词法分析(编译原理不用慌)
Posted 混个样子出来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词法分析(编译原理不用慌)相关的知识,希望对你有一定的参考价值。
目录
一.简单版
#include<stdio.h>
#include<iostream>
using namespace std;
#include<string.h>
//char prog[80]="begin if x>=24 then s:=0 end #"
char prog[80];
char token[8]; //prog存放输入符号串;token存放识别出的单词
int syn, p, sum,m;
char ch; //syn-种别码;p-prog数组的下标;sum-识别出的整数
char *rwtab[6] = "begin", "if", "then", "while", "do", "end"; //关键字表置初值
//扫描子程序
void scaner( )
m=0;
for (int n=0; n<8; n++ ) token[n]=NULL; //将token清空
ch=prog[p++] ; //根据全局变量p读取下一个字符,分析下一个单词
while (ch==' '|| ch == '\\n') ch=prog[p++] ;
//1.首字符为字母的情况,可能为标识符或关键字
if(ch<='z'&& ch>='a')
m=0;
while (ch<='z'&& ch>='a'||ch<='9'&& ch>='0')
token[m++]=ch;//将ch保存至token[m++]中
ch=prog[p++] ;//读取下一个字符
token[m++]='\\0';
p--;//......
syn=10 ; //标识符,置syn=10
for (int n=0; n<6; n++ ) //判断当前标识符是否为关键字
if (strcmp( token, rwtab[n])==0)
syn=n+1;//关键字,置关键字syn
break ;
//2.首字符为数字的情况,为整数
else if (ch<='9'&& ch>='0')
while (ch<='9'&& ch>='0')
sum=sum*10+ch-'0'; //将ch数字字符转换成整数送入sum,进位故sum*10,
ch=prog[p++] ;//读取下一个字符
p--;//.......
syn=11; //整数,置syn=11
//3.其他算符或界符等情况
else
switch(ch)
case '<':
token[m++]=ch; //ch存入token ;
ch=prog[p++] ;// 读下一个字符 ;
//三种情况,<=或<>或<
if (ch=='>')
syn=21;//将<>的种别码赋给syn;
token[p++]=ch; //ch存入token ;
else if (ch=='=')
syn=22;//将<=的种别码赋给syn;
token[p++]=ch; // ch存入token ;
else
syn=20;//将<的种别码赋给syn;
p--;
break;
case '>':
token[m++]=ch; ch=prog[p++] ;// 读下一个字符 ;
if (ch=='=')
syn=24;//将<=的种别码赋给syn;
token[m++]=ch; // ch存入token ;
else
syn=23;//将<的种别码赋给syn;
p--;
break;
case ':':
token[m++]=ch; //ch存入token ;
ch=prog[p++] ;// 读下一个字符 ;
if (ch=='=')
syn=18;//将<=的种别码赋给syn;
token[m++]=ch; // ch存入token ;
else
syn=17;//将<的种别码赋给syn;
p--;
break;
case '+':
token[m++]=ch;syn=13;break;
case '-':
token[m++]=ch;syn=14;break;
case '*':
token[m++]=ch;syn=15;break;
case '/':
token[m++]=ch;syn=16;break;
case '=':
token[m++]=ch;syn=25;break;
case ';':
token[m++]=ch;syn=26;break;
case '(':
token[m++]=ch;syn=27;break;
case ')':
token[m++]=ch;syn=28;break;
case '#':
token[m++]=ch;syn=0;break;
default: syn= -1;
token[m++]='\\0';
int main( )
//......
printf( "\\n please input string : \\n" ) ;
do
ch=getchar( );
prog[p++]=ch ;
while(ch!='#');
p=0;//......
do //循环调用scanner()函数分析prog中的字符串,直到syn为0(即#)分析结束
scaner();
switch(syn)
case 11: //根据syn的值输出(syn,sum或者token)二元组
printf("%-6d %-5d\\n",sum,syn);break;
default: printf("%-6s %-5d\\n",token,syn);
while(syn!=0);
二.简单版(文本保存)
c++版
此处是自己先创建一个1.txt文件
如:
const a=10;
var b,c;
procedure p;
begin
c:=b+a
end;
begin#
#include<stdio.h>
#include<string.h>
//"begin if x>24 then s:=0 end #"
char prog[80], token[10]; //prog存放输入符号串;token存放识别出的单词
int syn, p, sum=0,m;
char ch; //syn-种别码;p-prog数组的下标;sum-识别出的整数
char str;
char *rwtab[13] = "begin", "if", "then", "while", "do", "end","const","var","procedure","odd","call","read","write";//关键字表置初值
FILE* pf = fopen("2.txt", "w+");
//扫描子程序
void scaner( )
m=0;sum=0;
for (int n=0; n<8; n++ ) token[n]=NULL; //将token清空
ch=prog[p++] ; //根据全局变量p读取下一个字符,分析下一个单词
while (ch==' '|| ch == '\\n') ch=prog[p++] ;
//1.首字符为字母的情况,可能为标识符或关键字
if(ch<='z'&& ch>='a')
m=0;
while (ch<='z'&& ch>='a'||ch<='9'&& ch>='0')
token[m++]=ch;//将ch保存至token[m++]中
ch=prog[p++] ;//读取下一个字符
token[m++]='\\0';
p--;//......
syn=30 ; //标识符,置syn=30
for (int n=0; n<13; n++ ) //判断当前标识符是否为关键字
if (strcmp( token, rwtab[n])==0)
syn=n+1;//关键字,置关键字syn
break ;
//2.首字符为数字的情况,为整数
else if (ch<='9'&& ch>='0')
while (ch<='9'&& ch>='0')
sum=sum*10+ch-'0'; //将ch数字字符转换成整数送入sum
ch=prog[p++] ;//读取下一个字符
p--;//.......
syn=31; //整数,置syn=31
//3.其他算符或界符等情况
else
switch(ch)
case '<':
token[m++]=ch; //ch存入token ;
ch=prog[p++] ;// 读下一个字符 ;
//三种情况,<=或<>或<
if (ch=='>')
syn=21;//将<>的种别码赋给syn;
token[m++]=ch; //ch存入token ;
else if (ch=='=')
syn=22;//将<=的种别码赋给syn;
token[p++]=ch; // ch存入token ;
else
syn=20;//将<的种别码赋给syn;
p--;
break;
case '>':
token[m++]=ch; ch=prog[p++] ;// 读下一个字符 ;
if (ch=='=')
syn=24;//将<=的种别码赋给syn;
token[p++]=ch; // ch存入token ;
else
syn=23;//将<的种别码赋给syn;
p--;
break;
case ':':
token[m++]=ch; //ch存入token ;
ch=prog[p++] ;// 读下一个字符 ;
if (ch=='=')
syn=18;//将:=的种别码赋给syn;
token[m++]=ch; // ch存入token ;
else
syn=17;//将:的种别码赋给syn;
p--;
break;
case '+':
token[m++]=ch;syn=32;break;
case '-':
token[m++]=ch;syn=14;break;
case '*':
token[m++]=ch;syn=15;break;
case '/':
token[m++]=ch;syn=16;break;
case '=':
token[m++]=ch;syn=25;break;
case ';':
token[m++]=ch;syn=26;break;
case '(':
token[m++]=ch;syn=27;break;
case ')':
token[m++]=ch;syn=28;break;
case '#':
token[m++]=ch;syn=0;break;
default: syn= -1;
token[m++]='\\0';
int f(int syn)
if(syn==26||syn==27||syn==28)
printf("界符");
fprintf(pf," 界符\\n");
else if((syn>=20&&syn<=25)||(syn>=14&&syn<=16)||syn==18||syn==32)
printf("运算符");
fprintf(pf," 运算符\\n");
else if(syn>=1&&syn<=13)
printf("关键字");
fprintf(pf," 关键字\\n");
else if(syn==30)
printf("标识符");
fprintf(pf," 标识符\\n");
else if(syn==17)
printf("非法");
fprintf(pf," 非法\\n");
int main( )
p=0;
FILE* pf1 = fopen("1.txt", "r");
while((str=fgetc(pf1))!=EOF)
//如果没有读到末尾,则继续读取信息
prog[p++]=str;
if(str=='#')
break;
prog[p++]='\\0';
p=0;
do //循环调用scanner()函数分析prog中的字符串,直到syn为0(即#)分析结束
scaner();
switch(syn)
case 31: //根据syn的值输出(syn,sum或者token)二元组
fprintf(pf,"%-6d ",sum);
fprintf(pf," 数字\\n");
printf("%-6d 数字\\n",sum);
break;
default:
fprintf(pf,"%-6s ",token);
printf("%-6s ",token);f(syn);printf("\\n");
while(syn!=0);
fclose(pf);//关闭文件
pf=NULL;
// fclose(pf1);
// pf1=NULL;
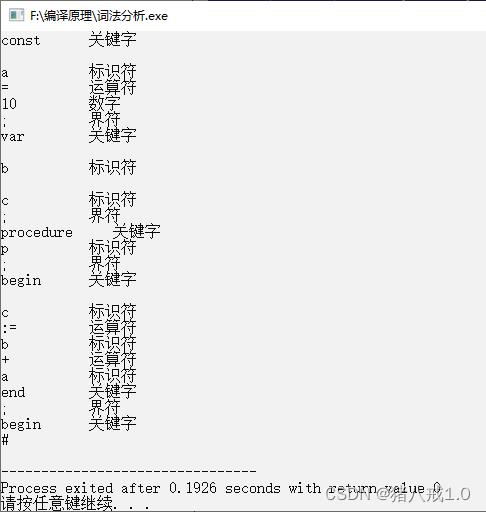
运行结果:
Java版
1.txt放你要读的文法
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Scanner;
/*
* 保留字13个syn赋值1-13const ,var,procedure,begin,end,odd,if,then,call, while,do, read,write
* 标识符syn赋值14
* 常数syn赋值
* 运算符+,-,*,/,= syn赋值16-20 #syn赋值为0 <,<=,>,>=,:= syn赋值21-25
* 界符( ) , ; . syn赋值26-30
* */
public class PL0
static String prog="";
//static String prog="begin if x>=24 then s:=0 end #";
static String token1; //做保留识别出的值
static int syn; //种别码
static int p=0; //做索引
static int sum; //做常数
static char ch; //做字符串索引下取值
static String str=" "; //做写入txt中分隔
//13个关键字
static String[] rwtab = "const" ,"var","procedure","begin","end","odd",
"if","then","call", "while","do", "read","write";
static void scaner()
token1=""; //将token1清空
sum=0; //sum清空
ch=prog.charAt(p++) ; //读字符串p索引下
while (ch==' '|| ch == '\\n') ch=prog.charAt(p++) ;
//1.首字符为字母的情况,可能为标识符或关键字
if(ch<='z'&& ch>='a')
while (ch<='z'&& ch>='a'||ch<='9'&& ch>='0')
token1+=ch;
ch=prog.charAt(p++) ;//读取下一个字符
p--;
syn=14 ; //标识符,置syn=14
for (int n=0; n<13; n++ ) //判断当前标识符是否为关键字
if (token1.equals(rwtab[n]) )
syn=n+1;
break ;
//2.首字符为数字的情况,为整数
else if (ch<='9'&& ch>='0')
while (ch<='9'&& ch>='0')
sum=sum*10+ch-'0'; //将ch数字字符转换成整数送入sum,进位故sum*10,
ch=prog.charAt(p++) ;//读取下一个字符
p--;
syn=15; //常数,置syn=15
//3.其他算符或界符等情况
else
switch(ch)
case '+':
token1+=ch;syn=16;break;
case '-':
token1+=ch;syn=17;break;
case '*':
token1+=ch;syn=18;break;
case '/':
token1+=ch;syn=19;break;
case '=':
token1+=ch;syn=20;break;
case '#':
token1+=ch;syn=0;break;
//<与<=
case '<':
token1+=ch;
ch=prog.charAt(p++) ;
if (ch=='=')
syn=22;
token1+=ch;
else
syn=21;
p--;
break;
//>与>=
case '>':
token1+=ch; ch=prog.charAt(p++) ;// 读下一个字符 ;
if (ch=='=')
syn=24;
token1+=ch;
else
syn=23;
p--;
break;
case ':':
token1+=ch;
ch=prog.charAt(p++) ;
if (ch=='=')
syn=25;
token1+=ch;
break;
case '(':
token1+=ch;syn=26;break;
case ')':
token1+=ch;syn=27;break;
case ',':
token1+=ch;syn=28;break;
case ';':
token1+=ch;syn=29;break;
case '.':
token1+=ch;syn=30;break;
default: syn= -1;
public static void main(String[] args) throws IOException
//System.out.print("please input string :");
//Scanner input = new Scanner(System.in);
//prog=input.nextLine();
FileInputStream fos0;
FileOutputStream fos1;
FileOutputStream fos2;
FileOutputStream fos3;
FileOutputStream fos4;
FileOutputStream fos5;
try
fos0=new FileInputStream("src/1.txt");
int ch=0;
while ((ch=fos0.read())!=-1)
prog+=(char)ch;
System.out.println(prog);
fos0.close();
fos1=new FileOutputStream("src/关键字.txt",true);
fos2=new FileOutputStream("src/标识符.txt",true);
fos3=new FileOutputStream("src/运算符.txt",true);
fos4=new FileOutputStream("src/常数.txt",true);
fos5=new FileOutputStream("src/界符.txt",true);
catch (FileNotFoundException e)
throw new RuntimeException(e);
do //循环调用scanner()函数分析prog中的字符串,直到syn为0(即#)分析结束
scaner();
if(token1!="")
//System.out.println(token1+" "+syn);
System.out.printf("%-8s",token1+" ");
//关键字1-13
if(syn>=1&&syn<=13)
fos1.write((token1+str+"\\n").getBytes(StandardCharsets.UTF_8));
System.out.println("基本字");
//标识符14
else if(syn==14)
fos2.write((token1+str+"\\n").getBytes(StandardCharsets.UTF_8));
System.out.println("标识符");
//运算符16-25和#0
else if(syn>=16&&syn<=25||syn==0)
fos3.write((token1+str+"\\n").getBytes(StandardCharsets.UTF_8));
System.out.println("运算符");
//常数15
else if(syn==15)
fos4.write((String.valueOf(sum)+str+"\\n").getBytes(StandardCharsets.UTF_8));
//System.out.println(sum+" "+syn);
System.out.printf("%-8d",sum);
System.out.println("数字");
else
fos5.write((token1+str+"\\n").getBytes(StandardCharsets.UTF_8));
System.out.println("界符");
while(syn!=0);
fos0.close();
fos1.close();
fos2.close();
fos3.close();
fos4.close();
fos5.close();
运行结果:
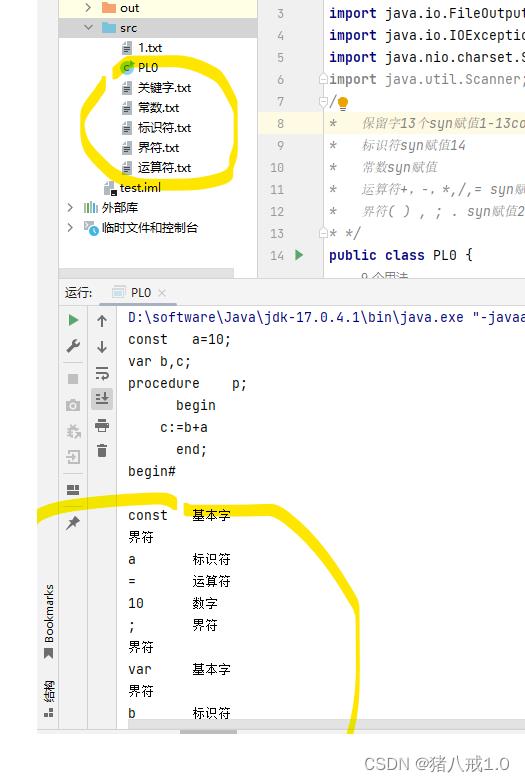
三.第三版(文本保存)
c++版
#include <stdio.h>
#include <string.h>
enum symbol
nul, ident, number, plus, minus,
times, slash, oddsym, eql, neq,
lss, leq, gtr, geq, lparen,
rparen, comma, semicolon, period, becomes,
beginsym, endsym, ifsym, thensym, whilesym,
writesym, readsym, dosym, callsym, constsym,
varsym, procsym,
;
int cc, ll;
FILE * fa1;
int err; /*错误计数器*/
FILE* fin;
int cx;
char ch;
char line[81];
#define getchdo if(-1==getch())return -1
# define al 10
char a[al + 1];
char id[al + 1];
# define norw 13
char word[norw][al];
enum symbol sym;
enum symbol wsym[norw];
# define nmax 14
int num;
enum symbol ssym[256];
char fname[al];
void init();
void error(int n);
int getch();
int getsym();
int main()
printf("Input pl/0 file?");
scanf("%s", fname); /* 输入PL/0源程序文件名 */
fin = fopen(fname, "r");
if(fin)
printf("Output pl/0 file?");
scanf("%s", fname);
fa1 = fopen(fname, "w");
init();
// err = 0;
// cc = cx = ll = 0;
// ch = ' ';
while(getsym() != -1);
else
printf("找不到文件\\n");
printf("\\n");
return 0;
void init()
int i;
/* 设置单字符符号 */
for(i=0; i<=255; i++)
ssym[i] = nul;
ssym['+'] = plus;
ssym['-'] = minus;
ssym['*'] = times;
ssym['/'] = slash;
ssym['('] = lparen;
ssym[')'] = rparen;
ssym['='] = eql;
ssym[','] = comma;
ssym['.'] = period;
ssym['#'] = neq;
ssym[';'] = semicolon;
/* 设置保留字名字,按照字母顺序,便于折半查找 */
strcpy(word[0], "begin");
strcpy(word[1], "call");
strcpy(word[2], "const");
strcpy(word[3], "do");
strcpy(word[4], "end");
strcpy(word[5], "if");
strcpy(word[6], "odd");
strcpy(word[7], "procedure");
strcpy(word[8], "read");
strcpy(word[9], "then");
strcpy(word[10], "var");
strcpy(word[11], "while");
strcpy(word[12], "write");
/* 设置保留字符号 */
wsym[0] = beginsym;
wsym[1] = callsym;
wsym[2] = constsym;
wsym[3] = dosym;
wsym[4] = endsym;
wsym[5] = ifsym;
wsym[6] = oddsym;
wsym[7] = procsym;
wsym[8] = readsym;
wsym[9] = thensym;
wsym[10] = varsym;
wsym[11] = whilesym;
wsym[12] = writesym;
/*
* 出错处理,打印出错位置和错误编码
*/
void error(int n)
char space[81];
memset(space,32,81);
space[cc-1] = 0; //出错时当前符号已经读完,所以cc-1
printf("****%s!%d\\n",space,n);
fprintf(fa1,"****%s!%d\\n",space,n);
err++;
/*
* 漏掉空格,读取一个字符。
*
* 每次读一行,存入line缓冲区,line被getsym取空后再读一行
*
* 被函数getsym调用。
*/
int getch()
if(cc==ll)
if(feof(fin))
printf("program incomplete");
return -1;
ll=0;
cc=0;
ch = ' ';
while(ch != 10)
if(EOF == fscanf(fin,"%c",&ch))
line[ll]=0;
break;
//fprintf(fa1,"%c", ch);
line[ll]=ch;
ll++;
ch = line[cc];
cc++;
return 0;
/*
* 词法分析,获取一个符号
*/
int getsym()
int i,j,k;
if(ch=='#')
return -1;
while(ch==' ' || ch==10 || ch==9) /* 忽略空格、换行和TAB */
getchdo;
if(ch>='a' && ch<='z')
/* 名字或保留字以a~z开头*/
k = 0;
do
if(k<al)
a[k]=ch;
k++;
getchdo;
while(ch>='a'&&ch<='z' || ch>='0'&&ch<='9');
a[k] = 0;
strcpy(id,a);
i=0;
j=norw-1;
do /* 搜索当前符号是否为保留字 */
k=(i+j)/2;
if(strcmp(id,word[k]) <= 0)
j=k-1;
if(strcmp(id,word[k]) >= 0)
i=k+1;
while(i<=j);
if(i-1>j)
printf("%s 保留字\\n", id);
fprintf(fa1,"%s 保留字\\n", id);
sym=wsym[k];
else
printf("%s 标识符\\n", id);
fprintf(fa1,"%s 标识符\\n", id);
sym=ident; /* 搜索失败,则是名字或数字 */
else
if(ch>='0'&&ch<='9')
/* 检测是否为数字:以0~9开头 */
k=0;
num=0;
sym=number;
do
//printf("%c\\n",ch);
num=10*num+ch-'0';
k++;
getchdo;
while(ch>='0'&&ch<='9'); /* 获取数字的值 */
k--;
if(k>nmax)
error(30);
printf("%d 整数\\n",num);
fprintf(fa1,"%d 整数\\n", num);
else
if(ch==':') /* 检测赋值符号 */
getchdo;
if(ch=='=')
printf(":= 运算符\\n");
fprintf(fa1,":= 运算符\\n", id);
sym=becomes;
getchdo;
else
printf(": error\\n");
sym=nul; /* 不能识别的符号 */
else
if(ch=='<') /* 检测小于或小于等于符号 */
getchdo;
if(ch=='=')
printf("<= 运算符\\n");
fprintf(fa1,"<= 运算符\\n", id);
sym=leq;
getchdo;
else
printf("< 运算符\\n");
fprintf(fa1,"< 运算符\\n", id);
sym=lss;
else
if(ch=='>') /* 检测大于或大于等于符号 */
getchdo;
if(ch=='=')
printf(">= 运算符\\n");
fprintf(fa1,">= 运算符\\n", id);
sym=geq;
getchdo;
else
printf("> 运算符\\n");
fprintf(fa1,"> 运算符\\n", id);
sym=gtr;
else
if(ch=='=')
printf("= 运算符\\n");
fprintf(fa1,"= 运算符\\n", id);
//getchdo;
if(ch=='+')
printf("+ 运算符\\n");
fprintf(fa1,"+ 运算符\\n", id);
getchdo;
else if(ch=='-')
printf("- 运算符\\n");
fprintf(fa1,"- 运算符\\n", id);
getchdo;
else if(ch=='*')
printf("* 运算符\\n");
fprintf(fa1,"* 运算符\\n", id);
getchdo;
else if(ch=='/')
printf("/ 运算符\\n");
fprintf(fa1,"/ 运算符\\n", id);
getchdo;
else if(ch=='(')
printf("( 运算符\\n");
fprintf(fa1,"( 运算符\\n", id);
getchdo;
else if(ch==')')
printf(") 运算符\\n");
fprintf(fa1,") 运算符\\n", id);
getchdo;
else if(ch==',')
printf(", 运算符\\n");
fprintf(fa1,", 运算符\\n", id);
getchdo;
else if(ch==';')
printf("; 运算符\\n");
fprintf(fa1,"; 运算符\\n", id);
getchdo;
else if(ch=='.')
printf(". 运算符\\n");
fprintf(fa1,". 运算符\\n", id);
getchdo;
else
sym=ssym[ch]; /* 当符号不满足上述条件时,全部按照单字符符号处理 */
if(sym != period)
getchdo;
return 0;
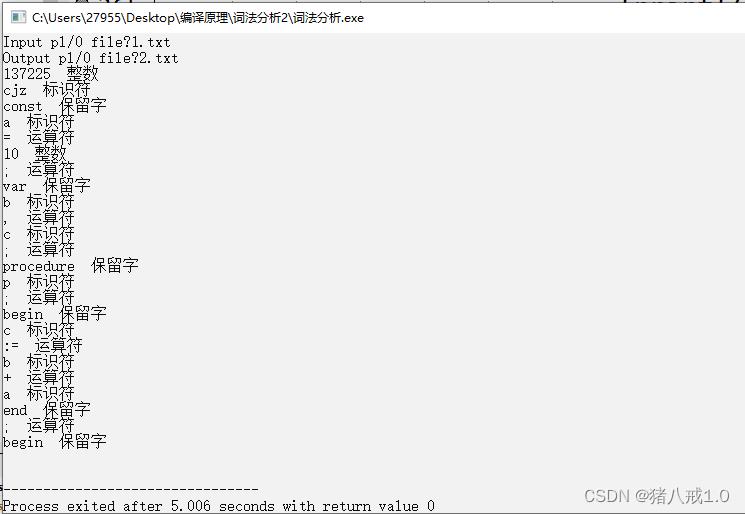
运行结果:
以上是关于词法分析(编译原理不用慌)的主要内容,如果未能解决你的问题,请参考以下文章