论文笔记Reading Scene Text in Deep Convolutional Sequences
Posted 糖梦梦是女侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记Reading Scene Text in Deep Convolutional Sequences相关的知识,希望对你有一定的参考价值。
论文来源:http://www.eecs.qmul.ac.uk/~ccloy/files/aaai_2016_reading.pdf
接收会议:AAAI 2016(the Association for the Advance of Artificial Intelligence)人工智能领域非常不错的一个会议。
论文架构:
Abstract
1.Introduction
2.Related Work
3.Deep-Text Recurrent Networks (DTRN)
3.1 SequenceGeneration with Maxout CNN
3.2 SequenceLabeling with RNN
3.3 ImplementationDetails
4.Experiments and Results
4.1 DTRN vs DeepFeatures
4.2 Comparison with State-of-the-Art
5.Conclusionand future directions
《Reading Scene Text in Deep Convolutional Sequences》
1.内容概述
建立一个深度文本循环网络(Deep-Text Recurrent Network, DTRN),将自然场景中的文本识别问题转换成一个序列标记问题。为了避免比较困难的字符分割问题,使用CNN从整张单词图片中生成一个有序的高级序列,然后使用建立在长短记忆网络(long short-term memory,LSTM)上的深度循环模型来识别生成CNN序列(即:使用deep CNN进行图像表示学习,RNN进行序列标记)。本文的主要特点是:
(1)可以利用有用的文本信息来识别高度模糊的词汇,不需要预处理或者后期处理;
(2)深度CNN特征足以抵抗严重扭曲的单词;
(3)包含词汇图片中明确的顺序信息,这是划分单词串的根本;
(4)这个模型不依赖预定义的词典,可以处理未知单词和任意单词串。
主要贡献:
(1)建立了一个统一deep recurrent system,同时利用CNN和RNN的优点来解决自然场景文本识别的问题;
(2)这是将卷积序列与系列标记模型相结合解决这个问题的第一次尝试;
(3)提出的DTRN在几个benchmark中,都获得了最佳的结果。
2.方法
提出了一个结合CNN与RNN的端到端DTRN系统:CNN将输入的单词图片编码为顺序序列,RNN将CNN序列译码(识别)为单词串。主要处理流程如图1所示。
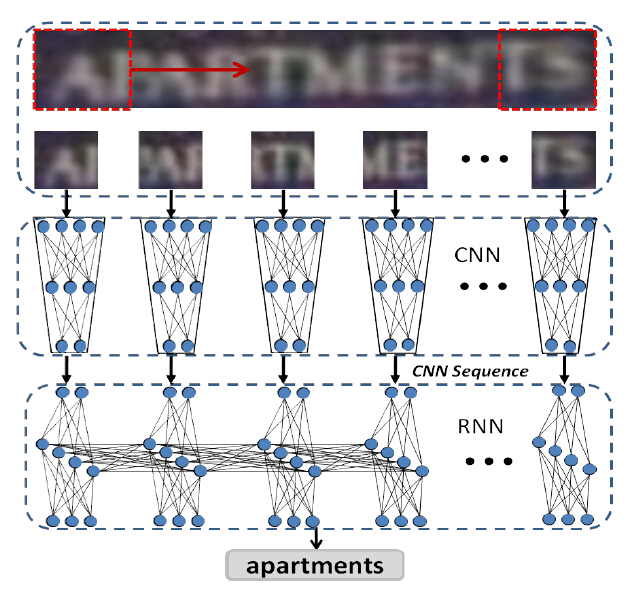
图1.DTRN模型单词图片识别基本流程
(1)MaxOut CNN生成序列
输入world image(即从自然场景文本中提取的包含一个单词串的图片),将其resize到高度为32、长宽比不变的图片大小,以一个32X32的滑窗在这个world image 上滑动,每次取32X32的图片大小输入到CNN中,CNN对其进行特征提取,最终返回128D的CNN序列。MaxOut CNN的网络结构如图2所示。
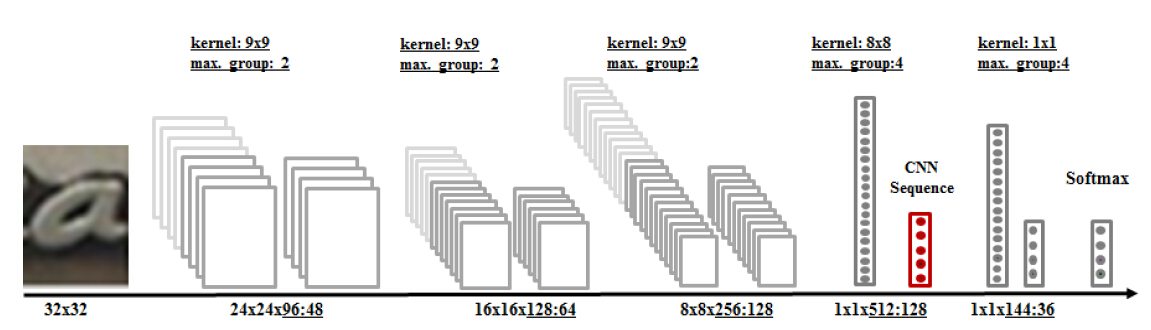
图2.MaxOut CNN模型结构
a.输入图片大小:32X32,即滑动窗口的大小;
b.5层卷积层,每一层后面跟着2组或者4组MaxOut操作,feature map的数目分别为48、64、128、128和36;
c.不包含pooling层,最后两层卷积的输出为单个像素;
d.这个MaxOut CNN使用了36类的字符图片进行训练(这里我理解的是:这个CNN用了字符图片(character images)来进行训练,训练完成后,这个网络能够极好地提取图片的特征,在最终识别的时候只是获取了128D的CNN序列,将这个CNN序列输入到后面的RNN中进行序列标记,并未用到图中的softmax和倒数第一层1X1X144:36, softmax和倒数第一层1X1X144:36应该只是用于训练,不知道这里理解是否正确)。
(2)RNN进行序列标记
RNN对有序序列中有意义的结构具有很强的学习能力,而自然场景中的文本上下文往往包含很重要的信息,应用RNN可以很好地利用上下文信息来对序列进行预测。RNN结构如图3所示。
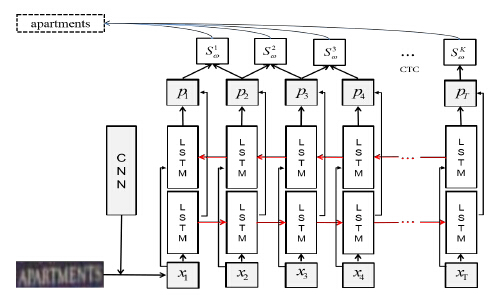
图3.RNN结构
此文中RNN的为LSTM。针对变长的序列标记,对每一个输入序列Xt循环调用LSTM,这样所有的LSTM 使用一样的参数。LSTM的输出ht一方面作为下一次的输入Xt+1送到LSTM中,另一方面也用来计算当前输出,转化为估算所有可能字符的可能性。最终生成一个预测序列,与输入序列具有相同长度。
由于LSTM输出的长度与目标单词串的长度不一致,因此很难使用目标单词串来对LSTM 进行直接训练。因此使用了一个CTC(Connectionist Temporal Classification)将LSTM的序列输出匹配到目标字符串。它的主要功能是移除循环标记和非字符标记。例如:(-gg-o-oo-dd-)=good。CTC在LSTM输出中找到具有最大可能性的最优化路径,将不同长度的LSTM序列与单词字符串匹配。CTC层直接连接到LSTM的输出上,作为整个RNN的输出。
(3)实现细节
a.CNN使用了从一序列benchmarks训练集中提取的1.8×100000张character images进行训练。
b.循环模型包含了一个双向LSTM,LSTM的每一层包含128个cell memory bolcks。输入层包含128个神经元(与128D的CNN序列相对应),同时与两层隐层全连接。两层隐层串联,然后与LSTM 37个类(包含一个非字符类)的输出层全连接,使用了softmax函数。RNN模型总共有273K个参数。实验发现增加LSTM的层数并不能获得更好的结果。
c.循环模型使用梯度下降法来进行训练。learning rate=10-4,momentum=0.9。使用前馈-后馈算法来优化LSTM与CTC的参数,也就是在整个网络中使用了一个前向传输,紧跟着一个前馈-后馈算法将真实的词汇字符串匹配到LSTM输出。误差反向传播用于调整参数,其计算公式如下:
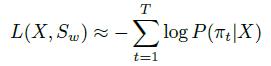
d.RNN使用了3000张word images来进行训练。
(注意:这部分的内容主要跟深度学习相关网络训练、参数选择有关。)
3.实验及结果
(1)Datasets: Street View Text、ICDAR 2003、IIIT 5K-word
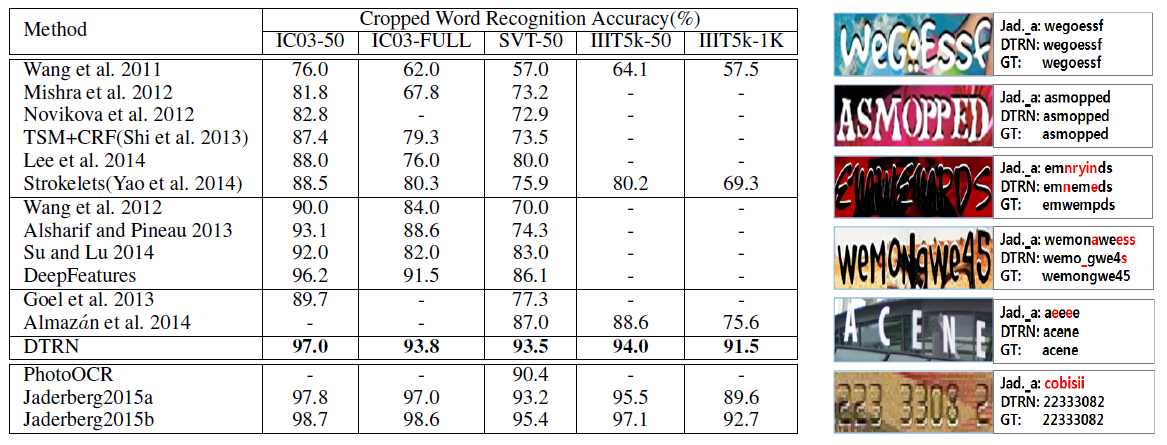
(2)实验结果:
以上是关于论文笔记Reading Scene Text in Deep Convolutional Sequences的主要内容,如果未能解决你的问题,请参考以下文章