Hadoop格式化后出现异常
Posted LIUXUN1993728
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop格式化后出现异常相关的知识,希望对你有一定的参考价值。
我在正常安装Hadoop 格式化后正常启动,在安装成功后再次格式化就出现了异常,对文件进行上传和删除时都出现了同样的异常 说是DataNode没有启动,我使用jps查看一下 别的都启动了 只有DataNode没有启动,解决方案从如下论坛中
http://forum.hadoop.tw/viewtopic.php?f=4&t=43找到启发,但是可能是版本不一致,并不像论坛中所说的DataNode和NameNode都有namespaceID
只好从DataNode的Log日志中查询:
找到了如下一段错误信息:
2017-08-16 15:04:46,518 INFO org.apache.hadoop.hdfs.server.common.Storage: Using 1 threads to upgrade data directories (dfs.datanode.parallel.volumes.load.threads.num=1, dataDirs=1)
2017-08-16 15:04:46,525 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /cloud/hadoop-2.7.4/temp/dfs/data/in_use.lock acquired by nodename 29522@hadoop1
2017-08-16 15:04:46,526 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/cloud/hadoop-2.7.4/temp/dfs/data/
java.io.IOException: Incompatible clusterIDs in /cloud/hadoop-2.7.4/temp/dfs/data: namenode clusterID = CID-1faf1f78-2d7a-4a70-8d62-83aa4dfd13c7; datanode clusterID = CID-d520d56a-ca5f-4e18-9cd0-443925773aba
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:777)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:300)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:416)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:573)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1386)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1351)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:313)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:216)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:637)
at java.lang.Thread.run(Thread.java:748)说是NameNode的clusterId 和DataNode的 clusterId不一致:
查看一下 果然不一致:
[root@hadoop1 current]# cat VERSION
#Wed Aug 16 14:25:21 EDT 2017
namespaceID=1793769073
clusterID=CID-1faf1f78-2d7a-4a70-8d62-83aa4dfd13c7 #NameNode上的clusterID
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1093563334-192.168.0.10-1502907921813
layoutVersion=-63
[root@hadoop1 current]# pwd
/cloud/hadoop-2.7.4/temp/dfs/name/current
[root@hadoop1 current]# cat /cloud/hadoop-2.7.4/temp/dfs/data/current/VERSION
#Wed Aug 16 14:18:20 EDT 2017
storageID=DS-713444f8-0e13-4a63-8ac5-21eb435438cd
clusterID=CID-d520d56a-ca5f-4e18-9cd0-443925773aba #DataNode上的clusterID
cTime=0
datanodeUuid=d6813d12-3427-4577-a40b-d504ba5089bf
storageType=DATA_NODE
layoutVersion=-56我将DataNode的clusterID修改成了NameNode版本号中的clusterID
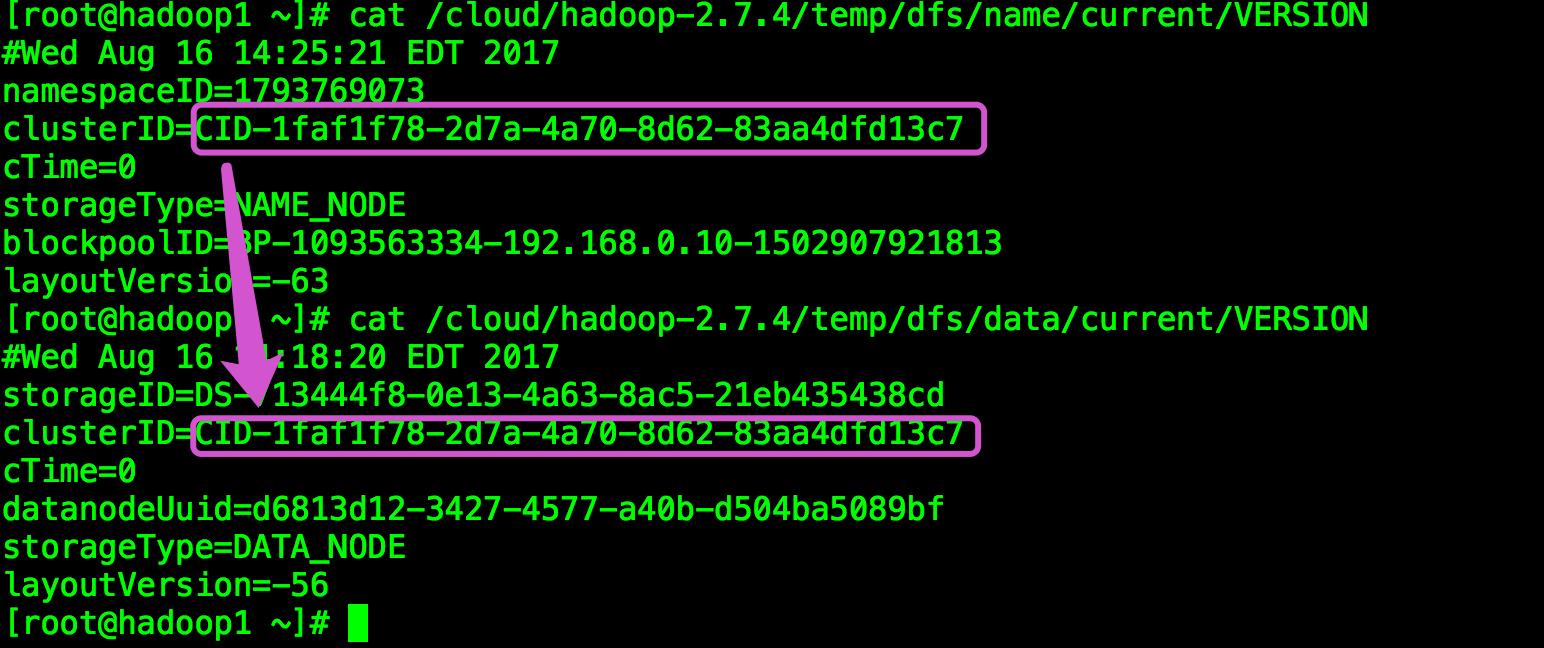
(按照正常逻辑修改任意一方的ClusterID和另一方保持一致即可)
然后重新启动Hadoop
发现启动了DataNode,然后测试上传 发现问题竟然解决了
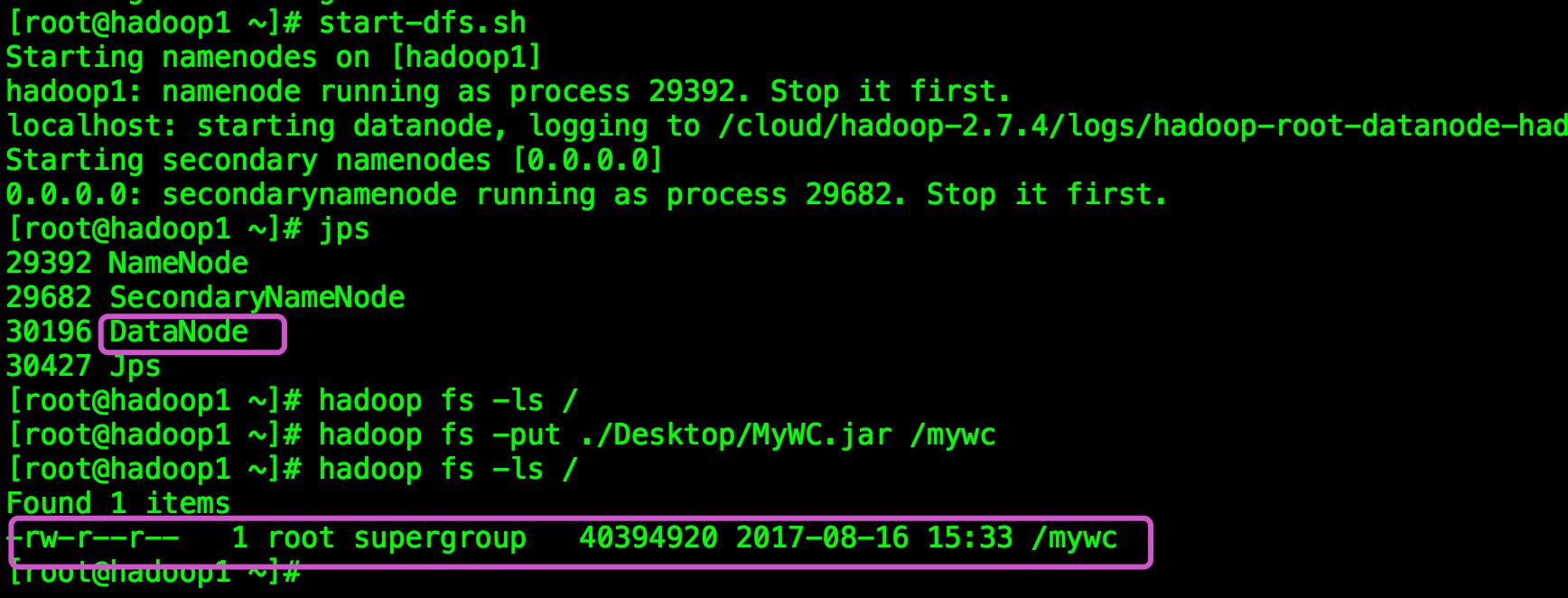
总结:发现以前遇到错误总是什么都不想 先将错误信息去网上查询解决方案并不一定奏效,才发现日志是一个好东西,遇到错误说不定在对应的日志中就能找到解决方案。
以上是关于Hadoop格式化后出现异常的主要内容,如果未能解决你的问题,请参考以下文章