DeepLearning-BasedIntelligentDefectDetectionofCutting WheelswithIndustrialImagesInManufacturing-阅读笔记
Posted Dream_WLB
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DeepLearning-BasedIntelligentDefectDetectionofCutting WheelswithIndustrialImagesInManufacturing-阅读笔记相关的知识,希望对你有一定的参考价值。
Deep Learning-Based Intelligent Defect Detection of Cutting Wheels with Industrial Images in Manufacturing
基于深度学习的工业图像切割砂轮智能缺陷检测
//2022.7.20上午8:46开始阅读笔记
论文速览
本文提出了一种CNN结构对于工业环境中LCD面板进行切割的切割齿轮表面缺陷进行了检测,其中将图像中的RoI区域作为CNN的输入加快了CNN的训练过程。此外,作者还探究了文中提出来的CNN架构中不同CONV层的数量对模型性能的影响,且还将提出来的CNN架构与传统的SVM、ANN等方法进行对比,最后,得到了文中提出的方法具有较高性能的结果。
同时,作者还研究了增加对输入图像的感受野大小(即增加CNN中的卷积核大小对模型的精度也有一定程度的提高)。
论文地址
论文贡献
本文提出了一个CNN网络架构用于检测工业环境中切割轮图像表面的缺陷,建立起来一个工业环境中切割图像表面的缺陷检测系统。
论文内容
1.介绍
图1所示为LCD面板生产线制造工艺流程。

作者重点介绍了现有的检测机器表面缺陷的方法不能用于检测切割轮表面缺陷检测的原因:
-
用于检测其他机器的方法对切割轮这种较小尺寸的缺陷检测对象的振动变化不是很敏感(而零部件的振动变化是工业中进行缺陷检测的重要参考指标);
-
此外,由于切割轮本身过小,无法收集足够的数据量;
图2展示了LCD面板表面缺陷。

2.所提出的方法
2.1 深度卷积神经网络(略)
2.2 提出的网络架构
图3展示了提出的网络架构。

分类交叉熵函数作为损失函数用于模型的训练,其定义为:
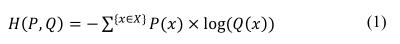
其中H(P,Q)是对于每个类别x属于X的在模型Q和数据集P之间的交叉熵损失函数。
交叉熵由每个数据集的类标签的预期概率乘以模型𝑄预测概率的对数的负和计算得出。
3.实验探究
3.1切割轮数据集描述
数据集来源:
本文使用实际的切割轮退化图像数据集进行验证,该数据集来自真实的工业制造过程。该数据集是辛辛那提大学智能维护系统(IMS)实验室和富士康技术集团的共同努力。
图4显示了切割轮切割LCD面板过程中拍摄的过程。

文中作者提取了RoI区域进行了训练,从而加快了训练过程。
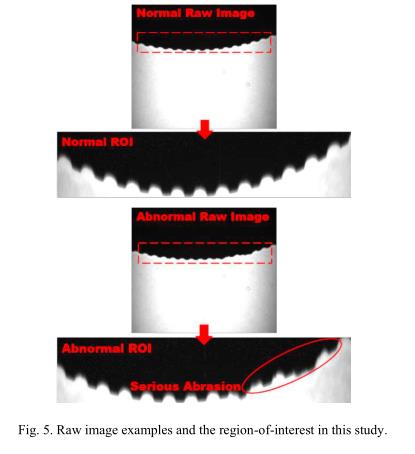
图5显示了正常车轮和降级车轮的图像示例。在ROI图像中可以明显地显示退化,这表明ROI图像可以用于缺陷检测问题。切割轮的尺寸和材料见表1。
切割轮的规格信息如表1所示。

3.2 数据增强
在本研究中,由于难以在真实工厂中捕获图像,因此收集了93幅原始图像。因此,数据扩充被用于扩大数据集的大小。基于收集的93幅图像,已生成407幅图像。对于每个新生成的图像,数据增强方法随机选择一个或两个变换,从93个切割轮原始图像的随机图像中添加高斯噪声、应用水平翻转,或同时添加高斯噪声和应用水平翻转。

新形成的数据集被分解为训练和测试数据。缺陷检测任务的详细信息如表2所示。关于所提出的方法,本研究中使用的参数列于表3中。


3.3 方法对比
作者为了对比评估提出方法的性能,和其他的方法进行了对比。
SVM:本研究采用图像的常规特征,包括车轮拟合曲线、峰高、峰间距等统计信息。图7简要说明了传统功能。

ANN:ANN模型的输入变量与我们在CNN模型上使用的ROI图像训练和测试数据集相同。
x-cov CNN:文中作者还研究了CONV层的数量对模型性能的影响。
3.4 结果和讨论
对每种方法进行了10次评估,然后取10次评估的平均值。
值得注意的是,较小的奇数大小的内核过滤器比较大的内核过滤器更受欢迎。但当本研究中采用3×30的滤波器尺寸时,模型性能良好。这是因为较大的滤波器尺寸能够捕捉2050年200像素的大接收场。当使用较大的滤波器尺寸时,基本上可以实现较高的精度。这表明,较大的内核大小也具有从原始数据中学习底层知识的强大能力。
图8展示了6种模型的acc。
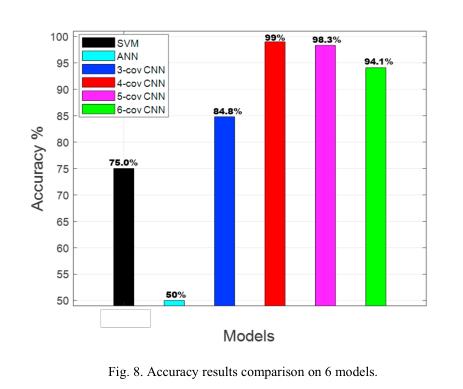
图9显示了模型训练过程中的测试精度和损失函数值。给出了所有10次实验的结果。可以观察到,经过25个阶段后,可以获得接近100%的测试精度,损失函数值也降至零左右。在训练的最后阶段,模型性能通常会收敛,并且模型在不同的运行中是稳定的。因此,验证了该方法的有效性和稳定性。

4.结论
文章最后,作者说明了下一步的研究方向:进一步研究减少人工标记数据之后进行模型训练的任务。
//本文仅作为日后复习之用,并无他用。
以上是关于DeepLearning-BasedIntelligentDefectDetectionofCutting WheelswithIndustrialImagesInManufacturing-阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章