请参考以下文章