自动驾驶 Apollo 源码分析系列,感知篇:车道线 Dark SCNN 算法简述及车道线后处理代码细节简述
Posted frank909
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶 Apollo 源码分析系列,感知篇:车道线 Dark SCNN 算法简述及车道线后处理代码细节简述相关的知识,希望对你有一定的参考价值。
本文大纲
自动驾驶中的车道线检测思路
车道线检测是 ADAS 领域和高级别自动驾驶都非常重要的一环,属于环境感知和定位中的核心项。
人可以轻易分辨道路上的车道线,但是对于机器而言,却非常的难,人脑有先验知识,有极速的上下文理解能力,但机器而言只有一张 2 维的图片,然后从中寻找有意义的特征,再拟合成曲线表达式的形式。
车道线检测的研究由来已久,大概分 2 种算法流派:
- 传统 CV 算法,主要是边缘检测,然后通过霍夫变换检测直线,再聚类,再拟合,这种算法很初级,鲁棒性很差,但因为简单是绝大多数同学入门车道线检测的 helloworld 算法。
- AI 算法,主要是 CNN,也有人用 CNN + LSTM,AI 天生就适合提取语义特征,也容易达到端到端的效果。
Apollo 6.0 源码中车道线是采用 dark scnn,应该是 scnn 一种翻版,scnn 就是一种用于检测车道线的 cnn。
SCNN 算法思想
SCNN 全称是 Spatial CNN,2018 年的产物。
论文地址:https://arxiv.org/pdf/1712.06080.pdf
本质上就是一个 Encoder-Decoder 模型。
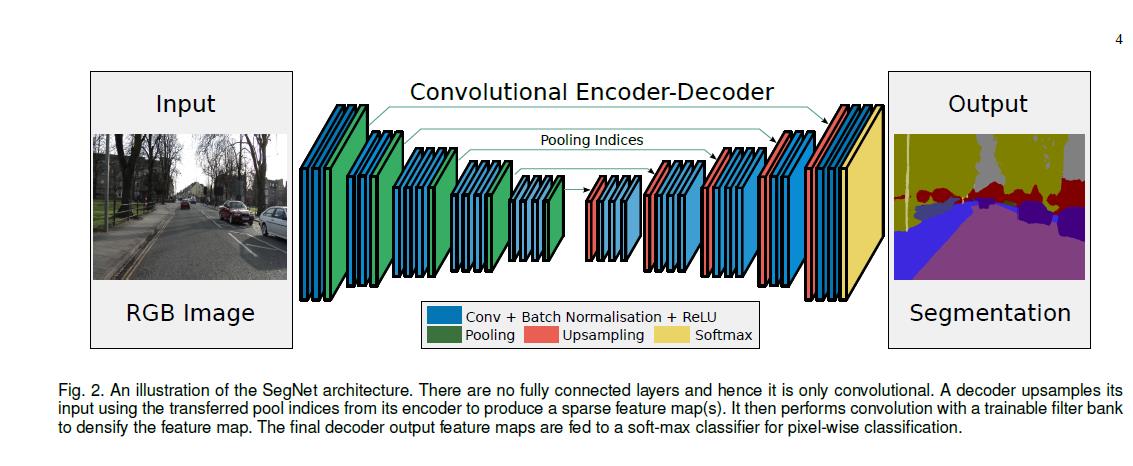
上面的图片是 Encoder-Decoder 在 CV 中的应用示例,一般用来做图像语义分割。
SCNN 本质上也是一种图像语义分割,只不过它是 2 值语义分割。
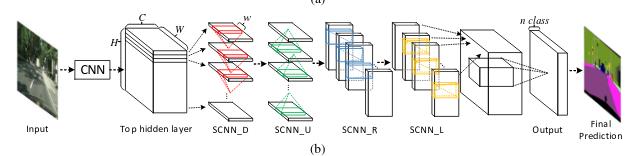
它最有价值的一点在于提出了一种逐行逐列信息传递的过程,因为这个过程能够更加有效抓取到细长的物体特征,毫无疑问,车道线正是这种细长的物体。
上图中 SCNN_D、SCNN_U、SCNN_R、SCNN_L 分别代表下、上、右、左 4 个方向去执行数据的前向传播。
SCNN 最多处理 4 条车道线,这让它模型更专注。
实际道路中肯定不止 4 条车道线,但车道线数量的变化对于模型挑战很大,把数量固定在 4 条能很大程度上减轻模型的复杂度和负担。
并且 4 条车道线大多时候对于摄像头而言已经够了,因为它代表了 3 车道:左车道、自车道、右边车道。

之前我自己用霍夫变换+聚类处理车道线检测的时候有个很头痛的问题就是聚类的个数是个头痛的事情,因为驾驶环境中车道线的数量是变化的,有时是 2 条,有时变成 3 条,有时是 4 条,然后又变成 3 条之类,如果采用 k-means 算法的话,这个 k 就很难确定,当然用 DBSCAN 聚类的话可以解决这个问题,但算法的高效性存疑。
我当时的想法是做“AI+传统算法融合”:
- 一个极度轻量的 AI 模型去预测画面有几条车道线。
- 用传统 CV 算法去检测、拟合。
后来我看到 SCNN 的思路时会心一笑,其实差不多,它直接一步到位用多分支 AI 模型就解决了问题,实在是妙。
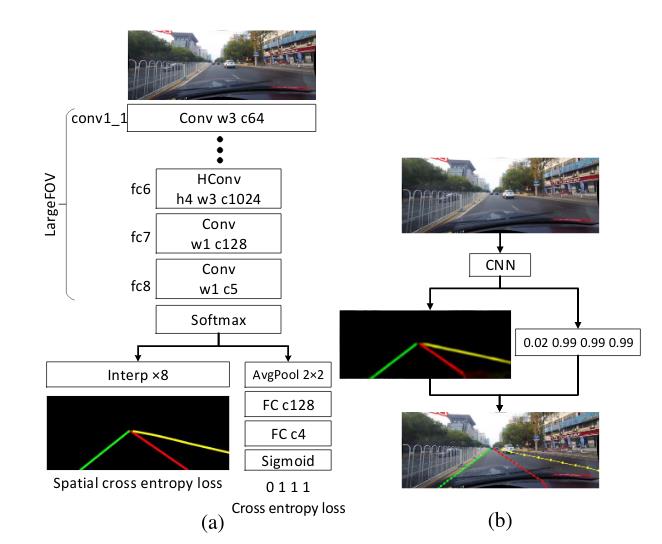
上图是 SCNN 车道线处理流程,左边分支应用 Encoder-Decoder 输出 heatmap,其实就是一张掩码图,代表了每个像素点是车道线的概率,右边分支做全局信息的预测,预测 4 条车道线存在的概率。
最终,根据右边分支的存在性概率向量,在左边的概率图上每隔 20 个像素寻找最高响应做采样,然后用 3次样条曲线完成拟合,车道线检测就这么愉快的结束了。
Apollo 中对应的 dark scnn 代码逻辑
前面一小节是 SCNN 论文算法思想,但 Apollo 中 scnn 是 dark scnn,我不知道 dark 的含义,但猜想肯定有些变化。
前面的文章讨论过车道线检测入口是 lane_detect_component,在其中的 onImageReceive 函数中处理,会调用 LaneCameraPerception 的 Perception 方法。
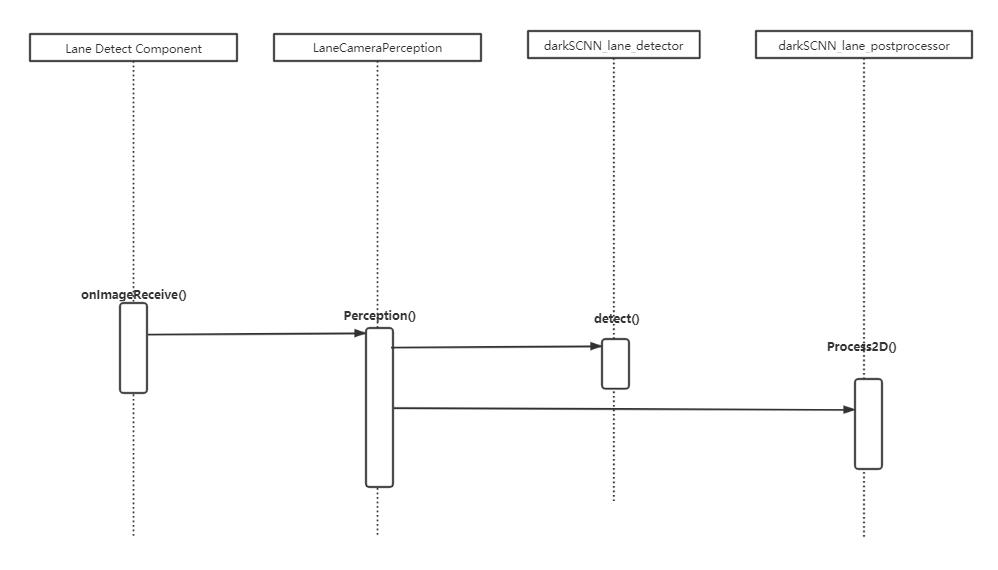
dark scnn 模型结构
定义文件位于:
modules/perception/production/data/perception/camera/models/lane_detector/darkSCNN/deploy.prototxt
借助于可视化工具 netron,可以看到它的结构。
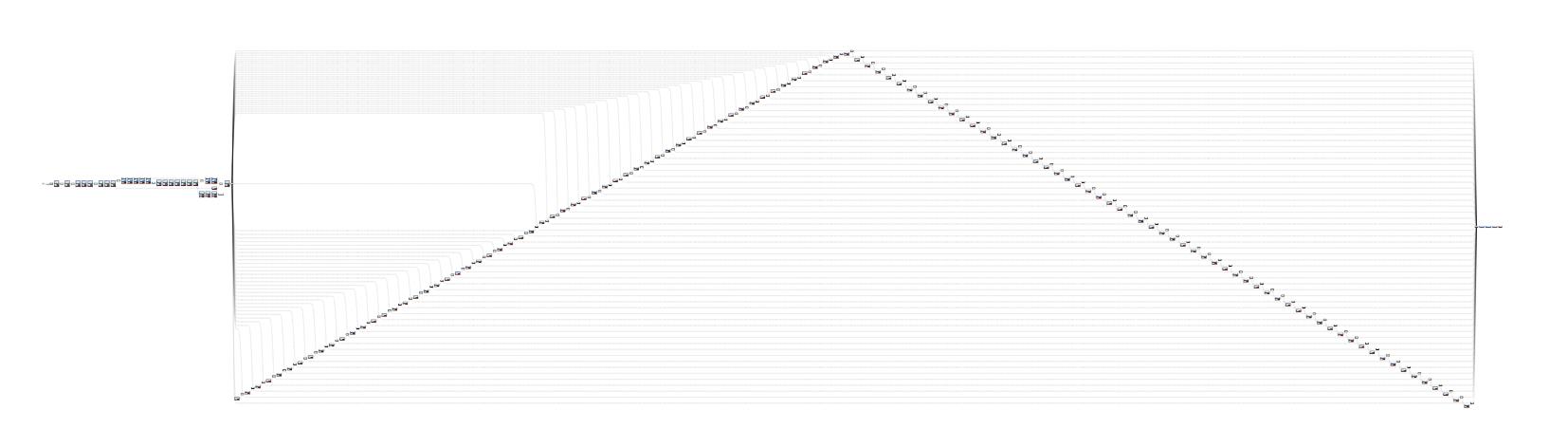
可以看到层次非常多,所以,还需要结合源文件中的注释。
name: "darknet-16c-16x-3d multitask TEST 960x384, offset L3:440, L4: 312, RM DET"
# SCNN part: kernel size 5, only Up-Down direction
###################### LANE #######################3
注释中提到模型要做多任务,这个多任务是什么呢?注释中也有提。
################## semantic segmentation output layer ###################
layer
name: "conv_out"
type: "Convolution"
bottom: "deconv_out"
top: "conv_out"
param
lr_mult: 1
decay_mult: 1
param
lr_mult: 1
decay_mult: 1
convolution_param
num_output: 13
kernel_size: 3
pad: 1
stride: 1
weight_filler
type: "msra"
layer
name: "softmax"
type: "Softmax"
bottom: "conv_out"
top: "softmax"
一个任务是做语义分割,也就是 SCNN 论文中提到的 4 条车道线,但在 dark scnn 中是 13 条。
另外一个任务是做灭点(vanishing Point)预测。
所以,任务有 2 个:
- 车道线语义分割
- 灭点预测
上面结构图中,如果放大来看,可以找到这两个分支。
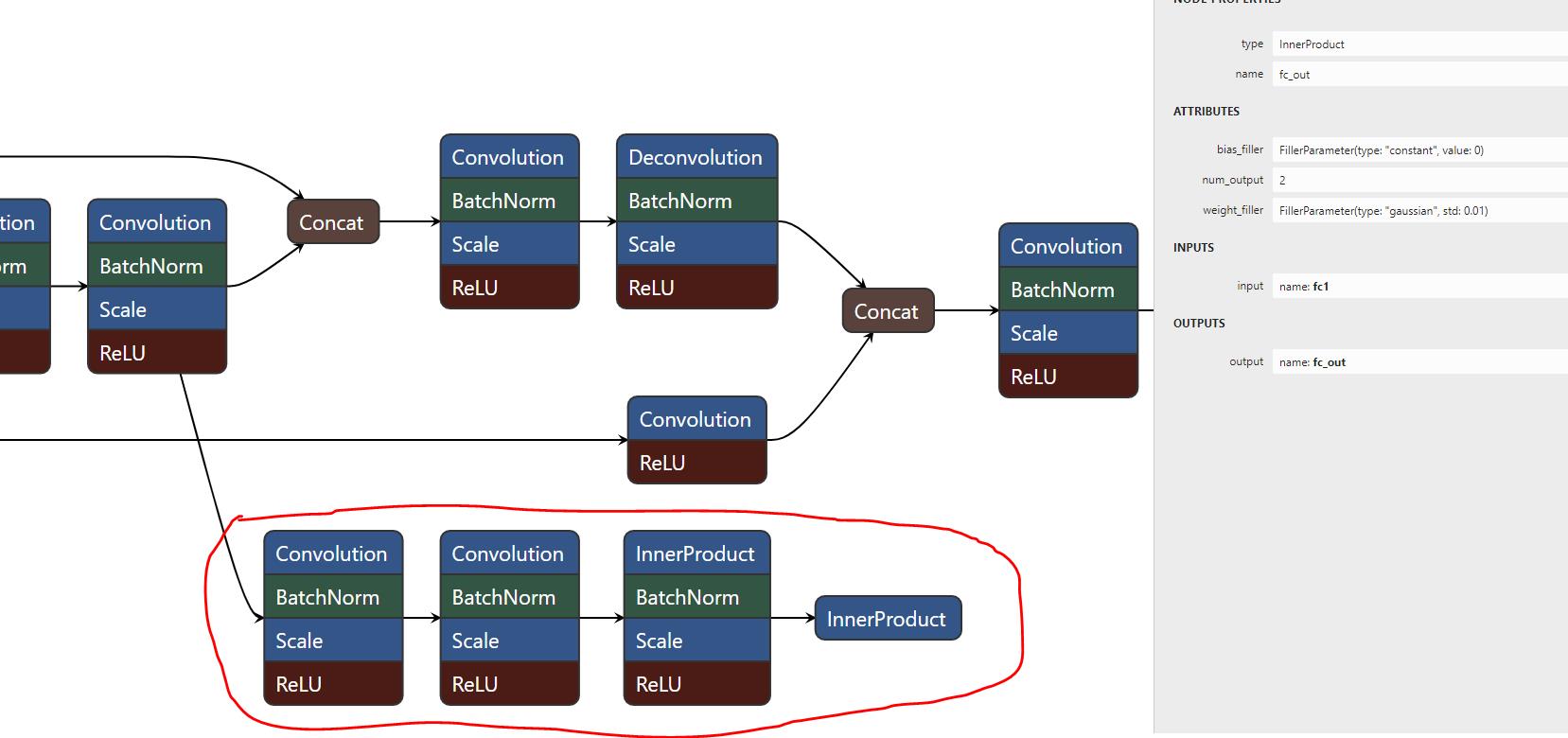
从 conv7_2 这一层引出了一个分支,最后是一个 FC 层,输出的只有 2 个值,也就是灭点的 x,y 坐标。
另外一个并列的长长的分支自然就是做语义分割。
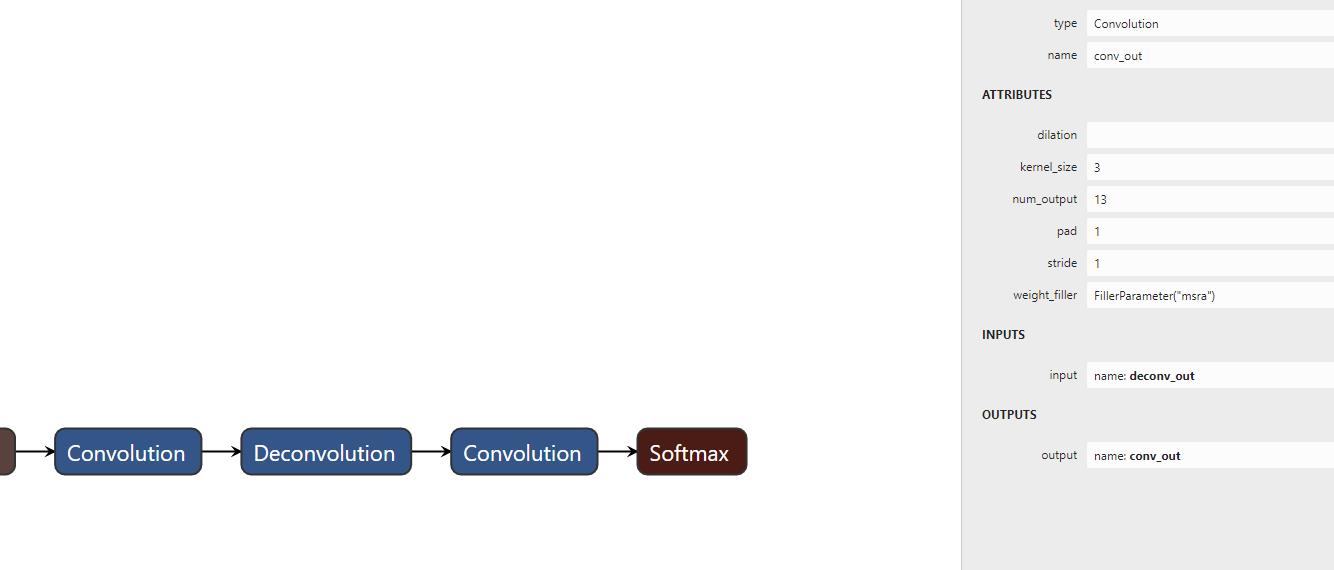
前面讲到做语义分割时分复用 Decoder-Encoder 技术,其实就是最后会采用反卷积手段去恢复输入数据的尺寸。
所以,我们也清楚地看到了,网络模型结构中有 Deconvolution 的存在。
最后的 Softmax 就是预测车道线的概率了。
SCNN 方向的简化
原始的 SCNN 论文中信息传递有 4 个方向,而 dark scnn 只保留了 2 个。
上图的小山顶提示了 dark scnn 先经过长长的 up 操作,再经过长长的 down 操作。
heatmap 对应代码逻辑
现在,我们知道了算法,也知道了模型结构,已经具备基础来阅读具体代码了。
首先关注的是 Apollo 代码如何从神经网络模型中提取车道线分割结果和提取灭点的结果。
具体代码在 dark_scnn_detector 中的 detect 中。

dark scnn 是 caffe2 的模型,里面的 blob 相当于 Pytorch 或者 Tensorflow 中的 Tensor。
需要适当的转换,在上面代码中用一个 vector 存放所有的概率图,这个概率图是用 opencv 中的 mat 表示,这个 vector 名叫 masks。
然后,检视所有的 masks 生成一张有颜色的图片,有无颜色根据每张 mask 中像素点的值是否超过阈值来决定,没有超过阈值的像素点值会设置为 0,这张有颜色的图片叫做 mask_color。
最后 mask_color 中的数据会被设置到 cameframe 中的 lane_detected_blob 对象上。
灭点提取
前面介绍的是如何提取车道线语义分割结果,这一节讲如何提取灭点信息。

dark scnn 模型有 2 个输出分支,其一是语义,其二是灭点。
上面的代码截图显示,vanishing point 的提取需要从 blob 中将它经过变换最终转换到原始输入图片中的坐标。
mask 2D曲线拟合
detector 负责模型检测,然后生成基础的车道线特征和灭点,存放在 cameraframe 当中。
后面自然需要处理这些信息,这些工作通过 posterprocessor 完成。
实际上由 DarkSCNNLanePostprocessor 完成。
核心方法是 Process2D,它的主要流程是这个:
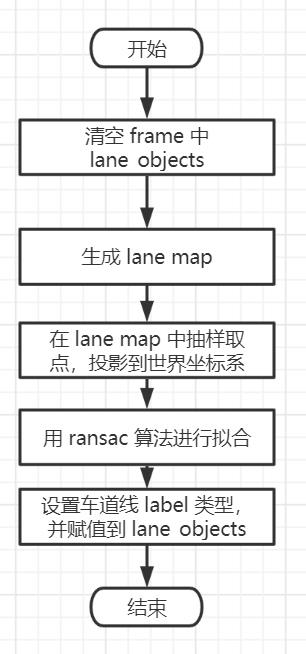
首先 lane_objects 是什么呢?
它是 cameraframe 中的变量,是一个 vector,存放的对象类型是 LaneLine,看名字就知道它是表示车道线的数据。
所以,在 Procce2D 函数开头,首先清空 lane_objects 是为了后续算法的结果存储在此处。

之前分析 detector 中的 detect 代码时有提到,提取到的车道语义分割信息会形成 mask_color 最终转换成 lane_detected_blob。
在这里,基于这份数据进行数据拷贝,产生 lane_map 对象做后期算法处理。
1. 采样
lane_map 中有很多点,直接全部拟合效率不高,所以,需要采样再拟合。
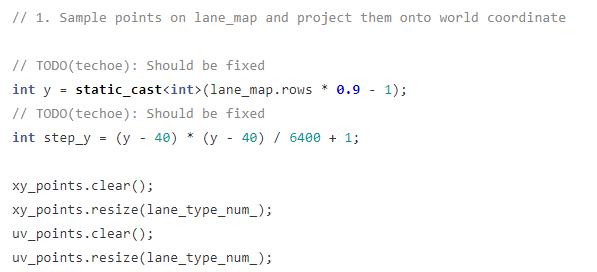
y 是动态计算的,由神经网络的输出的 blob 高度决定,step_y 代表采样步幅。
假设 lane_map.rows 是 480,那么 y 就是 433,那么 step_y 就是 25.
那就代表需要采样 18 次。
xy_points 应该存放的是所有的车道线的地面物理坐标。
uv_points 应该存放的所有车道线的图像像素坐标。

采样是一个自顶向下,自左向右的过程。

首先要将 Lane_map 中的值取出来,这个值是有范围的。
0 ~ 13.
表示的是车道线的位置关系,总共有 13 种,注意是位置关系。

按照这个定义,结合代码,我绘制了一张图片。
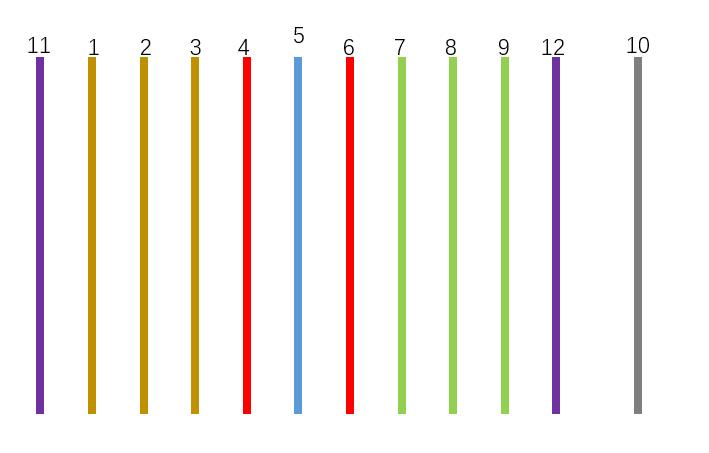
4和6代表自车道左右两根线。
5 表示车道变道时,车子中间的那根。
11 和 12 表示马路牙子,道路边沿。
11 表示未知的其它类型。
因此,提取 Lane_map 中像素值时,也会根据它的值进行左右区分。

因为车道线在 lane_map 中有宽度,所以我们只需要提取车道线的边缘像素点就好了。
在这份代码中,只关注前方 300 米,左右 30 米的区域,其它的会被过滤掉。
这些参数在 postprocessor.h 中有定义。
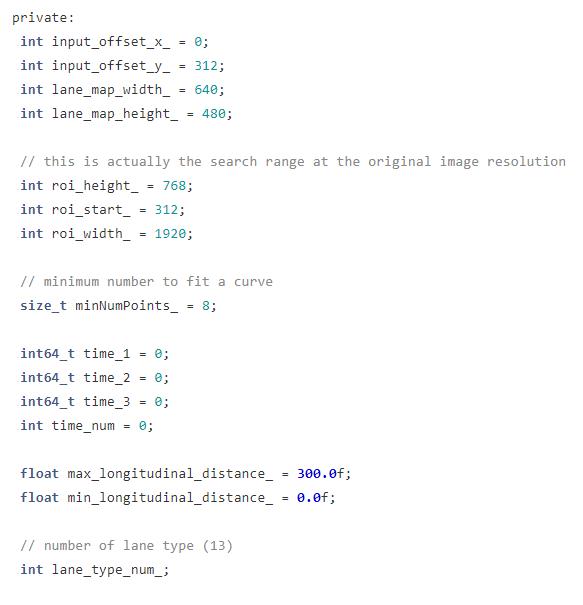
在提取 xy_points 的时候,重点关注这段代码。
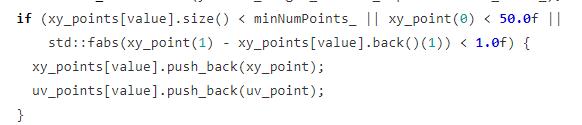
当前 value 值是否转换成 xy 或者 uv 坐标有 3 个条件:
- 当前 value 所代码的车道线坐标数量小于最小的拟合数量
- 纵向坐标小于 50
- 横向坐标与上一次存储的坐标值很近,没有超过 1 米。
3 个条件满足其一就可以了。
大致思路是尽量满足在车辆前方 50 米内取更多点,并且照顾到车道线与车辆车姿的相对角度,毕竟车道线也可能在相机中呈现倾斜的角度。
因为 step_y 的存在,所以,lane_map 不是每一行都会扫描到,理想状态下,进行一次采样,xy和uv容器中能保持 10 个左右数量的采样点。
有了采样点就可以进行曲线表达式拟合了。
2.车道线拟合
车道线是用 3 次多项式表示。

也就是:
y
=
a
∗
x
3
+
b
∗
x
2
+
c
∗
x
+
d
y=a*x^3+b*x^2+c*x+d
y=a∗x3+b∗x2+c∗x+d
系数有 4 个,拟合的过程就是通过采样点得到这 4 个系数的值。

拟合采用的是 Ransac 算法,相比于最小二乘法它能够更好处理离群点带来的干扰。
3. 填充 lane_object 对象

c0s 的作用是保存车道线在纵向距离 3 米处,横向距离分别是多少,后面的代码会应用到。
之前讲到 value 为 5 时,车道线在车子中央,那么所有的车道线位置就可能需要调整,因为车子可能向左变道中,也可能是向右变道中。

如果代表 egoLeft 的车道线坐标数量不够,而 center 车道坐标够那么就交换数据,也就是把 center 这根线当作是 egoLeft。
egoRight 的逻辑也是类似。
但优先处理左边情况。

如果左边一条车道都没有,11 也就是左边的马路牙子会被当成 egoLeft。
如果右边一条车道都没有,12 也就是右边的马路牙子会被当成 egoRight。
lane_objects 中存放的是 LaneLine 对象,里面包含了车道线的相关信息。
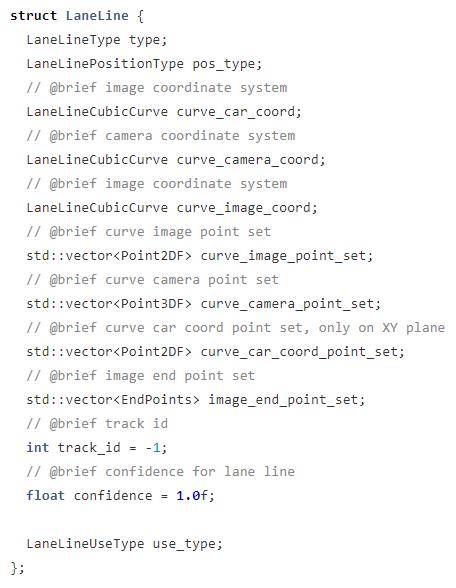
拟合完成后就需要填充这些信息。
首先就是 Position Tag
cur_object.pos_type = spatialLUT[i];
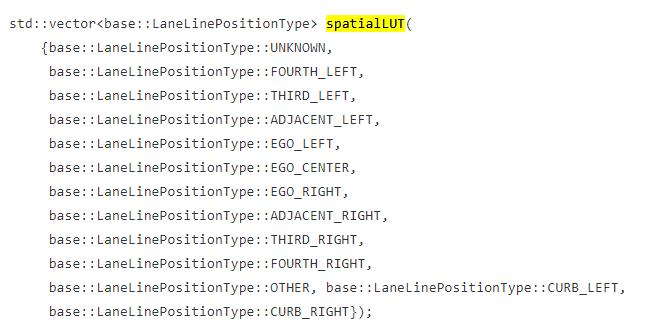
车道线要按照位置的左右顺序处理,如果某根车道线在 x = 3 处,y 的大小不符合常理,那边这根车道线就过滤掉了。

并且,如果左右路牙的横向距离不对劲的话,也需要被过滤掉。

上面的代码会保存车道线的 4 个属性:
- 两个端点的坐标
- 曲线表达式的系数
- 曲线表达式的坐标值集合
- 置信度
4. 当车辆行驶在一条车道线的情况处理
center lane 存在时有 3 种情况处理:
- 不存在这种情况
- 在左边
- 在右边
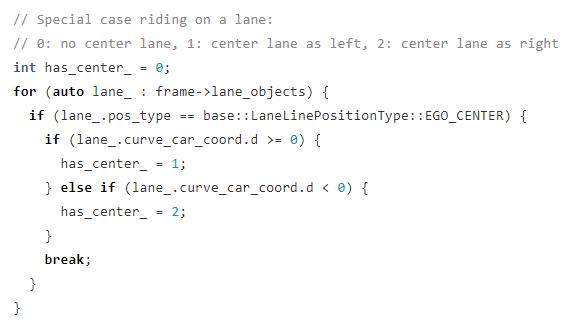
因为 x 轴是横轴,y 轴是纵轴,根据表达式 d 系数就可以判断它在左边还是右边。
d > 0 左边
d < 0 右边

如果 center lane 在车辆左边,那么左边所有的车道 id 减 1,按这种逻辑应该是假设这是一种向右变道的行为。
反之 center lane 在右边,车道 id 全部加 1,对应向左变道的行为。
自此,车道线的 2D 拟合过程全部完成。
3D 车道线检测
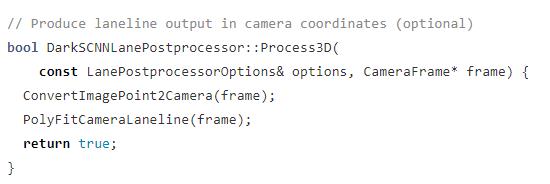
3D 拟合首先要进行坐标变换,将图像坐标转换到相机坐标。

它通过相机的 pitch 和 height 参数,结合内参、外参最终生成车道线的相机坐标系下的 x,y,z。

在相机坐标系下又进行了一轮拟合,生成新的表达式,结果同样存放在 lane_objects 当中。
总结
整个一轮代码分析下来,过程比较多,但好在是流水线的形式,理解起来相对比较容易。
Apollo 中对于车道线考虑还是比较多,特别是对于车道线的位置问题处理得很谨慎,因为自动驾驶车辆车道定位非常的重要。
以上是关于自动驾驶 Apollo 源码分析系列,感知篇:车道线 Dark SCNN 算法简述及车道线后处理代码细节简述的主要内容,如果未能解决你的问题,请参考以下文章