第14课:Spark 分布式模型训练及调优(实战)
Posted wangongxi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第14课:Spark 分布式模型训练及调优(实战)相关的知识,希望对你有一定的参考价值。
上节课已经为大家介绍了 Apache Spark 项目的基本情况,以及分布式深度神经网络的解决方案。这节课我们将给出一个 Deeplearning4j+Spark 的建模实例,包括从配置 Maven 工程开始到本地的原型验证,以及集群上的模型训练。由于 ND4J 的张量运算是通过 JavaCPP 技术,诸如 OpenBLAS 开源库来调用实现的,因此我们也将就内存的调优进行介绍。下面我们首先介绍下配置 Maven 工程的一些细节。本节课的核心内容包括:
- Deeplearning4j-Spark 应用配置 Maven 工程
- Deeplearning4j-Spark 本地 Local 模式进行原型验证
- Deeplearning4j-Spark 集群 Yarn-Cluster 模式进行分布式建模
- 常见问题和调优
14.1 Deeplearning4j-Spark 应用配置 Maven 工程
首先给出我们依赖的开源库的一些版本信息:
- Apache Spark:2.1.x
- Eclipse Deeplearning4j:0.8.0
- Scala:2.11
- Java:1.8
以上这些信息并不是唯一的组合,尤其是 Spark 版本,Deeplearning4j 同样也支持 1.x 的 Spark,因此开发者可以根据自己的实际情况进行搭配。接着我们新建 Maven 工程并添加必要的依赖:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<nd4j.version>0.8.0</nd4j.version>
<dl4j.version>0.8.0</dl4j.version>
<datavec.version>0.8.0</datavec.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2</spark.version>
</properties>
<!--省略部分内容-->
<!--ND4J 依赖-->
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native</artifactId>
<version>$nd4j.version</version>
</dependency>
<!--Deeplearning4j 核心依赖-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>$dl4j.version</version>
</dependency>
<!--Deeplearning4j-Spark 依赖-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>dl4j-spark_$scala.binary.version</artifactId>
<version>$dl4j.version_spark_$spark.version</version>
</dependency>
<!--DataVec-Spark 依赖-->
<dependency>
<groupId>org.datavec</groupId>
<artifactId>datavec-spark_$scala.binary.version</artifactId>
<version>$datavec.version_spark_$spark.version</version>
</dependency>
<!--ND4J-Kryo 序列化依赖-->
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-kryo_$scala.binary.version</artifactId>
<version>$dl4j.version</version>
</dependency>
我们首先声明了一些版本号信息,包括之前提到的 Spark 和 Deeplearning4j 的版本。在具体的 Dependency 中,dl4j-spark 的依赖比较灵活,Spark 1.x/2.x 都可以和不同的 Scala 还有 Deeplearning4j 版本进行组合。更多内容可以查询 Maven 中心仓库。需要注意的是,我们不需要添加 Spark 的依赖,因此 dl4j-spark 会间接依赖到 Spark 的相关 JAR 包。下面是部分候选版本的截图:
14.2 Deeplearning4j-Spark 本地 Local 模式进行原型验证
在 3.1 中我们介绍了构建 Deeplearning4j-Spark 项目所需要的 Maven 依赖以及相关的注意事项。这个部分我们将在此基础上先以本地 Local 模式进行逻辑的编写和原型的验证。我们将之前课程中介绍过的 Fashion-MNIST 数据集的分类问题用到本次的课程中,如果对这个案例有不明确的同学,可以参见之前我们在介绍卷积神经网络时候的相关内容。
Spark 本地 Local 模式是以多线程来模拟集群的一种运行模式,不需要额外部署多机集群,因此方便了开发人员编写算法逻辑和调试。在上面的 WordCount 的例子中,我们给出了示例,这里我们用 Spark 的 Java 接口来编写整个逻辑,请大家注意和 Scala 用法的差异。
SparkSession sparksession = SparkSession.builder()
.appName("Fashion Mnist CNN Spark")
.master("local[*]")
.config("spark.kryo.registrator", "org.nd4j.Nd4jRegistrator") // 为 ND4J 注册 Kryo
.getOrCreate();
SparkContext sparkContext = sparksession.sparkContext();
JavaSparkContext sc = JavaSparkContext.fromSparkContext(sparkContext);
我们声明了 Spark 上下文的实例并配置 Job 名称、本地运行模式、ND4J 对象的 Kryo 序列化形式注册。为了方便基于 Java 接口开发 Spark 应用,我们声明了 JavaSparkContext 对象。需要强调的是,Kryo 序列化相比于 Java 默认的序列化算法要高效很多。而在进行分布式建模的时候,参数/梯度向量通过网络传输是非常耗时的,尤其对于拥有几十甚至几百兆字节参数的神经网络来说更是这样。因此为了减少网络 I/O 的开销,官方指定使用 Kryo 序列化算法,并且是强制的,否则会报错。下面我们说明下如何从 HDFS 上读取训练的图片。
图片是小文件,单张图片一般也就几十 KB 或者几个 MB。因此直接存储在 HDFS 上并不合适(一般为了吞吐量的考虑,HDFS 的 block size 会设置得比较大)。当然对于这种小文件的存储有一些解决方案,比如阿里的 TFS 文件系统,这里不多展开介绍。我们在这里将训练和验证图片集打包成 ZIP 文件上传到 HDFS,并且在训练前从 HDFS 读取这些文件来达到读取图片集的目的。当然,在本地验证的时候我们可以有多种方式读取本地磁盘上的图片文件,但为了兼容集群上的建模程序,我们在本地也同样采用读取 ZIP 文件的方式,这样在集群上跑的程序几乎不需要再做改动。这是部分图片的截图:
每张图片的命名中包含了该张图片的标注信息。比如,9_9993.jpg 中下划线前的那个数字 9 就是这张图片的标注。至于标注和类别名称的映射关系可以自己指定。
我们来看下读取 ZIP 文件中图片的逻辑:
//入参解析
final String imageFilePath = args[0];
final int numEpochs = Integer.parseInt(args[1]);
final String modelPath = args[2];
final int numBatch = Integer.parseInt(args[3]);
final String testimageFilePath = args[4];
//读取 ZIP 中的 Fashion-MNIST 图片集
JavaPairRDD<String,PortableDataStream> dataAndPortableRDD = jsc.binaryFiles(imageFilePath);
JavaPairRDD<String,PortableDataStream> testdataAndPortableRDD = jsc.binaryFiles(testimageFilePath);
JavaRDD<DataSet> javaRDDImageTrain = dataAndPortableRDD.flatMap(new FlatMapFunction<Tuple2<String,PortableDataStream>, DataSet>()
@Override
public Iterator<DataSet> call(Tuple2<String, PortableDataStream> t)
throws Exception
ZipInputStream zipIn = new ZipInputStream(t._2.open());
List<DataSet> data = getData(zipIn,numBatch);
Collections.shuffle(data);
return data.iterator();
).persist(StorageLevel.MEMORY_ONLY_SER());
//
JavaRDD<DataSet> javaRDDTestImageTrain = testdataAndPortableRDD.flatMap(new FlatMapFunction<Tuple2<String,PortableDataStream>, DataSet>()
@Override
public Iterator<DataSet> call(Tuple2<String, PortableDataStream> t)
throws Exception
ZipInputStream zipIn = new ZipInputStream(t._2.open());
List<DataSet> data = getData(zipIn,numBatch);
return data.iterator();
).persist(StorageLevel.MEMORY_ONLY_SER());
imageFilePath 传入的是本地磁盘上训练数据集/压缩包的路径。我们可以用二进制数据集的读取方式来加载这些压缩文件。读取后的 dataAndPortableRDD 和 testdataAndPortableRDD 这两个 RDD 实例封装了 ZIP 文件的路径和 ZIP 文件可读取的二进制字节流。我们用 ZipInputStream 来读取 ZIP 文件中的每个文件,并按照设定的 batchSize 封装在一个 DataSet 对象中,最后我们得到的就是 RDD 形式的 DataSet。getData 方法的实现我们放在最后说明,下面我们来看下参数服务器的声明:
ParameterAveragingTrainingMaster trainMaster = new ParameterAveragingTrainingMaster.Builder(numBatch)
.workerPrefetchNumBatches(0)
.saveUpdater(true)
.averagingFrequency(5)
.batchSizePerWorker(numBatch)
.build();
参数服务器是 Deeplearning4j 分布式建模的其中一种解决方案,在上文中我们已经介绍了其理论。这里我们给出参数服务器实例的声明和参数设置。需要说明的是,averagingFrequency 的设置对于整体模型的收敛速度和训练速度都有着比较直接的影响。结合参数服务器的理论可知,如果参数平均的频率过低,那么网络 I/O 会非常频繁,训练的速度会被拖慢。但是如果设置得很高,那么网络的准确性将收到影响。因此需要分析并做出一些权衡。如果需要采用去中心化的梯度共享的策略,相关的逻辑可以参考下面:
VoidConfiguration voidConfiguration = VoidConfiguration.builder()
//.meshBuildMode(MeshBuildMode.PLAIN) 该设置从 1.0.0-beta3 开始生效
.unicastPort(12345)
.networkMask("10.27.0.0/16")//Spark 集群机器子网掩码
.controllerAddress(null)//master 节点设置,如果为 null 则默认为 Spark Job 的 driver 节点
.build();
TrainingMaster tm = new SharedTrainingMaster.Builder(voidConfiguration, numBatch)
.collectTrainingStats(false)
.updatesThreshold(1e-3)
.rddTrainingApproach(RDDTrainingApproach.Direct)//Direct 表示直接从 RDD 中读取数据训练,另一种 Export 方式会将训练数据先写到 HDFS 的临时目录下
.batchSizePerWorker(numBatch)
//.thresholdAlgorithm(new AdaptiveThresholdAlgorithm(1e-3)) 该设置从 1.0.0-beta3 开始生效
.build();
这里解释下上面的相关配置。VoidConfiguration 的实例对象定义了在梯度共享策略下的网络配置,具体依赖的是 UDP 通信协议(可支持 UDP 单播/多播/广播三种模式),因此需要我们定义下通信端口(如果不定义则采用默认端口号)。另外,对于涉及的计算节点需要统一设置子网掩码,主节点的 IP 可以采用默认或指定 IP,在上面的配置逻辑里我采用的是主节点默认的方式。
对于 SharedTrainingMaster 实例来讲,相对比较重要的配置项是 updatesThreshold。这里我设置的值是 0.01,其实也是默认的阈值。当阈值设置较大时,网路 IO 会减少,整体训练的速度会提升但对模型的准确性影响较大。反之模型参数的更新会频繁,也就是意味着网络 IO 会频繁。因此阈值的设置一般从较小的值开始尝试,毕竟模型的准确性更为重要。其他的一些设置我在注释里有一些说明,大家可以结合自身的实际情况进行设置。
最后 .meshBuildMode 和 .thresholdAlgorithm 是在 1.0.0-beta3 才刚被实现,主要是用于指定集群的模式和阈值更新的自动机制,属于进一步的优化项,大家在使用时注意版本和 Maven 依赖的更新。
下面是分布式训练的相关逻辑:
MultiLayerConfiguration netconf = builder.build();
MultiLayerNetwork net = new MultiLayerNetwork(netconf);
net.setListeners(new ScoreIterationListener(1));
net.init();
SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(jsc, net, trainMaster);
// 训练 Spark 网络
for (int i = 0; i < numEpochs; ++i)
sparkNetwork.fit(javaRDDImageTrain);
System.out.println("----- Epoch " + i + " complete -----");
卷积神经网络的配置我们在这里不做详细介绍了,具体实例可以参考前面介绍 Fashion-MNIST 问题时用到的网络配置。我们需要使用 SparkDl4jMultiLayer 来封装本地的神经网络对象,这样每个 Spark 集群节点上会有一个该网络的实例。多轮训练和单机的编码没有什么差别,每一轮开始后 fit 训练数据集 RDD 即可。在训练完之后,我们在验证数据集上评估下分类准确率:
// evaluate model
Evaluation evalActual = sparkNetwork.evaluate(javaRDDTestImageTrain);
System.out.println(evalActual.stats());
SparkDl4jMultiLayer 提供了直接验证 RDD 数据准确率的接口,我们直接调用下就行。正常情况下,我们可以得到类似下面的评估结果:
Examples labeled as 8 classified by model as 2: 31 times
Examples labeled as 8 classified by model as 3: 5 times
Examples labeled as 8 classified by model as 4: 7 times
Examples labeled as 8 classified by model as 5: 24 times
Examples labeled as 8 classified by model as 6: 13 times
Examples labeled as 8 classified by model as 7: 2 times
Examples labeled as 8 classified by model as 8: 904 times
Examples labeled as 8 classified by model as 9: 2 times
Examples labeled as 9 classified by model as 1: 1 times
Examples labeled as 9 classified by model as 3: 1 times
Examples labeled as 9 classified by model as 4: 1 times
Examples labeled as 9 classified by model as 5: 25 times
Examples labeled as 9 classified by model as 7: 39 times
Examples labeled as 9 classified by model as 8: 1 times
Examples labeled as 9 classified by model as 9: 920 times
==========================Scores========================================
Accuracy: 0.7562
Precision: 0.7482
Recall: 0.7562
F1 Score: 0.7522
========================================================================
最后,如果我们希望将训练好的模型保存在 HDFS 上也非常方便,ModelSerializer 这个内置工具类已经提供了将模型序列化并通过流写入存储介质的方法,我们提供如下操作供大家参考:
// save model
FileSystem hdfs = FileSystem.get(jsc.hadoopConfiguration());
Path hdfsPath = new Path(modelPath);
FSDataOutputStream outputStream = hdfs.create(hdfsPath);
MultiLayerNetwork trainedNet = sparkNetwork.getNetwork();
ModelSerializer.writeModel(trainedNet, outputStream, true);
由于是在本地 Local 模式下进行原型验证,因此在执行应用的时候和启动普通 Java 应用没有太大的区别。需要注意的是,Local 模式下用的是本地文件系统,相关路径需要和 HDFS 路径加以区分,但是代码逻辑上完全兼容。下面我们介绍在 Spark 集群上进行分布式建模的相关步骤。
14.3 Deeplearning4j-Spark 集群 Yarn-Cluster 模式进行分布式建模
首先需要说明的是,本地模式和集群模式下主体建模的逻辑几乎不要做什么修改。唯一需要变动的是,声明 SparkSession 对象实例时,.master("local[*]") 需要进行修改或者直接删除是在 spark-submit 命令行中进行指定。这里我们直接进行注释了。
其次,由于考虑到 Spark 集群并没有部署 Deepleargning4j 的 JAR 包(实际用户是可以自己情况部署 Deeplearning4j 的 JAR 到集群,但考虑到版本升级后需要重新部署等重复性工作,因此可以考虑不直接部署 JAR 在集群),因此向集群提交任务的时候,我们需要将 Deeplearning4j 相关的依赖打成一个 fat-jar,包括 ND4J 的相关依赖和自己的业务建模逻辑都构建成一个 fat-jar。这个我们可以通过 maven-shade-plugin 或者 maven-assembly-plugin 这些 Maven 插件来构建。
<build>
<plugins>
<!-- Configure maven shade to produce an uber-jar when running "mvn package" -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>$maven-shade-plugin.version</version>
<configuration>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>bin</shadedClassifierName>
<createDependencyReducedPom>true</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>org/datanucleus/**</exclude>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
在 pom.xml 中添加完插件后,我们置信 mvn package -DskipTests 命令来构建包含所有依赖的 fat-jar。根据作者的经验,构建完的 JAR 包 > 150M。
在构建完 fat-jar 之后,我们通过命令行将图片训练和验证数据集的压缩文件直接传到 HDFS 上。那么到此,所有的准备工作就基本都完成了。我们执行下列提交命令来向集群提交任务:
spark-submit --class cv.SparkMnist \\
--master yarn-cluster \\
--executor-memory 1g \\
--num-executors 4 \\
--driver-memory 1g \\
DeepLearning-1.0-bin.jar /user/sousuo/sescs/trainData.zip 10 /user/sousuo/sescs/model.bin 100 /user/sousuo/sescs/testData.zip
我们申请了 4 个 executor 并且每个执行器分配了 1G 的 on-heap memory。另外 driver 节点也分配了 1G 的内存。DeepLearning-1.0-bin.jar 是我们之前构建好的 fat-jar,紧跟在后面用空格间隔的是入参组用于指定文件路径和部分建模用的超参数。正常情况下,我们可以通过 UI 来观察任务的运行进度,这里提供一个作者自己的截图:
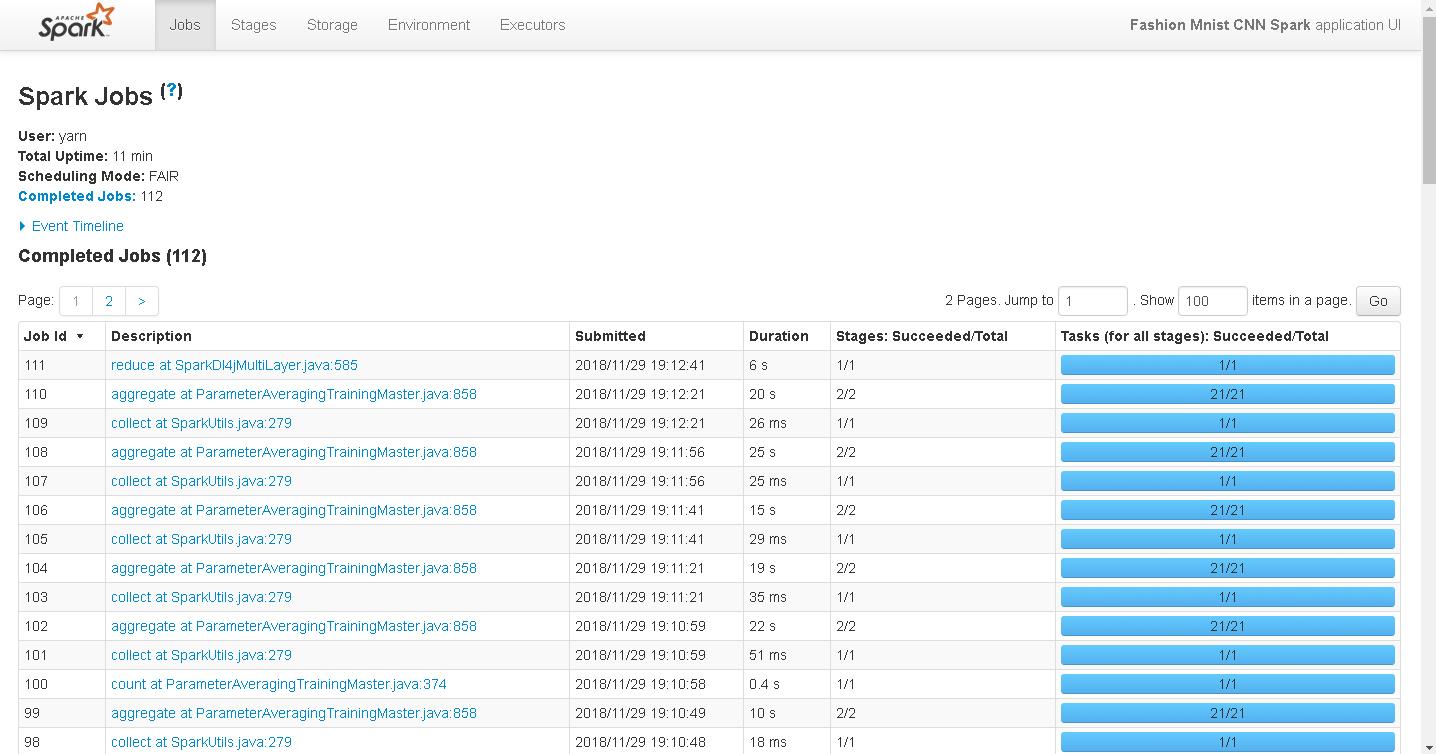
最后一步的 reduce action 是对验证数据集进行准确率评估,其余的 aggregate–collect 操作则是在进行模型的迭代/参数的更新。待所有的 stage 结束之后,我们就完成了一个基于 Spark 的分布式深度学习模型的一栈式开发建模。
最后我们对该部分做下小结和分析。我们在 3.2 课的基础上,将建模过程移植到 Spark 集群上进行。包括训练数据集和验证数据集的存储也从本地磁盘迁移到了 HDFS 上面,最后模型的保存也会直接写 HDFS。尽管如此,我们的程序保持了高度的兼容性和可移植性。几乎不用做特别的修改就可以在 Spark 上运行起来,这得益于 Deeplearning4j 对 Spark 分布式建模的原生支持及高度封装的上层 API,使得底层的操作细节对用户透明。采用 Deeplearning4j+Apache Spark 的解决方案,和执行一般的 Spark 任务没有太大的差别,甚至 Spark 集群不需要部署 Deeplearning4j 的相关 JAR 包,只要客户端构建一个 fat-jar 就可以打包所有的依赖,这使得 Spark 集群运维和 Spark 应用开发这两项工作得到了真正的解耦,做到了“热插拔”的状态。
由于这里我们举例的 Fashion-MNIST 分类问题是一个类似 Mnist 的入门级神经网络建模的案例,有很多调优问题并没有被暴露出来,那么在下面的章节里,我们将介绍在 Spark 集群上分布式建模可能面临的一些问题和解决方案。
14.4 常见问题和调优
1. Off-Heap Memory OOM
我们先来看一张截图:

这张图是我在修改 3.3 中 Spark 提交命令中将 executor-memory 设置成 512M 后出现的情况。从异常信息上我们已经可以清楚地看到 OOM 的异常,根本原因是 cannot allocate FloatPointer 等日志所反馈出来的信息,直接原因是我们将 executor-memory 减小了一半。我们在源码中定位 FloatPointer 这个类的信息,并找到异常堆栈来源如下:
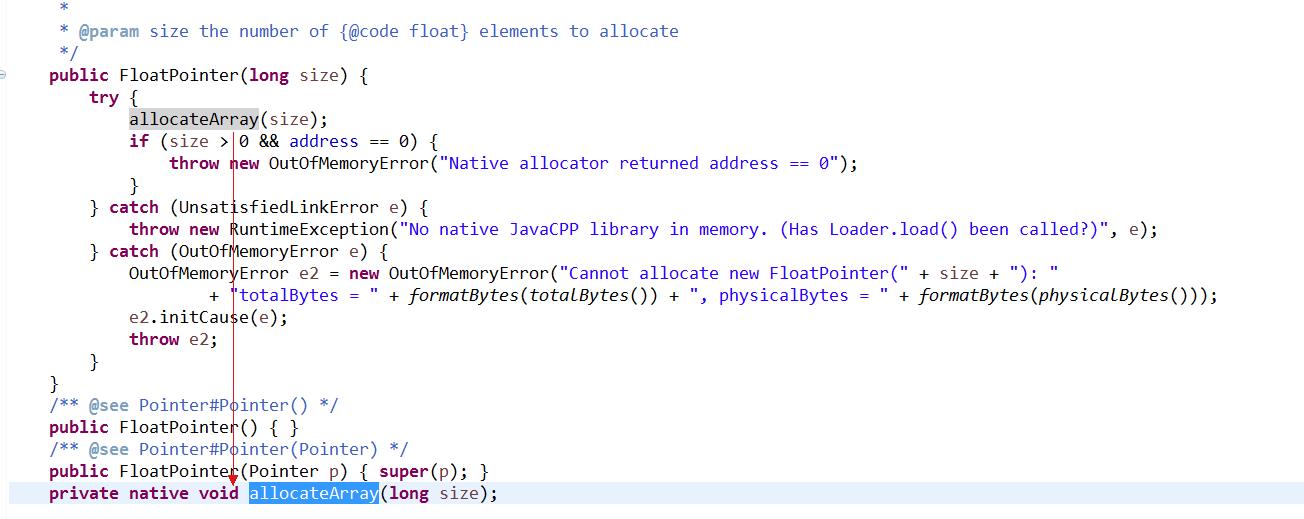
从源码中我们可以很清楚地看到 OOM 的原因是在 allocateArray 方法执行的时候产生的,而 allocateArray 方法的是个 Java 本地方法,申请分配的实际是堆外内存,就是所谓的 Off-Heap Memory。在之前的课程中我们介绍过,Deeplearning4j 的张量运算实际是通过 JavaCPP 调用 OpenBLAS/MKL 来实现的,换句话说并非是在堆上内存(On-Heap Memory)中直接进行操作的,这样的好处是可以通过 JNI 的技术调用一些成熟的且经过优化的开源矩阵运算库,加速 Deeplearning4j 中的张量运算。而对于在 Spark 中设置 executor-memory 或者 driver-memory 都是 On-Heap Memory,虽然会以一定的比例(一般是 10%)用作于堆外内存,但这个比例对于需要大量矩阵计算的深度学习训练来说一般都是不够的。我们看下 Spark 官网的相关介绍:
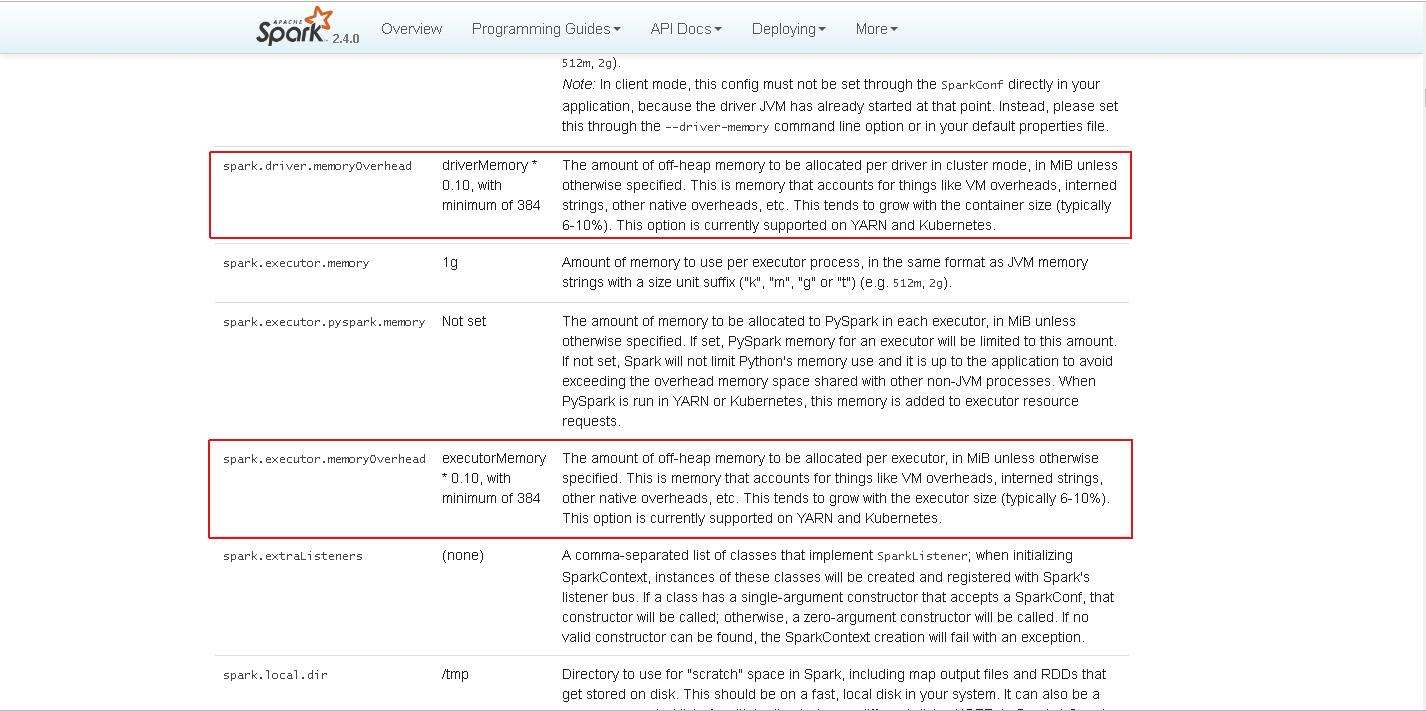
从官网的介绍中我们可以看到,spark.driver.memoryOverhead 和 spark.executor.memoryOverhead 是用于设置对外内存的配置项,它们的功能在截图中都有详细描述我们就不在这里解释了。下面我就给出一个带有 Off-Heap Memory 设置的 Spark 提交命令:
spark-submit --class cv.SparkMnist \\
--master yarn-cluster \\
--executor-memory 512m \\
--num-executors 4 \\
--driver-memory 1g \\
--conf spark.yarn.driver.memoryOverhead=2048 \\
--conf "spark.driver.extraJavaOptions=-Dorg.bytedeco.javacpp.maxbytes=2147483648" \\
--conf spark.yarn.executor.memoryOverhead=512 \\
--conf "spark.executor.extraJavaOptions=-Dorg.bytedeco.javacpp.maxbytes=536870912" \\
DeepLearning-1.0-bin.jar /user/sousuo/sescs/trainData.zip 10 /user/sousuo/sescs/model.bin 100 /user/sousuo/sescs/testData.zip
我们在提交任务的命令行里添加了关于 Off-Heap Memory 的设置。其中 memoryOverhead 就是上面已经分析过的配置,除此之外我们还额外为本地 JVM 设置了 JavaCPP 的最大内存字节数。注意,这个最大内存字节数不得超过 memoryOverhead 的配置。那么这样的设置就可以保证堆外内存足够建模使用,而不再出现内存不够的异常了。
2. RDD 的 Cache 策略
我们先引用上面部分的源码:
JavaRDD<DataSet> javaRDDImageTrain = dataAndPortableRDD.flatMap(new FlatMapFunction<Tuple2<String,PortableDataStream>, DataSet>()
@Override
public Iterator<DataSet> call(Tuple2<String, PortableDataStream> t)
throws Exception
ZipInputStream zipIn = new ZipInputStream(t._2.open());
List<DataSet> data = getData(zipIn,numBatch);
Collections.shuffle(data);
return data.iterator();
).persist(StorageLevel.MEMORY_ONLY_SER());
这部分是从存储介质上读取图片数据并缓存 RDD 的的一段逻辑。需要注意的是,.persist(StorageLevel.MEMORY_ONLY_SER()) 这样的操作。对于比较熟悉 Spark 开发的研发人员,一般直接调用 Cache 接口来达到缓存 RDD 的目的。但是这里我们并没有这样操作,或者更加准确地说,我们并不是直接缓存原数据而是以序列化的形式进行缓存。
效率问题固然是一方面,但更加重要的是,如果直接缓存原数据,那么容器估计的缓存容量只包含 On-Heap Memory,而忽略了 Off-Heap Memory。对于 Deeplearning4j 在 Spark 建模,RDD 中存储的 DataSet 其实大部分都是在 Off-Heap Memory 的张量数据,而只有很小的比例(主要是 Pointer 的实例对象)存储在 On-Heap Memory,那么使用直接 Cache 的策略就不合适了。而序列化后的对象都存储在堆上,这样容器是可以准确计算需要用于存储的内存容量。
3. ERROR NTPTimeSource: Error querying NTP server
这个异常其实并不能算是一个逻辑问题,因为一般来讲这个错误不是开发人员可以人为设置的。出现这个异常的原因主要是 Spark 集群中的机器无法联网获取 NTP 服务器的时间信息(一般非常多的出现在公司内网中,即公司内网存在网络隔离)并且参数服务器被设置成需要获取各个服务器的计算性能的时候,这个错误就会出现,并且导致任务失败。一般来讲,计算节点之间时钟并不需要在训练期间反复同步,因此我们可以通过做如下的一些设置来解决这个问题。
Step1:
TrainingMaster tm = new SharedTrainingMaster.Builder(voidConfiguration, numBatch)
.collectTrainingStats(false)
Step2:
--conf spark.driver.extraJavaOptions=-Dorg.deeplearning4j.spark.time.TimeSource=org.deeplearning4j.spark.time.SystemClockTimeSource
--conf spark.executor.extraJavaOptions=-Dorg.deeplearning4j.spark.time.TimeSource=org.deeplearning4j.spark.time.SystemClockTimeSource
第一步的设置是避免在执行训练任务的时候收集计算节点的状态,那么节点的时钟信息也不会被收集了。第二步则是对于 driver 和 executor 节点上的时钟设置成该节点本地的时钟,而不需要联网去获取 NTP 服务器的时钟信息。当然如果集群的机器可以联网,则不会出现上述问题。
14.5 小结
本次上下两部分的课程我们介绍了在 Apache Spark 上基于 Deeplearning4j 构建分布式神经网络模型的整个流程,以及一些常见问题和优化方案。我们首先以一个简单的 wordcount 的例子引入对 Spark 使用的介绍,随后我们介绍了 Deeplearning4j 提供的分布式建模方案及其原理。从第三部分开始,我们以 Fashion-MNIST 为案例,介绍了如何在本地 Local 和集群上以 Yarn-Cluster 的模式建立卷积分类网络。最后,我们着重解释了堆外内存的使用和优化方案。
Deeplearning4j 并不是唯一原生支持在 Spark 集群上进行分布式神经网络建模的框架,但其方便的网络搭建流程及简洁的参数服务器声明步骤使其成为在 Spark 上深度学习建模的一种良好的解决方案。用户不仅可以完成基于 Spark 的离线模型训练和评估,同样可以基于如 Spark Streaming 完成模型的准实时线上预测,甚至为了保证更高的实时性,用户可以将 Spark 上训练好的模型(包含模型和参数的序列化文件)通过 HDFS 等存储介质做“中转”,在推送到 Java Web 的应用服务器上后和普通数据文件一样通过反序列化后,从磁盘加载到内存完成深度学习应用的在线部署。由于这一部分我会在第 17 课中详细讲述 Deeplearning4j+Tomcat+JSP 的在线部署过程,因此在这里就不再赘述了。
最后需要强调的是,Deeplearning4j 在 Spark 上的建模并不需要在集群上部署相应的 JAR 包及动态链接库文件(当然部署也是可以的,另外 Deeplearning4j 的动态链接库已经打包在 JAR 文件中)。这样即插即用的好处在于,Spark 集群的管理人员不需要担心引入许多第三方依赖而导致诸如 JAR 包冲突等实际问题,同时也不必担心新版本发布出来后需要升级依赖。所有的工作都在应用开发人员这边完成,开发人员在完成业务逻辑的开发后,将所有依赖打包成的 fat-jar 向集群提交就可以了,双方的耦合度可以降到最低。
答疑与交流
为了让订阅课程的读者更快更好地掌握课程的重要知识点,我们为每个课程配备了课程学习答疑群服务,邀请作者定期答疑,尽可能保障大家学习效果。同时帮助大家克服学习拖延问题!
购买课程后,一定要添加小助手伽利略微信 GitChatty6,并将支付截图发给她,小助手会拉你进课程学习群。
以上是关于第14课:Spark 分布式模型训练及调优(实战)的主要内容,如果未能解决你的问题,请参考以下文章