分类模型标签多少张合适呢
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分类模型标签多少张合适呢相关的知识,希望对你有一定的参考价值。
参考技术A 10张左右合适,Label smoothing,即标签平滑,是一种机器学习中的模型正则化方法。在分类模型中,通常的过程是提取特征之后,接一个全联接层,将输出映射到分类大小,之后再进行softmax,将结果映射到0-1之间,再同one-hot标签计算交叉熵损失函数来训练模型。而标签平滑其基于的出发点有两方面原因:1. 此外使用one-hot的表示,会促使模型逐渐向1靠近,从而表现的对于预测结果过于自信,而这种自信就会促使模型过拟合。
2. 在分类模型中,标签一般都是使用的one-hot向量表示,这种表示存在过拟合的风险。因为训练集中的训练数据往往是有限的,并不能真正表示出预测的结果的真实分布情况。
小白学习PyTorch教程十六在多标签分类任务上 微调BERT模型
@Author:Runsen
BERT模型在NLP各项任务中大杀四方,那么我们如何使用这一利器来为我们日常的NLP任务来服务呢?首先介绍使用BERT做文本多标签分类任务。
文本多标签分类是常见的NLP任务,文本介绍了如何使用Bert模型完成文本多标签分类,并给出了各自的步骤。
参考官方教程:https://pytorch.org/tutorials/intermediate/dynamic_quantization_bert_tutorial.html
复旦大学邱锡鹏老师课题组的研究论文《How to Fine-Tune BERT for Text Classification?》。
论文: https://arxiv.org/pdf/1905.05583.pdf
这篇论文的主要目的在于在文本分类任务上探索不同的BERT微调方法并提供一种通用的BERT微调解决方法。这篇论文从三种路线进行了探索:
- (1) BERT自身的微调策略,包括长文本处理、学习率、不同层的选择等方法;
- (2) 目标任务内、领域内及跨领域的进一步预训练BERT;
- (3) 多任务学习。微调后的BERT在七个英文数据集及搜狗中文数据集上取得了当前最优的结果。
作者的实现代码: https://github.com/xuyige/BERT4doc-Classification
数据集来源:https://www.kaggle.com/shivanandmn/multilabel-classification-dataset?select=train.csv
该数据集包含 6 个不同的标签(计算机科学、物理、数学、统计学、生物学、金融),以根据摘要和标题对研究论文进行分类。
标签列中的值 1 表示标签属于该标签。每个论文有多个标签为 1。
Bert模型加载
Transformer 为我们提供了一个基于 Transformer 的可以微调的预训练网络。
由于数据集是英文, 因此这里选择加载bert-base-uncased。
具体下载链接:https://huggingface.co/bert-base-uncased/tree/main
from transformers import BertTokenizerFast as BertTokenizer
# 直接下载很很慢,建议下载到文件夹中
# BERT_MODEL_NAME = "bert-base-uncased"
BERT_MODEL_NAME = "model/bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(BERT_MODEL_NAME)
微调BERT模型
bert微调就是在预训练模型bert的基础上只需更新后面几层的参数,这相对于从头开始训练可以节省大量时间,甚至可以提高性能,通常情况下在模型的训练过程中,我们也会更新bert的参数,这样模型的性能会更好。
微调BERT模型主要在D_out进行相关的改变,去除segment层,直接采用了字符输入,不再需要segment层。
下面是微调BERT的主要代码
class BertClassifier(nn.Module):
def __init__(self, num_labels: int, BERT_MODEL_NAME, freeze_bert=False):
super().__init__()
self.num_labels = num_labels
self.bert = BertModel.from_pretrained(BERT_MODEL_NAME)
# hidden size of BERT, hidden size of our classifier, and number of labels to classify
D_in, H, D_out = self.bert.config.hidden_size, 50, num_labels
# Instantiate an one-layer feed-forward classifier
self.classifier = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(D_in, H),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(H, D_out),
)
# loss
self.loss_func = nn.BCEWithLogitsLoss()
if freeze_bert:
print("freezing bert parameters")
for param in self.bert.parameters():
param.requires_grad = False
def forward(self, input_ids, attention_mask, labels=None):
outputs = self.bert(input_ids, attention_mask=attention_mask)
last_hidden_state_cls = outputs[0][:, 0, :]
logits = self.classifier(last_hidden_state_cls)
if labels is not None:
predictions = torch.sigmoid(logits)
loss = self.loss_func(
predictions.view(-1, self.num_labels), labels.view(-1, self.num_labels)
)
return loss
else:
return logits
其他
关于数据预处理,DataLoader等代码有点多,这里不一一列举,需要代码的在公众号回复:”bert“ 。
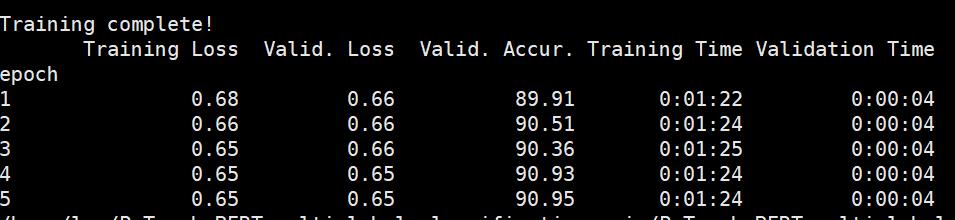
最后的训练结果如下所示:


以上是关于分类模型标签多少张合适呢的主要内容,如果未能解决你的问题,请参考以下文章