分布式锁原理与实现(数据库rediszookeeper)
Posted 胡玉洋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式锁原理与实现(数据库rediszookeeper)相关的知识,希望对你有一定的参考价值。
分布式锁原理与实现(数据库、redis、zookeeper)
分布式锁
分布式锁可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
分布式锁的实现方式有:
-
数据库实现分布式锁:原理简单,性能较差
-
Redis分布式锁:性能最好
-
Zookeeper分布式锁:可靠性最好
一、数据库实现分布式锁
数据库实现分布式锁的思路,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。具体实现方式有多种:
- 当我们要锁住某个方法或资源的时候,就在该表中增加一条记录;想要释放锁的时候,就删除这条记录。
- 可以基于乐观锁实现。
- 也可以利用数据库自带的排它锁实现。
由于需要连数据库,适用于对性能要求不高的场景如集群环境下的定时任务等。
参考:《基于数据库的分布式锁实现》https://blog.csdn.net/lmb55/article/details/78495629
二、Redis实现分布式锁
Redis实现分布式锁的思路主要是,获取锁的时候在redis中存储一个特定的key-value,释放锁的时候删除这个key-value。具体实现有多种方式。
1、【setnx】命令实现分布式锁(set if not exist)
一般思路是先用setnx命令设置一个指定的key-value来获取锁(同一业务逻辑获取的分布式锁对应的key固定,value随意),释放的时候用del命令删除这个key-value。这样做可能出现一个问题,如果释放锁(del key)之前系统挂了,redis中的这个key-value会一直存在,也就是会造成死锁。
因此可以用expire命令来给这个key-value加一个有效期,过一段时间即使不删除也自动失效。但由于加锁的时候,setnx和expire是分成两步来执行的,并没有原子性,如果执行expire之前系统挂了,也无法释放锁,造成死锁。当然执行expire需要依赖setnx的执行结果,如果setnx执行不成功(没抢到锁),是不应该执行expire的,所以也无法用redis事务的方式来保证这两个命令的原子性(如果用事务,及时setnx执行失败,也会继续执行expire)。
最终方案:可以通过setnx+getset命令来完美实现redis分布式锁,这种方案可以避免死锁,主要思想就是如果持有锁的线程没有及时释放锁,其他线程可以帮它释放锁。具体做法是:
(1)申请锁的时候用setnx设置key-value,key值固定,value=当前时间戳+过期时间,申请成功则获取锁成功
(2)如果申请锁失败(说明setnx执行失败,redis中已经有对应key了),用getset方法获取之前的值,判断锁是否已过期,如果过期了,判断设置的value
如下是用spring-data-redis实现分布式锁的例子:
public boolean lock(String redisKey,long expireMsecs)
try
long currentLockValue = System.currentTimeMillis() + expireMsecs + 1;
boolean lockResult = redisTemplate.opsForValue().setIfAbsent(redisKey, currentLockValue);
//成功获取得锁
if(lockResult)
return true;
//如果redisKey存在,但已达到过期时间,则重新进入争抢
Long lockValue = (Long)this.getRedisTemplate().opsForValue().get(redisKey); //2019年04月08日12:00:10|000
long currentTimeMillis = System.currentTimeMillis(); //2019年04月08日12:00:00|100
if(lockValue != null && lockValue < currentTimeMillis)
Long oldLockValue = (Long)redisTemplate.opsForValue().getAndSet(redisKey, currentLockValue); //2019年04月08日12:00:10|000
//确保set的时候,没有其它线程进行getset操作
if(oldLockValue != null && oldLockValue.equals(lockValue))
return true;
catch (Exception e)
logException(bizAction, "exception", getLockKey(), e);
return false;
public boolean unLock()
redisTemplate.delete(getLockKey());
当锁过期重新进入争抢的时候,比如之前redis中存的时间value是5,现在时间currentLockValue是10,所以现在的锁过期了。这时线程A和线程B同时(在同一毫秒)争抢锁,线程A先执行getset,获取到的oldLockValue=5,同时把当前时间currentLockValue 10放到缓存中,线程2再执行getset时,获取到的oldLockValue=10,这时比较线程A获取到的oldLockValue和之前的lockValue值一样,就表示A获取到了锁。

这种方案还有个小问题就是,需要依赖每个服务器节点的时间,因此需要保证每个服务器的时间一致。
2、用【set key value [EX seconds] [PX milliseconds] [NX|XX]】命令实现分布式锁。
redis2.8之后,扩展了set命令的参数,可以直接执行用一个命令来原子执行set和expire。
3、用lua脚本实现redis分布式锁
4、Redlock算法
三、用Zookeeper实现分布式锁
Zookeeper锁原理:通过Zookeeper上的数据节点来标识一个锁,例如/curator/lock。Zookddper分布式锁与Redis分布式锁相比相比,实现的稳定性更强,这是因为zookeeper的特性所致,在外界看来,zookeeper集群中每一个节点都是一致的。
1、Zookeeper实现分布式锁
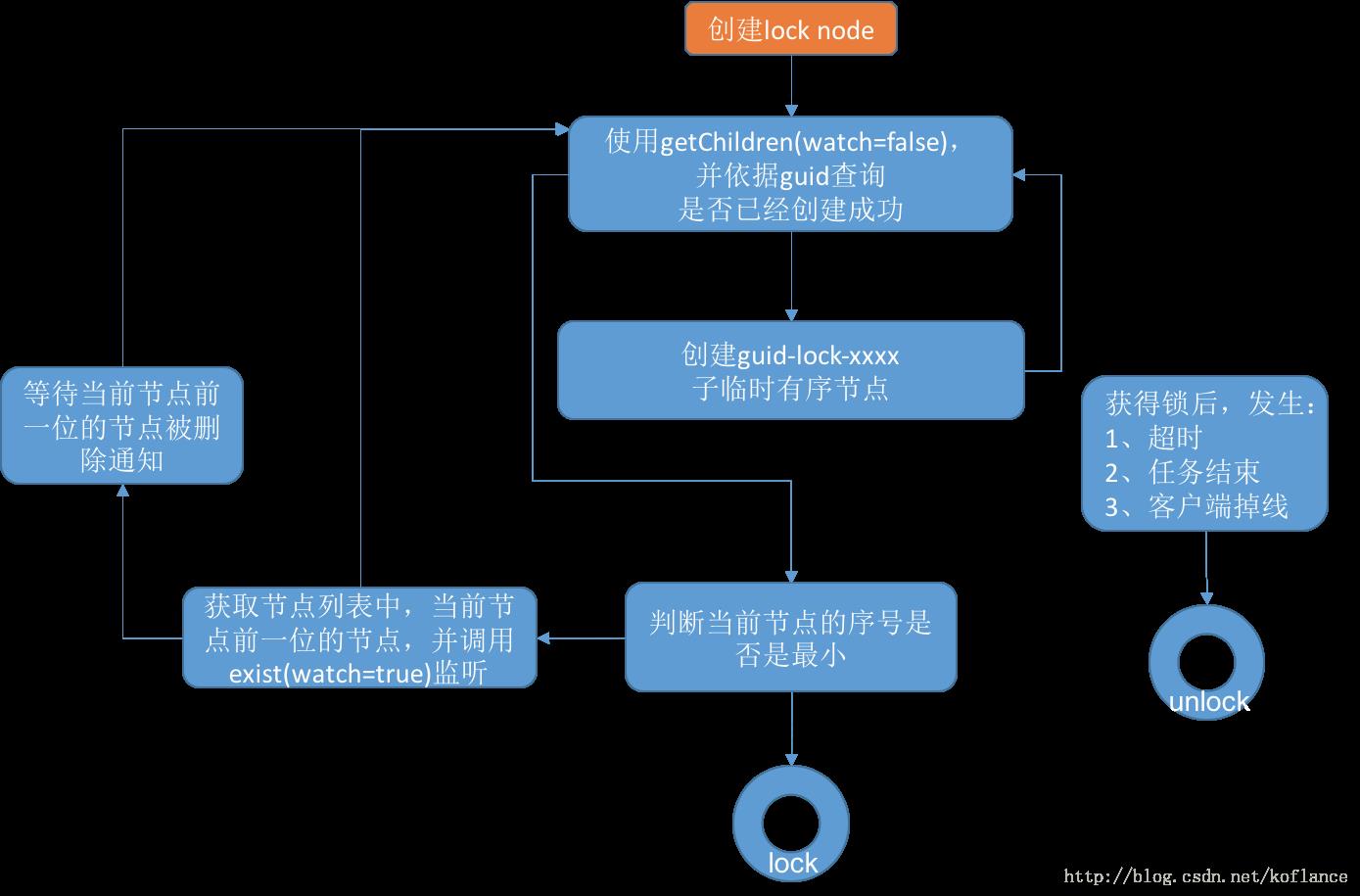
下面描述使用zookeeper实现分布式锁的算法流程,假设锁空间的根节点为/curator/lock:
- 客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/curator/lock/lock-0000000000,第二个为/curator/lock/lock-0000000001,以此类推。
- 客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听/curator/lock的子节点变更消息,获得子节点变更通知后重复此步骤直至获得锁;
- 执行业务代码;
- 完成业务流程后,删除对应的子节点释放锁。
创建的临时节点能够保证在故障的情况下锁也能被释放,考虑这么个场景:假如客户端a当前创建的子节点为序号最小的节点,获得锁之后客户端所在机器宕机了,客户端没有主动删除子节点;如果创建的是永久的节点,那么这个锁永远不会释放,导致死锁;由于创建的是临时节点,客户端宕机后,过了一定时间zookeeper没有收到客户端的心跳包判断会话失效,将临时节点删除从而释放锁。
对于这个算法有个极大的优化点:假如当前有1000个节点在等待锁,如果获得锁的客户端释放锁时,这1000个客户端都会被唤醒,这种情况称为“羊群效应”;在这种羊群效应中,zookeeper需要通知1000个客户端,这会阻塞其他的操作,最好的情况应该只唤醒新的最小节点对应的客户端。应该怎么做呢?在设置事件监听时,每个客户端应该对刚好在它之前的子节点设置事件监听,例如子节点列表为/lock/lock-0000000000、/lock/lock-0000000001、/lock/lock-0000000002,序号为1的客户端监听序号为0的子节点删除消息,序号为2的监听序号为1的子节点删除消息。调整后的分布式锁算法为:
- 客户端连接zookeeper,并在/lock下创建临时的且有序的子节点,第一个客户端对应的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推;
- 客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁;
- 执行业务代码;
- 完成业务流程后,删除对应的子节点释放锁。
如下是用Curator实现分布式锁的例子:
public class ZookeeperDistributeLock
private static String lockPath = "/curator/lock";
private static CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("33.101.98.109:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
public static void main(String[] args) throws Exception
client.start();
final InterProcessMutex lock = new InterProcessMutex(client, lockPath);
final CountDownLatch countDownLatch = new CountDownLatch(1);
final SimpleDateFormat simpleDateFormat = new SimpleDateFormat("HH:mm:ss|SSS");
for (int i = 1; i <= 50; i++)
final int finalI = i;
new Thread(new Runnable()
@Override
public void run()
try
countDownLatch.await();
catch (InterruptedException e)
e.printStackTrace();
try
lock.acquire();
catch (Exception e)
e.printStackTrace();
String orderNo = simpleDateFormat.format(new Date());
try
lock.release();
catch (Exception e)
e.printStackTrace();
System.out.println("生成的第" + (finalI) + "个订单号是:" + orderNo);
).start();
System.out.println("1秒后开始并发生成订单号……");
Thread.sleep(1000);
countDownLatch.countDown();
2、Zookeeper读写锁
也可以通过Zookeeper来获取分布式读写锁,在获取读写锁时,也是通过数据节点来表示一个锁。请求锁时,在锁节点(比如/lock)下创建格式为“/lock/类型-序号”的临时顺序节点,比如“R-0000001”、“W-0000002”、“R-0000003”:
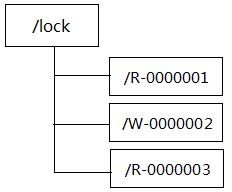
获取读写锁流程分析:
- 在获取读锁时,客户端在/lock节点下创建/R-为前缀的临时顺序节点,比如“R-0000001”、“R-0000003”;在获取写锁时,客户端在/lock节点下创建/W-为前缀的临时顺序节点,比如“W-0000002”。
- 创建节点后,获取/lock下所有子节点,确定当前节点在所有子节点中的位置,并对最近的子节点设置Watcher监听。
- 对于读锁请求,如果没有比自己序号小的节点,或者所有比自己序号小的节点都是读请求,则成功获取到读锁,否则进入等待。
- 对于写请求,如果自己是序号最小的节点,则成功获取到写锁,否则进入等待。
Curator已经为我们实现了多种分布式锁:
InterProcessMutex:分布式可重入排它锁
InterProcessSemaphoreMutex:分布式排它锁
InterProcessReadWriteLock:分布式读写锁
InterProcessMultiLock:将多个锁作为单个实体管理的容器
总结
数据库分布式锁、Redis分布式锁、Zookeeper分布式锁的比较
- 理解的难易程度
数据库>Redis>Zookeeper - 实现的复杂程度
Zookeeper>=Redis>数据库 - 性能高低
Redis>Zookeeper>数据库 - 可靠性
Zookeeper>Redis>数据库
以上是关于分布式锁原理与实现(数据库rediszookeeper)的主要内容,如果未能解决你的问题,请参考以下文章