NAACL 2021RCI:在基于 Transformer 的表格问答中行和列语义捕获
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NAACL 2021RCI:在基于 Transformer 的表格问答中行和列语义捕获相关的知识,希望对你有一定的参考价值。
1、简介
- 论文地址:https://arxiv.org/pdf/2104.08303.pdf
最近,基于 Transformer 的架构被用于越来越多被应用于Table QA。在本文中,作者提出了两种新颖的方法,证明一种方法可以在不使用任何这些专门的预训练技术的情况下在 Table QA 任务上实现卓越的性能。
- 第一个模型称为 RCI Interaction ,它利用基于 Transformer 的架构,该架构独立地对行和列进行分类以识别相关单元格。该模型在最近的基准测试中查找单元格值时产生了极高的准确性。
- 作者还提出的第二种模型,称为 RCI Representation,通过实现现有表的嵌入,为在线 QA 系统提供了优于表的显着效率优势。
在最近的基准上实验证明,所提出的方法可以有效地定位表格上的单元格值(在 WikiSQL 查找问题上高达 ∼98% 的 Hit@1 准确率)。此外,RCI Interaction 模型优于最先进的基于 Transformer 在非常大的表语料库(TAPAS 和 TABERT)上进行预训练的方法,在标准 WikiSQL 基准上实现了 ∼3.4% 和 ∼18.86% 的额外精度提高。
2、模型介绍
2.1 模型结构
RCI使用文本匹配来定位答案所在的行或者列,其中一个文本是Question,另一个文本是行或者列。
- RCI Interaction:序列化文本会使用[CLS]和[SEP]将问题与行或者列文本进行拼接,然后这个序列对被输入至ALBERT 。最终[CLS] 隐藏层的输出用于后面的线性层和softmax,判断行或者列是否包含答案。
- RCI Representation:
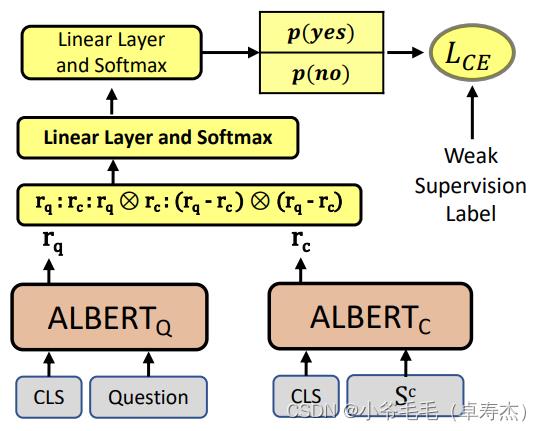 问题的向量表示和列或者行的向量表示会先被分别算出来。然后,这两个向量按如上图所示的方式进行拼接,并使用带有softmax层的全连接层对拼接后的向量进行分类。
问题的向量表示和列或者行的向量表示会先被分别算出来。然后,这两个向量按如上图所示的方式进行拼接,并使用带有softmax层的全连接层对拼接后的向量进行分类。
2.2 表格序列化
我们了解了模型的结构后,还有个问题没介绍,那就是行和列是怎么序列化为文本的?作者这里采用的方案是:
- 行:每个单元格的序列化为:单元格的值与该单元格所对应的列标题的拼接,再将该行的每个单元格序列化拼接,构成行的序列化。
- 列:将该列列表头与该列的各个单元格值进行拼接,构成列的序列化。
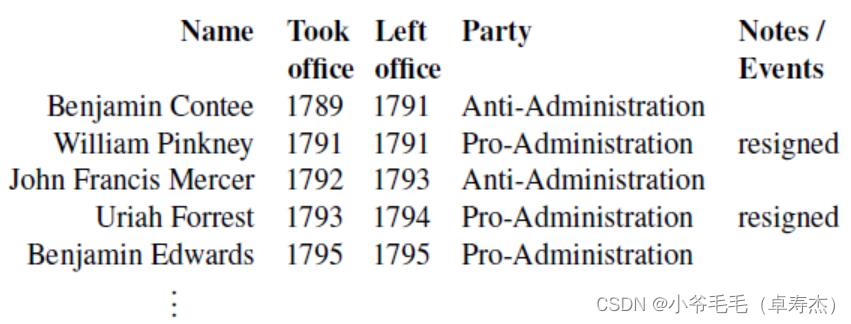
举个例子,如上所示的表。该表格的第一行被转换为:
Name:Benjamin Contee|Took office:1789|Left office:1791|Party:Anti-Administration|Note/Events:|
该表的第二列被转换为
Took office : 1789 | 1791 | 1792 | 1793 | 1795 |
3. 扩展到聚合问题
虽然 RCI 的重点是解决表格查找问题,但也可以通过添加问题分类器扩展到聚合问题。训练另一个Transformer将“问题-表头”序列对分类为六类之一:lookup, max, min, count, sum 和average。因为表格标题是和,诸如“How many wins do the Cubs have?”之类的问题是相关的。可以由 lookup、count 或者 sum操作得到答案,具体取决于表的结构。
对 RCI 模型的单元级别置信度设置一个阈值,并按预测的问题类型,进行聚合,产生最终答案,即可用于单元格的查找问题,也可以用于聚合成单个数字的问题。
以上是关于NAACL 2021RCI:在基于 Transformer 的表格问答中行和列语义捕获的主要内容,如果未能解决你的问题,请参考以下文章