rasa 介绍文档
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rasa 介绍文档相关的知识,希望对你有一定的参考价值。
1. Rasa介绍
1.1 架构
- Rasa Open Source: NLU (理解语义) + Core (决定对话中每一步执行的actions)
- Rasa SDK: Action Server (调用自定义的 actions)
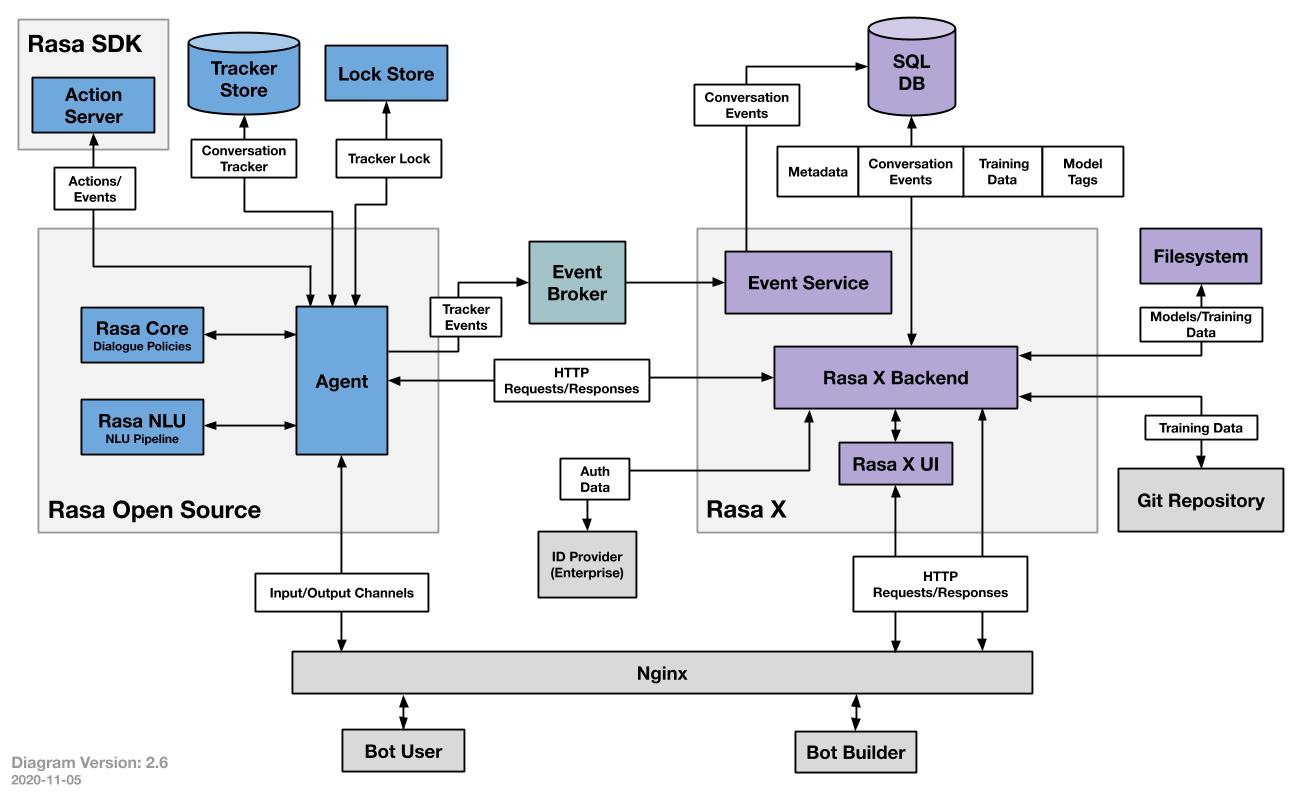
- Rasa NLU
理解用户的对话,提取出感兴趣的信息 (如意图分类、实体提取等),以pipeline的方式处理用户对话,在config.yml中配置。 - Rasa Core
根据NLU输出的信息、以及Tracker记录的历史信息,得到上下文的语境:预测用户当前最可能表达的意图;决定对话中每一步执行哪一个action - Agent
从user来看,它是整个系统的代理,接收用户输入信息,返回系统的回答。在系统内,它是一个总控单元,引导系统启动,连接NLU和DM,得到并调用actions,保存对话数据到存储中 - Action Server
提供了Action和Policy解耦的一种方式。用户可以自定义任何一种action连接到action server上,通过训练学习,rasa可以将policy路由到这个action上。 - Tracker Srore
对话的存储单元,将用户和机器人的对话保存在Tracker Store 中。Rasa提供了针对不同存储类型的开箱即用的实现,包括Redis、MongoDB等。 - Lock Store
是一个ID产生器,使用ticket lock机制来确保全局唯一的conversation ID,并在消息处于活动状态时锁定对话,保证消息的顺序处理。使得多个Rasa服务器可以并行运行,当客户端为给定的conversation ID发送消息时,不需要寻址到相同的节点 - Event Broker
事件代理,bot通过event broker连接到其他服务,可以发布一个消息给其他服务来处理这些消息,也可以转发rasa server的消息到其他服务。目前支持的有SQL、RabbitMQ、Kafka - File System
提供无差别的文件存储服务,比如训练好的模型可以存储在不同位置。支持磁盘加载、服务器加载、云存储加载。
1.2 配置文件
📂 /path/to/project
┣━━ 📂 actions
┃ ┣━━ 🐍 init.py
┃ ┗━━ 🐍 actions.py
┣━━ 📂 data
┃ ┣━━ 📄 nlu.yml
┃ ┣━━ 📄 rules.yml
┃ ┗━━ 📄 stories.yml
┣━━ 📂 models
┣━━ 📂 tests
┃ ┗━━ 📄 test_stories.yml
┣━━ 📄 config.yml
┣━━ 📄 credentials.yml
┣━━ 📄 domain.yml
┗━━ 📄 endpoints.yml
- nlu.yml
本模块会具体针对意图识别,实体提取等任务,配置意图以及触发该意图的文本,提供用户在各种意图下的文本作为examples:询问Query:用户对聊天机器人发出的询问。行动Action: 聊天机器人根据用户询问做出的回应。意图Intent:用户输入蕴含的目的或意图,eg. 用户:你好;intent:打招呼。实体Entity:从用户输入中提取的有用信息
- responses.yml
提供bot在各种类型下的响应,预设定好的内容,不需要执行代码或返回事件。和actions中的response对应,定义格式为utter_intent
responses:
utter_greet:
- text: "今天天气怎么样" #添加文字
image: "https://i.imgur.com/nGF1K8f.jpg" #添加图像
我们在激活form之后,会循环请求slot值,为了让用户知道机器人正在请求哪一个slot值,我们会在responses里添加utter_ask_<slot_name>,使得机器需要填这个槽时,会对用户发出询问。下面是机器需要填name_spelled_correctly这个slot的回复实例:
responses:
utter_ask_name_spelled_correctly:
- buttons:
- payload: /affirm
title: Yes
- payload: /deny
title: No
text: Is first_name spelled correctly?
- stories.yml
提供用户和bot的对话信息作为examples,用来训练bot的 Core (DM) 模型,能推广到看不见的对话路径。
stories:
- story: happy path
steps:
- intent: greet
- action: utter_greet
- intent: mood_great
- action: utter_happy
-
forms.yml
定义表单信息,分别需要哪些slots,以及如何填充slots -
rules.yml
对特定的意图,执行特定的action,始终遵循相同的路径,可用于训练RulePolicy的小部分对话 -
config.yml
定义了 NLU pipeline和Dialogue Policies分别使用了哪些组件 -
domain.yml
列举了bot中包含的所有信息,指定了意图、实体、槽位slot、响应、表格、动作以及对话配置 -
slot
slots是助手机器人的记忆,它可以帮助我们的机器人记住之前实体提取到的信息,从而在后续操作中可以针对用户信息做出应答。
1.3 常用命令
rasa init # 使用自带的样例数据生成一个新的 project
rasa train # 训练模型
rasa test # 测试训练好的 rasa 模型 (默认使用最新的)
rasa interactive # 和 bot 进行交互,创建新的训练数据
rasa shell # 加载模型 (默认使用最新的),在命令行和 bot 对话
rasa run # 使用训练好的模型,启动 server,包括 NLU 和 DM
rasa run actions # 使用 rasa SDK,启动 action server
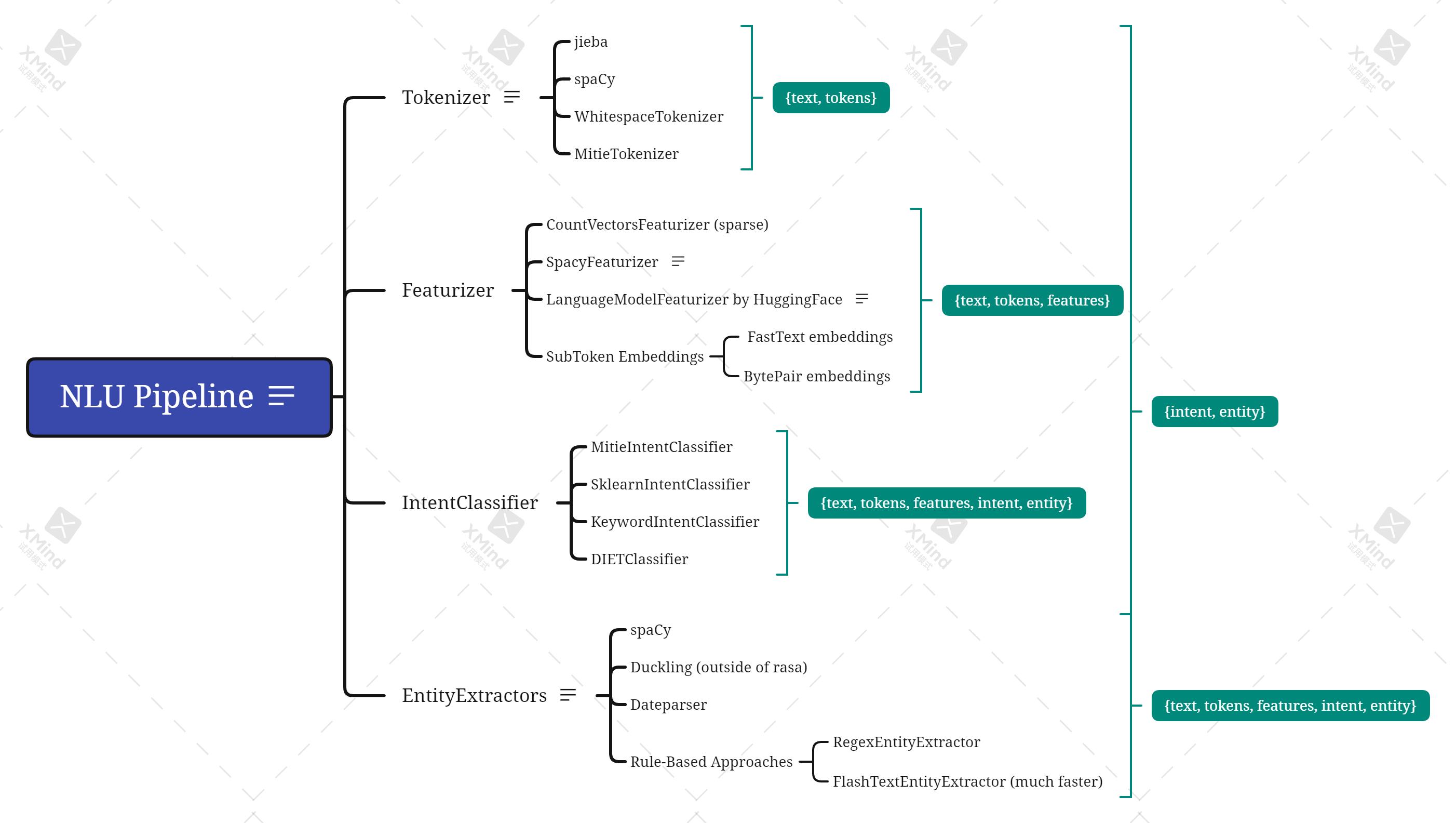
2. NLU
-
Tokenizer
将文本分割成token,便于导入featurizer进行特征化处理 -
Featurizer
从token中提取特征,特征种类包括稀疏sparse特征和稠密dense特征。所有Featurizer都可以返回两种不同的特征:序列特征和句子特征。序列特征是(number-of-tokens x feature-dimension)维度的矩阵,矩阵包含了句子中每个Token的特征向量,我们用这个特征去训练序列模型,如实体识别。句子特征由(1 x feature-dimension)大小矩阵表示,它包含完整对话的特征向量,可以用于意图分类等。 -
意图识别
配置方法:在example下加入符合此意图的文本。识别意图,rasa NLU提供了两种方法:1. Pretrained Embeddings:使用spaCy等加载预训练模型,赋予每个单词word embedding。Rasa NLU会将一条信息中的所有embedding取平均值,然后通过gridsearch搜索支持向量分类器的最优参数 2. Supervised Embeddings:从开始训练word embedding。得到embedding之后通过分类模型得到intent -
实体提取
实体提取有三种方法:
- 使用预训练模型:Duckling e.g. 提取数字,日期,url,邮箱地址等。SpaCy e.g. 提取名字,商品名称,地点等
- 使用正则 Regex (eg. RegexEntityExtractor):适用于满足特定规则的实体。RegexEntityExtractor 不需要训练示例来学习提取实体,但至少需要提供两个带注释的实体examples,以便 NLU 模型可以在训练时将其标记为实体。
nlu:
- regex: car_type
examples: |
- ^[a-zA-Z][0-9]$
- 使用机器学习的方法。nlu.yml 配置训练数据:实体识别的训练数据需要将文本里的实体内容用[]括起,后面接其所属的实体名字(entity_name)
- intent: 手机产品介绍
examples: |
- 这款手机[续航](property)怎么样呀?
输出结果:包括实体的取值"value",类别"entity",置信水平"confidence"和抽取器"extractor"等的json格式:
"entities": [
"value": "续航",
"start": 20,
"end": 33,
"confidence": 0.812631,
"entity": "property",
"extractor": "DIETClassifier"
]
实体角色:如果你觉得两个实体属于同一种类但是他们在文本中扮演的角色不一样,那么你可以通过定义entity roles来区分他们。
nlu:
- intent: 手机产品介绍
examples: |
- 我想要对比一下[Mi11]“entity”: “type”, “role”: “xiaomi”和[iPhone11]“entity”: “type”, “role”: “apple”
实体group:如果你不想具体定义相同的实体的角色名称,只是想给他们分成不同的group,可以使用这个方法:
nlu:
- intent: 手机产品介绍
examples: |
- 我想要对比一下[Mi10]“entity”: “type”, “group”: “1”,
[Mi11]“entity”: “type”, “group”: “1”
和[iPhone11]“entity”: “type”, “group”: “2”
- 同义词映射:映射抽取出来的实体value为一个标准value,需要添加EntitySynonymMapper实现:
nlu:
- intent: 手机产品介绍
examples: |
- 我想看看[Mi11](type)
- synonym: P7
examples: |
- 小米11
- xiaomi11
2.1 组件
config.yml文件中定义nlu pipeline部分示意:
language: en
pipeline:
- name: WhitespaceTokenizer
- name: RegexFeaturizer
- name: LexicalSyntacticFeaturizer
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: char_wb
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 100
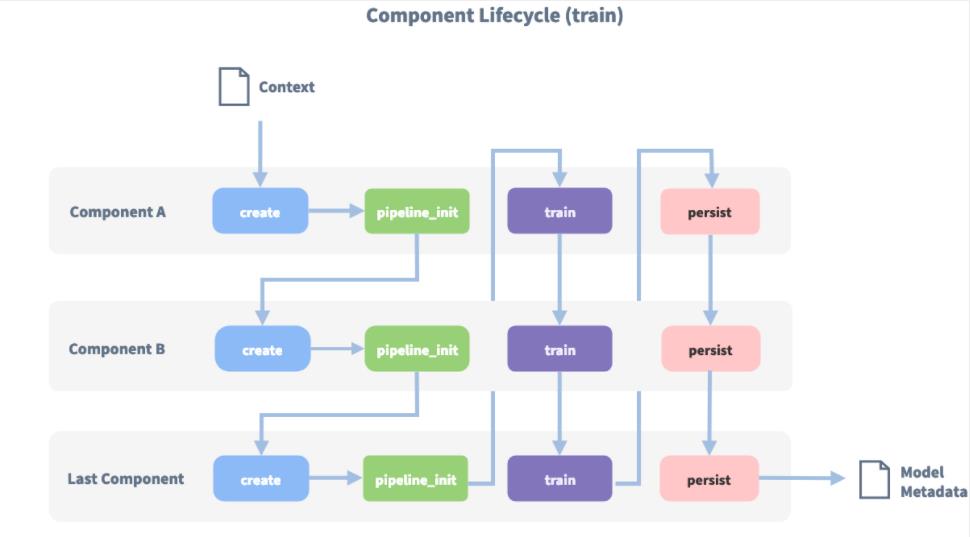
每个组件接受其他组件的输入数据并输出数据,一个组件的输出可以被pipeline中的任何排在他后面的组件使用。某些组件仅生成pipeline中其他组件使用的信息,而一些组件可以流程完成后返回的输出属性。
- Tokenizer
BertTokenizer:中文版Bert tokenize中文的时候会将文本按字分割.rasa_chinese帮助我们将其作为tokenizer组件。rasa_chinese是rasa人员针对中文开发的包,安装如下:
pip install rasa_chinese
pip install rasa_chinese_service
其中包括基于 HuggingFace’s transformers 的分词组件,在config.yml修改此组件如下:
- name: "rasa_chinese.nlu.tokenizers.lm_tokenizer.LanguageModelTokenizer"
tokenizer_url: "http://127.0.0.1:8000/"
需要使用 rasa_chinese_service 作为服务器
JiebaTokenizer:
“我想要了解小鹏汽车” —> [‘我’, ‘想要’, ‘了解’, ‘小鹏’, ‘汽车’]
WhitespaceTokenizer:
“I would like to know about Xiaopeng car.” —> [‘I’, ‘would’, ‘like’, ‘to’, ‘know’, ‘about’, ‘Xiaopeng’, ‘car’]
- Featurizer
Sparse featurizer(CountVectorizer):按照token是否在语料corpus里出现的情况编码文本,编码结果是稀疏矩阵,以节省空间的格式存储。
Dense featurizer(FastTextFeaturizer、SpacyTokenizer、RegexFeaturizer)还有LanguageModelFeaturizer:使用预训练的语言模型eg. Bert, GPT2等,生成稠密的特征向量,config.yml如下:
- name: LanguageModelFeaturizer
model_name: bert
model_weights: /path/to/offline_model
-
Intent Classifiers
从domain.yml文件中定义的所有意图intent中选择一个意图。有MitieIntentClassifier、SklearnIntentClassifier、KeywordIntentClassifier。还有DIETClassifier,可以参阅文章:【RASA】DIET:Dual Intent and Entity Transformer -
Entity Extractors(MitieEntityExtractor 、SpacyEntityExtractor、CRFEntityExtractor、DucklingEntityExtractor)
如果使用两个或多个Extractors,例如 MitieEntityExtractor、DIETClassifier 或 CRFEntityExtractor,则所有Extractors都会找到并提取训练数据中的实体类型。如果您使用实体类型填充的slot是text类型,则pipeline中的最后一个Extractor会填充这个slot。如果slot是list类型,则所有结果都将添加到列表中,包括重复项。 -
EntitySynonymMapper:如果要使用同义映射功能,请添加该组件
-
自定义组件:
如果你想自定义你的组件,你需要在rasa/nlu文件夹(其他路径也可)下新建py文件components.py,在其中定义了一个新的MyComponent类,并在pipeline中添加如下:
pipeline:
- name: "rasa.nlu.components.MyComponent"
rasa/nlu/components.py文件模板:
import typing
from typing import Any, Optional, Text, Dict, List, Type
from rasa.nlu.components import Component
from rasa.nlu.config import RasaNLUModelConfig
from rasa.shared.nlu.training_data.training_data import TrainingData
from rasa.shared.nlu.training_data.message import Message
if typing.TYPE_CHECKING:
from rasa.nlu.model import Metadata
class MyComponent(Component):
"""A new component"""
# Which components are required by this component.
# Listed components should appear before the component itself in the pipeline.
@classmethod
def required_components(cls) -> List[Type[Component]]:
"""Specify which components need to be present in the pipeline."""
return []
# Defines the default configuration parameters of a component
# these values can be overwritten in the pipeline configuration
# of the model. The component should choose sensible defaults
# and should be able to create reasonable results with the defaults.
defaults =
# Defines what language(s) this component can handle.
# This attribute is designed for instance method: `can_handle_language`.
# Default value is None which means it can handle all languages.
# This is an important feature for backwards compatibility of components.
supported_language_list = None
# Defines what language(s) this component can NOT handle.
# This attribute is designed for instance method: `can_handle_language`.
# Default value is None which means it can handle all languages.
# This is an important feature for backwards compatibility of components.
not_supported_language_list = None
def __init__(self, component_config: Optional[Dict[Text, Any]] = None) -> None:
super().__init__(component_config)
def train(
self,
training_data: TrainingData,
config: Optional[RasaNLUModelConfig] = None,
**kwargs: Any,
) -> None:
"""Train this component.
This is the components chance to train itself provided
with the training data. The component can rely on
any context attribute to be present, that gets created
by a call to :meth:`components.Component.pipeline_init`
of ANY component and
on any context attributes created by a call to
:meth:`components.Component.train`
of components previous to this one."""
pass
def process(self, message: Message, **kwargs: Any) -> None:
"""Process an incoming message.
This is the components chance to process an incoming
message. The component can rely on
any context attribute to be present, that gets created
by a call to :meth:`components.Component.pipeline_init`
of ANY component and
on any context attributes created by a call to
:meth:`components.Component.process`
of components previous to this one."""
pass
def persist(self, file_name: Text, model_dir: Text) -> Optional[Dict[Text, Any]]:
"""Persist this component to disk for future loading."""
pass
@classmethod
def load(
cls,
meta: Dict[Text, Any],
model_dir: Text,
model_metadata: Optional["Metadata"] = None,
cached_component: Optional["Component"] = None,
**kwargs: Any,
) -> "Component":
"""Load this component from file."""
if cached_component:
return cached_component
else:
return cls(meta)
自定义tokenizer:
class MyTokenizer(Tokenizer):
language_list = ["zh"]
def __init__(self, component_config: Dict[Text, Any] = None) -> None:
"""Construct a new Tokenizer."""
super().__init__(component_config)
@classmethod
def required_packages(cls) -> List[Text]:
return []
def tokenize(self, message: Message, attribute: Text) -> List[Token]:
"""Construct a new Tokenizer."""
return tokens
3. Rasa Core (DM)
3.1 介绍
对话管理模块 (Dialogue Management)主要用来根据NLU输出的用户意图、槽位等信息,结合对话跟踪模块提供的历史上下文信息,决定对话过程中执行什么actions,因此也被称为Dialogue Policies。可以同时选择多个policies,由rasa agent统一调度,选择其中置信度最高的action。
3.2 Policies
Policy Priority: 当不同的policy的预测结果有相同的置信度时,按优先级进行排序:RulePolicy,6;MemoizationPolicy / Augmented Memoization Policy,3;UnexpecTEDIntentPolicy,2;TEDPolicy,1。
- RulePolicy
根据rule.yml中配置的规则进行预测,优先级最高。
rasa提供了非常丰富的规则,通过规则组合形成各种策略。
policies:
- name: "RulePolicy"
core_fallback_threshold: 0.3 # 当 policies不能预测出下一个action时,回退的action
core_fallback_action_name: action_default_fallback
enable_fallback_prediction: true
restrict_rules: true
check_for_contradictions: true # 训练前检查 slots和 active loops在rules中的一致性
- MemoizationPolicy
记住了训练数据中的全部stories,检查当前对话是否与训练数据中的任意story相匹配。匹配数据时,选取最近max_history轮数据:
policies:
- name: "MemoizationPolicy"
max_history: 7
-
Augmented Memoization Policy
在MemoizationPolicy基础上增加了遗忘机制,在缩减后的历史记录中寻找匹配的信息 -
TEDPolicy
参阅《【RASA】TED Policy:Dialogue Transformers》 -
UnexpecTED Intent Policy
和TEDPolicy有相同的架构,从stories中学习用户在给定对话上下文中最有可能表达的意图集 (Intent Set)。其作为辅助性工具,用于判断NLU输出的意图是否可靠:若可靠,则不执行任何action;若不可靠,则激活deny意图,并执行action_unlikely_intent -
Custom Policies
policies: (自定义 policy)
- name: "path.to.your.policy.class"
arg1: "……"
需要在配置项中指定priority (优先级)参数:
class TEDPolicy(Policy):
def __init__(
self,
featurizer: Optional[TrackerFeaturizer] = None,
priority: int = DEFAULT_POLICY_PRIORITY,
max_history: Optional[int] = None,
model: Optional[RasaModel] = None,
fake_features: Optional[Dict[Text, List["Features"]]] = None,
) -> None:
主要函数:
train( ): 训练组件(可选) ;
predict_action_probalities( ): 预测下一步需要执行的 action;
persist( ): 保存 policy 组件模型到本地;
load( ): 加载保存好的 policy 组建模型
- 配置
max_history:需要考虑多少轮的对话历史来预测下一步的action。太长会增加训练时长,可以把上下文信息设置为slot,在整个对话过程中都有效
Data augmentation:随机将stories.yml中的story粘在一起,创建更长的故事
Featurizers:
State Featurizers:需要将用户的历史状态数据转换成特征向量,供policy使用;rasa的每个故事都对应一个追踪器,对历史中的每个事件都创建一个状态;对追踪器的单个状态进行特征化:SingleStateFeaturizer。
Tracker Featurizers:在预测action时,除了当前状态,还应包含一些历史记录。FullDialogueTrackerFeaturizer:将整个对话都传入神经网络,遍历跟踪器状态,为每一个状态调用 SingleStateFeaturizer。MaxHistoryTrackerFeaturizer:和 full 类似,参数 max_history 定义了跟踪历史状态的轮数。IntentMaxHistoryTrackerFeaturizer:由 UnexpecTEDIntentPolicy 使用,目标标签是用户在对话跟踪器的上下文中表达的意图
3.3 Actions
- Responses
response 内容可以是文本、按钮、图像、连接等信息
位于 domain.yml 或 responses.yml 中对应 response 键的下方,以 utter_ 开头
responses 中可以加入变量,使用 slot_name 去引用变量
同一个 response 名称,可以对应多个话术,调度器会随机访问,增加话术多样性
responses:
utter_ask_type:
- text: 请问您是咨询哪款机型?
utter_greet:
- text: 你好, name. 最近怎样?
utter_cheer_up:
- text: 这儿有一些有趣的照片。
image: "https://i.imgur.com/nGF1K8f.jpg"
- Forms
向用户询问 slots 信息,必须添加 RulePolicy。
定义表单:在配置文件forms
forms:
type_form: 型号表单
required_slots:
car_type:
- type: from_entity
插槽映射 (slot mappings),即需要哪些slots,如何填充这些slots:
from_entity:基于抽取出的 entities 来 fill slots。
from_text:使用用户的对话来 fill slots。
from_intent:若用户意图满足条件,使用得到的 value 来 fill slots。
from_trigger_intent:根据激活表单的意图来 fill slots
激活表单:添加story或rule,告知何时运行该表单
rules: (激活表单)
- rule: Activate form
steps:
- intent: request_car_type
- action: type_form # 开始运行表单
- active_loop: car_form # 激活表单
注意:激活填单会自动执行 utter_ask_slot name 的response,来询问槽位信息。
停用表单:当所有 slots 都被填满时,将自动停用。提前中断/停止:当用户不配合时,使用一些自定义的包含意图中断的 rules / stories
rules:
- rule: (停用并提交表单)
condition:
- active_loop: type_form # 满足表单激活的状态
steps:
- action: type_form
- active_loop: null # 停用该表单
- slot_was_set:
- requested_slot: null # 不再请求slot
- action: utter_submit # 提交表单
- rule: (用户中途切换话题)
condition:
- active_loop: type_form
steps:
- intent: chitchat # 用户中途开始闲聊
- action: utter_chitchat # 回应闲聊
- action: type_form
- active_loop: type_form
-
Default Actions
Rasa内置在对话管理模块中的actions
action_listen:等待下一次用户输入
action_restart:重置整个对话历史记录
action_session_start:启动一个新的会话 session
action_default_fallback:撤消上一次用户与机器人的交互,并发送 utter_default 响应
action_deactive_loop:禁用处理表单的动作循环,并重置请求的 slots
action_two_stage_fallback:先调用 action_default_ask_affirmation 二次询问确认后,再撤销
action_default_ask_affirmation:由action_two_stage_fallback使用,要求用户确认意图
action_default_ask_rephrase:若用户拒绝确认意图,则循环使用此操作
action_back:撤销上一次用户和机器人的交互 -
Custom Actions
自定义动作,继承 rasa_sdk 的 Action 类:
name( ):自定义action的名称
run( ):执行action的具体操作,自定义编写
dispatcher.utter_message( ) :向用户发送信息
tracker.get_slot(slot_name):获取插槽的值
tracker.lastest_message:获取最近的用户信息
Slotset(key:Text, value: Any):为插槽设置 value
class Action:
def name(self) -> Text:
raise NotImplementedError("An action must implement a name")
async def run(
self,
dispatcher: "CollectingDispatcher",
tracker: Tracker,
domain: "DomainDict",
) -> List[Dict[Text, Any]]:
3.4 训练数据构造
训练数据,stories和rules
-
stories
根据任务需要,设置不同种类和数量的steps:
intent:来自用户的消息,可直接利用NLU pipeline输出的intent和entity
action:参考3.3节
active_loop:active_loop: name_forms (表示当前有一个激活的表格);active_loop: null (执行下一个step前,所有表格都应该被填满)
slot_was_set:指定 slot event,使用slot name和可选的slot value。
checkpoint (不要过度使用,会降低训练速度):在故事的开头或结尾指定,用于连接不同的故事,可以简化数据并减少冗余。以checkpoint结尾的story,会连接到以checkpoint开头的同名的story
or (不要过度使用,会降低训练速度):以相同的方式处理多个intent的方法,不必为每个意图编写单独的故事;在训练的时候,会转化成多个独立的stories -
rules
三种使用rules的常见场景:
控制 fallback behaviour: 将规则和 FallbackClassifier 结合使用。自定义当 NLU 模型对其预测不确定时应该怎么操:
rules:
- rule: 当置信度低于阈值时,要求用户重新表述
steps:
- intent: nlu_fallback
- action: utter_please_rephrase
- 单轮互动:保证单轮互动中的特定结果
rules:
- rule: 只有当用户提供姓名后才回复问好
condition:
- slot_was_set:
- user_provided_name: true
steps:
- intent: greet
- action: utter_greet
- rasa interactive 人机交互生成训练数据
可通过Rasa X或者Command-line进行交互
和 bot 进行对话交互,并提供 feedback,帮助模型学到正确的 policy 和 actions
需要同时启动 action server,因为有自定义的 actions
每一步都需要人工确认预测的 actions 是否正确,若错误需要人工校正
? Next user input: hello
? Is the NLU classification for 'hello' with intent 'hello' correct? Yes
------
Chat History
# Bot You
────────────────────────────────────────────
1 action_listen
────────────────────────────────────────────
2 hello
intent: hello 1.00
------
? The bot wants to run 'utter_greet', correct? (Y/n)
以上是关于rasa 介绍文档的主要内容,如果未能解决你的问题,请参考以下文章