论文阅读之Syntax Encoding with Application in Authorship Attribution(2018)
Posted Icy Hunter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读之Syntax Encoding with Application in Authorship Attribution(2018)相关的知识,希望对你有一定的参考价值。
文章目录
摘要

我们提出了一种新的策略,将句子的语法分析树编码为可学习的分布式表示。所提出的语法编码方案是可证明的信息无损的。具体而言,为句子中的每个单词构建嵌入向量,对语法树中与该单词对应的路径进行编码。这些“语法嵌入”向量与句子中的单词(因此它们的嵌入向量)之间的一一对应使得将这种表示与所有单词级NLP模型相结合变得容易。我们通过经验展示了作者归属域上语法嵌入的好处,其中我们的方法改进了现有技术,并在五个基准数据集上实现了新的性能记录。
这篇文章提出一种语法树的编码方式,能够几乎无损地编码语法树。
引言
(节选)
迄今为止,利用句法信息的现有方法可分为两类。第一类可以被视为“句法特征工程”。在这种方法中,从句子的语法分析树中提取某些属性或统计信息作为语法特征。例如,提取的特征可能包括树的深度、树中某些结构模式的频率等(Massung等人,2013;Wang等人,2015)。这种方法的优点是,如果特征被认为与分类任务相关,则提取的特征可以用于任何类型的分类器。然而,这种方法的局限性在于语法树中包含的丰富结构信息在特征提取过程中丢失。此外,使用这种策略,模型设计者通常需要设计特定于其任务的语法特征提取器。
第二类可被视为“语法辅助句子编码”。这类方法基于神经网络模型。此类方法的示例包括TreeSTM(Tai等人,2015;Zhu等人,2015b)和递归神经网络(Socher等人,2011),其中网络根据输入句子的语法树进行结构化。经过训练后,网络能够以自下而上的方式将单词嵌入序列编码为表示整个句子的向量。值得注意的是,在这些方法中,编码的特征向量虽然包含语法信息,但主要用作输入句子的语义表示,其中利用的语法信息主要用于辅助语义表示。此外,这种方法不够灵活,无法与另一类流行的NLP模型CNN集成。
文章先分析了之前对利用句法树地方式,第一种类似特征工程,计算出句法树地一些统计特征如句法树地深度等进行分析,第二种就是结构性建模如使用Tree-LSTM将句法树自下而上编码,最终将句法信息融入到句子中,虽然使用了结构,但是其实可能结构信息并不完整,并且也不够灵活,不能与CNN等集成。
Syntax Encoding
几十年来,包括句法分析信息在内的有益于NLP模型的研究一直很活跃。句法特征工程是指从给定文本的句法分析树中静态提取特定领域特征的努力(Massung等人,2013;Wang等人,2015)。最近的尝试还包括利用句法分析树结构自下而上递归生成句子表示(Socher等人,2011;Zhu等人,2015b;Tai等人,2015;Zhu等,2015a)。
上述两类方法都有严重的局限性。前者的解析表示通常无法对解析树结构进行编码,而后者受到解析器所青睐的树结构的约束。此外,最近的分布式单词嵌入技术,如Glove(Pennington等人,2014)和W2V(Mikolov等人,2013),已被证明对给定语料库的有限语法知识进行编码(Andreas和Klein,2014)。这一缺点也促进了最近关于创建语法感知单词嵌入的研究,该研究利用单词在其周围上下文中的位置信息增强了分布式嵌入向量(Cheng和Kartsaklis,2015),这再次编码了有限的语法信息。
我们的语法嵌入方法克服了上面提到的限制。
嗯看不太懂,接下来我们就看看他到底怎么进行句法树编码的。
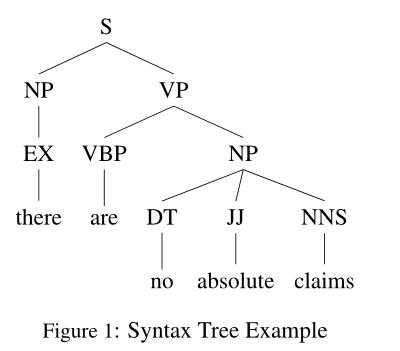

给定句子的句法结构可以由一棵树唯一地表示,我们称之为句法树。图1给出了这样一个语法树的示例。如示例所示,语法树具有标记节点。具体来说,每个节点的标签是一个“语法标记”,如S、NP、VP等,表示节点下树枝覆盖的单词序列的语法属性。例如,树的根总是用S(“句子”)标记,树下的树枝覆盖了整个句子。另一方面,树的末端或叶子的标签,如EX、VBP、JJ等,对应于该句子中每个单词的“词性”标签。我们将用T表示所有语法标记的集合。
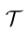 表示所有语法标记(S、NP、VP和EX、VBP等)的集合。
表示所有语法标记(S、NP、VP和EX、VBP等)的集合。

给定句子s的这种句法树结构,句子s中的每个单词w在树中都有一条唯一的路径,离开词根到达终点。
然后,单词w的这种“语法路径”可以由路径上的一系列节点标签表示。表1给出了语法路径的一些示例。下面的引理很容易验证。
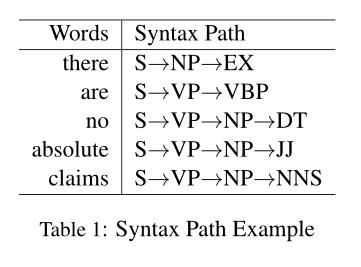
s表示一个句子,w表示一个单词。
每句话中,每个单词的句法树路径是唯一的。

引理1:
让一个句子s写成一系列单词(w1,w2,…,wn)。为每个单词位置i=1,2,…,n,设r(wi)表示单词wi的语法路径。设R:=(i,R(wi)):i=1,2,…,n是一个(无序)集合,精确地包含s中单词的所有语法路径。

在引理中,我们注意到R是一个无序集合。也就是说,无论R中路径的顺序如何,都可以从R中恢复语法树。

令 r(w) 为单词 w 在感兴趣的句子 s 中的句法路径。具体来说,r(w)可以写成序列(t1,t2,…,tL),其中L是路径r中的节点数,每个ti是一个句法记号。
这里无序就是说其实每个元组已经包含了单词位置以及路径信息,每个元组之间的顺序是不影响结果的。
r(wi)表示的是单词i的句法路径。
例如以上面那颗句法树为例
(3,(VP,NP,DT))就是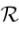 中的一个元素。L=3,t1为VP
中的一个元素。L=3,t1为VP

让欧几里得空间RK是我们将用于编码语法的嵌入空间。现在,我们描述一种将路径r(w)编码为向量r(w)的方法。

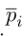 表示的是位置编码的1、2、3等的embedding向量。
表示的是位置编码的1、2、3等的embedding向量。
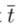 表示的就是句法标记VP,NP,DT等的embedding向量
表示的就是句法标记VP,NP,DT等的embedding向量
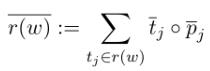 那么句法路径的表示就是位置和句法标记的元素积求和。
那么句法路径的表示就是位置和句法标记的元素积求和。
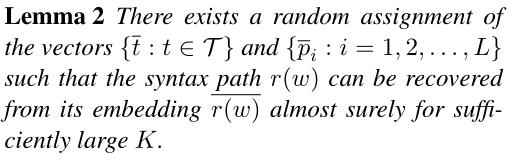
只要K足够大,上述编码句法树的方法将会是无损的。

然而,我们注意到,在实践中,当学习到标记嵌入和位置(整数)嵌入时,不再保证可以从其嵌入中恢复语法路径。对于受监督的任务尤其如此。在此类任务的训练过程中,与训练目标无关的信息必然被“挤出”,那些不提供区分特征的语法路径的表示被“拉近”。这将导致这些路径与其嵌入不可区分(因此不可恢复)。这也是在实践中不需要非常大的嵌入维度 K 的原因。
尽管如此,由于不同的监督任务可能具有不同的训练目标,因此适用于一项任务的“有损”语法编码可能对其他任务无效。因此,正如我们在本文中提出的那样,采用一种普遍适用的信息无损编码框架仍然是必不可少的。
在实战中,K其实不需要很大,但无损确实有必要,因为不同的任务需要保留的句法结构不同。
实验结果
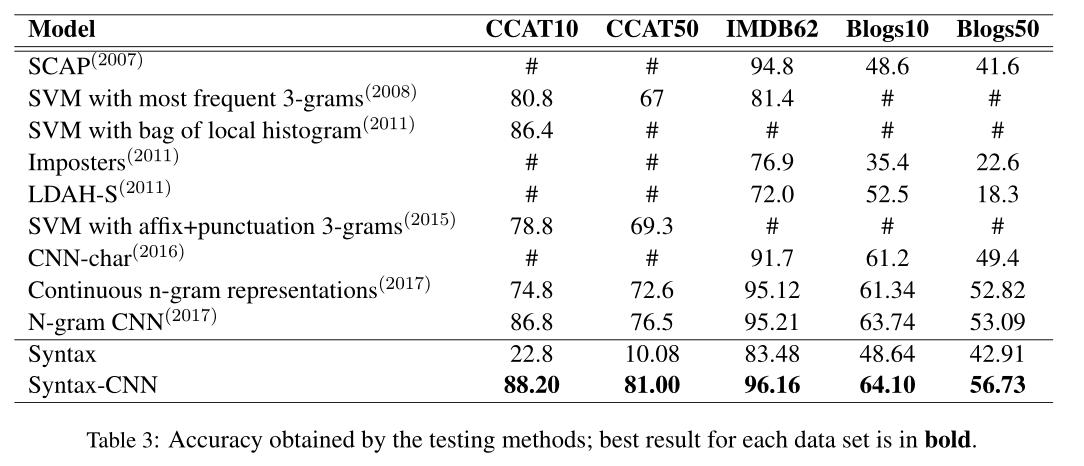
主要是看这篇文章的句法树编码了,CNN应该好懂。
只是可惜这文章代码没开源…
参考
Syntax Encoding with Application in Authorship Attribution
以上是关于论文阅读之Syntax Encoding with Application in Authorship Attribution(2018)的主要内容,如果未能解决你的问题,请参考以下文章