Spark中文手册3:Spark之基本概念
Posted wanmeilingdu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark中文手册3:Spark之基本概念相关的知识,希望对你有一定的参考价值。
|
转自:http://www.aboutyun.com/thread-11502-1-1.html
1、什么是Spark Streaming? 2、如何创建StreamingContext对象? 3、什么是高级源?  关联 与Spark类似,Spark Streaming也可以利用maven仓库。编写你自己的Spark Streaming程序,你需要引入下面的依赖到你的SBT或者Maven项目中
为了从Kafka, Flume和Kinesis这些不在Spark核心API中提供的源获取数据,我们需要添加相关的模块spark-streaming-xyz_2.10到依赖中。例如,一些通用的组件如下表所示: 为了获取最新的列表,请访问Apache repository 初始化StreamingContext 为了初始化Spark Streaming程序,一个StreamingContext对象必需被创建,它是Spark Streaming所有流操作的主要入口。一个StreamingContext 对象可以用SparkConf对象创建。
appName表示你的应用程序显示在集群UI上的名字,master是一个Spark、Mesos、YARN集群URL 或者一个特殊字符串“local”,它表示程序用本地模式运行。当程序运行在集群中时,你并不希望在程序中硬编码master,而是希望用spark-submit启动应用程序,并从spark-submit中得到 master的值。对于本地测试或者单元测试,你可以传递“local”字符串在同一个进程内运行Spark Streaming。需要注意的是,它在内部创建了一个SparkContext对象,你可以通过ssc.sparkContext 访问这个SparkContext对象。 批时间片需要根据你的程序的潜在需求以及集群的可用资源来设定,你可以在性能调优那一节获取详细的信息。 可以利用已经存在的SparkContext对象创建StreamingContext对象。
当一个上下文(context)定义之后,你必须按照以下几步进行操作
几点需要注意的地方:
离散流(DStreams) 离散流或者DStreams是Spark Streaming提供的基本的抽象,它代表一个连续的数据流。它要么是从源中获取的输入流,要么是输入流通过转换算子生成的处理后的数据流。在内部,DStreams由一系列连续的 RDD组成。DStreams中的每个RDD都包含确定时间间隔内的数据,如下图所示:  任何对DStreams的操作都转换成了对DStreams隐含的RDD的操作。在前面的例子中,flatMap操作应用于lines这个DStreams的每个RDD,生成words这个DStreams的 RDD。过程如下图所示: 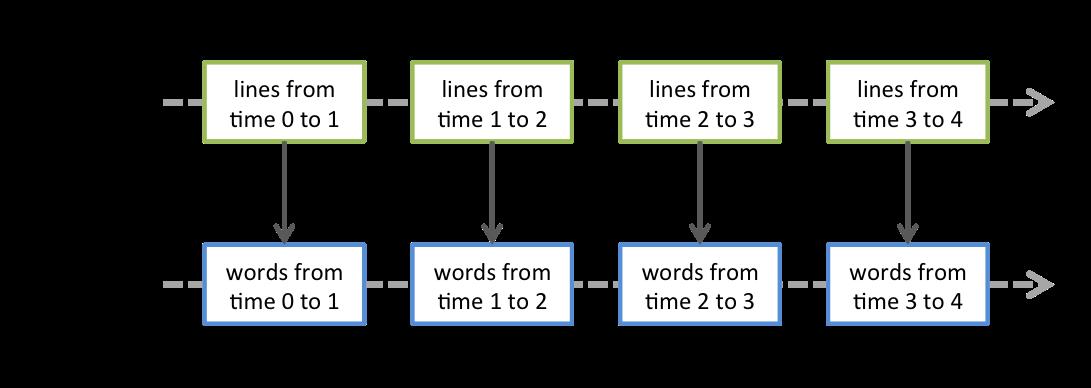 通过Spark引擎计算这些隐含RDD的转换算子。DStreams操作隐藏了大部分的细节,并且为了更便捷,为开发者提供了更高层的API。下面几节将具体讨论这些操作的细节。 输入DStreams和receivers 输入DStreams表示从数据源获取输入数据流的DStreams。在快速例子中,lines表示输入DStream,它代表从netcat服务器获取的数据流。每一个输入流DStream 和一个Receiver对象相关联,这个Receiver从源中获取数据,并将数据存入内存中用于处理。 输入DStreams表示从数据源获取的原始数据流。Spark Streaming拥有两类数据源
需要注意的是,如果你想在一个流应用中并行地创建多个输入DStream来接收多个数据流,你能够创建多个输入流(这将在性能调优那一节介绍) 。它将创建多个Receiver同时接收多个数据流。但是,receiver作为一个长期运行的任务运行在Spark worker或executor中。因此,它占有一个核,这个核是分配给Spark Streaming应用程序的所有 核中的一个(it occupies one of the cores allocated to the Spark Streaming application)。所以,为Spark Streaming应用程序分配足够的核(如果是本地运行,那么是线程) 用以处理接收的数据并且运行receiver是非常重要的。 几点需要注意的地方:
基本源 我们已经在快速例子中看到,ssc.socketTextStream(...)方法用来把从TCP套接字获取的文本数据创建成DStream。除了套接字,StreamingContext API也支持把文件 以及Akka actors作为输入源创建DStream。
Spark Streaming将会监控dataDirectory目录,并且处理目录下生成的任何文件(嵌套目录不被支持)。需要注意一下三点: 1 所有文件必须具有相同的数据格式 2 所有文件必须在`dataDirectory`目录下创建,文件是自动的移动和重命名到数据目录下 3 一旦移动,文件必须被修改。所以如果文件被持续的附加数据,新的数据不会被读取。 对于简单的文本文件,有一个更简单的方法streamingContext.textFileStream(dataDirectory)可以被调用。文件流不需要运行一个receiver,所以不需要分配核。 在Spark1.2中,fileStream在Python API中不可用,只有textFileStream可用。
关于从套接字、文件和actor中获取流的更多细节,请看StreamingContext和JavaStreamingContext 高级源 这类源需要非Spark库接口,并且它们中的部分还需要复杂的依赖(例如kafka和flume)。为了减少依赖的版本冲突问题,从这些源创建DStream的功能已经被移到了独立的库中,你能在关联查看 细节。例如,如果你想用来自推特的流数据创建DStream,你需要按照如下步骤操作:
需要注意的是,这些高级的源在spark-shell中不能被使用,因此基于这些源的应用程序无法在shell中测试。 下面将介绍部分的高级源:
自定义源 在Spark 1.2中,这些源不被Python API支持。 输入DStream也可以通过自定义源创建,你需要做的是实现用户自定义的receiver,这个receiver可以从自定义源接收数据以及将数据推到Spark中。通过自定义receiver指南了解详细信息 Receiver可靠性 基于可靠性有两类数据源。源(如kafka、flume)允许。如果从这些可靠的源获取数据的系统能够正确的应答所接收的数据,它就能够确保在任何情况下不丢失数据。这样,就有两种类型的receiver:
怎样编写可靠的Receiver的细节在自定义receiver中有详细介绍。 |
以上是关于Spark中文手册3:Spark之基本概念的主要内容,如果未能解决你的问题,请参考以下文章