Kibana 最常见的“启动报错”或“无法连接ES集群服务”的故障原因及解决方案汇总
Posted Elastic开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kibana 最常见的“启动报错”或“无法连接ES集群服务”的故障原因及解决方案汇总相关的知识,希望对你有一定的参考价值。
1、引言
新手最常见的 Kibana 服务不可用的问题解答,此类问题如非有经验积累,可能耗费大量时间还不能解决,所以我特此整理了新手常见的 Kibana连不上集群或启动报错的问题及解决方案。
可能会有遗漏,如果你遇到的问题不在此列表,请私信提问,我会在此补充。
2、问题汇总
2.1 Kibana server is not ready yet
-
Kibana 服务正在启动中
解决方案:Kibana 启动需要一定时间,耐心等待 Kibana服务启动完成,这是最常见的原因。
-
Kibana 和 Elasticsearch 的版本不兼容。
问题描述,Kibana 和 Elasticsearch 需保证所用版本互相兼容。
解决方案:检查版本兼容性,参考:兼容性列表。
-
Elasticsearch 的服务地址和 Kibana 中配置的 elasticsearch.hosts 不匹配
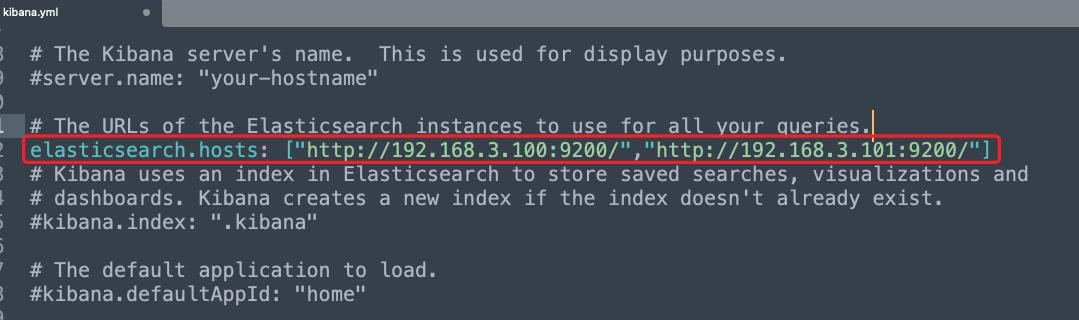
问题描述:如下图所示,Kibana 配置文件中配置的服务列表和实际启动集群中节点信息不一致,这里可以少配置,但是不能错误配置
解决方案:修改配置文件,保证配置文件中和集群服务的节点信息一致
-
Elasticsearch中禁止跨域访问
解决方案:在 ES 的服务节点中加入以下两行配置
http.cors.enabled: true http.cors.allow-origin: "*" -
Elasticsearch服务所在㐏磁盘剩余空间不足85%
问题描述:当服务器剩余磁盘空间不足 85% 的时候,ES会阻止数据的持续写入,可能会导致分片不可用。
解决方案:清理磁盘空间,保证剩余使用空间大于 15% -
ES 服务的健康状态异常
健康状态绿色:所有分片都可用
黄色:至少有一个副本不可用,但是所有主分片都可用
红色:至少有一个主分片不可用,数据不完整健康值检查
GET _cat/health GET _cluster/health -
节点未成功加入集群
问题描述:这是最常见的 Kibana 连不上ES集群服务的原因,即:集群服务不可用,这种情况有可能单独访问每个节点都是没问题的,但是通过
_cat/nodes输出集群节点信息就会报错。解决方案:删除每个节点的 data 目录(开发环境),重启每个节点
-
开启security之后,登录角色未配置kibana user角色,注意kibana system不行
问题描述:当开启 Serurity 之后,访问远程集群需要提供SSL证书,不管是集群之间通信还是客户端访问都是一样
解决方案:给 Kibana 配置Security功能,配置账户名密码,账户需要具有
kibana_user角色,而不是kibana_sysem或者kibana_admin
2.2 服务无法访问

-
防火墙阻止了指定端口的访问
关闭本地防火墙(CentOS 7):
//临时关闭 systemctl stop firewalld //禁止开机启动 systemctl disable firewalld云服务器关闭防火墙:
需要登录云服务器提供商后台管理系统,打开控制台,选择防火墙,开放指定端口
2.3 [.kibana] Action failed with ‘search_phase_execution_exception’. Retrying attempt 6 in 64 seconds.
解决方案:先检查集群状态是否正常,不仅仅是分片是否可用,还要检查集群是否选主成功。使用_cat/nodes查看每个节点是否的正常输出,如果不正常,课删除每个节点的data目录,重启每个节点服务。
2.4 Unable to retrieve version information from Elasticsearch nodes
报错是无法获取Elasticsearch集群的版本信息,原因有两种
- 集群服务不可用
- Kibana 权限不够
- Kibana 中 ES 集群服务地址配置错误
2.5 unable to complete saved object migrations for the [.kibana_task_manager] index.

由于Kibana的一些索引也是需要保存在ES集群中给的,造成此报错的原因大概率是 Kibana 无法将数据保存至急群中,可能的原因有以下几种
-
Kibana 当前运行实例登录的账号没有写入权限
解决办法:检查登录账号是否包含 kibana_user 的角色。或者是否通过 RBAC 限制了写入权限。此原因为小概率发生的事件
-
Elastc 集群健康状况异常,导致索引数据无法写入。
解决办法:首先检查集群健康状态,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CvXV4YEA-1650954718829)(/Users/wulei/Library/Application Support/typora-user-images/image-20220426134809076.png)]
可通过
_cat/health或_cluster/health检查,如果集群中包含未分配状态的分片,[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IVGYvl38-1650954718830)(/Users/wulei/Library/Application Support/typora-user-images/image-20220426134737460.png)]
可通过``GET _cluster/allocation/explain`查分片未分配原因
3、生产和开发环境的不同处理策略
针对开发环境删除data目录解决ES服务无法启动的方法,如遇生产环境如何解决?
提问
前提条件:已搭建好的es集群:
node1为主节点,node2是从节点,两者都没有设置node. roles角色,且在集群已存在数据分片
现象
现在修改集群配置node2为初始主节点
,并配置node1 node. roles为data和master,node2的角色为master,重启集群node1启动成功,node2节点启动时报错不允许启动,原因是已存在数据分片但又没有data角色,删除node2的数据后node2能启动成功
此时的问题是按配置node2为主节点没有问题,但是检查集群节点状况就只有一个node2,并为主节点,node1并没有加入到集群成为从节点,是什么原因呢?
解决:删除了node1的数据后重启node1,node1成功加入集群,但是生产应该不能这么操作,该怎么解决?
解答
首先生产环境是有严格的上线步骤的,不允许你随意启动和关闭服务以及随意修改配置文件,就比如你一开始啥都不配置启动集群,然后一个节点一个节点的修改配置文件单个节点重启这种行为肯定是不允许的。生产环境在对集群的任何修改之前都有详细的计划,包括数据的备份迁移以及事故发生后如何回滚。
一但生产环境出现上述问题,首先node1因为有旧的集群状态信息而导致无法加入集群,那么就需要登录node1所在集群删除其冲突数据,并做好业务数据的备份工作,然后重新启动节点加入新集群。集群状态信息有单独的索引保存,
以上是关于Kibana 最常见的“启动报错”或“无法连接ES集群服务”的故障原因及解决方案汇总的主要内容,如果未能解决你的问题,请参考以下文章