XGBoost 极限提升树 (Extreme Gradient Boosting)
Posted Wing以一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XGBoost 极限提升树 (Extreme Gradient Boosting)相关的知识,希望对你有一定的参考价值。
XGBoost是一个以提升树为核心的算法系统,它覆盖了至少3+建树流程、10+损失函数,可以实现各种类型的梯度提升树。同时,XGBoost天生被设计成支持巨量数据,因此可以自由接入GPU/分布式/数据库等系统、还创新了众多工程上对传统提升算法进行加速的新方法。
【本文给对于XGBoost零基础de人,跟着完成所有实验,必有收获。后续会用实际算法竞赛题目来巩固(尽量不拖更)】
GBDT ? 如果你一无所知,请先看如下链接再开始XBGBoost。GBDT 梯度提升树(Gradient Boosting Decision Tree)(万字全解)_Wing以一的博客-CSDN博客
目录
一、XGBoost基本实现
1、基础思想
Boosting算法基本建模流程:
依据上一个弱评估器 的结果,计算损失函数
的结果,计算损失函数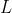 ,
,
使用自适应地影响下一个弱评估器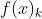 的构建。
的构建。
集成模型输出的结果,受到整体所有弱评估器 ~
~ 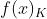 的影响。
的影响。
(1)经验风险和结构分析的平衡
树模型的学习能力与过拟合风险之间的平衡,就是预测精确性与模型复杂度之间的平衡,也是经验风险与结构风险之间的平衡。XGBoost中,每一次建树都会对精确性与复杂度之间进行衡量。
- 新的不纯度衡量指标,考虑复杂度
在上文的GBDT中,使用了弗里德曼均方误差friedman_mse来衡量叶子的不纯度,有丰富的剪枝参数可以选择,获得较高的精度。可是我们也在这个过程中建立了190棵树,深度为29,它的复杂度太高了。
XGBoost重新设定了分枝指标结构分数(Structure Score,也被称为质量分数Quality Score),以及基于结构分数的结构分数增益(Gain of structure score),结构分数增益可以使得决策树向整体结构更简单的方向生长。
- 目标函数中增加结构风险项
XGBoost为损失函数 加入结构风险项,构成目标函数
加入结构风险项,构成目标函数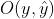 。
。
GBDT当中,我们的目标是找到损失函数的最小值,也就是让预测结果与真实结果差异最小,这一流程只关心精确性、不关心复杂度和过拟合情况。如果出现了过拟合,我们通过调节树结构相关的参数(例如`max_depth`,`min_impurity_decrease`)来限制过拟合。
XGBoost的目标是找到目标函数的最小值,会优先利用结构风险中的参数来控制过拟合。
(2)降低复杂度,提升模型运行速度,便于处理大体量的数据
使用估计贪婪算法、平行学习、分位数草图算法等方法构建了适用于大数据的全新建树流程。
使用感知缓存访问技术与核外计算技术,提升算法在硬件上的运算性能。
引入Dropout技术,为整体建树流程增加更多随机性、让算法适应更大数据。
2、程序实现(回归)

Python API Reference — xgboost 1.7.1 documentation文档里有所有你需要的。(以下截图均来自官网,图中已标注在官网的具体位置,可自己对应查看)
这里以先回归模型为例。
(1)读取数据
如果我们想要更快的运行速度,并后续在GPU说进行相关运行,我们就必须使用XGBoost自定义的数据结构DMatrix。DMatrix的结构一旦生成无法查看无法改动!数据预处理需要在转换为DMatrix之前完成。如果我们有划分训练集和测试集,则需要分别将训练集和测试集转换为DMatrix。
#一、读取数据
data = pd.read_csv(r"E:\\House Price\\train_encode.csv",index_col=0)
#回归数据
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
#转换数据格式
data_xgb = xgb.DMatrix(X,y)
#如果有分割训练集和测试集
from sklearn.model_selection import train_test_split
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=1409)
dtrain = xgb.DMatrix(Xtrain,Ytrain)
dtest = xgb.DMatrix(Xtest,Ytest)(2)设置参数
#二、设置参数
params = "max_depth":5,"seed":1409 #通常param字典中包含较多参数除了建树棵树、提前停止这两个关键元素,其他参数基本都被设置在params当中。
(3)训练模型
#三、训练模型
reg = xgb.train(params, data_xgb, num_boost_round=100)(4)预测结果
#四、预测结果
y_pred = reg.predict(data_xgb)
print(y_pred)
#用RMSE进行评估
print(MSE(y,y_pred,squared=False))#RMSE(5)使用交叉验证进行训练
xgb.cv()进行训练并不会返回模型!!
#用交叉验证进行训练
params = "max_depth":5,"seed":1409
result = xgb.cv(params,data_xgb,num_boost_round=100
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1409 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
print(result)每一行代表了每次迭代后进行交叉验证的结果的均值。 这样的数据集十分适合绘图展示。
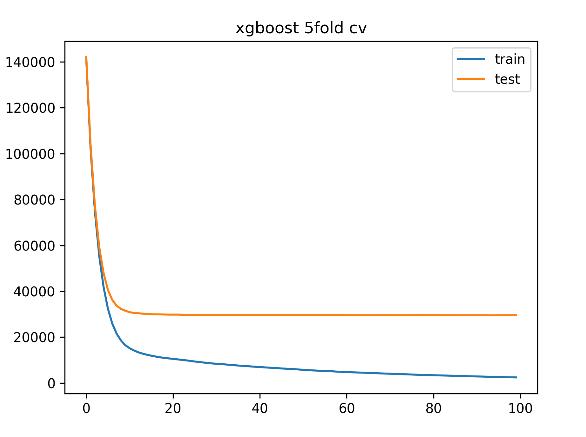
3、程序实现(分类)
XGBoost默认实现回归算法,如果要执行分类需要主动声明。在params中填写objective参数,xgboost会根据所使用的损失函数来判断任务类型。
(1)`objective`参数的选择
- 用于回归
reg:squarederror:平方损失,即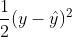 ,其中1/2是为了计算简便
,其中1/2是为了计算简便
reg:squaredlogerror:平方对数损失,即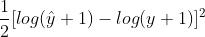 ,其中1/2是为了计算简便
,其中1/2是为了计算简便
- 用于分类
binary:logistic:二分类交叉熵损失,使用该损失时`predict`接口输出概率。
binary:logitraw:二分类交叉熵损失,使用该损失时`predict`接输出执行sigmoid变化之前的值。
multi:softmax:多分类交叉熵损失,使用该损失时`predict`接口输出具体的类别。
multi:softprob:多分类交叉熵,适用该损失时`predict`接口输出每个样本每个类别下的概率。
- 用于排序
rank:pairwise:采用评分机制进行训练
……
(2)读取数据
#一、读取数据
#导入2个分类数据集:乳腺癌数据集与手写数字数据集
from sklearn.datasets import load_breast_cancer, load_digits
#二分类数据
X_binary = load_breast_cancer().data
y_binary = load_breast_cancer().target
data_binary = xgb.DMatrix(X_binary,y_binary)
#多分类数据
X_multi = load_digits().data
y_multi = load_digits().target
data_multi = xgb.DMatrix(X_multi, y_multi)(3)设置参数
#二、设置参数
params1 = "seed":1409, "objective":"binary:logistic"
,"eval_metric":"logloss" #二分类交叉熵损失
#二分类直接返回概率,不返回类别
params2 = "seed":1409, "objective":"multi:softmax"
,"eval_metric":"mlogloss" #多分类交叉熵损失
,"num_class":10
#多分类,选择`multi:softmax`时返回具体类别,也可以选择`multi:softprob`返回概率。(4)训练模型
#三、训练模型
clf_binary = xgb.train(params1, data_binary, num_boost_round=100)
clf_multi = xgb.train(params2, data_multi, num_boost_round=100)(5)预测结果与转换
#四、预测结果
y_pred_binary = clf_binary.predict(data_binary)
#print(y_pred_binary)
y_pred_multi = clf_multi.predict(data_multi)
print(y_pred_multi )
#预测返回概率后的进一步处理
#二分类转换为类别
y_pred_binary_exchange = (y_pred_binary > 0.5).astype("int")
print(y_pred_binary_exchange)
#二分类计算准确率
ACC_binary= ACC(y_binary,(y_pred_binary > 0.5).astype(int))
print(ACC_binary)
ACC_multi = ACC(y_multi, y_pred_multi)
print(ACC_multi)(6)交叉验证
params2 = "seed":1409
, "objective":"multi:softmax"
, "num_class":10
result = xgb.cv(params2,data_multi,num_boost_round=100
,metrics = ("mlogloss") #交叉验证的评估指标
,nfold=5
,seed=1409
)
print(result)二、XGBoost参数详解
XGBoost原始论文:https://arxiv.org/pdf/1603.02754v1.pdf
1、用于迭代过程的参数
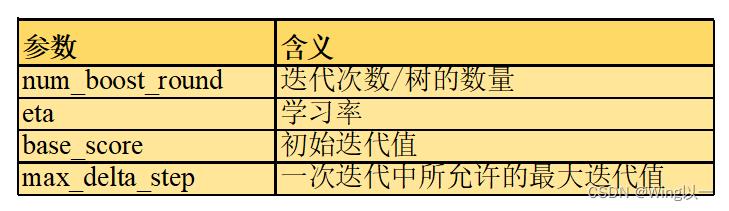
对于样本 ,集成算法当中一共有
,集成算法当中一共有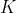 棵树,则参数`num_boost_round`的取值为K。假设现在正在建立第
棵树,则参数`num_boost_round`的取值为K。假设现在正在建立第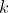 个弱评估器,则第个弱评估器上的结果可以表示为
个弱评估器,则第个弱评估器上的结果可以表示为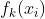 。假设整个Boosting算法对样本输出的结果为
。假设整个Boosting算法对样本输出的结果为 ,则该结果一般可以被表示为k=1~k=K过程当中,所有弱评估器结果的加权求和(XGBoost算法不计算树权重,故去除权重项):
,则该结果一般可以被表示为k=1~k=K过程当中,所有弱评估器结果的加权求和(XGBoost算法不计算树权重,故去除权重项):

对于第k次迭代来说,则有:
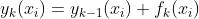
将本轮建好的决策树加入之前的建树结果时,可以增加参数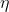 ,表示为第k棵树加入整体集成算法时的学习率(参数eta)
,表示为第k棵树加入整体集成算法时的学习率(参数eta)
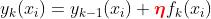
在XGBoost当中,`num_boost_round`的默认值为10,`eta`的默认值为0.3。我们需要在这两者之间作出调整权衡。eta较大则控制 的增长速度较快,可能在更少的num_boost_round就停止了训练。
的增长速度较快,可能在更少的num_boost_round就停止了训练。
建立第一个弱评估器时有:
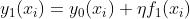
没有第0棵树的,因此 的值在数学过程及算法具体实现过程中都需要进行单独的确定,而这个值就由`base_score`确定。`base_score`可以为任何数值,但不同于之前的GBDT,无法将随机森林这样的评估器作为(在迭代次数和数据量都充足的情况下,一般不调整此参数)。
的值在数学过程及算法具体实现过程中都需要进行单独的确定,而这个值就由`base_score`确定。`base_score`可以为任何数值,但不同于之前的GBDT,无法将随机森林这样的评估器作为(在迭代次数和数据量都充足的情况下,一般不调整此参数)。
`max_delta_step`参数代表了每次迭代时被允许的最大 。被设置为0,则说明不对每次迭代的大小做限制,如果该参数被设置为正数C,则代表
。被设置为0,则说明不对每次迭代的大小做限制,如果该参数被设置为正数C,则代表 ,否则执行:
,否则执行: 。(样本极度不均衡可以试着调一调,通常不改动)
。(样本极度不均衡可以试着调一调,通常不改动)
2、结构风险相关参数

xgboost向着令目标函数最小化的方向运行。在XGBoost的定义中,目标函数是针对每一棵树的,而不是针对一个样本或整个算法
对任意树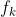 来说,目标函数有两个组成部分,一部分是任意可微的损失函数,它控制模型的经验风险。从数值上它等于现在树上所有样本上损失函数之和,其中单一样本的损失为
来说,目标函数有两个组成部分,一部分是任意可微的损失函数,它控制模型的经验风险。从数值上它等于现在树上所有样本上损失函数之和,其中单一样本的损失为 。另一部分是控制模型复杂度的
。另一部分是控制模型复杂度的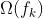 ,它控制当前树的结构风险。
,它控制当前树的结构风险。
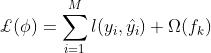
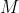 表示现在这棵树上一共使用了M个样本,
表示现在这棵树上一共使用了M个样本, 表示单一样本的损失函数。当模型迭代完毕之后,最后一棵树上的目标函数就是整个XGBoost算法的目标函数。
表示单一样本的损失函数。当模型迭代完毕之后,最后一棵树上的目标函数就是整个XGBoost算法的目标函数。
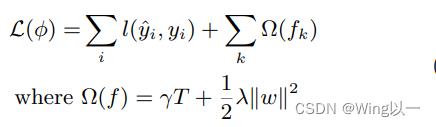
结构风险又由两部分组成,一部分是控制树结构的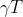 ,另一部分则是正则项:
,另一部分则是正则项:
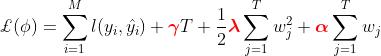
可以自由设置的这三个系数都与结构风险有关,这三个系数也正对应着xgboost中的三个参数:`gamma`,`alpha`与`lambda`。
这三个参数如果调大的话,均可以达到控制过拟合的效果。
`gamma`:乘在一棵树的叶子总量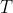 之前,依照叶子总量对目标函数施加惩罚的系数,默认值为0,可填写任何[0, ∞]之间的数字。
之前,依照叶子总量对目标函数施加惩罚的系数,默认值为0,可填写任何[0, ∞]之间的数字。
`alpha`与`lambda`:乘在正则项之前,依照叶子权重的大小对目标函数施加惩罚的系数,也就是正则项系数。`lambda`的默认值为1,`alpha`的默认值为0,在原论文中是使用了L2正则化。
在实际调参过程中,这三个没有上限的参数,必须关注它们的敏感度问题。(若轻微的参数变化对模型产生较大的影响,则称这个参数敏感)。
当树的结构十分复杂的情况下,叶子总量T是一个很大的值(1000000),对应的参数gamma轻微的变化就会对模型产生较大的影响。这个时候如果原始标签的数值很小(0-1),`lambda`和`alpha`就不敏感了,因为这个参数要到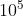 以上,才能对模型产生可见的影响。
以上,才能对模型产生可见的影响。
反之,`lambda`和`alpha`就会敏感。
这三个参数敏感度的实验代码在文末链接下载,此处不作展示。
3、弱评估器及相关参数
参数`booster`:使用哪种弱评估器。 可以输入"gbtree"、"gblinear"或者"dart"。每一种弱评估器都有自己的params列表。
- "gbtree":使用遵循XGBoost规则的CART树,又被称为“XGBoost独有树”,XGBoost Unique Tree。
- "dart":使用抛弃提升树,DART(Dropout Multiple Additive Regression Tree)在建树过程中会随机抛弃一些树的结果,可以更好地防止过拟合。在数据量巨大、过拟合容易产生时经常被使用,但可能会伤害模型的学习能力,同时可能会需要更长的迭代时间。
- "gblinear":使用线性模型,当弱评估器类型是"gblinear"而损失函数是MSE时,表示使用xgboost方法来集成线性回归。当弱评估器类型是"gblinear"而损失函数是交叉熵损失时,则代表使用xgboost来集成逻辑回归。
(1) dart
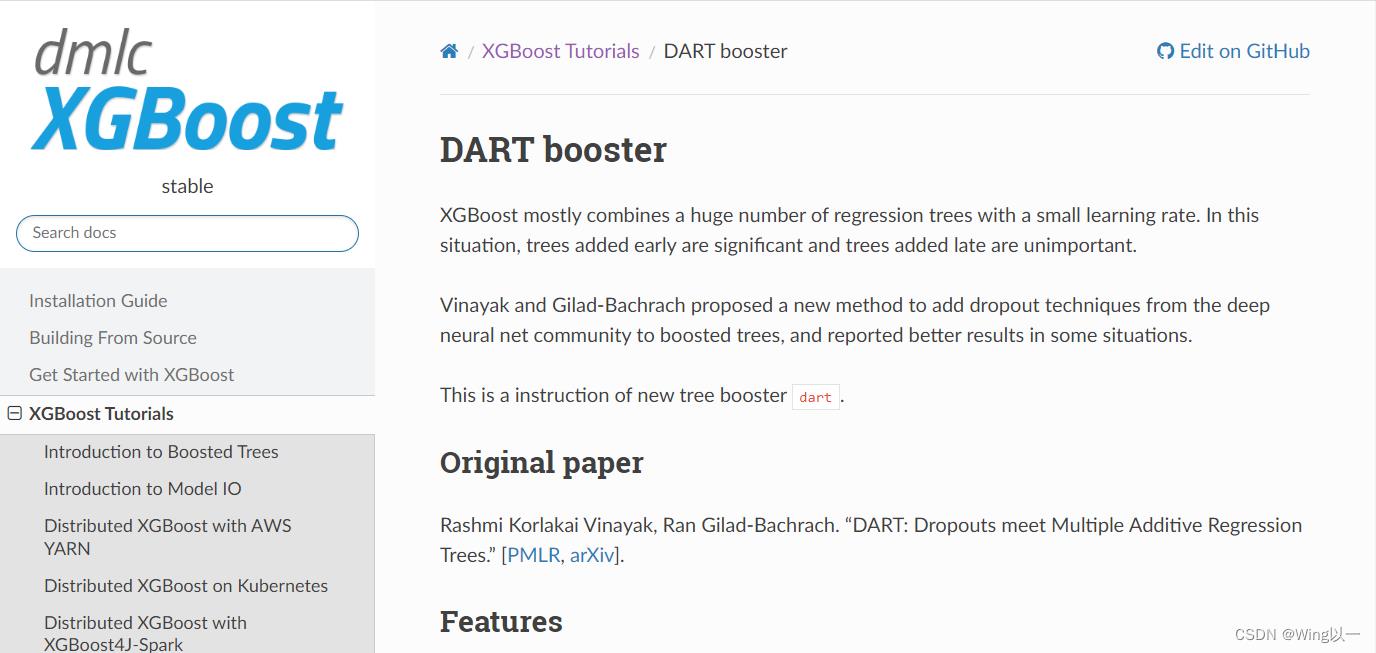
原始论文:https://arxiv.org/abs/1505.01866
DART树在
每一次迭代前都会随机地抛弃部份树,即不让这些树参与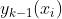 的计算,这种随机放弃的方式被叫做“Dropout”。因为是随机抛弃的,它就可以削弱前端树(刚开始迭代,效果明显的树)的影响力,大幅提升抗过拟合的能力。
的计算,这种随机放弃的方式被叫做“Dropout”。因为是随机抛弃的,它就可以削弱前端树(刚开始迭代,效果明显的树)的影响力,大幅提升抗过拟合的能力。
举个栗子:假如我们已经建立了四棵树如下
| k = 1 | k = 2 | k = 3 | k =4 | |
| 1 | 0.9 | 0.8 | 0.6 |
建立第5棵树的时候 = 1+0.9+0.8+0.6
采用dart的方法随机抛弃一棵的话可能= 1+0.9+0.6
通过对的影响,影响了迭代的目标函数,影响下一次迭代结果。

rate_drop和one_drop同时设定时,实际执行时取较大的。
sample_type中"uniform":表示均匀不放回抽样;"weighted":表示按照每棵树的权重(整棵树上所有叶子权重之和)进行有权重的不放回抽样。
注意,该不放回是指在一次迭代中不放回。每一次迭代中的抛弃是相互独立的,因此每一次抛弃都是从所有树中进行抛弃。上一轮迭代中被抛弃的树在下一轮迭代中可能被包括。
normalize_type中"tree"(默认),表示新生成的树的权重等于所有被抛弃的树的权重的均值;"forest",表示新生成的树的权重等于所有被抛弃的树的权重之和。
dart实验的相关代码,见文末链接。py文件已清楚注释,此处不作展示。
dart在对抗过拟合方面有较好的效果,但这是以降低模型学习能力为代价的。
(2)gbtree
CART树:向着叶子质量提升/不纯度下降的方向分枝、并且每一层都是二叉树。
XGBoost只有一个自定的分枝指标:结构分数(Structure Score)与结构分数增益(Gain of Structure Score)(也被叫做结构分数之差),更大程度地保证了CART树向减小目标函数的方向生长。

以上是原论文中的一些标注。
结构分数增益Gain = 左节点的结构分数 + 右节点的结构分数 - 父节点的结构分数
(不同于之前的GBDT,无论不纯度衡量指标是基尼系数还是信息熵,随着树的逐步建立,不纯度是逐渐降低的,我们按照不纯度变化最大来进行分支)
在树生长的过程中,选择Gain最大的点进行分枝。(结构分数增益越大,分支结果越好)
(信息熵、基尼系数只评估某一个特定节点如果左右节点一个为1一个为5,我们可以说左节点更好;但结构分数只能够评估结构本身的优劣,无论左右节点结构分数哪个更大都不能评估左右节点的优劣。)
原论文中上图公式6利用一棵树上所有叶子的结构分数之和来评估整棵树的结构的优劣。
(3)剪枝

min_child_weight:是任意节点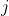 上所允许的最小的
上所允许的最小的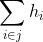 值。如果一个节点上的小于该参数中设置的值,该节点就会被剪枝。min_child_weight越大越不容易过拟合,但学习能力越弱。
值。如果一个节点上的小于该参数中设置的值,该节点就会被剪枝。min_child_weight越大越不容易过拟合,但学习能力越弱。
看看在原始论文中标注的结构分数的分母:

如果损失函数为 则求二阶导后,任意样本的
则求二阶导后,任意样本的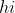 都是1,求和后就就是该叶子节点上的样本总量。
都是1,求和后就就是该叶子节点上的样本总量。
gamma:在目标函数中是叶子数量T前的系数,放大gamma可以将目标函数的重点转移至结构风险,从而控制过拟合。
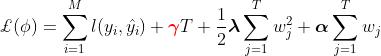
结构分数增益:
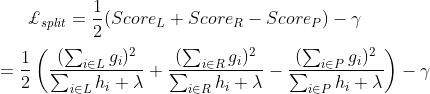
XGBoost中任意结构的分数增益不能为负,任意增益为负的节点都会被剪枝.
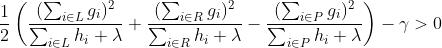
gamma越大越不容易过拟合,但学习能力越弱。
lambda和alpha:正则化系数,同时也位于结构分数中不同位置,间接影响树的生长和分枝。
使用L2正则化时,结构分数为:
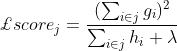
当lambda越大,结构分数会越小,参数gamma的重要性会增加,模型整体的剪枝会变得更加严格。同时,它也可以通过目标函数将模型学习的重点引向结构风险。
使用L1正则化时,结构分数为:

当alpha越大时,结构分数会越大,参`gamma的重要性会被缩小,模型整体的剪枝会变得更宽松。同时,它也可以通过目标函数将模型学习的重点引向结构风险。
通常正则化我们只选其一进行使用,如果L2正则化本身不足以抵抗过拟合的时候,可以尝试L1正则化和L2正则化一起使用。但对于模型的影响太复杂了,不好调参。
(4)抽样
对样本和特征进行抽样来增加弱评估器多样性、从而控制过拟合。

subsample:对样本进行抽样的比例,默认为1,可输入(0,1]之间的任何浮点数。输入0.6,则表示随机抽样60%的样本进行建树。
XGBoost中的样本抽样是不放回抽样,不会产生袋外数据,样本量较少的情况下保持为1,不进行抽样。
sampling_method`:对样本进行抽样时所使用的抽样方法,默认均匀抽样。输入"uniform":表示使用均匀抽样,此时subsample最好大于0.5。("gradient_based":表示使用有权重的抽样,暂时没用过)
对XGBoost来说,特征的抽样可以发生在建树之前(用`colsample_bytree`设置)、生长出新的一层树之前(用`colsample_bylevel`设置)、或者每个节点分枝之前(用`colsample_bynode`设置)。
三者之间会互相影响,全特征集 >= 建树所用的特征子集 >= 建立每一层所用的特征子集 >= 每个节点分枝时所使用的特征子集
(总计16个特征,colsample_bytree=0.5,从中选了8个特征,colsample_bylevel=0.5从8个里面再选4个,colsample_bynode=0.5从4个里面再选2个)不建议三个同时使用哦。、
大部分时候我们都会使用贪婪树来运行XGBoost算法,但在XGBoost当中还有其他几种不同的建树模式,包括基于直方图的估计贪婪树(approx greedy tree)、快速直方图贪婪树(Fast Histogram Approximate Greedy Tree)、以及基于GPU运行的快速直方图贪婪树等。
4、训练相关参数

early_stopping_rounds:位于`xgb.train`方法当中。如果规定的评估指标(evals中进行设置)不能连续`early_stopping_rounds`次迭代提升,那就触发提前停止。
evals:位于`xgb.train`方法当中,用于规定训练当中所使用的评估指标,一般都与损失函数保持一致,也可选择与损失函数不同的指标。
verbosity:用于打印训练流程和训练结果的参数。verbosity中设置数字[0,1,2,3],参数默认值为1。0:不打印任何内容;1:表示如果有警告,打印警告;2:打印建树的全部信息;3:正在debug,打印更多的信息。
scale_pos_weight:负正样本比值,用来调节样本不均衡。
nthread:允许并行的最大线程数,xgboost在默认运行时会占用大量资源。
以上是关于XGBoost 极限提升树 (Extreme Gradient Boosting)的主要内容,如果未能解决你的问题,请参考以下文章