Python3.6+jieba+wordcloud 爬取豆瓣影评生成词云
Posted geekfly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3.6+jieba+wordcloud 爬取豆瓣影评生成词云相关的知识,希望对你有一定的参考价值。
在上一篇介绍了如何通过Python爬虫抓取豆瓣电影榜单。Python3.6+Beautiful Soup+csv 爬取豆瓣电影Top250
此篇博客主要抓取豆瓣某个电影的影评,利用jieba分词和wordcloud词云生成影评词云。
下文以电影无名之辈为例:https://movie.douban.com/subject/27110296/comments?start=0&limit=20&sort=new_score&status=P
0. 依赖包
- 中文分词:
pip install jieba - 词云:
pip install wordcloud - 绘图:
pip install matplotlib
1. 分析翻页
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P&percent_type=' \\
% (movie_id, (i - 1) * 20)
其中i代表当前页码,从0开始。

2. 获取影评
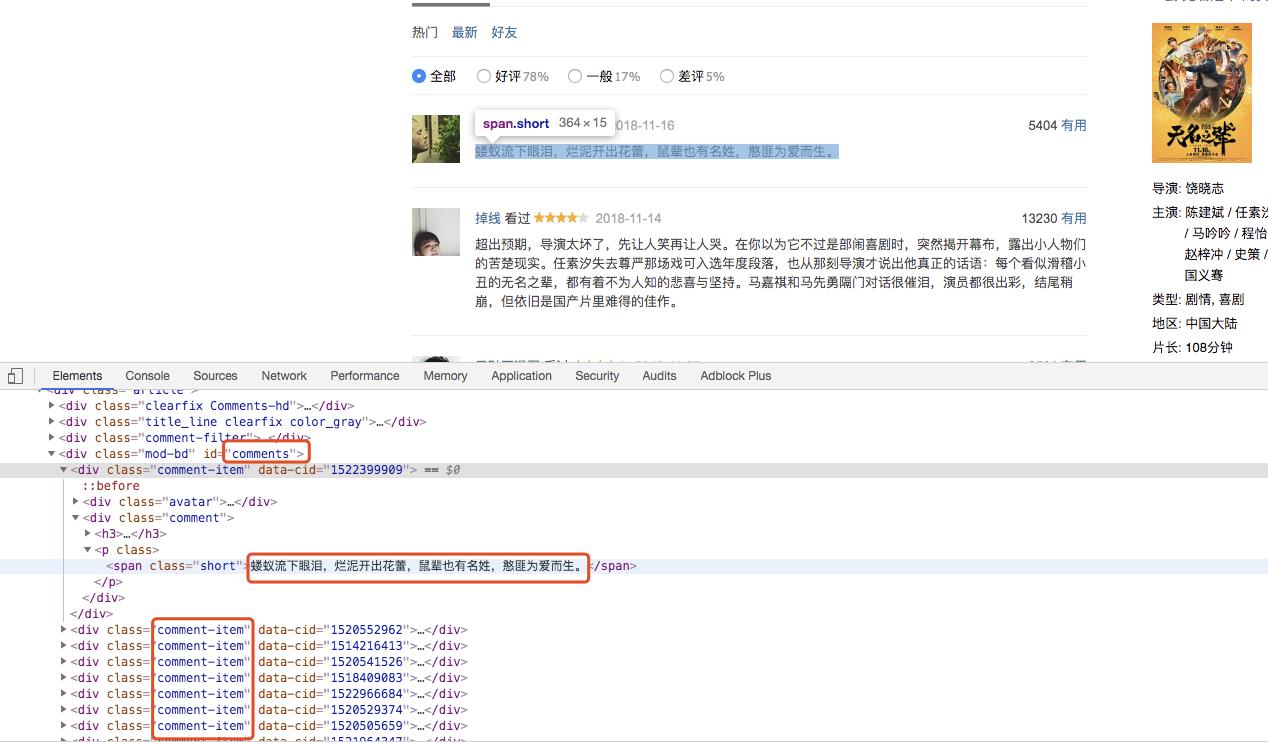
分析源码,可以看到评论在div[id=‘comments’]下的div[class=‘comment-item’]中的第一个span[class=‘short’]中,即代码为:
soup = BeautifulSoup(req)
comment_div_list = soup.select('#comments .comment-item')
for comment_div in comment_div_list:
print(comment_div.select('.short')[0].text)
3. 使用jieba分词和wordcloud词云
def wordcloud(comment_list):
wordlist = jieba.lcut(''.join(comment_list))
text = ' '.join(wordlist)
print(text)
wordcloud = WordCloud(
font_path="./simkai.ttf", # 字体需下载到本地,不引入会出现乱码,色彩图块等异常,可替换其他中文字体库
background_color="white",
max_font_size=80,
stopwords=STOPWORDS,
width=1000,
height=860,
margin=2, ).generate(text)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
关于jieba分词:https://github.com/fxsjy/jieba
关于wordcloud词云:https://www.datacamp.com/community/tutorials/wordcloud-python
字体文件:https://cs.fit.edu/code/projects/ndworld/repository/changes/Resources/Fonts/simkai.ttf?rev=11
4. 效果

5. 完整代码
import requests
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
from bs4 import BeautifulSoup
def spider_comment(movie_id, page):
"""
爬取评论
:param movie_id: 电影ID
:param page: 爬取前N页
:return: 评论内容
"""
comment_list = []
for i in range(page):
url = 'https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P&percent_type=' \\
% (movie_id, (i - 1) * 20)
req = requests.get(url).content
soup = BeautifulSoup(req)
comment_div_list = soup.select('#comments .comment-item')
for comment_div in comment_div_list:
comment_list.append(comment_div.select('.short')[0].text)
print("当前页数:%s,总评论数:%s" % (i, len(comment_list)))
return comment_list
def wordcloud(comment_list):
wordlist = jieba.lcut(' '.join(comment_list))
text = ' '.join(wordlist)
print(text)
wordcloud = WordCloud(
font_path="./simkai.ttf",
background_color="white",
max_font_size=80,
stopwords=STOPWORDS,
width=1000,
height=860,
margin=2, ).generate(text)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# 主函数
if __name__ == '__main__':
movie_id = '27110296'
page = 10
comment_list = spider_comment(movie_id, page)
wordcloud(comment_list)
以上是关于Python3.6+jieba+wordcloud 爬取豆瓣影评生成词云的主要内容,如果未能解决你的问题,请参考以下文章