NLP 实战 | CSDN 在改进,2021我们做了什么?
Posted 幻灰龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP 实战 | CSDN 在改进,2021我们做了什么?相关的知识,希望对你有一定的参考价值。
CSDN 在改进,2021 CSDN AI 小组做了什么?AI 组通过提供智能数据服务,与多个团队合作,支撑产品功能改进和创新产品设计。我们结合NABCD(Need、Approach、Benefit、Competitors、Delivery)的方式来做一个复审,每个环节未必包含全部环节分析,主要从“需求”,“改进”,2个方面做一个客观描述。
统一标签
需求: 对技术数据的正确的统一分类,能打通底层数据之间的关联关系,解决数据的精确匹配等需求。历史上不同的板块有不同的标签体系,体系分类也不尽相同。统一标签并且对数据做足够覆盖度的分类是一个基础且重要的改进。
解决/改进:在体系构建和AI标签分类两个方面入手,为数据建立统一标签,支撑数据标签到用户兴趣标签的推荐。
- 从问答开始,建立统一标签,建立 统一标签开放编辑仓库 。先在问答内实现统一标签,再逐步扩展到博客、用户中心,逐步实现全站核心内容数据的标签统一。
- 从问答开始,针对问答的短文本、下载数据的超短文本、博客的长文本、专栏摘要数据、代码等不同类型的数据训练覆盖300-500个标签级别的标签分类器。在这个过程中我们解决海量数据清理的技术问题。
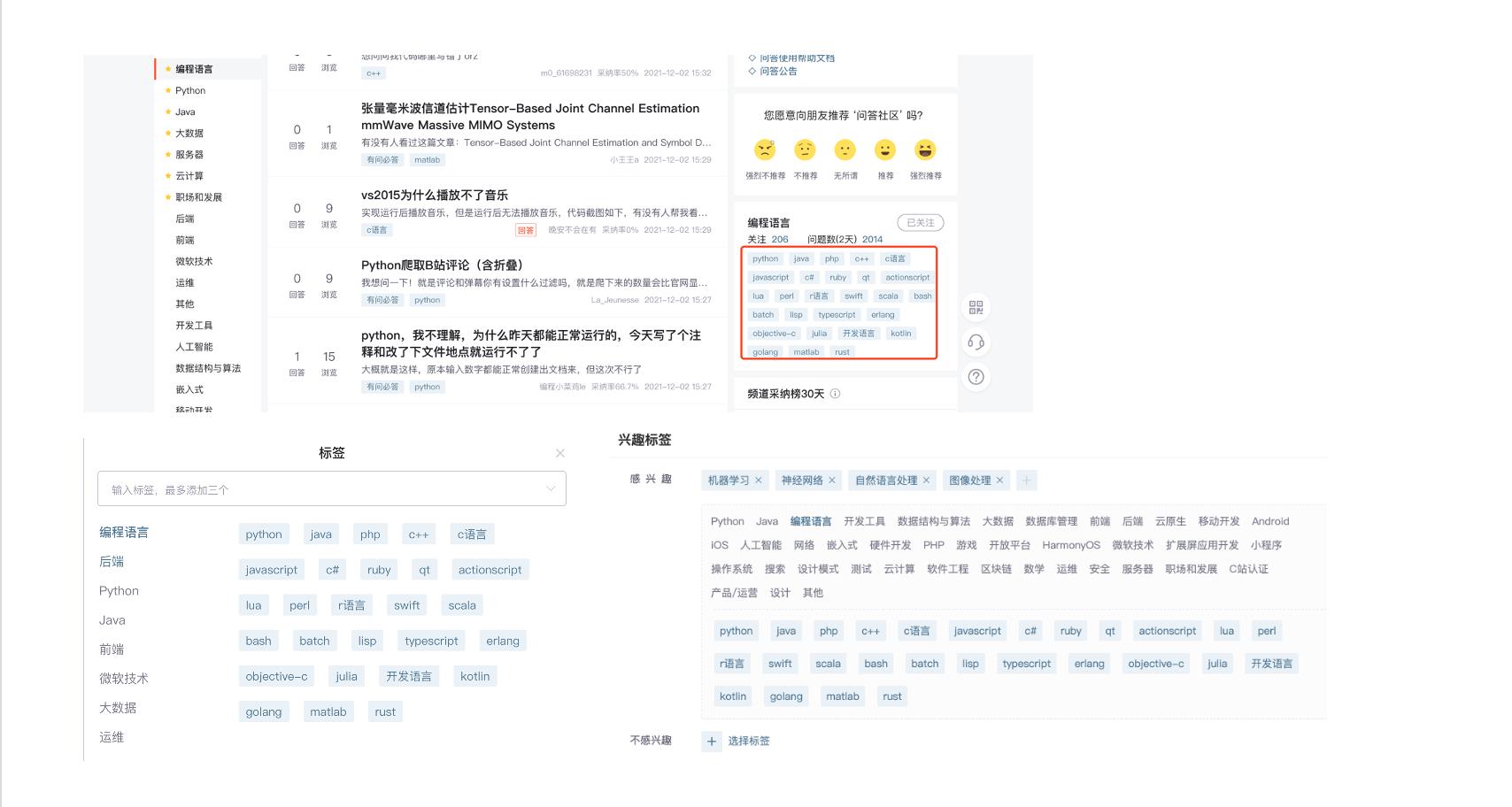
合作团队:AI/问答/搜索/分发推荐/博客/UC
问答AI助手/博文发文助手
需求:希望构建一流的问答,问答的内容质量能迭代到 stackoverflow 的内容质量水平。对于问答,提问/回答 是问题的两面。优质的回答离不开优质的提问。因此提升提问的内容质量就是一个必要的过程。存在的问题有:
- 标题质量不高,例如初期很多“救救孩子”,“大佬救救我”标题。
- 一些重复的已有回答的问题。
- 提问只有图片的时候,文本不利于回答者提取信息。
- 一些图片是翻转的,不利于阅读。
- 许多问题没有正确打上标签。
解决/改进:我们着手构建一组初步的智能服务,在问答提问入口(ask.csdn.net/new)提供一个AI助手。包含一组互相配合的功能。
- 标题优化建议,包含对禁词的判定,以及根据原标题和内容合成推荐标题的服务。
- 相似已采纳问题的推荐。如果目标问题在已采纳的问题里找到相似的问题,就推荐3个最接近的,希望减少重复问题创建。
- 提供图片优化功能,包含图片提取文本服务和图片一键判定翻转服务。
- 提供智能标签推荐。
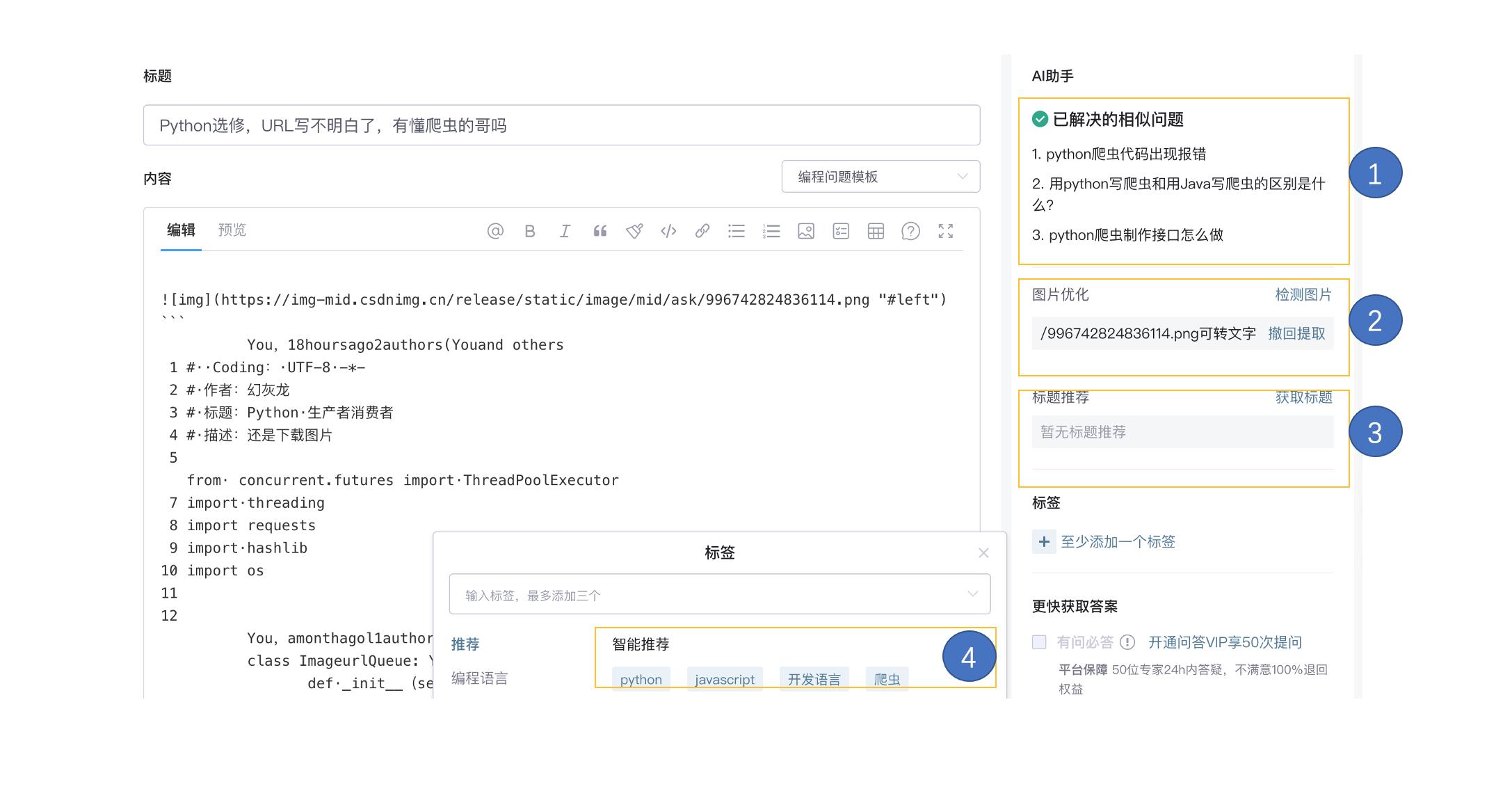
扩展:问答助手的基础上,通过类似的技术支持博文发文助手的标题优化、正文纠错、智能标签等功能。
合作团队:AI/问答/博客
每日一题数据服务
需求:解决技术学习者每天5-10分钟左右的碎片学习。
解决/改进:打卡是比较有效的点滴积累的方式。用户可能每天只有5-10分钟时间可以做一个碎片式的学习,但是如果能连续打卡积累,用一种轻学习的方式也会逐渐获得积累。每日一题提供了这样的一个学习场景,使用代码选择题的方式提供数据。每日一题数据服务核心能力:
- 题源:包含多种题源。
- 问答上很多用户提了问题,部分回答有直接的代码。来自真实学习过程中的问题。
- 算法题,例如leetcode题目等。
- 历史上的今天 的背景知识构成了一组“IT冷知识”的扩展视野的题源。
- 选项:结合算法和编辑。
- 人工编辑的选项。
- 通过算法替换合成的方式为每个题目提供4个选项。
合作团队:AI/App/主站/运营
技能树社区
需求:信息爆炸的时代,用户的学习是很碎片的。用户的一次搜索只会有一个具体的知识点。为用户构建从点到线到面的学习过程,在学习中有合适的反馈学习效果的方式,在学习中有可视化的进度跟踪,在学习中能跟同主题学习的人交流和讨论。CSDN 的海量数据应该为学习者带来这样的体验。这是最开始的内部讨论:以终为始 – 技能树的设计初心 (2021/6 版本)
解决/改进: 从6月份开始,AI组就在内部思考这些问题,并着手解决海量数据如何为学习者服务的问题。整个路径大概是这样的:
6月份:实验阶段。通过算法合成,构建了15棵有深度的领域技能树结构。并且把有采纳答案的问答数据挂载到树上。解决节点和挂载数据难度分类,解决相关性匹配算法问题。一开始长这样:

7月份:原型设计阶段。通过直接搭建原型,验证技能树模型的API完备性,实验一些技能树如何为用户提供学习服务的交互功能。并与产品做深度讨论交流。原型以随机信息流+详情页的方式展示,最开始长这样:
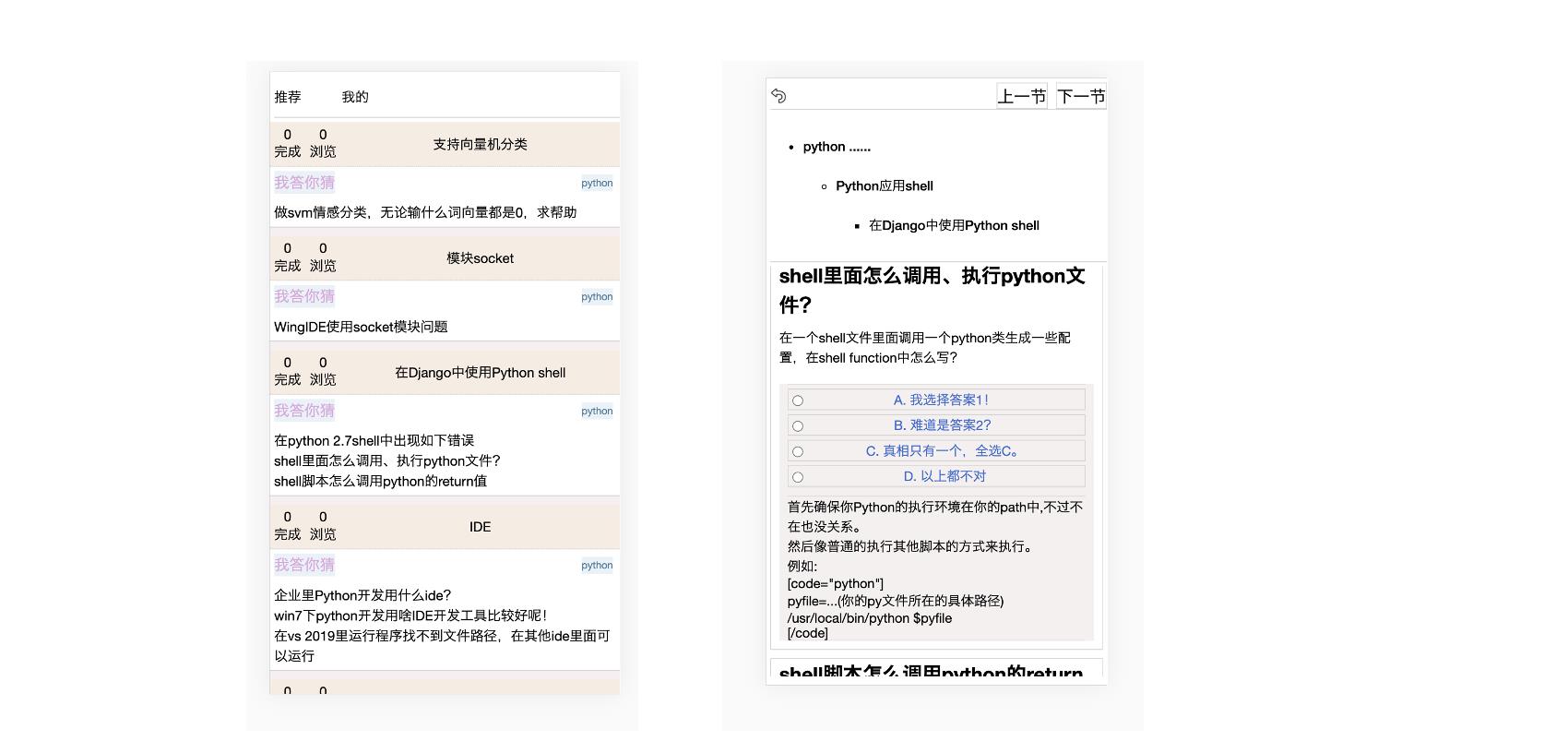
8月份: 技能树社区产品。有了社区云产品的加入,产品和UX进入后,开始正规的迭代过程。在这个过程中我们解决了产品的MVP迭代。核心解决的问题有:
- 产品上确定了技能树社区只展示 章/节 两层的视图。对应的技能树数据服务的整套api切成了完整技能树的基础接口和针对产品需要的视图层接口。
- 建立了技能树社区单一社区的原子操作:
- 创建一个知识点社区
- 初始化一个社区的参考资料、练习题、交流贴标准3频道
- 数据层通过对社区资源的原子操作在上线一个技能树社区之前吧技能树的骨架、知识点参考资料挂载、知识点习题挂载、知识点习题交流贴一键准备好。
- 在此技术上,完成技能树社区的构建和上线。技能树社区是社区SAAS化的一个MVP迭代。
实际上在这个过程中,有一个闭环问题需要解决,每个知识点必须要有习题,有了习题学习者才能有反馈(比尔盖茨说过:反馈能给教师的教学带来改进。何况学习者呢?技能树的答题会持续改进功能)。参考资料的匹配方面我们逐渐通过算法和数据解决的方式获得了解决,选项第1版本可以通过算法合成的方式解决。但是出题需要人来解决。我和AI组的小伙伴们支撑了这些出题数据:)
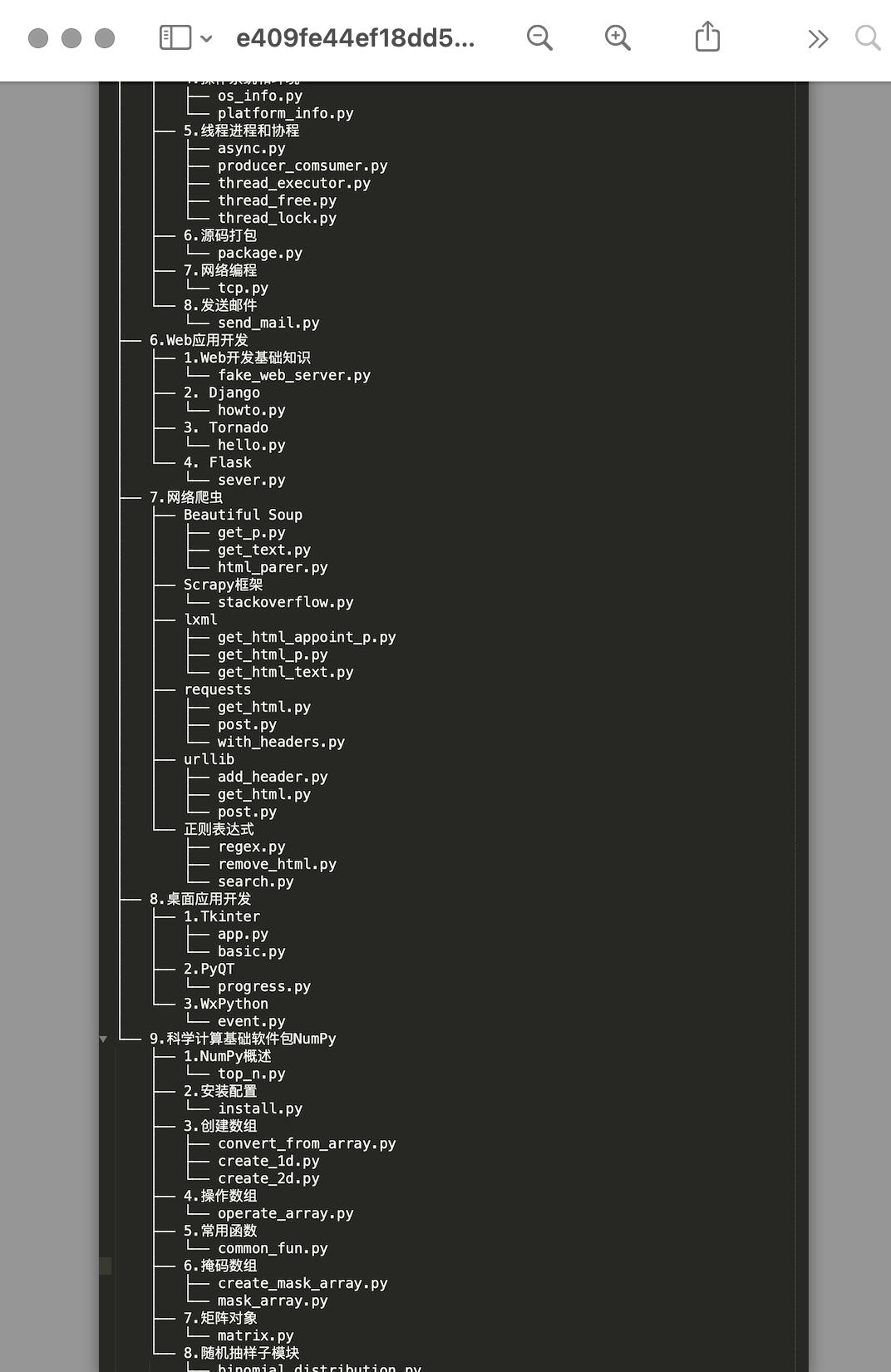
9月份:产品上线内测,用户反馈,改进数据质量(参考资料匹配和习题)。AI组和社区深度协作,迭代上线了 Python 技能树社区: python.csdn.net 。
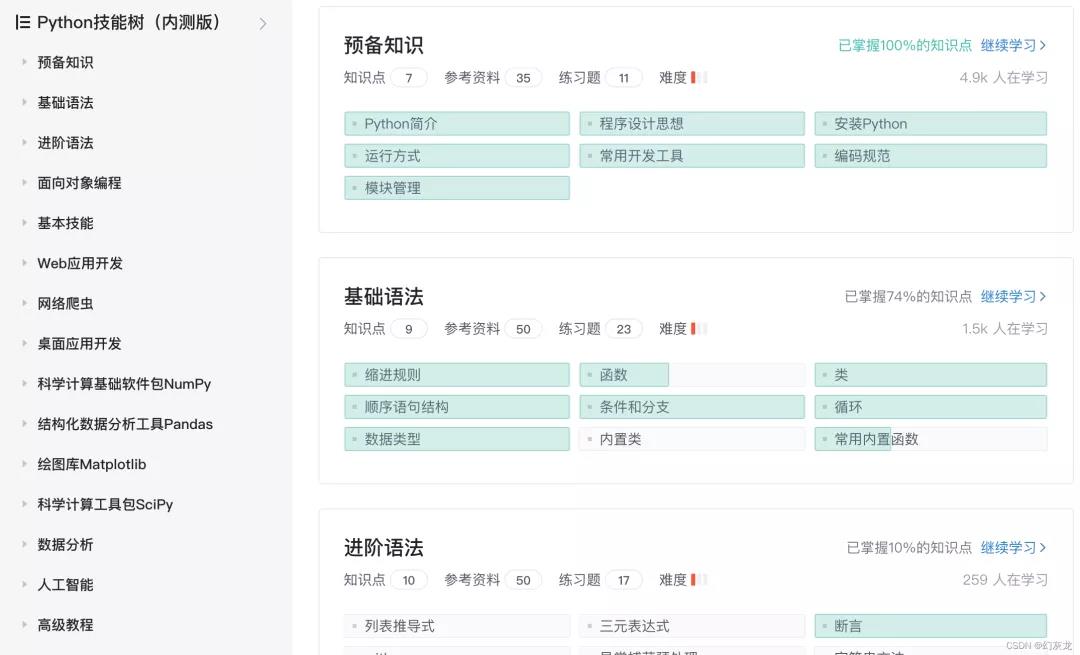
合作团队: AI/社区/App/主站/GitCode
技能森林,开放技能树编辑管道
需求:信息爆炸的时代,非结构化数据还是需要通过结构化才能有效的发挥它的价值。AI和知识图谱的结合是一个典型的做法。但是怎样有效做知识图谱,让它在实际产品中落地是一个需要考虑的地方。我们用树的形式组织数据,让“点的数据”被“树”结构化,这是一个有效的方式。但是怎样扩展呢?
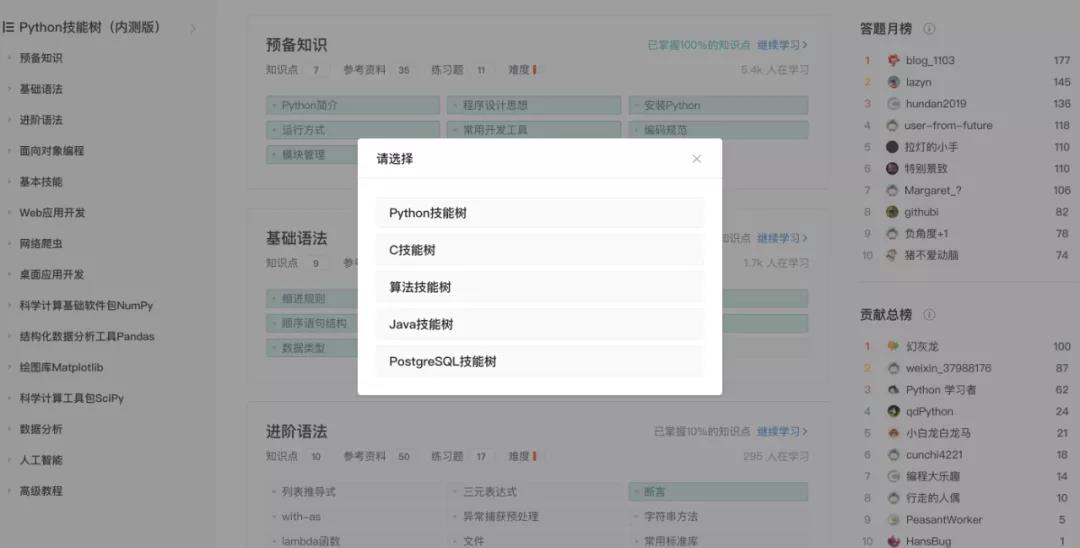
解决/改进:通过构建开放技能树编辑管道。我们在gitcode上创建了一组开放技能树编辑仓库,这些开放技能树编辑仓库使用 MIT 或者 CC4协议,通过开放技术社区的协作来共建 技能森林。

《技能森林:矩阵重启》:我们已发布了 Python、C、Java、算法,PostgreSQL 五大技能社区。集齐5棵技能树就能召唤神龙满足你一个愿望~
合作团队:CSDN-AI / Rust 社区/ OpenCV 社区/ PostgreSQL 社区/ OceanBase / .NET 社区
热榜改进
需求: CSDN 热榜有很多不同的需求。有用户的需求,也有平台的需求。用户的需求也分不同的类型,平台的需求也会分不同的类型。
解决/改进:结合现代的热榜算法和上述不同的需求持续迭代改进。接受用户的真实反馈,不断改进。参考:NLP 实战 (7) | 热榜算法更新
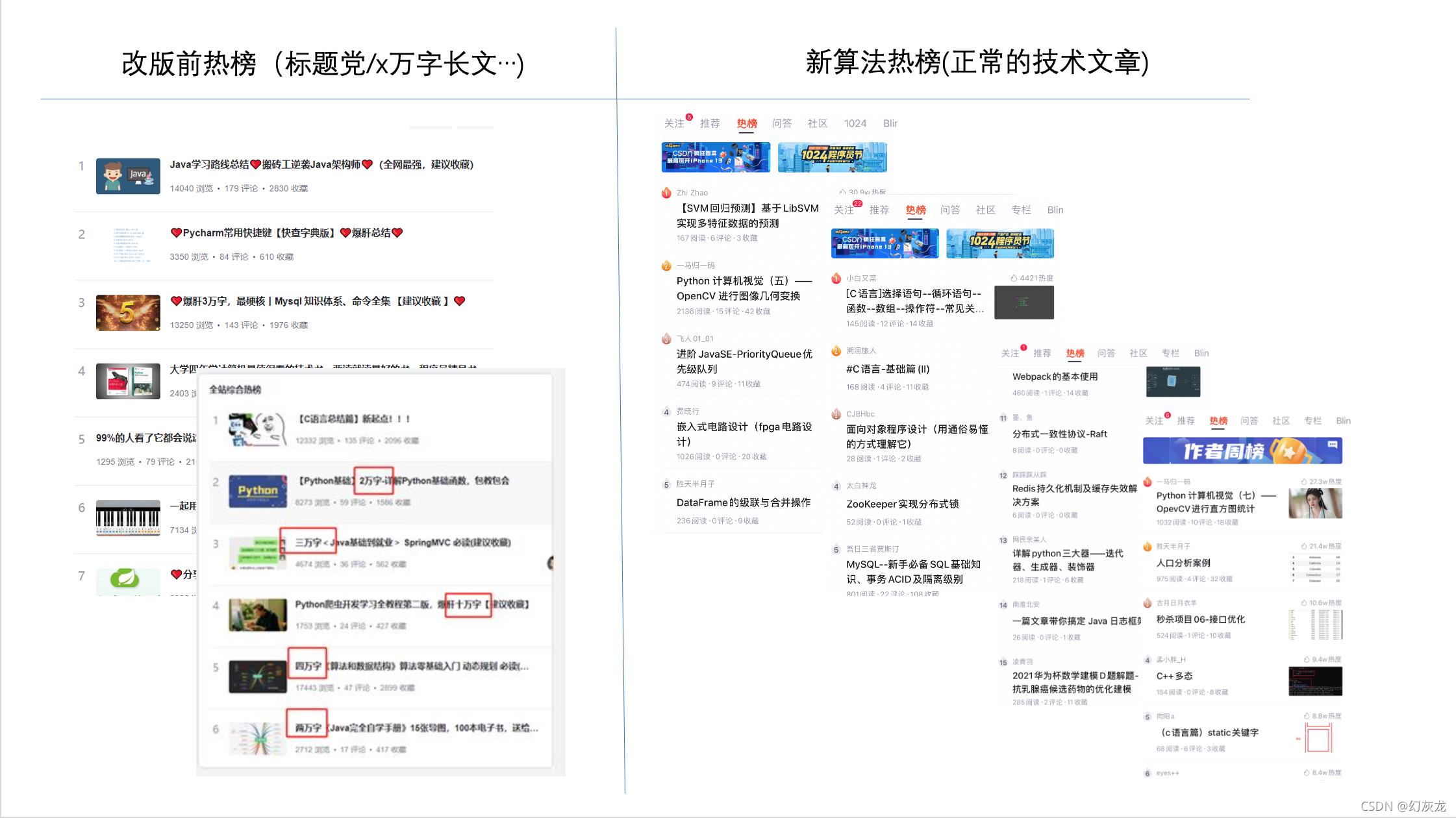
合作团队: AI/分发推荐
CSDN 指数
需求:技术的奇异点,需要看指数。
解决/改进:提供指数数据服务,支持产品迭代。CSDN指数
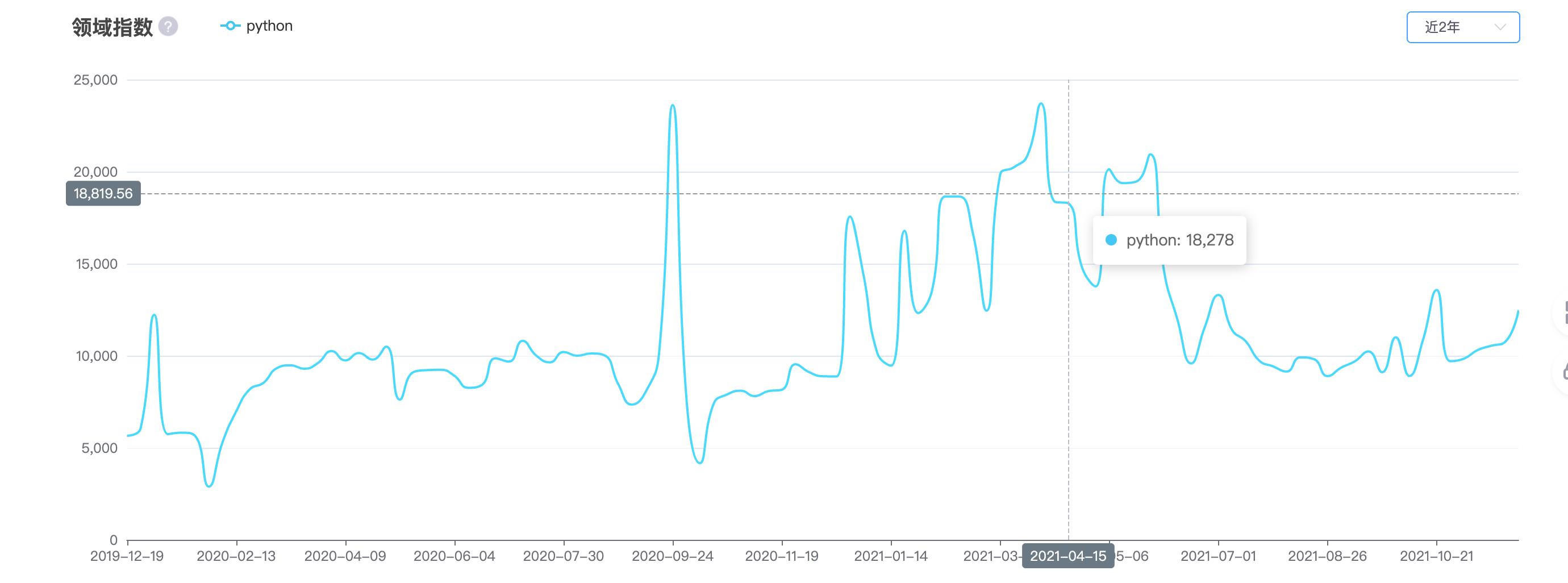
合作团队: AI/主站
反抄袭
需求:解决抄袭问题。
解决/改进:基于句库模型构建反抄袭服务。这部分服务还需要在应用上迭代。
内容质量
需求:搜索的结果,我们希望给用户返回的博文数据质量是优质的。需要剔除低质内容。
解决/改进:综合使用多种方式给数据质量打分。
-
标题质量分:基于规则对标题党类型的标题降低得分。
-
内容质量分:基于两种规则
- 计算内容的结构特征,计算基础得分。包含结构信息、代码圈复杂度信息等。这是一组基础得分,谨慎控制数据对结果的影响。
- 低质量特征惩罚,这部分可以放大惩罚:
- 链接 / 内容 占比过大
- 文本太短
- 图裂…
- …
这部分工作还在迭代中,只要原理是对的,通过持续迭代最终能有效改进数据的质量。
合作团队: AI/搜索/标注
小结
继续迭代。
–end–
以上是关于NLP 实战 | CSDN 在改进,2021我们做了什么?的主要内容,如果未能解决你的问题,请参考以下文章