BERT实战:使用DistilBERT作为词嵌入进行文本情感分类,与其它词向量(FastText,Word2vec,Glove)进行对比
Posted 梆子井欢喜坨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BERT实战:使用DistilBERT作为词嵌入进行文本情感分类,与其它词向量(FastText,Word2vec,Glove)进行对比相关的知识,希望对你有一定的参考价值。
这次根据一篇教程Jay Alammar: A Visual Guide to Using BERT for the First Time学习下如何在Pytorch框架下使用BERT。
主要参考了中文翻译版本
教程提供了可用的代码,可以在colab或者github获取。
1. huggingface/transformers
Transformers提供了数千个预训练的模型来执行文本任务,如100多种语言的分类、信息提取、问答、摘要、翻译、文本生成等。
文档:https://huggingface.co/transformers/
模型:https://huggingface.co/models
huggingface团队用pytorch复现许多模型,本次要使用它们提出的DistilBERT模型。
2. 数据集
本次使用的数据集是 SST2,是一个电影评论的数据集。用标签 0/1 代表情感正负。

3. 模型
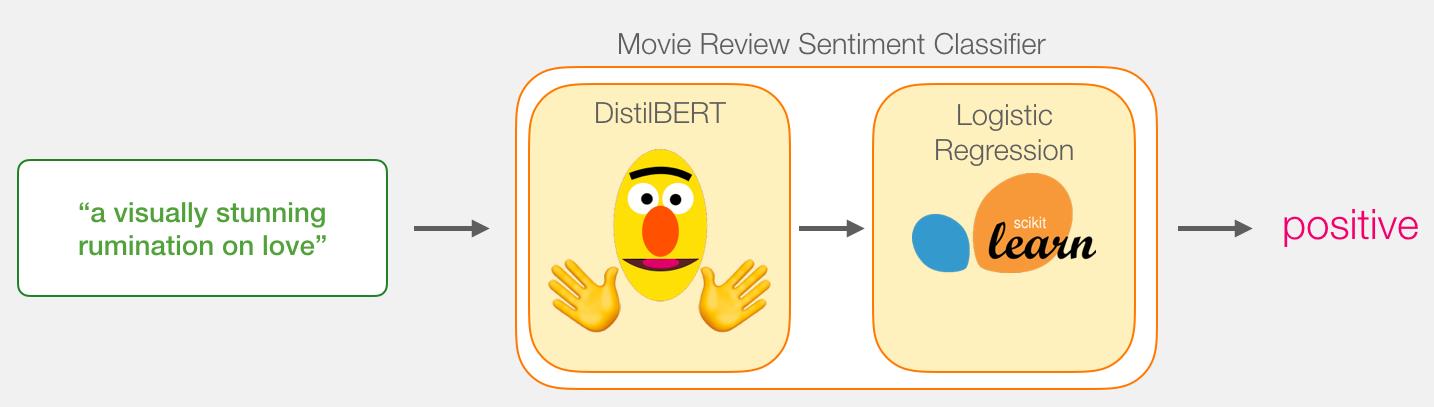
句子的情感分类模型由两部分组成:
- DistilBERT处理输入的句子,并将它从句子中提取的一些信息传递给下一个模型。 DistilBERT 是一个更小版本的 BERT 模型,是由 HuggingFace 团队开源的。它保留了 BERT 能力的同时,比 BERT 更小更快。
- 一个基本的 Logistic Regression 模型,它将处理 DistilBERT 的输出结果并且将句子进行分类,输出0或1。
在这两个模型之间传递的数据是一个 768 维的向量。
假设句子长度为n,那及一个句子经过BERT应该得到n个768 维的向量。
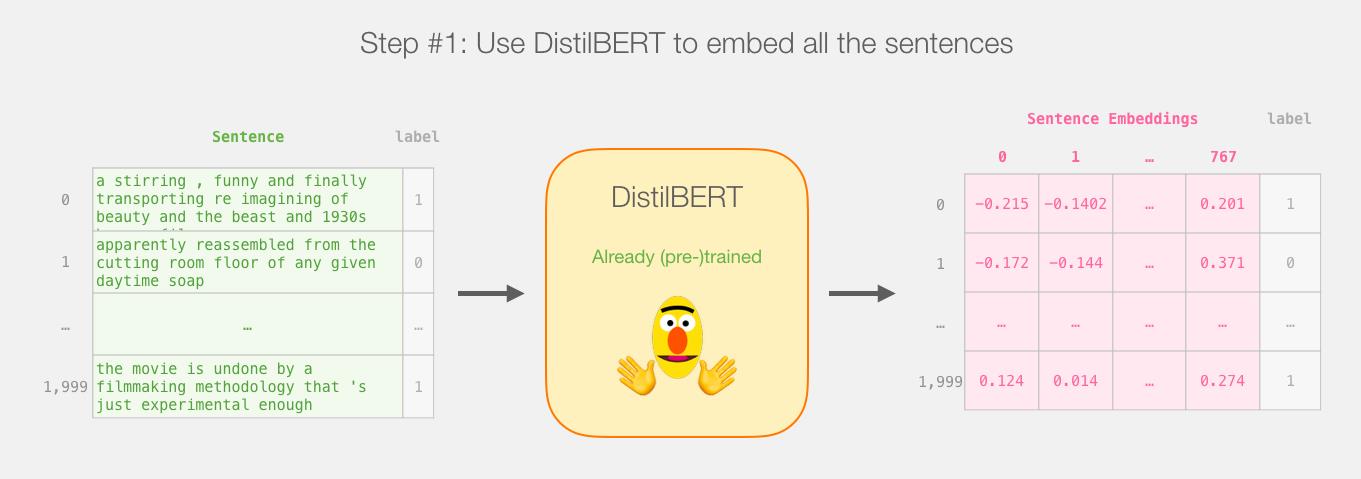
实际上只使用[CLS]位置的向量看作是我们用来分类的句子的embedding向量。
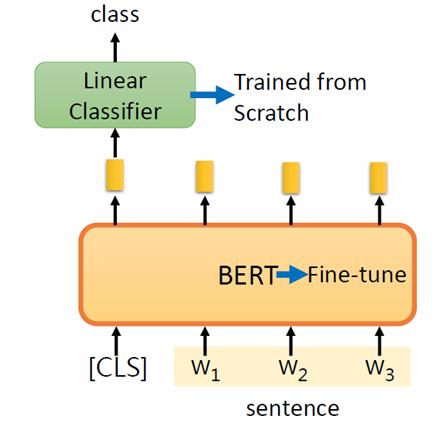
4. 训练与预测
4.1 训练
虽然我们使用了两个模型,但是只需要训练回归模型(Logistic Regression)即可。
对于 DistilBERT 模型,使用该模型预训练的参数即可,这个模型没有被用来做句子分类任务的训练和微调。
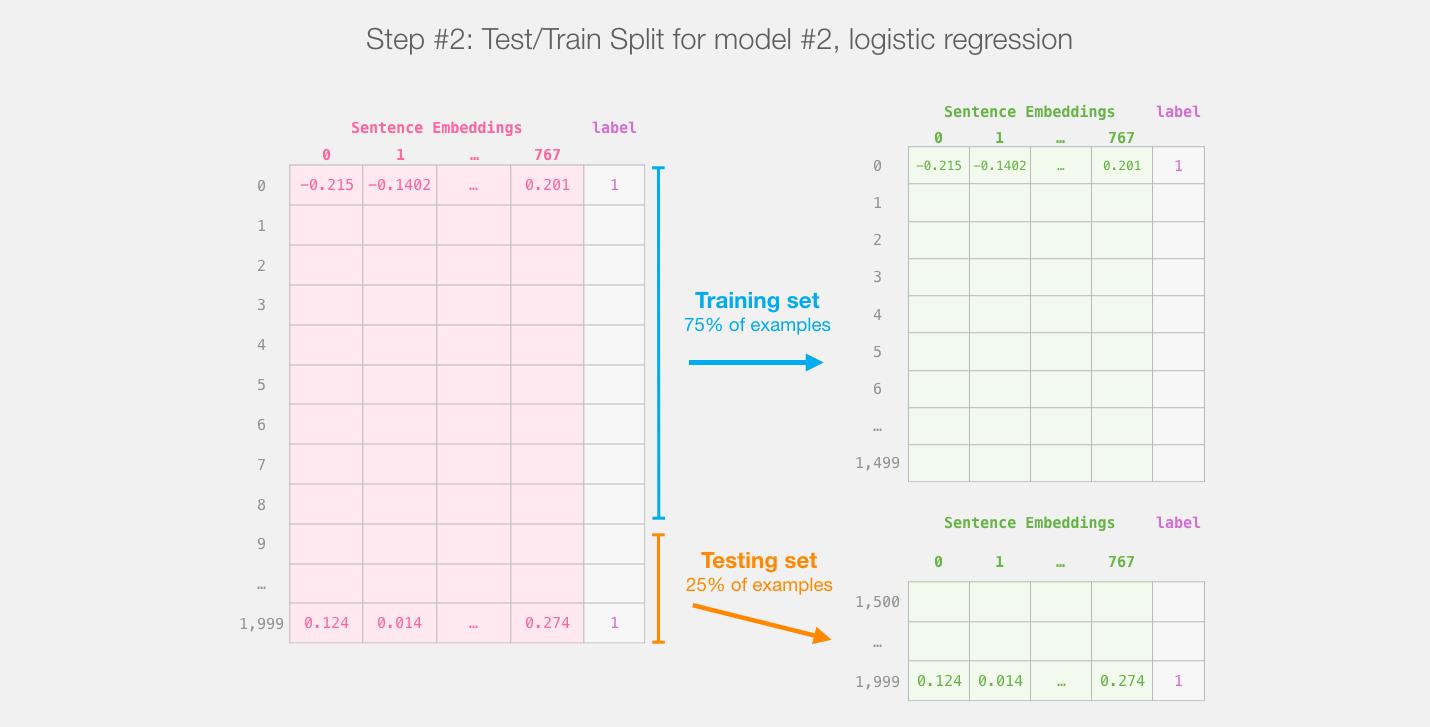
使用 Scikit Learn 工具包进行操作。将整个BERT输出的数据分成 train/test 数据集。
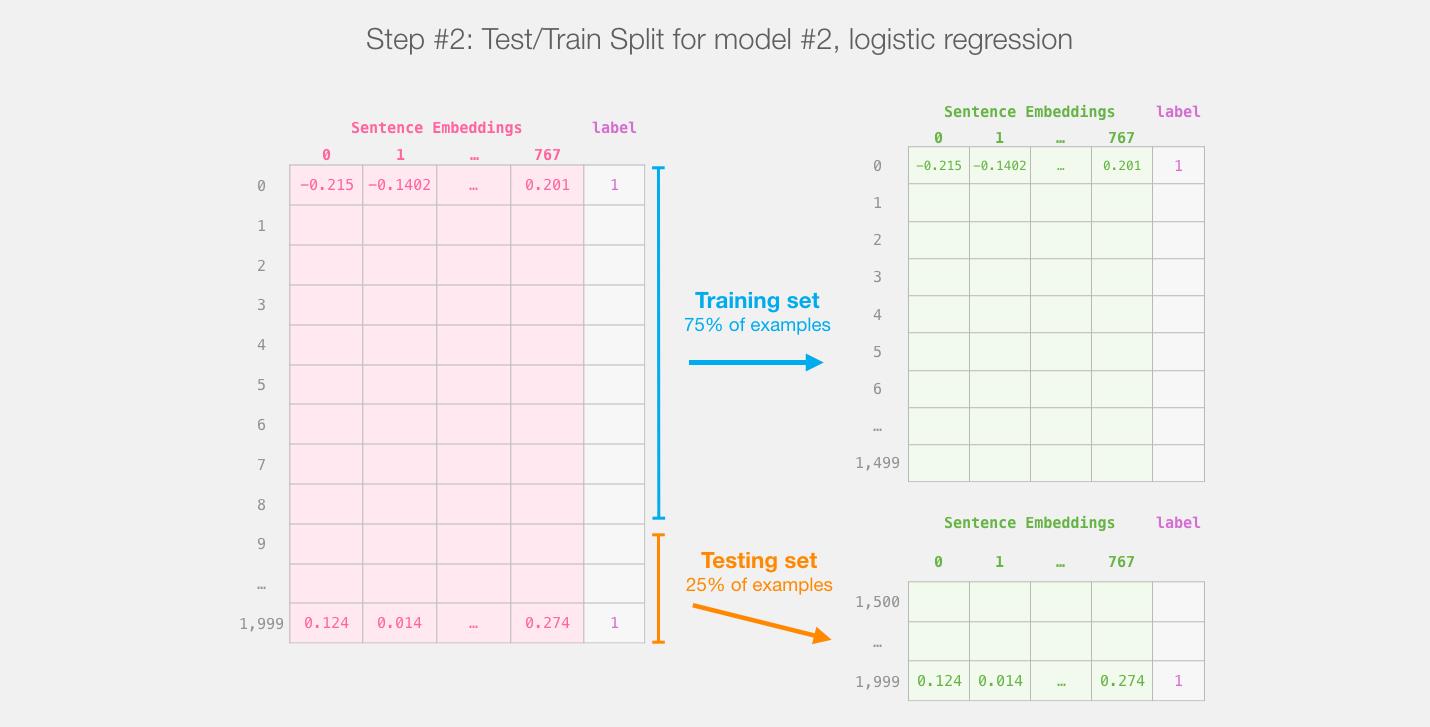
将75%的数据划为训练集,将25%的数据划分为测试集。
sklearn的train/test split在进行分割之前会对示例进行shuffles。
接下来就用机器学习的方法训练回归模型就行了。
4.2 预测
如何使用模型进行预测呢?
比如,我们要对句子 “a visually stunning rumination on love” 进行分类
第一步,用 BERT 的分词器(tokenizer)将句子分成 tokens;
第二步,添加特殊的 tokens 用于句子分类任务(在句子开头加上 [CLS],在句子结尾加上 [SEP]);
第三步,分词器(tokenizer)会将每个 token 替换成 embedding 表中的ID,embedding 表是我们预训练模型自带的;

下面这一行代码就完成了上述3步。
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)
每个token的输出都是一个一个768维的向量。
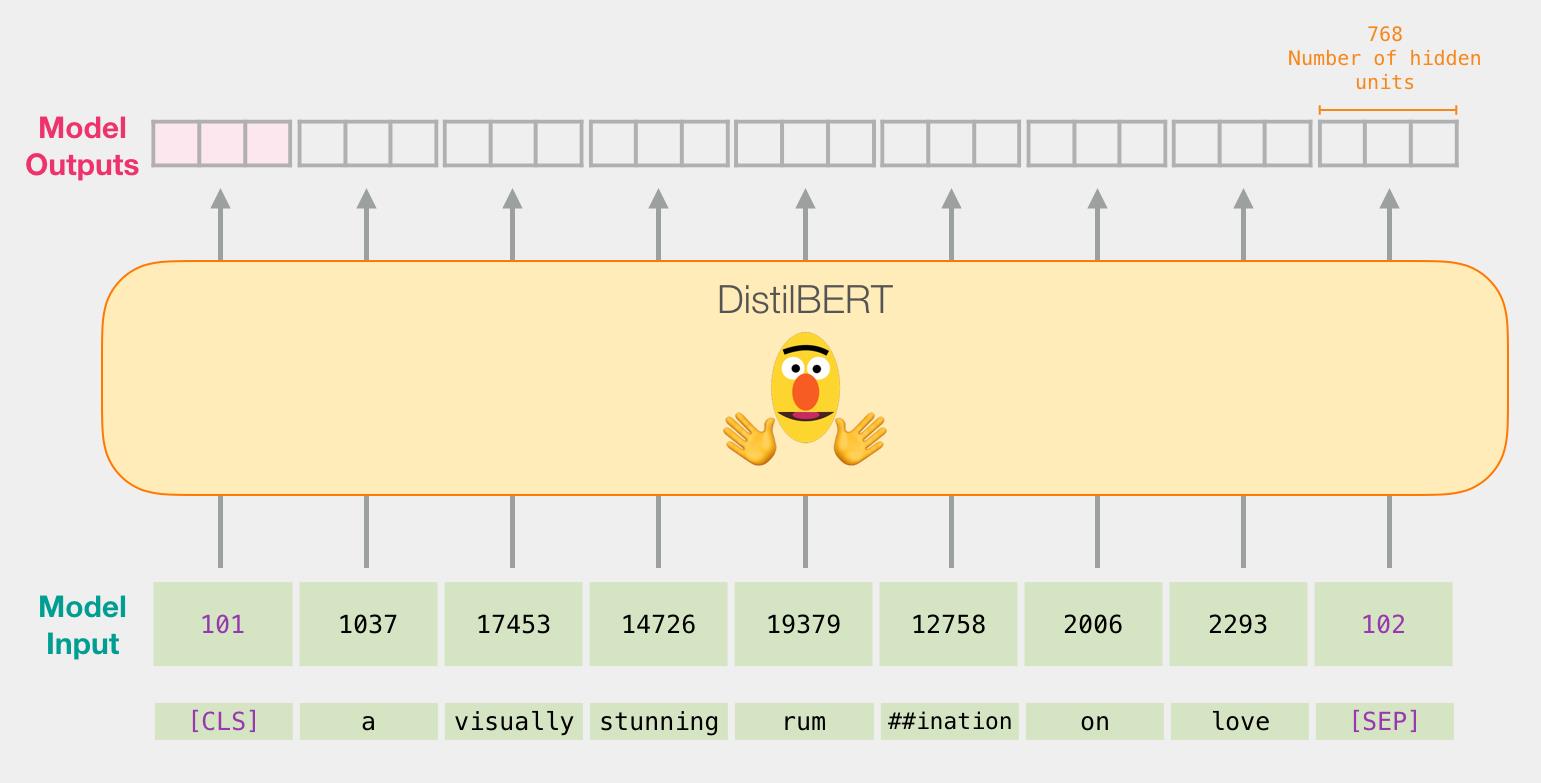
由于这是一个句子分类任务,我们只取第一个向量(与 [CLS] token有关的向量)而忽略其他的 token 向量。
将该向量作为 逻辑回归的输入。
5. 代码(加入图片注释)
环境的配置就不细说了,可以在transformers的github页面查阅
5.1 导入所需的工具包
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import torch
import transformers as ppb
import warnings
warnings.filterwarnings('ignore')
5.2 导入数据集
数据集的链接,这里我已经提前下载到本地了。
df = pd.read_csv('./train.tsv', delimiter='\\t', header=None)
# 为做示例只取前2000条数据
batch_1 = df[:2000]
# 查看正负例的数量
batch_1[1].value_counts()
5.3 导入预训练模型
下载大概花费了40s
# For DistilBERT:
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
## Want BERT instead of distilBERT? Uncomment the following line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
# Load pretrained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
5.4 数据预处理
包括token化和padding
token化的过程与4.2中图片相同
tokenized = batch_1[0].apply((lambda x:tokenizer.encode(x, add_special_tokens = True)))
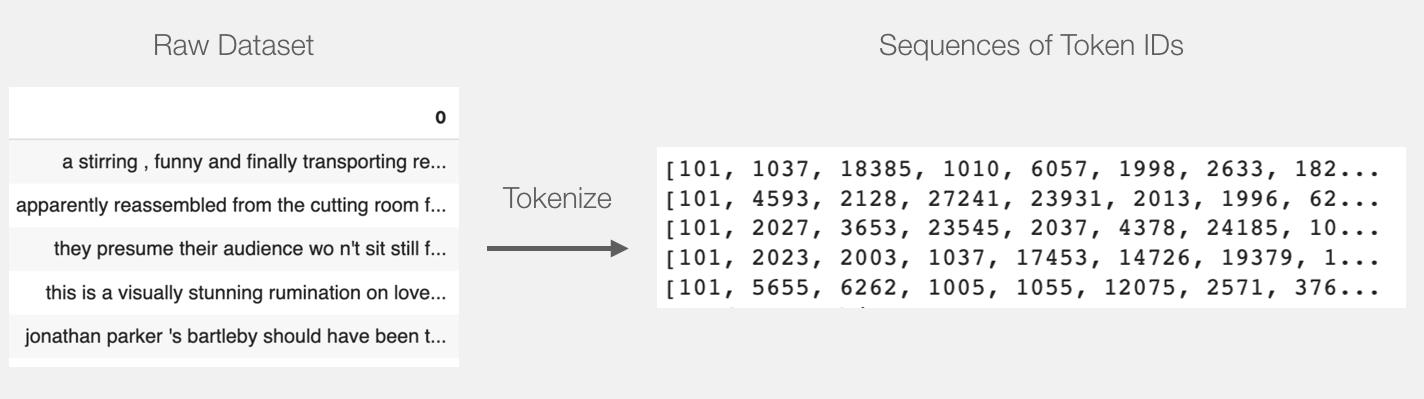
需要把所有的向量用 id 0 来填充较短的句子到一个相同的长度。
max_len = 0
for i in tokenized.values:
if len(i) > max_len:
max_len = len(i)
padded = np.array([i + [0] * (max_len - len(i)) for i in tokenized.values])
np.array(padded).shape
# Masking
# attention_mask(也就是input_mask)的0值只作用在padding部分
# np.where(condition, x, y) 满足条件(condition),输出x,不满足输出y
attention_mask = np.where(padded != 0, 1, 0)
attention_mask.shape
padding的过程如下图所示,值得注意的是,如果我们直接把padded发给BERT,那会让它有点混乱。我们需要创建另一个变量,告诉它在处理输入时忽略(屏蔽)我们添加的填充。这就是attention_mask:

5.5 使用BERT
# 基本可以看作又进行了一次embedding
input_ids = torch.LongTensor(padded)
attention_mask = torch.tensor(attention_mask)
with torch.no_grad():
last_hidden_states = model(input_ids, attention_mask=attention_mask)
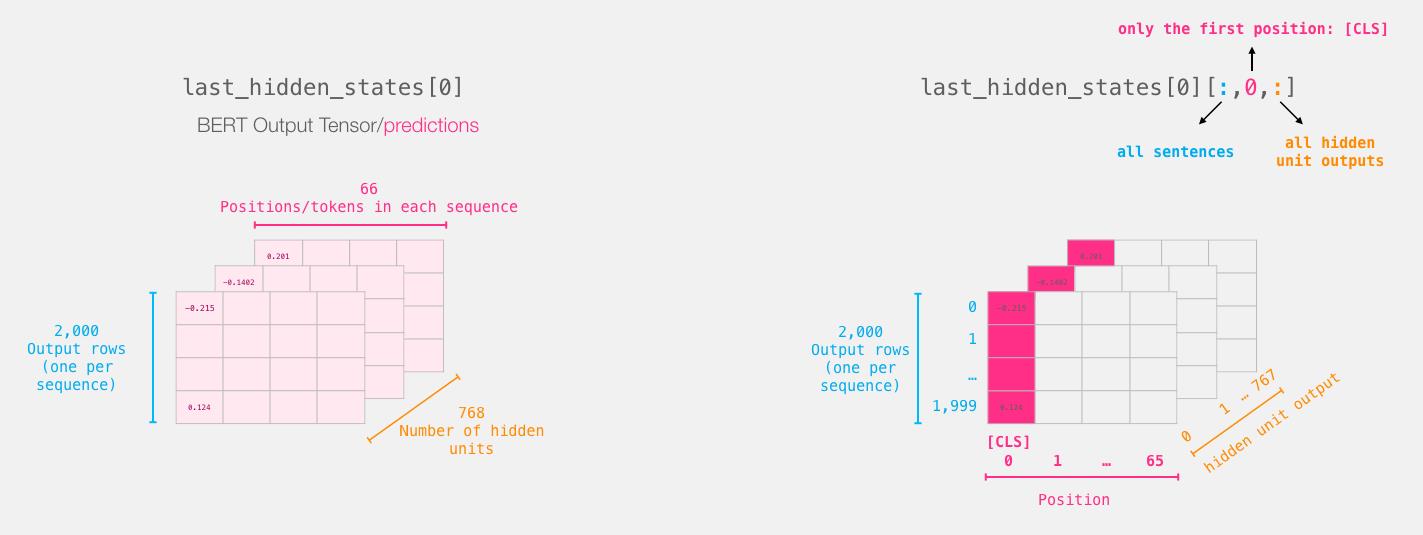
# BERT模型输出的张量尺寸为[2000, 59, 768]
# 取出[CLS]token对应的向量
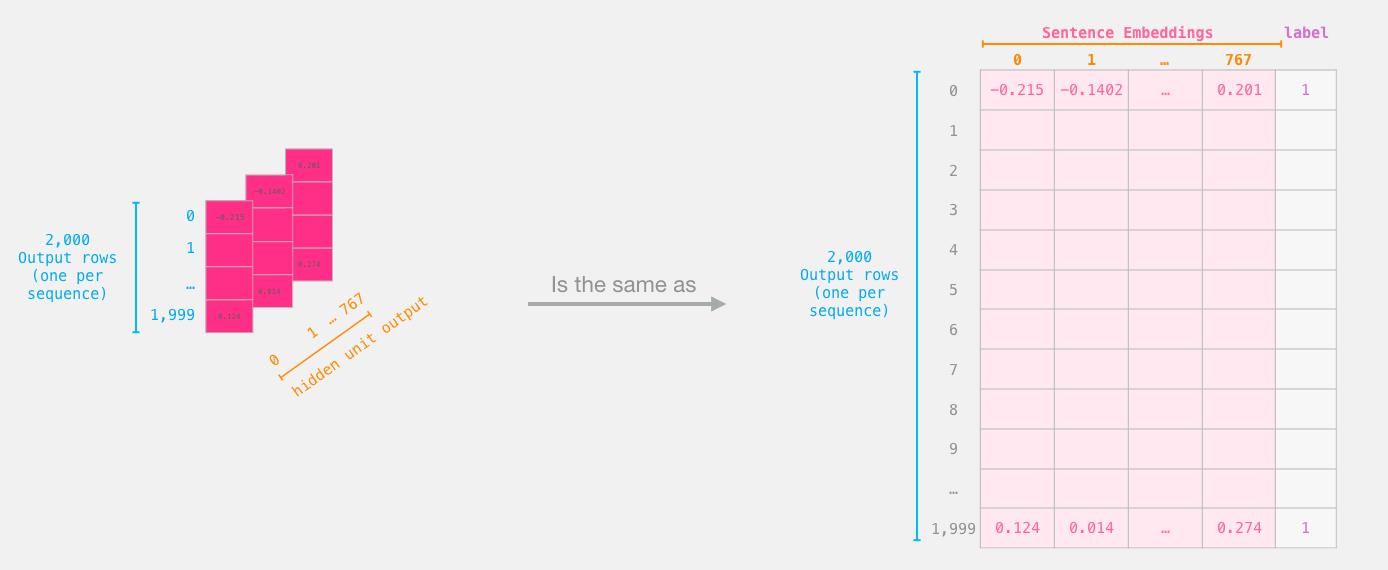
features = last_hidden_states[0][:,0,:].numpy()
labels = batch_1[1] # 取出标签
5.5 训练一个Logistic回归模型
# 划分训练集和测试集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
# 搜索正则化强度的C参数的最佳值。
parameters = 'C': np.linspace(0.0001, 100, 20)
grid_search = GridSearchCV(LogisticRegression(), parameters)
grid_search.fit(train_features, train_labels)
print('best parameters: ', grid_search.best_params_)
print('best scrores: ', grid_search.best_score_)
lr_clf = LogisticRegression(C = 10.526405263157894)
lr_clf.fit(train_features, train_labels)
lr_clf.score(test_features, test_labels)
在使用完整数据集的时候,预测的准确率约为0.847。
6.结果评估
from sklearn.dummy import DummyClassifier
clf = DummyClassifier()
scores = cross_val_score(clf, train_features, train_labels)
print("Dummy classifier score: %0.3f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
可以发现训练出的分类器的结果明显好于随即预测的结果。
但这个例子恐怕完全没有体现出BERT的性能,因为缺少了fine-tuning阶段。根据19年的教程,该数据集上最高的准确率是 96.8。
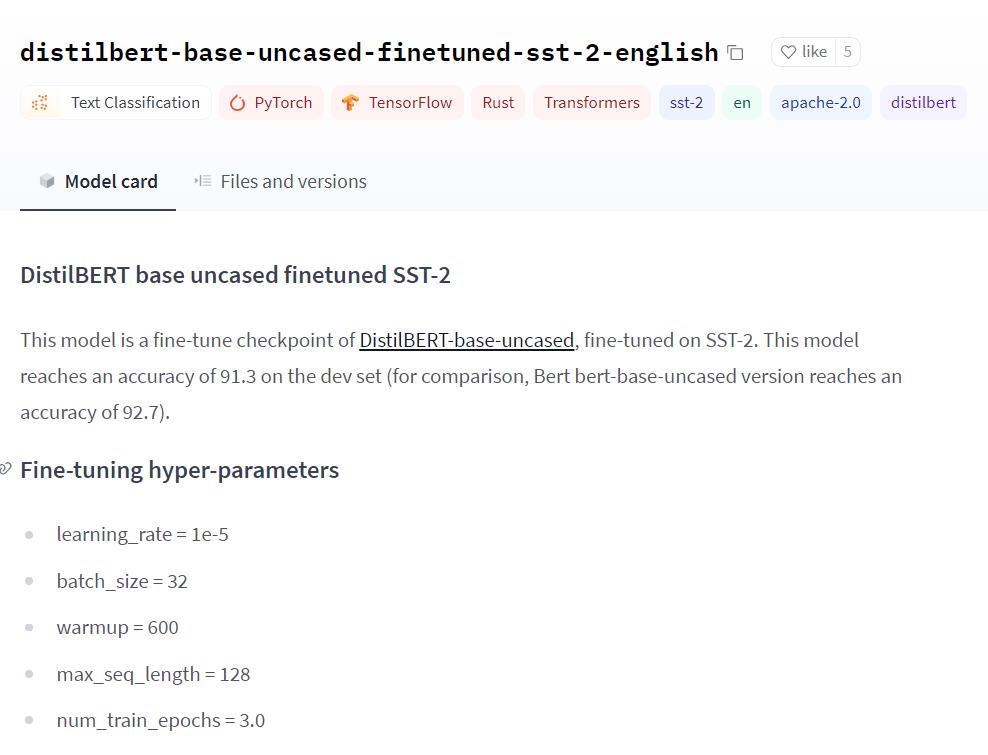
通过fine-tuning 更新 BERT 的参数权重, 可以提升DistilBERT 模型在句子分类任务(称为下游任务)上得到的分数。原教程中表示,通过对 DistilBERT 进行 fine-tuned 之后达到了 91.3 的准确率(模型见huggingface官网),全参数量的 BERT 模型能达到 92.7 的分数。
训练参数如下图所示:
接下来我们将数据集按照8:1:1切分为训练集,验证集和测试集。
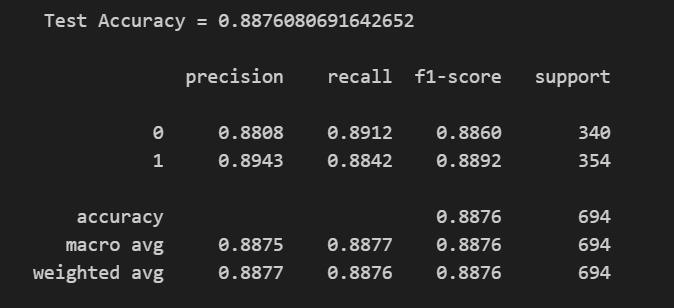
通过在训练集上的微调,模型在测试集上的准确度为0.8876,可能因为参数设置问题,没有达到原文中的效果。
代码见我的GitHub仓库:Comparison-of-Word-Vectors
7. 与常规的词向量对比
很多工作表明使用句子中所有词汇的Glove向量平均,比直接使用不经fine-tune的BERT [CLS]嵌入表现得更好。 为了验证这个观点,在数据集SST2上分别使用fastText,word2vec, Glove做词嵌入,再训练分类器,比较它们与BERT的效果。
代码见我的GitHub仓库:Comparison-of-Word-Vectors
7.1 fastText
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够在1分钟之内分类有着30万多类别的50多万句子。
- fastText在输入时对每个词加入了n-gram特征,在输出时使用分层softmax加速训练。
- fastText将整篇文章的词向量求平均作为输入得到文档向量,用文本分类做有监督训练,对输出进行softmax回归,词向量为副产品。
- fastText也可以无监督训练词向量,与CBOW非常相似。
fastText论文地址
fastText的github地址
使用fasttext预训练的英文词向量下载地址

这里我们使用的预训练词向量是上图中的1。
结果如下:
| 条件 | 准确度 |
|---|---|
| 直接使用预训练的fasttext词向量 | 0.7951 |
| 使用预训练的fasttext词向量并用训练集微调 | 0.7847 |
| 只使用训练集训练 | 0.7899 |
总体来说,效果比不进行微调的BERT差了不少,但是我们选用的fasttext词向量维数为300,比DistilBERT产生的768维的词向量小了不少。
参考资料:
https://blog.csdn.net/ymaini/article/details/81489599
https://blog.csdn.net/sinat_26917383/article/details/83041424
7.2 word2vec
使用word2vec预训练的英文词向量下载地址
word2vec说明文档
gensim文档
关于word2vec的原理,可见我的这篇博客:NLP方向组会内容整理(1)词向量
结果如下:
| 条件 | 准确度 |
|---|---|
| 直接使用google提供预训练的word2vec词向量 | 0.7917 |
| 只使用训练集训练 | 0.6685 |
可以发现,使用预训练词向量的准确度和fasttext相差无几。同时,由于word2vec不具备fasttext的识别OOV词的能力,在较少数据集上训练出的词向量效果不佳。
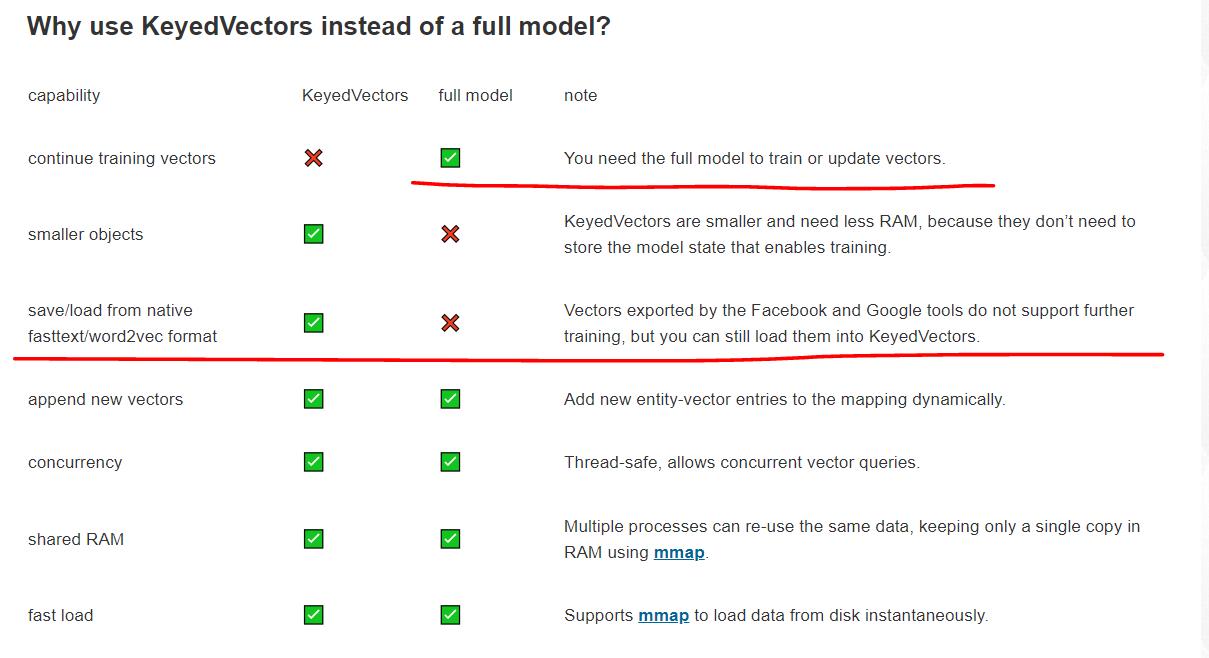
笔者未能实现在预训练词向量的基础上使用训练集继续训练,根据gensim3.8的文档,Google提供的预训练词向量,只能以KeyedVectors形式读取,不支持继续训练,只有完整的word2vec模型(model.word2vec.Word2Vec)才能继续训练。
7.3 Glove
Glove将Word2Vec原本预测一个词和它的语境是否会共现的任务,升级成预测两个词之间的共现频率大小的问题。
使用方法与word2vec类似,也是通过gensim使用,这里不再赘述。
7.4 总结对比
在本任务中,只是用预训练的DistilBERT模型做词嵌入的效果要好于预训练的fasttext和word2vec,也好于在训练集上微调过的fasttext。
7.5 更多词向量
https://github.com/Embedding/Chinese-Word-Vectors/blob/master/README_zh.md
https://ai.tencent.com/ailab/nlp/en/embedding.html
以上是关于BERT实战:使用DistilBERT作为词嵌入进行文本情感分类,与其它词向量(FastText,Word2vec,Glove)进行对比的主要内容,如果未能解决你的问题,请参考以下文章