Flink实时数据处理实践经验(Flink去重维表关联定时器双流join)
Posted oahaijgnahz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink实时数据处理实践经验(Flink去重维表关联定时器双流join)相关的知识,希望对你有一定的参考价值。
Flink实时数据处理实践经验
文章目录
首先需要知道的一些知识:
- Flink中所说的UDF在官方文档中定义为用户自己通过继承类或实现接口的自定义类、已有方法中传入匿名内部类、在已有函数中用Lambda表达式。
- Flink实现结果实时展示(一些简单的分组聚合逻辑)可以直接在流中分组聚合写入Redis/mysql,而需要在线实时多维分析需要将数据存入ClickHouse交给CK来处理。
1. 数据输入与预处理
- 首先,Flink的每项实时任务需要通过FlinkKafkaComsumer获取对接Kafka的流式处理环境,所以可以对获取DataStream封装一个工具类。这个工具类根据传入的配置文件和具体的反序列化方式类型
Class<? extends DeserializationSchema<T>>(如SimpleStringSchema.class),在内部为每个实时任务创建唯一执行环境和返回对接Kafka的DataStream。 - 其次,在获取到对应的DataStream后,需要对每条JSON数据解析成Java Bean对象。而解析的方法可以通过封装一个UDF(实现ProcessFunction,内部fastjson解析)。
2. 实时数据处理
在实时数仓实践中比较有意思的一些部分的总结:
- 流量域相关:
- 地理维度集成
FLink对每条数使用map进行查询是同步的做法,效率低下。这里可以使用Flink中的AsyncDataStream进行异步I/O查询。一般会在优先请求本地缓存的地理位置信息库,如果没有查询结果请求地图服务商API,在获取本次查询结果后再完善本地地理位置信息库。

- 关于新老用户标签:
离线数仓中由于数仓总是保存了历史的数据,所以在新的一天增量数据到来时,可以通过两表join的操作判断新数据是否为新用户来为每条记录添加新老用户标签。
实时数仓中新老用户的判断也可以去查询历史数据,但这样做会比较慢,不符合实时的场景。解决方式可以很容易想到在确保每个用户每次访问都会进入同一个组中1,状态保存HashSet来标记bean新老用户字段,但问题也很明显HashSet随用户线性增长,占用内存过高使得内存压力大且状态写入statebackend速度也会下降。所以会使用布隆过滤器替代HashSet方案,布隆过滤器的特点在于擅长判断不存在(只要有一个对应位为0就能判断其不存在),用位存储相比于HashSet节省存储空间。1.实现同一个用户访问进入同一个组中的方法:
第一种方法:可以通过对粗粒度的维度进行keyby比如手机型号等来确保同一个用户的数据进入同一个分组中,但存在的问题是可能由于手机型号不均衡导致数据倾斜,和每个分组都持有一个布隆过滤器(KeyedState)还是占用较多内存;
第二种方法:对最细粒度的维度进行keyby即设备id,这样只有同一用户的数据会进入到同一分组中,但同一个Slot中会存在大量分组,所以在同一个Slot中共享一个布隆过滤器(OperatorState)来实现。
- 关于Flink实现多维分析:
一般在Flink使用的实时场景中,不会对数据进行大量的分组聚合等操作,对于像多维复杂统计的需求一般是Flink在对数据ETL后存入CK后利用CK实现快速查询。
- 数据唯一ID生成(Kafka的topic+partition+offset)
可以通过FlinkKafkaComsumer类中传入KafkaDeserializtionSchema的实现类,重写deserialize()中可以获取topic、partition、offset和原始value信息等。- Flink整合CK实现At-Least-Once方案
使用是ClickHouse的ReplacingMergeTree,可以将同一个分区中,数据唯一ID相同的数据进行覆盖(merge),可以保留最新的数据(根据插入CK时的系统时间),可以使用这个特点实现Flink + Clickhouse的At-Least-Once。
存在的问题:写入到CK中的数据不会立即merge,需要手动optimize或后台自动合并。
解决方案:查询时在表名的后面加上final关键字,就只查最新的数据数据,但是查询效率变低。- Flink通过JDBC Sink将数据导入CK(详情Flink官网有示例,数据按批次和时间阈值执行导入)。
- 关于数据的实时统计结果测流输出的方案:
前言:在实时统计的场景中,比如对某个实物的在线人数实时统计,如果使用较多状态存储(尤其布隆过滤器),需要设置状态TTL对非活跃的状态进行管理。对有在线时长要求的计算通过状态和定时器实现对应的需求1。
现在有一个需求是,将数据流的一些聚合结果写入Redis用于实时展示,将明细写入ClickHouse用于之后的多维分析。采用的方式是将需要展示的聚合结果在定时器触发时(onTimer方法中)测流输出(打上标签)。测流输出Sink入Redis的主要代码如下:
其中,addSink()中的第二个参数需要重写里面的方法来设计写入Redis的k-v格式(Hset形式,key设计为id+时间,value设计为其他字段的拼接)。
主流输出JDBC Sink入ClickHouse的主要代码如下:
1.定时器定时触发的设定
定时器在设定时间相同的情况下会覆盖前一个定时器,利用这个特性可以用进入时间-进入时间%设定时长+设定时长来达到定时器根据设定时间的恒定触发效果(期间数据到达不会对定时器触发产生影响)。


- 关于数据流关联维表的方案:
Flink关联外部维表通常的解决方案:
a) 每来一条数据查一次数据库(慢、吞吐量低)
b) 可以使用异步IO(相对快,消耗资源多)
c) 广播State(最快、适用于少量数据、数据可以变化的)
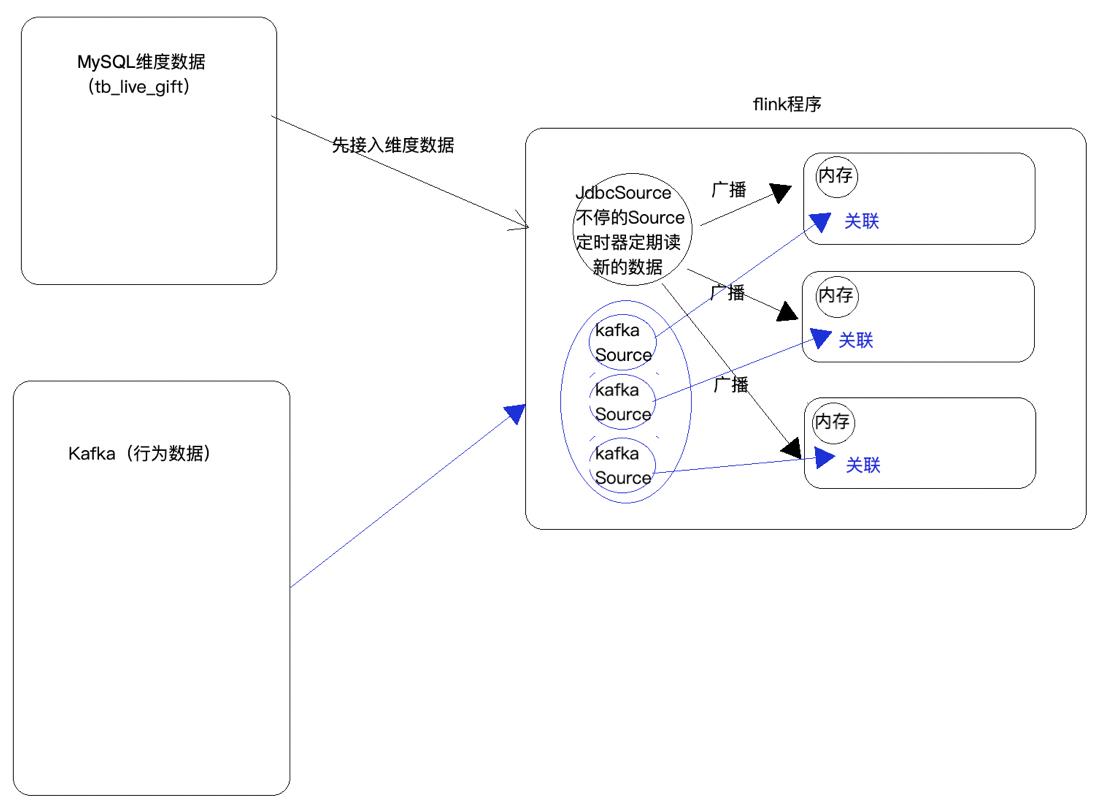
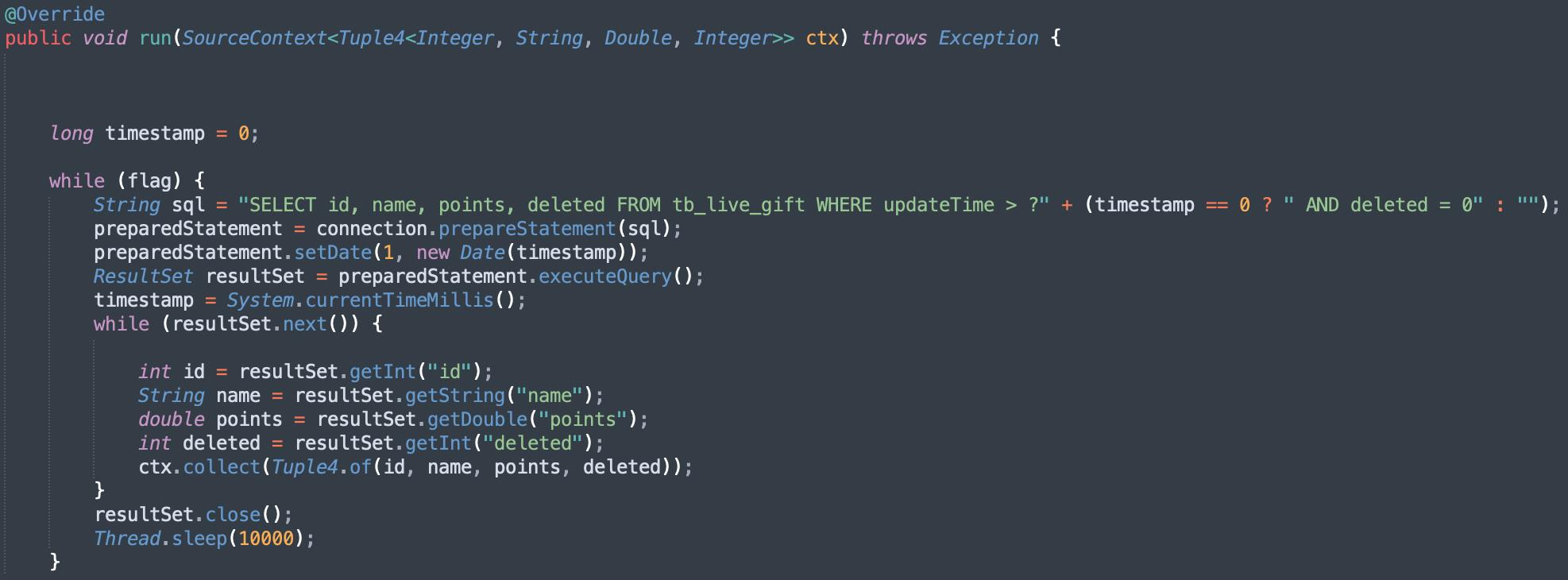
上面这个方案需要JDBC Source定时查询数据库,并不是最好的方案。自定义JDBC单并行Source(避免需要对MySQL表进行划分)实现MySQL维表增量读取:
读取完成后,得到的广播变量与主流进行connnect并实现BroadcastProcessFunction完成数据整合和输出。
- 关于划分窗口计算TopN:
实现方式:
- 先将数据进行keyby,划分滑动窗口(数据平滑),在窗口内进行增量聚合1(效率高,全局聚合效率低,而且占用大量资源)。但聚合函数只能获得到聚合条件和聚合结果信息,没法获取窗口的信息(窗口的起始时间,结束时间),所以再定义一个WindowFunction,窗口触发后可以在WindowFunction获取到窗口聚合后的数据,并且可以得到窗口的起始时间和结束时间(这两个定义的方法都是传入AggregateFunction中的)。
- 接下来要根据分类ID、事件ID、窗口起始时间、结束时间等条件keyby后进行排序。使用ProcessFunction的定时器实现判断一个窗口数据是否已经到齐,每来一条数据,不直接输出,而是将数据存储到ValueState<List>(为了容错),再注册一个比当前窗口的结束时间还要大一毫秒的定时器(仍然利用了注册时间相同的定时器会覆盖的特性)。如果下一个窗口的数据到达了,那么WaterMark已经大于了注册的定时器的时间,上一个窗口的数据已经攒齐,在onTimer方法中就可以排序并输出上个窗口的TopN数据。
1.增量聚合和全量聚合
增量聚合: 窗口不维护原始数据,只维护中间结果,每次基于中间结果和增量数据进行聚合。>如:ReduceFunction、AggregateFunction。
全量聚合: 窗口需要维护全部原始数据,窗口触发进行全量聚合。如:ProcessWindowFunction。
- 业务域相关:
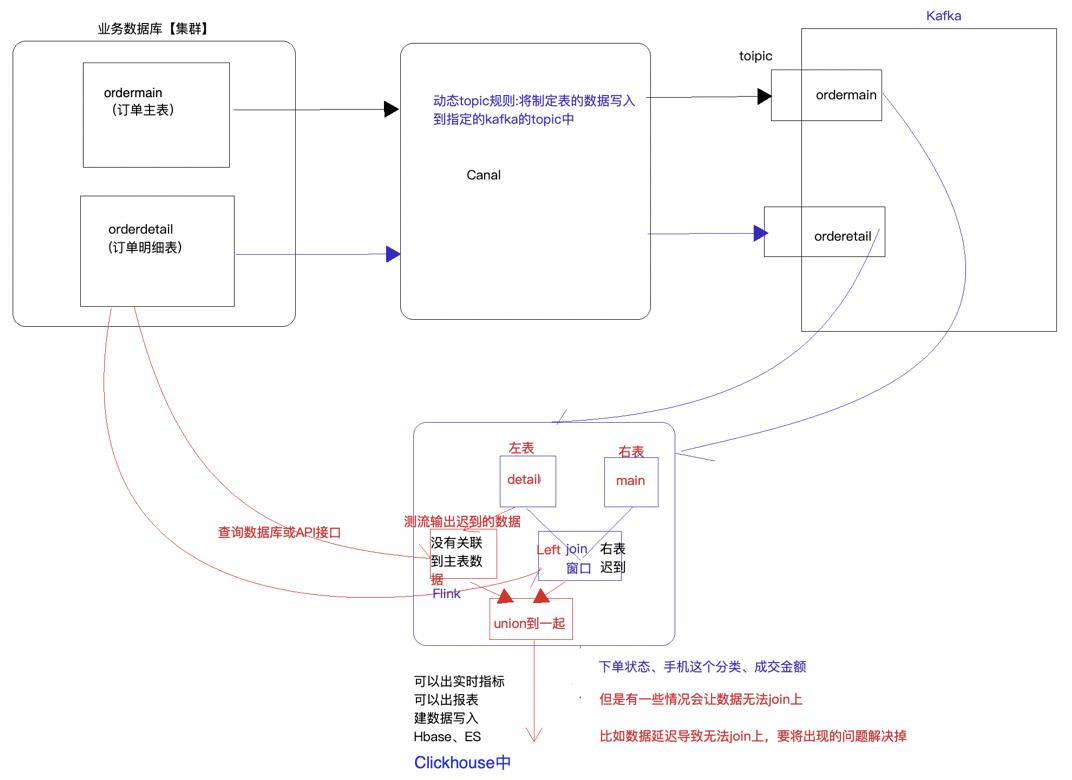
- 关于业务数据双流Join:
双流join最主要的问题是,两个流可能会有一个流存在迟到的现象:
- 左表数据迟到:比较严重,在left join后甚至不会有数据出现。
- 右表数据迟到:在left join后右表数据为null。
- 正常情况:左右表都有数据。
针对上面迟到数据的解决方案为:
首先,在两个流join时需要划分窗口,在窗口中调用coGroupFunction进行left join。那么可以在join前先让左表数据先通过一个与后面join时等长的窗口,这样如果左表数据迟到,在两个窗口中都必定迟到,由此在第一个窗口中可以将迟到数据测流输出进行收集(WaterMark进行判断)。在left join后,迟到的右表数据则体现为右表全为null。将左表迟到的流和主流进行union,再去数据库查询右表为空的数据来解决双流join中数据迟到的问题。
另一种解决方案是,想在join的同时去测流数据迟到的数据,但coGroupFunction没有对应的实现,需要进行源码的修改实现。
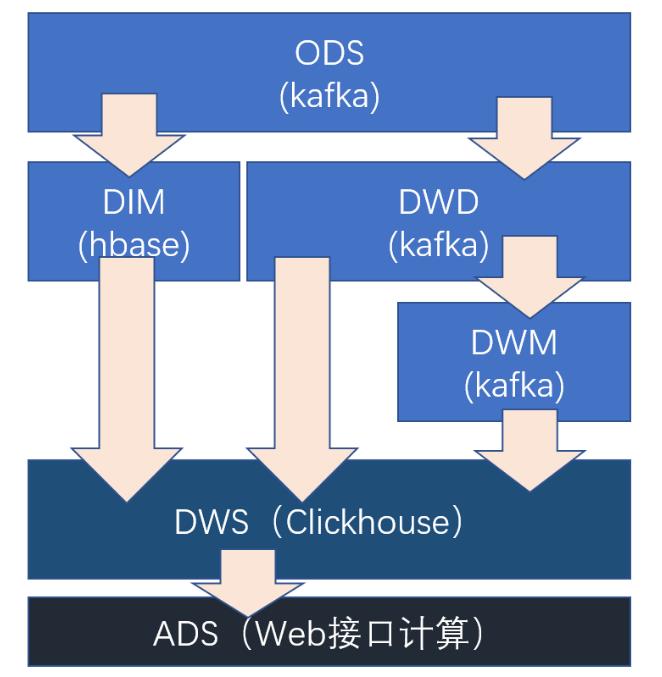
3. 实时数仓架构
4. 优化方案
- StateBackend的优化:使用RocksDB作为StateBackend,适合存储更多状态、有长窗口的状态(window state)、key value的数据较大的状态(上限2G)。还有个重要的优势在于可以增量checkpoint。
以上是关于Flink实时数据处理实践经验(Flink去重维表关联定时器双流join)的主要内容,如果未能解决你的问题,请参考以下文章