Java学习总结(21)——XML文档解析:DOM解析,SAX解析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java学习总结(21)——XML文档解析:DOM解析,SAX解析相关的知识,希望对你有一定的参考价值。
一.XML简介
1.可扩展性标记语言(eXtensible Markup Language)
2.XML用于描述数据
3.应用场合:
(1)持久化存储数据
(2)数据交换
(3)数据配置
4.XML语法
(1)文档类型:
在编写XML文档时,需要先使用文档声明,声明XML文档的类型。
最简单的声明语法:
<?Xml version=”1.0” ?>
用encoding属性说明文档的字符编码:
<?Xml version=”1.0” encoding=”GB2312” ?>
(2)元素
对于XML标签中出现的所有空格和换行,XML解析程序都会当标签中的内容进行处理,例如:下面两段内容的意义是不一样的:

由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,使用换行和缩进等方式来让原文中的把内容清晰可读的“良好”书写习惯可能要被迫改变
(3)注释
XML文件中的注释采用:“<!--注释内容-->”格式
注意:
XML声明之前不能有注释
注释不能嵌套
(4)格式:
必须有XML声明语句
必须有且仅有一个根元素
标签大小写敏感
属性值用双引号或单引号
标签成对
元素正确嵌套
例1(联系):
使用XML描述下表中的学生成绩信息,XML文件为student.xml
XML表示如下:
<?xml version="1.0" encoding="GBK"?>
<students>
<student>
<id>1</id>
<name>张同</name>
<subject>java</subject>
<score>89</score>
</student>
<student>
<id>2</id>
<name>李佳</name>
<subject>sql</subject>
<score>58</score>
</student>
</students>将文件拉入浏览器看是否可以显示:
显示结果:
二.DOM(Doncument Object Model)解析
1.DOM解析是将XML文件在的内存中换成一个文档对象模型(通常称为DOM树),应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,DOM解析的机制也被称为随机访问机制。
注意:DOM解析对内存的需求比较高
2.DOM解析的步骤:
(1)建立DocumentBuilderFactory
(2)建立DocumentBuilder
(3)建立Document
(4)建立NodeList

(5)进行XML信息读取
3.DOM数模型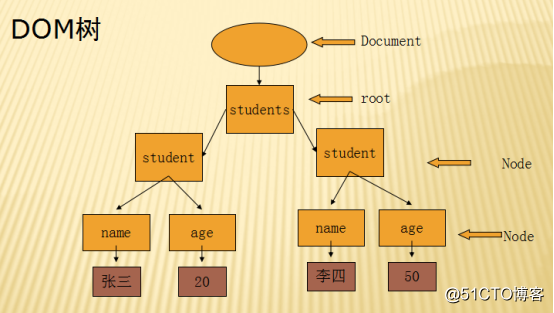
例2(DOM解析XML文件,我们以刚才写好的XML文件为例):
package org.xml.dom;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
public class DOMParserDemo {
public static void main(String[] args) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();// 1.建立DOM工厂
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();// 2.获得DOM解析器
Document document = builder.parse("e:" + File.separator
+ "userinfo.xml");// 3.指定解析的文件路径,将XML文件在解析成DOM树
NodeList nodelist = document.getElementsByTagName("province");// 根据标签名获取获取所有该标签名的节点
String value = nodelist.item(3).getFirstChild().getTextContent();// 获取节点中的内容
System.out.println("解析节点名称为province的第三个元素中的内容为:" + value);
System.out.println("获取节点名称:" + nodelist.item(3).getNodeName());
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:

例3(动态创建XML文件):
package org.xml.dom;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Text;
public class DOMCreateDemo {
public static void main(String[] args) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();// 1.创建DOM工厂
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();// 2.获取DOM解析器
Document doc = builder.newDocument();// 3.新建文档
Element students = doc.createElement("students");
Element student = doc.createElement("student");
Element id = doc.createElement("id");
Element name = doc.createElement("name");
Element subject = doc.createElement("subject");
Element score = doc.createElement("score");
Text idtext = doc.createTextNode("1");
Text nametext = doc.createTextNode("王昭君");
Text subjecttext = doc.createTextNode("java");
Text scoretext = doc.createTextNode("99.4");
students.appendChild(student);
student.appendChild(id);
student.appendChild(name);
student.appendChild(subject);
student.appendChild(score);
id.appendChild(idtext);
name.appendChild(nametext);
subject.appendChild(subjecttext);
score.appendChild(scoretext);
doc.appendChild(students);
TransformerFactory factory2 = TransformerFactory.newInstance();
Transformer tf = factory2.newTransformer();
tf.setOutputProperty(OutputKeys.INDENT, "yes");//自动换行
tf.setOutputProperty(OutputKeys.ENCODING, "GBK");
DOMSource soure = new DOMSource(doc);// 生成DOMSource里边包含了doc对象
StreamResult rs = new StreamResult(new File("f:" + File.separator
+ "student.xml"));//StreamResult封装了目标输出文件
tf.transform(soure, rs);//开始写入
System.out.println("student.xml文件生成成功......");
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
三.SAX(Simple APIs for XML)解析
1.SAXs是一个用于处理XML事件驱动的“推”模型,在读取文档时激活一系列事件,这些事件被推给事件处理器,然后由事件处理器提供对文档内容的访问
2.通常用于查找,读取XML数据
3.SAX解析步骤:
(1)编写SAX解析器,该解析器类继承自DefaultHanderler类,同时覆写相关方法
(2)建立SAX解析工厂:
(3)构造解析器:
(4)解析XML:
例4(利用SAX解析XML文档):
(1)自定义SAX解析器
package org.xml.saxdemo;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
//自定义解析器
public class MySAXHandler extends DefaultHandler {
// 文档开始解析时自动调用该方法
@Override
public void startDocument() throws SAXException {
System.out.println("XMl文档开始解析..");
}
// 开始解析元素时,自动调用此方法
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.out.print("<" + qName);
for (int i = 0; i < attributes.getLength(); i++) {
System.out.print(" " + attributes.getLocalName(i) + "=""
+ attributes.getValue(i) + """);
}
System.out.print(">");
}
// 元素解析结束时自动调用该方法
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("</" + qName + ">");
}
// 解析文本数据时自动调用该方法
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.print(new String(ch, start, length));
}
// 文档解析结束时自动调用该方法
@Override
public void endDocument() throws SAXException {
System.out.println("文档解析结束..");
}
}
(2)测试解析XML文件
package org.xml.saxdemo;
import java.io.File;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class SAXDemo {
public static void main(String[] args) {
MySAXHandler handler=new MySAXHandler();
//1.建立sax解析工厂
SAXParserFactory factory=SAXParserFactory.newInstance();
//2.构造解析器
try {
SAXParser parser=factory.newSAXParser();
//3.解析XML
parser.parse("e:"+File.separator+"userinfo.xml",handler );
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
例5(解析XML文档并将其封装如JavaBean对象中):
(1)编写JavaBean代码:
User对象:
package org.xml.saxbean2;
import java.util.List;
public class User {
private String id;
private String name;
private List<Address> adds;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<Address> getAdds() {
return adds;
}
public void setAdds(List<Address> adds) {
this.adds = adds;
}
@Override
public String toString() {
return "User [id=" + id + ", name=" + name + ", adds=" + adds + "]";
}
}
Address对象:
package org.xml.saxbean2;
public class Address {
private String type;
private String province;
private String city;
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Override
public String toString() {
return "Address [type=" + type + ", province=" + province + ", city="
+ city + "]";
}
}
(2)自定义解析器:
package org.xml.saxbean2;
import java.util.*;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
// SAX解析器
public class MySAXHandler extends DefaultHandler {
private User user;
private Address address;
private List<Address> addressList;
private List<User> userList;
private String text; // 存储文本
// XML文档开始解析时自动调用该方法
@Override
public void startDocument() throws SAXException {
System.out.println("开始读取XML文档..");
}
// 开始解析文档元素时自动调用该方法
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if ("users".equals(qName)) {
userList = new ArrayList<User>();
} else if ("user".equals(qName)) {
user = new User();
} else if ("adds".equals(qName)) {
addressList = new ArrayList<Address>();
} else if ("address".equals(qName)) {
address = new Address();
address.setType(attributes.getValue(0));
}
}
// 解析文本数据时调用
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
text = new String(ch, start, length);
}
// 元素解析完毕时开始调用
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if ("id".equals(qName)) {
user.setId(text);
} else if ("name".equals(qName)) {
user.setName(text);
} else if ("province".equals(qName)) {
address.setProvince(text);
} else if ("city".equals(qName)) {
address.setCity(text);
} else if ("address".equals(qName)) {
addressList.add(address);
} else if ("adds".equals(qName)) {
user.setAdds(addressList);
} else if ("user".equals(qName)) {
userList.add(user);
}
}
// 文档解析完毕时开始调用
@Override
public void endDocument() throws SAXException {
for (User user : userList) {
System.out.println(user);
}
}
}
(3)测试代码
package org.xml.saxbean2;
import java.io.File;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class SAXDemo {
public static void main(String[] args) {
SAXParserFactory factory=SAXParserFactory.newInstance();
try {
SAXParser parser=factory.newSAXParser();
parser.parse(new File("e:"+File.separator+"userinfo.xml"),new MySAXHandler());
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
例5(解析网络XML文档,获取当前天气预报):
(1)编写天气预报JavaBean
(2)自定义SAX解析器
(3)测试SAX解析,获取当前天气信息
以上是关于Java学习总结(21)——XML文档解析:DOM解析,SAX解析的主要内容,如果未能解决你的问题,请参考以下文章
javaweb学习总结十一(JAX对XML文档进行DOM解析)