Storm Trident API总结-2
Posted 真诚的程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Storm Trident API总结-2相关的知识,希望对你有一定的参考价值。
Trident State的概念
我们之前在《Storm的事务总结》中已经说了,为了保证事务性,Storm需要根据事务号txid来判断当前是否需要更新数据库中的状态。Trident作为Storm事务性的一种框架实现,那么它是如何存储txid以及应用的状态的呢?这就是State的作用。我们可以简单的将State理解为DAO。
Trdient的三种State
Trident支持三种State,分别为:Non-Transactional state,Repeated Tranasactional state, Opaque State,这个我们也在《Storm的事务总结》中介绍过了。我们这里再回顾一下:
- 要求为每个Batch分配一个txid,且要求事务更新的强顺序性
- Non-Transactional State只保证状态的持久化
- Repeated Transactional State内部存储事务号txid,以及此事务对应的状态,如果当前的事务号等于存储的事务号,则不会把当前的状态持久化
- Opaque state内部存储事务号txid,以及前一次事务的状态prestate,当前事务对应的状态state;如果当前事务号不等于存储的事务号,则不会更新存储的状态;而当前事务号等于存储的事务号,那么需要使用前一次事务的状态prestate来更新当前事务状态。
Trident的三种Spout
我们在应用中选择使用何种state,依赖于你使用何种Spout。Spout和State对应,也有三种:分别为:Non-Transactional Spout, Transactional Spout, Opaque Transactional Spout。我们需要取得exact once processing,必须使用互相匹配的Spout和State,它们的关系如下表:
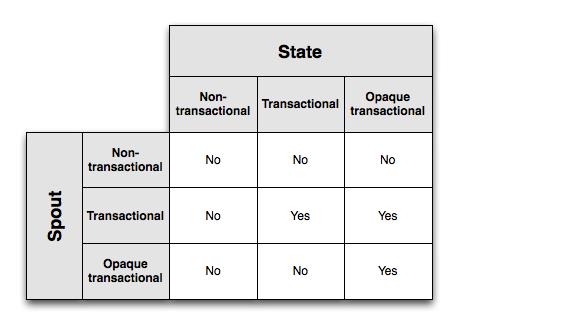
我们可以看到,如果你的源(Spout)保证性强一点(Transactional特性),那么State的选择就宽泛一点(既可以支持Transactional,也可以支持Opaque Transactional);想法,如果你选择的源是Opaque Transactional,你的State也只能选择Opaque Transactional。
Trident的简单API介绍
我们先理清一下各个API直接的关系,从最上层的调用接口入手:
TridentTopology topology = new TridentTopology();
TridentState locations =
topology.newStream("locations", locationsSpout)
.partitionPersist(new LocationDBFactory(), new Fields("userid", "location"), new LocationUpdater())
TridentTopology topology = new TridentTopology();
TridentState locations = topology.newStaticState(new LocationDBFactory());
topology.newStream("myspout", spout)
.stateQuery(locations, new Fields("userid"), new QueryLocation(), new Fields("location"))
第一段代码调用的partitionPersist,相当于数据库写操作:
TridentState partitionPersist(StateFactory stateFactory, Fields inputFields, StateUpdater updater)
关键的参数是第一个和第三个,以及返回值,第一个是一个用来生成State的工厂类StateFactory,而第三个参数是一个StateUpdater,它利用State提供的接口来实现操作数据库的更新操作。返回值是一个TridentState,我们可以当作修改后的结果集,在查询时要使用到。
第二段代码调用的是stateQuery操作,相当于数据库读操作:
Stream stateQuery(TridentState state, Fields inputFields, QueryFunction function, Fields functionFields)
关键的参数是第一个和第三个,第一个参数是第一段代码的返回值TridentState,第三个参数是一个查询函数类,实现具体的查询操作。
我们这里的关键是定义State,StateUpdater,QueryFunction。
自定义的State类,为了提高性能,必须提供对数据库的批查询和批修改功能。
自定义的StateUpdater,QueryFunction,它们的实现是通过调用State的批查询、批修改功能,传入具体的实参,来完成实际的状态修改和查询操作。
Trident复杂API介绍
Trident中为了实现事务性,还提供了MapState和SnapShottable两个接口:MapState是针对GroupedStream的,如果你需要使用groupBy操作,就需要实现MapState接口,如果不需要,就只需要实现SnapShottable接口,一般来说,两个接口都要实现。
Trident已经提供了一些具有fault-tolerance功能的MapState实现类:NonTransactionalMap,TransactionalMap,OpaqueMap,这三个类分别封装了Non-Transactional,Transactional,Opauqe Transactional三种fault-tolerance级别,主要是之前我们在事务那里总结的逻辑,例如针对Transactional,当前txid和数据库里面存放的是否相同,相同就不更新,不同就更新。而具体更新、查询操作,则需要程序员来定义:实现IBackingMap接口。IBackingMap接口的实现类作为NonTransactionalMap,TransactionalMap,OpaqueMap类的build方法的参数,来提供实际存储的支撑。
总结一下:和简单API类似,你还是要实现StateFactory来提供生成State,但是你提供的State是NonTransactionalMap,TransactionalMap,OpaqueMap这三个类的实例(这三个类Trident已经为你提供了),调用这三个类的build方法,传入IBackingMap类的实现类实例。所以,归根到底,你就是要实现IbackingMap接口就可以了。
可以参考Nathanmarz提供的MemcachedStatep的实现代码
以上是关于Storm Trident API总结-2的主要内容,如果未能解决你的问题,请参考以下文章