深潜Kotlin协程(十四):共享状态的问题
Posted RikkaTheWorld
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深潜Kotlin协程(十四):共享状态的问题相关的知识,希望对你有一定的参考价值。
系列电子书:传送门
在开始之前,先看看下面的 UserDownload 类。它允许我们通过 id 来获取用户信息或获取之前下载的所有用户信息。这个实现有什么问题呢?
class UserDownloader(
private val api: NetworkService
)
private val users = mutableListOf<User>()
fun downloaded(): List<User> = users.toList()
suspend fun fetchUser(id: Int)
val newUser = api.fetchUser(id)
users.add(newUser)
请注意这里防御型拷贝 toList,这样做是为了避免读取下载返回的对象和向可变列表中添加元素之间的冲突。我们也可以使用只读列表(List<User>)和读写属性(var)来修饰 users。这样,我们就不需要做防御型拷贝,下载的信息也完全不需要被保护,但是我们会降低向集合中添加元素的性能。我个人更喜欢使用后者,但我决定以使用可变集合的方法为例,因为我在现实项目中经常看到这种做法。
上面的实现并没有为并发使用做好准备,每次 fetchUser 调用都会修改 users。只要这个函数没有同时在一个以上的线程中调用,就没有问题。但因为它可以同时在多个线程上启动,所以我们称 users 是一个共享状态,因此它需要被保护。这是因为并发修改会导致冲突。这个问题如下所示:
class FakeNetworkService : NetworkService
override suspend fun fetchUser(id: Int): User
delay(2)
return User("User$id")
suspend fun main()
val downloader = UserDownloader(FakeNetworkService())
coroutineScope
repeat(1_000_000)
launch
downloader.fetchUser(it)
print(downloader.downloaded().size) // ~998242
因为多个线程与同一个实例交互,所以上面的代码将打印一个小于1,000,000的数字(例如998242),或者它可能会抛出异常。
Exception in thread “main”
java.lang.ArrayIndexOutOfBoundsException: 22
at java.util.ArrayList.add(ArrayList.java:463)
…
这是修改共享状态会遇到的经典问题。为了更清楚的理解它,我将展示一个更简单的示例:用多个线程给一个整数递增。我使用 Dispatchers.Default 调用 massiveRun,它会启动1000个协程,每个协程操作1000次递增,在这些操作之后,结果的数字应该是1,000,000(1,000 * 1,000)。但是,如果没有任何数据同步,实际结果会因为冲突而更小。
var counter = 0
fun main() = runBlocking
massiveRun
counter++
println(counter) // ~567231
suspend fun massiveRun(action: suspend () -> Unit) =
withContext(Dispatchers.Default)
repeat(1000)
launch
repeat(1000) action()
要理解为什么结果不是1,000,000,请想象这样一个场景:两个线程试图同时增加相同的数字。假设初始值是0,第一个线程当前接收到的值是0,然后 CPU 立马决定切换到第二个线程,第二个线程接收的数字也为0,然后将其增加1,并存储在变量中。我们切换到第一个线程之前结束的地方:它的值为0,所以它将递增为1并存储它。最终变量将是1,但它应该是2。这就是一些操作丢失的问题。
阻塞同步
上面的问题可以使用从 Java 提供的经典工具来解决,比如同步块或同步集合。
var counter = 0
fun main() = runBlocking
val lock = Any()
massiveRun
synchronized(lock) //这里我们阻塞了线程!
counter++
println("Counter = $counter") // 1000000
这个解决方案有效,但也有一些问题。最大的问题是,在同步块中不能使用挂起函数。第二个是,当一个协程在等待轮到它的时候,这个同步块阻塞了线程。我希望在学习了Dispatcher协程调度器一章之后,你能理解我们并不想阻塞线程,因为它有可能是主线程。为什么要浪费这些资源呢?我们应该使用一些特定的协程工具。不是阻塞,而是挂起或避免冲突的。因此,让我们把这个解决方案放在一边,并探索一些其它的解决方案。
原子
还有另一种 Java 的解决方案可以在一些简单的情况下帮助我们。 Java 有一组原子值,它们的所有操作都是快速的,并且保证是“线程安全的”。它们被称为原子。它们的操作是在没有锁的底层实现的。因此这个解决方案是有效的,并且适合我们,我们可以使用不同的原子值。对我们的例子,我们可以使用 AtomicInteger。
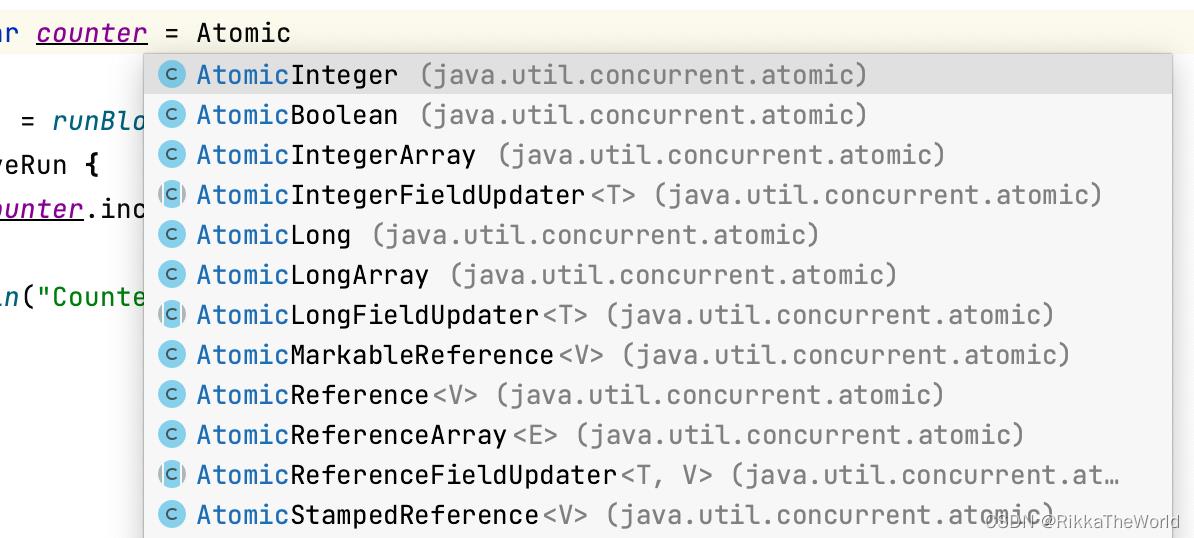
private var counter = AtomicInteger()
fun main() = runBlocking
massiveRun
counter.incrementAndGet()
println(counter.get()) // 1000000
它在这里工作的很完美,但是原子值的效用通常非常有限,因此我们需要小心:当我们有一堆操作时,仅仅一个操作是原子的并不会帮助我们。
private var counter = AtomicInteger()
fun main() = runBlocking
massiveRun
counter.set(counter.get() + 1)
println(counter.get()) // ~430467
为了确保 UserDownloader 的安全,我们可以使用 AtomicReference 包装只读用户列表。我们可以使用 getAndUpdate 原子函数来更新它的值,而不发生冲突。
class UserDownloader(
private val api: NetworkService
)
private val users = AtomicReference(listOf<User>())
fun downloaded(): List<User> = users.get()
suspend fun fetchUser(id: Int)
val newUser = api.fetchUser(id)
users.getAndUpdate it + newUser
我们经常使用原子来保护原语或单个引用,但对于更加复杂的情况,我们仍然需要使用更好的工具。
单个线程的调度器
在Dispatcher协程调度器一章中,我们认识了一个管理单个线程的协程调度器。对于绝大多数共享状态的问题,它是最简单的解决方案。
val dispatcher = Dispatchers.IO
.limitedParallelism(1)
var counter = 0
fun main() = runBlocking
massiveRun
withContext(dispatcher)
counter++
println(counter) // 1000000
在实践中,这种方式有两种用法,第一种方法被称为粗粒度的线程约束。这是一种简单的方法,我们只需要使用 withContext 来包装整个函数,dispatcher 将限制行为运行在单一的线程上。这个解决方案很简单,并且消除了冲突,但问题是我们整个函数失去了多线程功能。让我们看看下面的例子, api.fetchUser(id) 可以在多个线程上并发的启动,但它的主体将运行在一个 dispatcher 上,该 dispatcher 限制只在单个线程上运行。因此,调用阻塞或 CPU 密集型操作时,该函数的执行速度可能会变慢。
class UserDownloader(
private val api: NetworkService
)
private val users = mutableListOf<User>()
private val dispatcher = Dispatchers.IO
.limitedParallelism(1)
suspend fun downloaded(): List<User> =
withContext(dispatcher)
users.toList()
suspend fun fetchUser(id: Int) = withContext(dispatcher)
val newUser = api.fetchUser(id)
users += newUser
第二种方法被称为细粒度线程约束。在这种方法中,我们只包装那些最终修改状态的语句。在我们的示例中,就是所有使用 users 的行。这种写法要求更高,但如果排除了别的(如本例中 fetcheUser)阻塞的或 CPU 密集型的代码,它可以提供更好的性能。如果它们只是普通的挂起函数,那么性能的改善就比较一般。
class UserDownloader(
private val api: NetworkService
)
private val users = mutableListOf<User>()
private val dispatcher = Dispatchers.IO
.limitedParallelism(1)
suspend fun downloaded(): List<User> =
withContext(dispatcher)
users.toList()
suspend fun fetchUser(id: Int)
val newUser = api.fetchUser(id)
withContext(dispatcher)
users += newUser
在大多数情况下,使用带有单个线程的调度器不仅简单,而且高效,这是因为标准调度器们共享相同的线程池。
互斥锁
最后一种流行的方式是使用互斥锁。你可以把共享内容想象成一个只有一把钥匙的房间,它最重要的功能是锁。当第一个协程调用它的时,协程会拿到钥匙,不用挂起就可以通过锁进入共享内容。如果另一个协程调用 lock,它将会被挂起,直到第一个协程调用 unlock,如果另一个协程运行到有锁的地方,它将会被挂起并放入队列中,就在第二个协程之后。当第一个协程运行完并最终调用 unlock 时,它会反还钥匙,接着就是恢复第二个协程(队列中的第一个协程),并最终可以通过使用 lock 来使用共享内容。因此,在 lock 和 unlock 之间只有一个协程。
suspend fun main() = coroutineScope
repeat(5)
launch
delayAndPrint()
val mutex = Mutex()
suspend fun delayAndPrint()
mutex.lock()
delay(1000)
println("Done")
mutex.unlock()
// (1 sec)
// Done
// (1 sec)
// Done
// (1 sec)
// Done
// (1 sec)
// Done
// (1 sec)
// Done
直接使用 lock 和 unlock 是有风险的,因为这两者之间的任何异都会导致钥匙永远不会返还(unlock 永远不会调用),因此就没有其他协程能够通过锁访问共享内容。这是一个严重的问题,它被称为死锁。因此,我们可以使用 withLock 函数,它会从调用 lock 开始,在 finally 块调用 unlock 函数结束,即使块内抛出任何异常都能成功的释放锁。它的使用类似于同步块。
val mutex = Mutex()
var counter = 0
fun main() = runBlocking
massiveRun
mutex.withLock
counter++
println(counter) // 1000000
互斥锁相对与同步块的重要优势是:我们可以挂起一个协程,而非阻塞一个线程。这是一种更安全、更轻便的选择。与使用仅限制于单个线程的调度器相比,互斥锁更加轻量,在某些情况下,它可能会提供更好的性能。另一方面,它也更难被正确使用。它有一个潜在的风险:协程不能两次通过锁。执行下面代码将会导致一个被称为死锁的程序状态 —— 它将永远被阻塞:
suspend fun main()
val mutex = Mutex()
println("Started")
mutex.withLock
mutex.withLock
println("Will never be printed")
// Started
// (runs forever)
互斥锁的第二个问题是:当协程挂起时,互斥锁不能解锁。看看下面的代码, 执行的时间将超过5秒,就是因为互斥锁在 delay 期间仍然处于锁定状态:
class MessagesRepository
private val messages = mutableListOf<String>()
private val mutex = Mutex()
suspend fun add(message: String) = mutex.withLock
delay(1000) // 我们模拟网络操作
messages.add(message)
suspend fun main()
val repo = MessagesRepository()
val timeMillis = measureTimeMillis
coroutineScope
repeat(5)
launch
repo.add("Message$it")
println(timeMillis) // ~5120
当我们使用仅限制于单个线程的调度器时,就不会出现这样的问题,当一个 delay 或一个网络请求挂起一个协程时,该线程可以被其他协程使用。
class MessagesRepository
private val messages = mutableListOf<String>()
private val dispatcher = Dispatchers.IO
.limitedParallelism(1)
suspend fun add(message: String) =
withContext(dispatcher)
delay(1000) // 我们模拟网络请求
messages.add(message)
suspend fun main()
val repo = MessagesRepository()
val timeMillis = measureTimeMillis
coroutineScope
repeat(5)
launch
repo.add("Message$it")
println(timeMillis) // 1058
这就是为什么我们要避免使用互斥锁来包装整个函数(粗粒度的方法),当我们使用它时,我们需要非常小心这样做,避免两次锁住共享内容和调用挂起函数。
class MongoUserRepository(
//...
) : UserRepository
private val mutex = Mutex()
override suspend fun updateUser(
userId: String,
userUpdate: UserUpdate
): Unit = mutex.withLock
// 是的, update 应该发生在 db
// 而不是在这个地方
// 这只是个示例
val currentUser = getUser(userId) // 死锁!
deleteUser(userId) // 死锁!
addUser(currentUser.updated(userUpdate)) // 死锁!
override suspend fun getUser(
userId: String
): User = mutex.withLock
// ...
override suspend fun deleteUser(
userId: String
): Unit = mutex.withLock
// ...
override suspend fun addUser(
user: User
): User = mutex.withLock
// ...
细粒度的线程限制(只包装我们修改共享状态的地方)会有所帮助,但在上面的示例中,我更喜欢使用限制为单个线程的调度器。
总结
在修改共享状态时候,可以通过多种方式编排协程以避免冲突。最实用的解决方案是使用调度器来修改共享状态,该调度器仅限制单个线程。这可以是一个细粒度的线程限制。它只封装需要同步具体位置;或者,它也可以是封装整个函数的粗粒度线程约束。第二种方法比较简单,但可能比较慢。我们也可以使用原子值或互斥锁。
以上是关于深潜Kotlin协程(十四):共享状态的问题的主要内容,如果未能解决你的问题,请参考以下文章