离群点检测和新颖性检测
Posted big_matster
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了离群点检测和新颖性检测相关的知识,希望对你有一定的参考价值。
引言
在异常检测领域中,我们常常需要决定新观测点是否属于与现有观测点相同的分布, (则称它们为inlier),或被认为是不同的(outlier).
在这里,必须做出两个重要的区别:
- 异常值检测:outlier detection
训练数据包含异常值,这些异常值被定义为远离其他异常值的观察值,因此,异常值估计器试图训练数据中最集中区域。忽略不正常观察。 - 新颖点检测
训练数据不受异常值的污染,我们有兴趣检测新观测是否是异常值,这种情况下, 异常值也被称为新颖点。
异常值检测和新颖性检测都属于异常检测,都是用来检测异常的,不常见一些观察值。
异常值检测是一种无监督的方法,新颖点检测是一种半监督的异常检测方法。在异常值检测情况下,异常值不能形成密集的簇,因为异常值估计器假设异常值总是位于低密度区域。相反,在新颖检测背景下,新颖点可以形成密集的簇,只要它们处于训练数据的低密度区域中。
SKlearn框架提出了一套机器学习工具,可用于新颖性检测和异常值检测,这个 策略通过从数据中以无人监督的方法学习对象来实现的。
estimator.fit(X_train)
新的观测值可以用如下的方法做预测,或判断。
estimator.predict(X_test)
这里,正常的点(内部点,inliers)的标签是1,异常点是-1.预测方法利用估计器计算原始评分函数的阈值,可以通过scores-samples方法访问该评分函数,而阈值可以通过contamination参数来控制。
- decision_function方法也可以从评分函数中定义,负值是异常值,非负值是内部点:
estimator.decision_function(X_test)
异常值检测(Outlier Detection)
下图是sklearn中离群点检测算法的比较,局部异常因子(LOF)不现时黑色决策边界,因为当用于异常值检测时,其没有predict方法用于新数据。
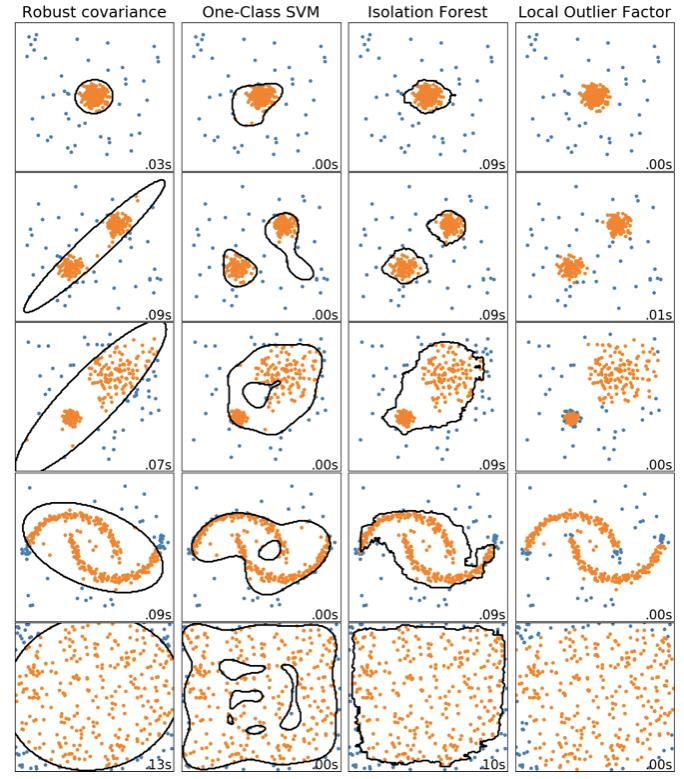
ensemble.IsolationForest(孤立森林)和neighbors.LocalOutlierFactor(局部异常因子)在这里的数据集上表现得相当好。 已知svm.OneClassSVM对异常值敏感,因此对异常值检测的效果不佳。 最后,covariance.EllipticEnvelope假设数据是高斯数并学习椭圆。
新颖性检测
-
新颖性检测一般是这样一种场景:考虑具有p维特征的、具有相同分布的n个观察值构成的数据集。 现在考虑我们再向该数据集添加一个新的观察值。 若新观察值与其他观察值的结果有不同,我们可以怀疑它是否regular,即它是不是来自同一个分布。或者恰恰相反,若它另与其他值非常相似,我们无法将其与原始观察值区分开来。这是新颖性检测工具和方法所解决的问题。
-
一般来说,新颖点检测将学习一个粗略的边界,界定初始观测分布的轮廓,绘制于p维空间空间中。 然后,如果新来的观察值位于边界划分的子空间内,则认为它们来自与初始观测相同的种类。 否则,如果他们位于边境之外,我们可以说他们是不正常的。
-
One-Class SVM是一种新颖性检测的手段,在sklearn框架下,它可以从svm模块中调用到(svm.OneClassSVM)。它需要选择内核和标量参数来定义边界。 通常选择RBF内核,尽管没有确切的公式或算法来设置其带宽参数。 这是scikit-learn实现中的默认值。ν参数,也称为one-class SVM的边界,对应于在边界外发现新的但有规律的观察的概率。
sklearn.svm.OneClassSVM
class sklearn.svm.OneClassSVM(kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1, random_state=None)[source]
一种用于异常检测的无监督方法。
其参数的具体含义请查看官方使用文档:

它的属性有:

最常用的两个方法:
训练和预测

离群点检测
离群点检测:在很多领域中具有广泛的应用,离群点检测的算法也各种各样,各种类型各种算法难以计数,我们研究是提出新的效果更好的离群点检测方法。(模型)
离群点检测,整体我认为包含有3部分,分别是**:数据集、模型、结果**。
数据集
离群点检测所用的数据集一般包含有合成数据集与真实数据集。那么我们从相对初始的数据集开始进行处理,一步步进行介绍。
对数据处理,我认为基本包含以下几个过程:
- 对数据集中缺失数据的处理
- 特征编码
- 正则化、特征缩放、标准化等。
- PCA降维,看看数据的样子,重要特征分析。
- 对数据集中的特征进行分析,构建相关系数矩阵,绘制heatmap图。
数据集中缺失数据的处理
现实生活中,收集到的原始数据一定经常存在缺失值的现象,部分UCI数据集上公开的数据也存在缺失,针对这个现象,在机器学习领域,我们一般的操作是用均值填补缺失值,换言之,如果矩阵第 i i i行第 j j j列缺失了某个值,那么我们就用第 j j j列的平均值去填补这个缺失值,据我了解,在实际应用中,还有用众数、中位数等方式去填补,但很显然,没有人用最大值和最小值等极端的方式去填补。
特征编码
针对现实世界中的各种现象,为了能将其进行计算,我们通常要用到特征编码技术。比如羊,狗等,收集到的数据可能在某一列,它的值是羊狗之类的文字,这种我们无法直接进行计算,需要有某种方式能将其转换成实数。一个很自然的想法是,用1表示羊,用2表示狗,等等。但是,这种方式存在一个问题,什么问题呢?这样子的话,就默认狗比羊大,它们之间这种表示方式的话,就存在了顺序关系,但其实应该是没有顺序关系的。那用什么方式呢?one-hot编码。
one-hot编码是一种很常见的特征编码方式,还以上段中的羊、狗的方式举例说明,因为我们有两个类(羊、狗)那么,我们可以用10.01的二进制方式来表示,这样两个样本之间的距离是1 ,不存在谁比谁更大更好的关系。
除了one-hot编码之外,还有虚拟编码、效果编码、特征散列化、分箱计数等方法。后续用到什么编码技术,然后学习什么编码技术,全部都将其搞定都行啦的样子与打算。
特征缩放和标准化等
常见的方式包括:
- max-min归一化
- zscore标准化
离群点检测算法分类

总结
慢慢的将各种模型算法及各种技术,全部将其搞定都行啦,研究透彻即可!全部将其完整搞全面化。
以上是关于离群点检测和新颖性检测的主要内容,如果未能解决你的问题,请参考以下文章