大数据Spark DataFrame/DataSet常用操作
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark DataFrame/DataSet常用操作相关的知识,希望对你有一定的参考价值。
目录
1 一般操作:查找和过滤
1.1 读取数据源

1.1.1读取json
使用spark.read。注意:路径默认是从HDFS,如果要读取本机文件,需要加前缀file://,如下
scala> val people = spark.read.format("json").load("file:///opt/software/data/people.json")
people: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> people.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
spark.read.format(“json”).load(“file:///opt/software/data/people.json”)
等价于spark.read.json(“file:///opt/software/data/people.json”)
如要要读取其它格式文件,只需修改format(“json”)即可,如format(“parquet”)
1.1.2 读取Hive表
使用spark.sql。其中hive数据库名default(默认数据库名可省略),表为people
scala> val peopleDF=spark.sql("select * from default.people")
peopleDF: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
scala> peopleDF.show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
|zhangsan| 22| chengdu|
| wangwu| 33| beijing|
| lisi| 28|shanghai|
+--------+---+--------+
scala> peopleDF.printSchema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- address: string (nullable = true)
1.2 取数据列



取列的三种方式如下
scala> peopleDF.select("name","age").show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 22|
| wangwu| 33|
| lisi| 28|
+--------+---+
scala> peopleDF.select($"name",$"age").show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 22|
| wangwu| 33|
| lisi| 28|
+--------+---+
scala> peopleDF.select(peopleDF.col("name"),peopleDF.col("age")).show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 22|
| wangwu| 33|
| lisi| 28|
+--------+---+
注意:如果在IDEA中编辑代码,使用
,
则
必
须
增
加
语
句
:
i
m
p
o
r
t
s
p
a
r
k
.
i
m
p
l
i
c
i
t
s
.
,
否
则
,则必须增加语句:import spark.implicits._,否则
,则必须增加语句:importspark.implicits.,否则表达式会报错。spark-shell默认已经导入了的
$”列名”这个是语法糖,返回Column对象
1.3 过滤算子filter(filter等价于where算子)





DF.col("id")等价于$"id",取列ColumnName
DF.filter("name=''") 过滤name等于空的行
DF.filter($"age" > 21).show() 过滤age大于21的行,必须增加语句:import spark.implicits._,否则$表达式会报错
DF.filter($"age" === 21) 取等于时必须用===,否则报错,对应的不等于是=!=。等价于DF.filter("age=21")
DF.filter("substring(name,0,1) = 'M'").show 显示name以M开头的行,其中substring是functions.scala,functions.scala包含很多函数方法,等价于DF.filter("substr(name,0,1) = 'M'").show

scala> peopleDF.printSchema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- address: string (nullable = true)
scala> peopleDF.show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
|zhangsan| 22| chengdu|
| wangwu| 33| beijing|
| lisi| 28|shanghai|
+--------+---+--------+
scala> peopleDF.filter($"name" === "wangwu").show
+------+---+-------+
| name|age|address|
+------+---+-------+
|wangwu| 33|beijing|
+------+---+-------+
scala> peopleDF.filter($"name" =!= "wangwu").show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
|zhangsan| 22| chengdu|
| lisi| 28|shanghai|
+--------+---+--------+
scala> peopleDF.filter("age > 30").show
+------+---+-------+
| name|age|address|
+------+---+-------+
|wangwu| 33|beijing|
+------+---+-------+
scala> peopleDF.filter($"age" > 30).show
+------+---+-------+
| name|age|address|
+------+---+-------+
|wangwu| 33|beijing|
+------+---+-------+
2 聚合操作:groupBy和agg
2.1 排序算子sort(sort等价于orderBy)
DF.sort(DF.col(“id”).desc).show 以DF中字段id降序,指定升降序的方法。另外可指定多个字段排序
=DF.sort($“id”.desc).show
DF.sort 等价于DF.orderBy
scala> peopleDF.sort($"age").show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
|zhangsan| 22| chengdu|
| lisi| 28|shanghai|
| wangwu| 33| beijing|
+--------+---+--------+
scala> peopleDF.sort($"age".desc).show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
| wangwu| 33| beijing|
| lisi| 28|shanghai|
|zhangsan| 22| chengdu|
+--------+---+--------+
scala> peopleDF.sort($"age".asc).show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
|zhangsan| 22| chengdu|
| lisi| 28|shanghai|
| wangwu| 33| beijing|
+--------+---+--------+
scala> peopleDF.orderBy($"age".asc).show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
|zhangsan| 22| chengdu|
| lisi| 28|shanghai|
| wangwu| 33| beijing|
+--------+---+--------+
scala> peopleDF.orderBy($"age".desc).show
+--------+---+--------+
| name|age| address|
+--------+---+--------+
| wangwu| 33| beijing|
| lisi| 28|shanghai|
|zhangsan| 22| chengdu|
+--------+---+--------+
2.2 分组函数groupBy
2.2.1 分组计数
select address,count(1) from people group by address; 等价的算子如下
scala> peopleDF.show()
+--------+---+--------+
| name|age| address|
+--------+---+--------+
|zhangsan| 22| chengdu|
| wangwu| 33| beijing|
| lisi| 28|shanghai|
|xiaoming| 28| beijing|
| mm| 21| chengdu|
|xiaoming| 18| beijing|
| mm| 11| chengdu|
+--------+---+--------+
scala> peopleDF.groupBy("address").count().show
+--------+-----+
| address|count|
+--------+-----+
| beijing| 3|
| chengdu| 3|
|shanghai| 1|
+--------+-----+
2.2.2 分组后求最值、平均值、求和的方法
//等价于select address,max(age) from people group by address;
scala> peopleDF.groupBy("address").max("age").show
+--------+--------+
| address|max(age)|
+--------+--------+
| beijing| 33|
| chengdu| 22|
|shanghai| 28|
+--------+--------+
//等价于select address,avg(age) from people group by address;
scala> peopleDF.groupBy("address").avg("age").show
+--------+------------------+
| address| avg(age)|
+--------+------------------+
| beijing|26.333333333333332|
| chengdu| 18.0|
|shanghai| 28.0|
+--------+------------------+
//等价于select address,min(age) from people group by address;
scala> peopleDF.groupBy("address").min("age").show
+--------+--------+
| address|min(age)|
+--------+--------+
| beijing| 18|
| chengdu| 11|
|shanghai| 28|
+--------+--------+
//等价于select address,sum(age) from people group by address;
scala> peopleDF.groupBy("address").sum("age").show
+--------+--------+
| address|sum(age)|
+--------+--------+
| beijing| 79|
| chengdu| 54|
|shanghai| 28|
+--------+--------+
2.2.3 分组后,求多个聚合值(最值、平均值等)。使用算子groupBy+agg
//等价于select address,count(age),max(age),min(age),avg(age),sum(age) from people group by address;
scala> peopleDF.groupBy("address").agg(count("age"),max("age"),min("age"),avg("age"),sum("age")).show
+--------+----------+--------+--------+------------------+--------+
| address|count(age)|max(age)|min(age)| avg(age)|sum(age)|
+--------+----------+--------+--------+------------------+--------+
| beijing| 3| 33| 18|26.333333333333332| 79|
| chengdu| 3| 22| 11| 18.0| 54|
|shanghai| 1| 28| 28| 28.0| 28|
+--------+----------+--------+--------+------------------+--------+
2.2.4 分组聚合后取别名
scala> peopleDF.groupBy("address").agg(count("age").as("cnt"),avg("age").as("avg")).show
+--------+---+------------------+
| address|cnt| avg|
+--------+---+------------------+
| beijing| 3|26.333333333333332|
| chengdu| 3| 18.0|
|shanghai| 1| 28.0|
+--------+---+------------------+
2.2.5 分组后行转列,使用pivot
//求同名用户在同一个地址的平均年龄
//把name的不同值作为列名
scala> peopleDF.groupBy("address").pivot("name").avg("age").show
+--------+----+----+------+--------+--------+
| address|lisi| mm|wangwu|xiaoming|zhangsan|
+--------+----+----+------+--------+--------+
| beijing|null|null| 33.0| 23.0| null|
| chengdu|null|16.0| null| null| 22.0|
|shanghai|28.0|null| null| null| null|
+--------+----+----+------+--------+--------+
2.3 案例
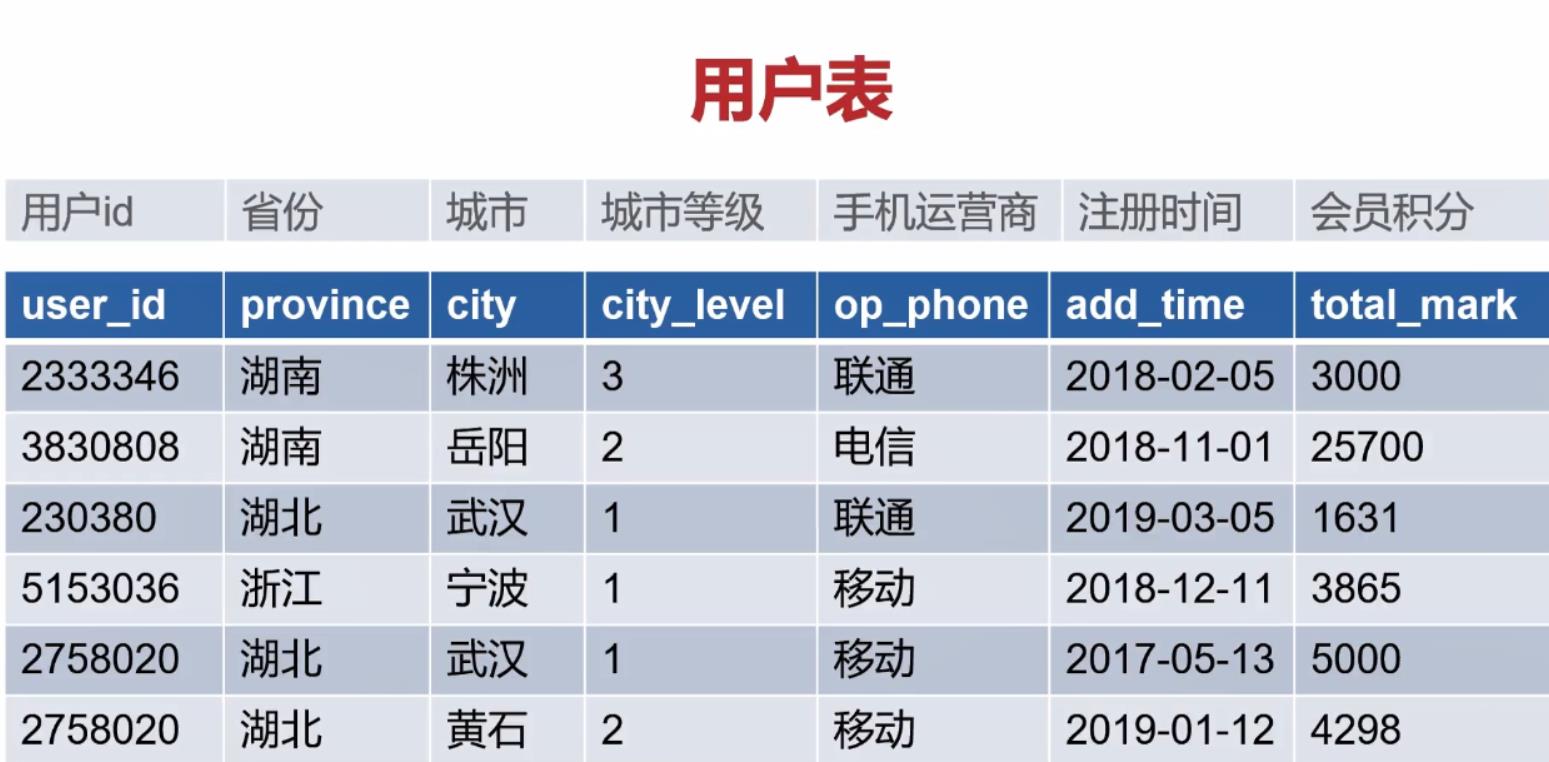







3 多表操作Join
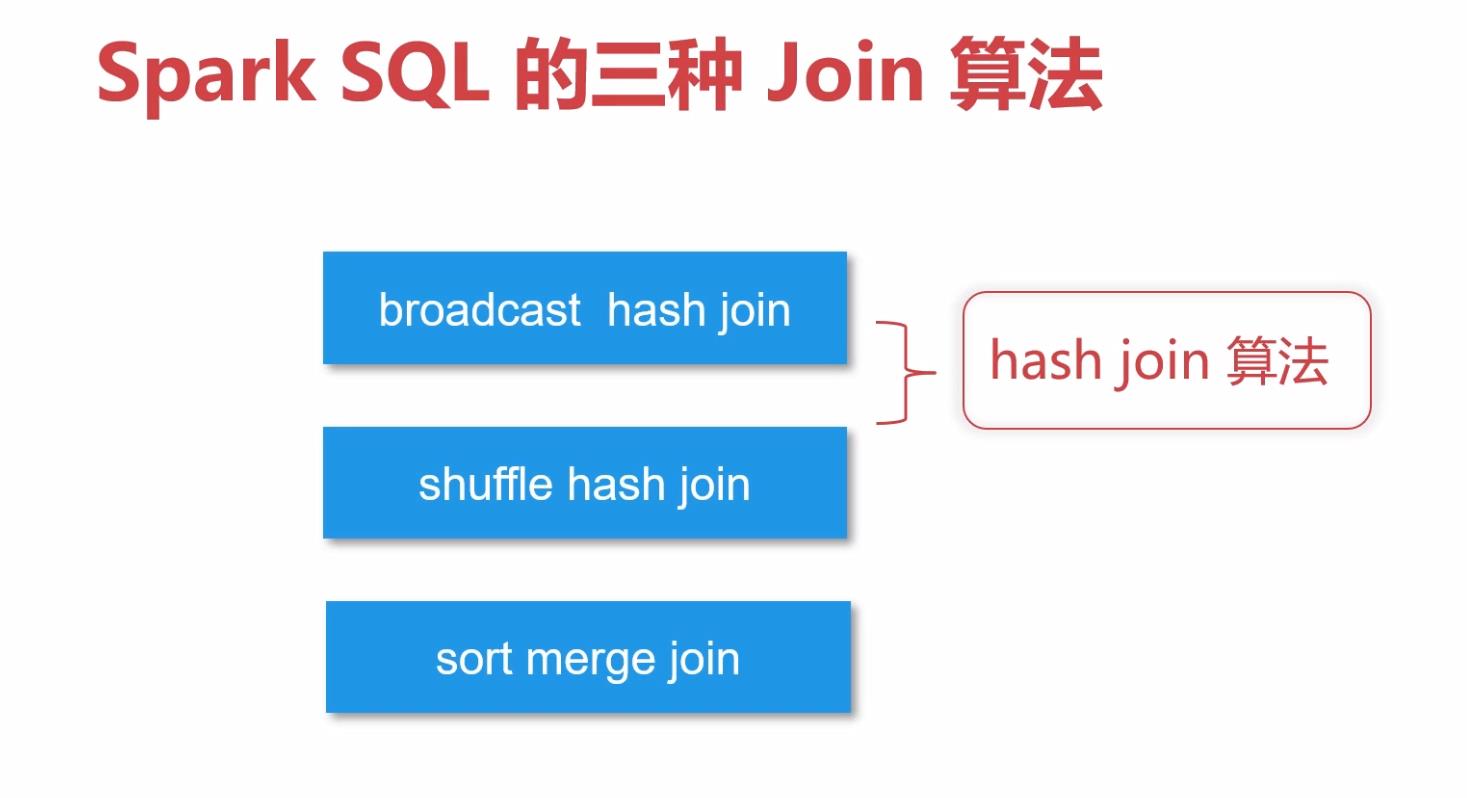

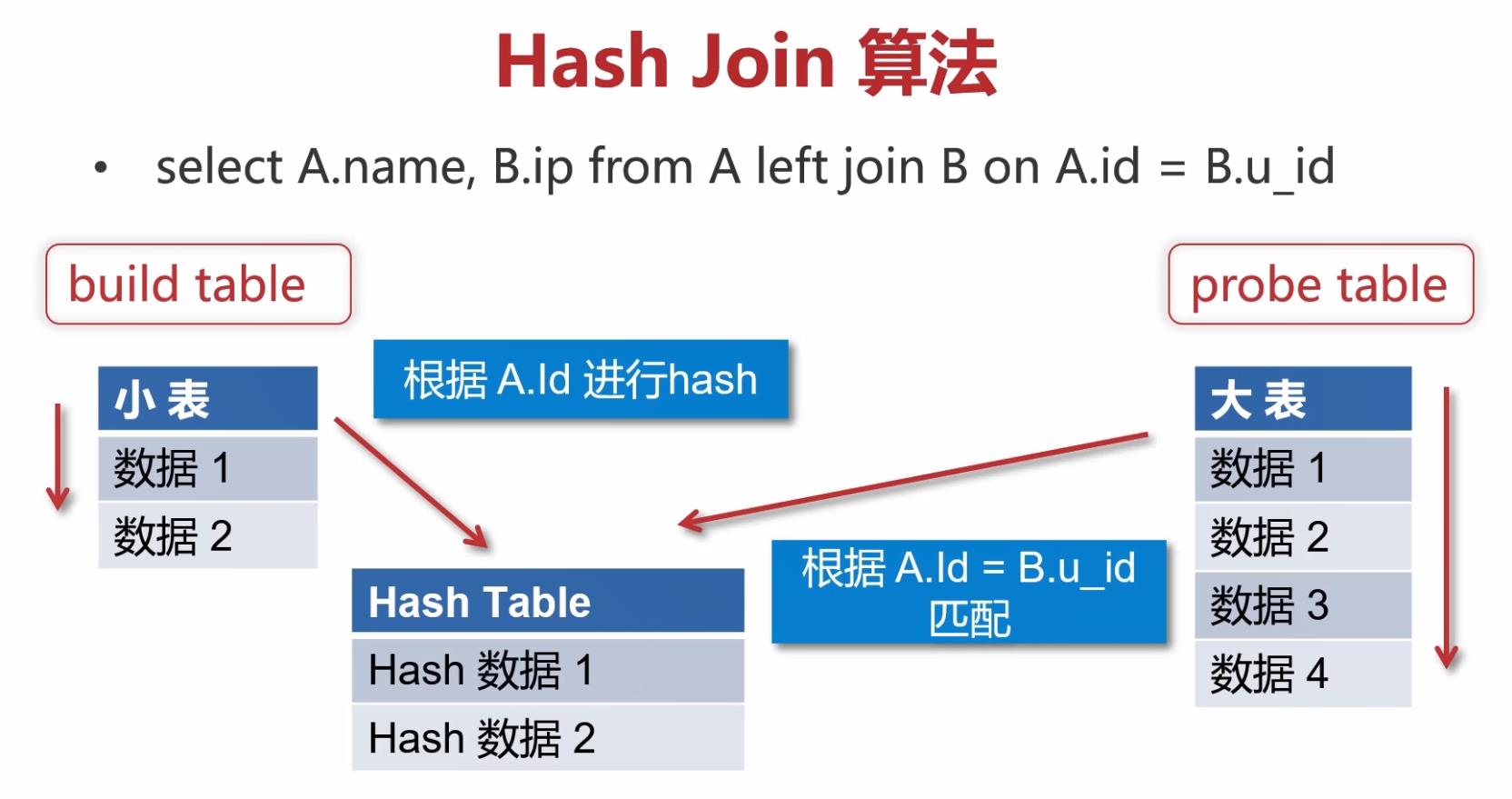


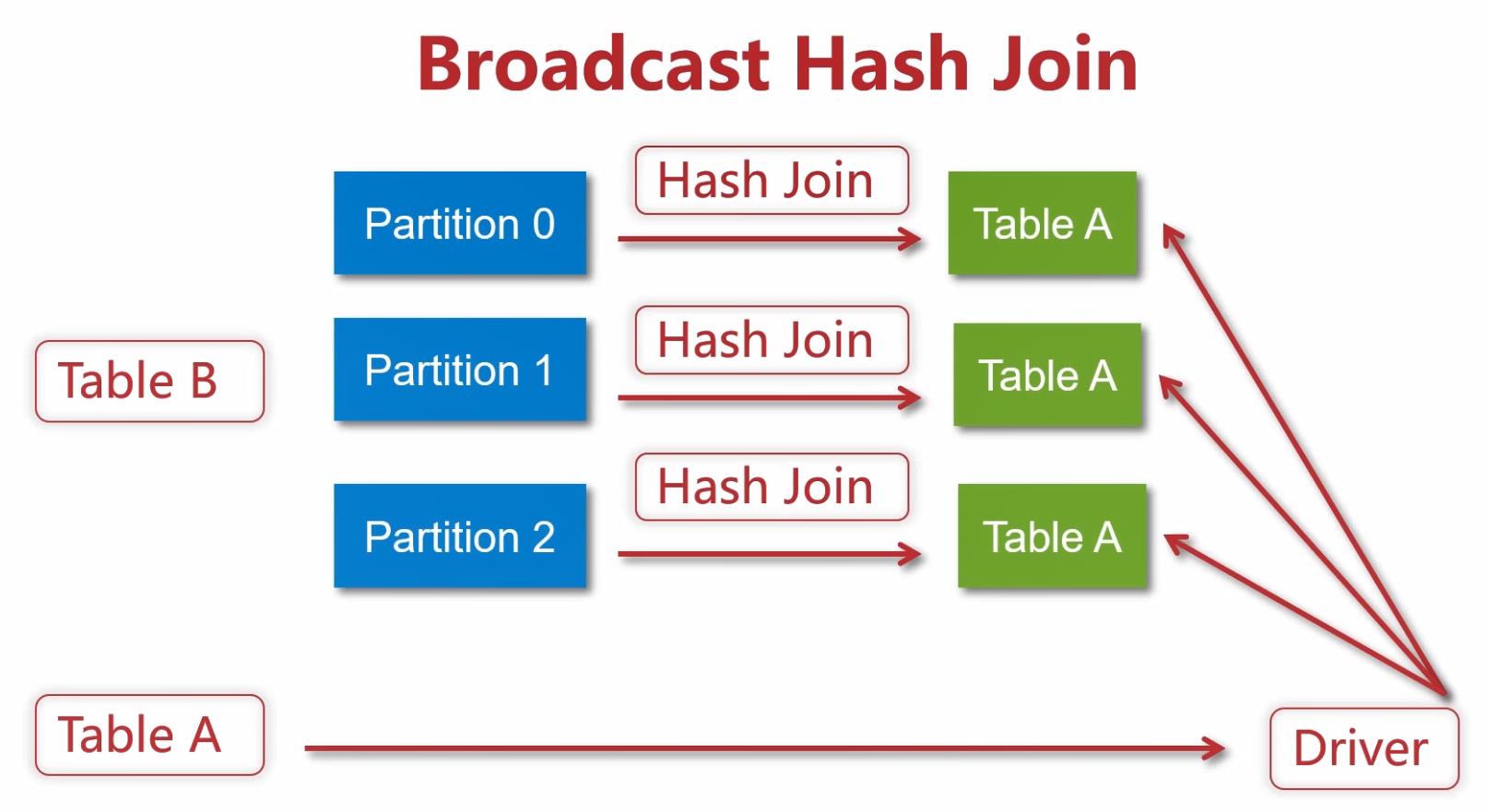







3.1 数据准备
先构建两个DataFrame
scala> val df1 = spark.createDataset(Seq(("a", 1,2), ("b",2,3) )).toDF("k1","k2","k3")
df1: org.apache.spark.sql.DataFrame = [k1: string, k2: int ... 1 more field]
scala> val df2 = spark.createDataset(Seq(("a", 2,2), ("b",3,3), ("b", 2,1), ("c", 1,1)) ).toDF("k1","k2","k4")
df2: org.apache.spark.sql.DataFrame = [k1: string, k2: int ... 1 more field]
scala> df1.show
+--以上是关于大数据Spark DataFrame/DataSet常用操作的主要内容,如果未能解决你的问题,请参考以下文章