原创使用Golang的电商搜索技术架构实现
Posted 黑夜路人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原创使用Golang的电商搜索技术架构实现相关的知识,希望对你有一定的参考价值。
作者:黑夜路人
时间:2022年11月
一、背景:
现在搜索技术已经是非常主流的应用技术,各种优秀的索引开源软件已经很普遍了,比如 Lucene/Solr/Elasticsearch 等等主流搜索索引开源软件,让我们搭建一个优秀的站内搜索引擎效率已经非常高了。
但是ES等只是解决了底层索引存储的问题,实际在具体要落地一个具备工程应用价值的搜索引擎,还是有很长的路要走,很多工程化的东西要去实现落地。
今天我们就基于电商的搜索场景,大概通过这些开源技术和一些基本的其他技术,如何搭建一个采用Golang为后端语言,完成具备落地实践性的搜索引擎工程实践。
电商网站大家都比较了解了,无论是某宝、拼夕夕、JD等等都是非常主流对大家日常生活影响很大的电商网站,基本从用户视角的使用流程链路,我们需要切换到技术工程师的视角去落地这类电商搜索引擎。
我们需要搭建的电商搜索引擎,需要具备能够快速找到用户需要的商品,还需要做一些营销考虑的扩展功能,所以我们定位的目标就是,完成一个基于电商场景的搜索引擎架构,能够达到:召回率高,时效性高,索引更新快 等目标。
二、搜索技术架构
搜索业务流程:
核心搜索业务流程:搜索入口 -> 搜索触发 -> 内容输入 -> 点击搜索 -> 反馈结果
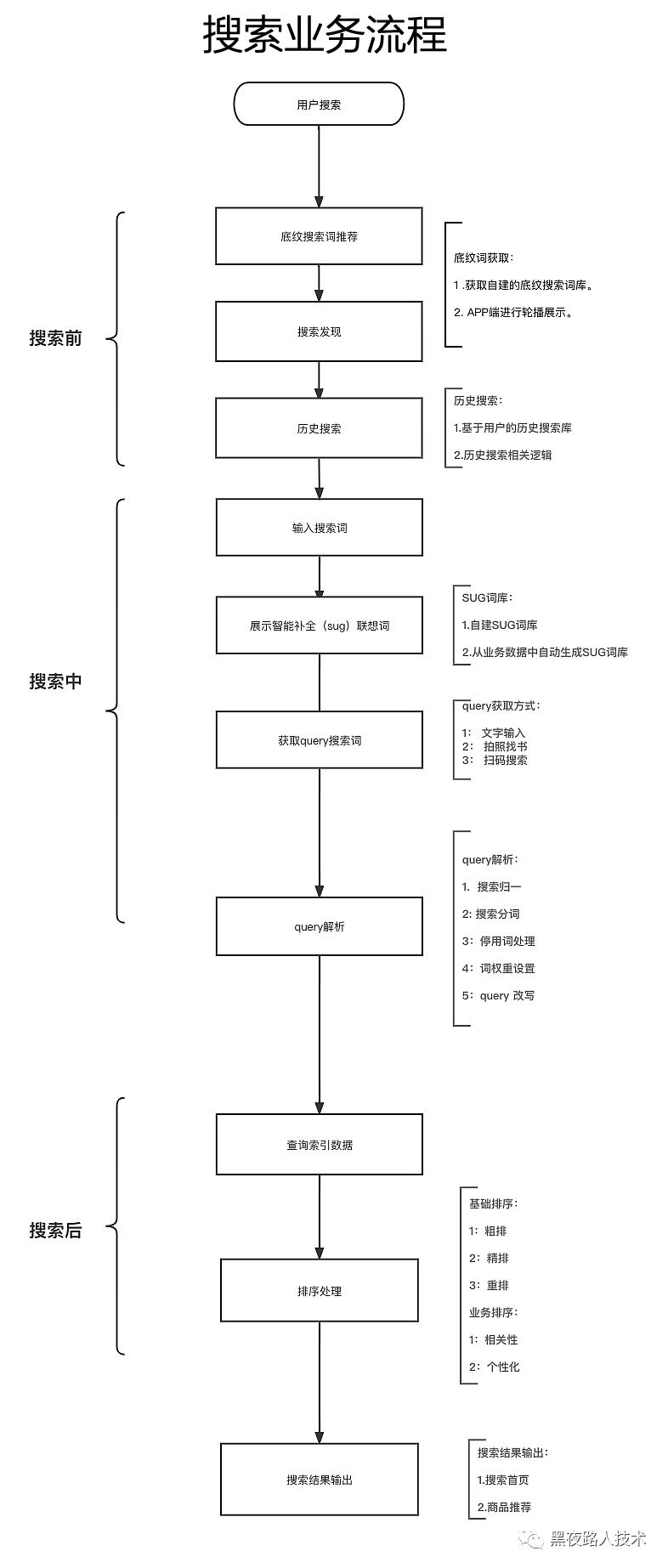
搜索基本技术架构:
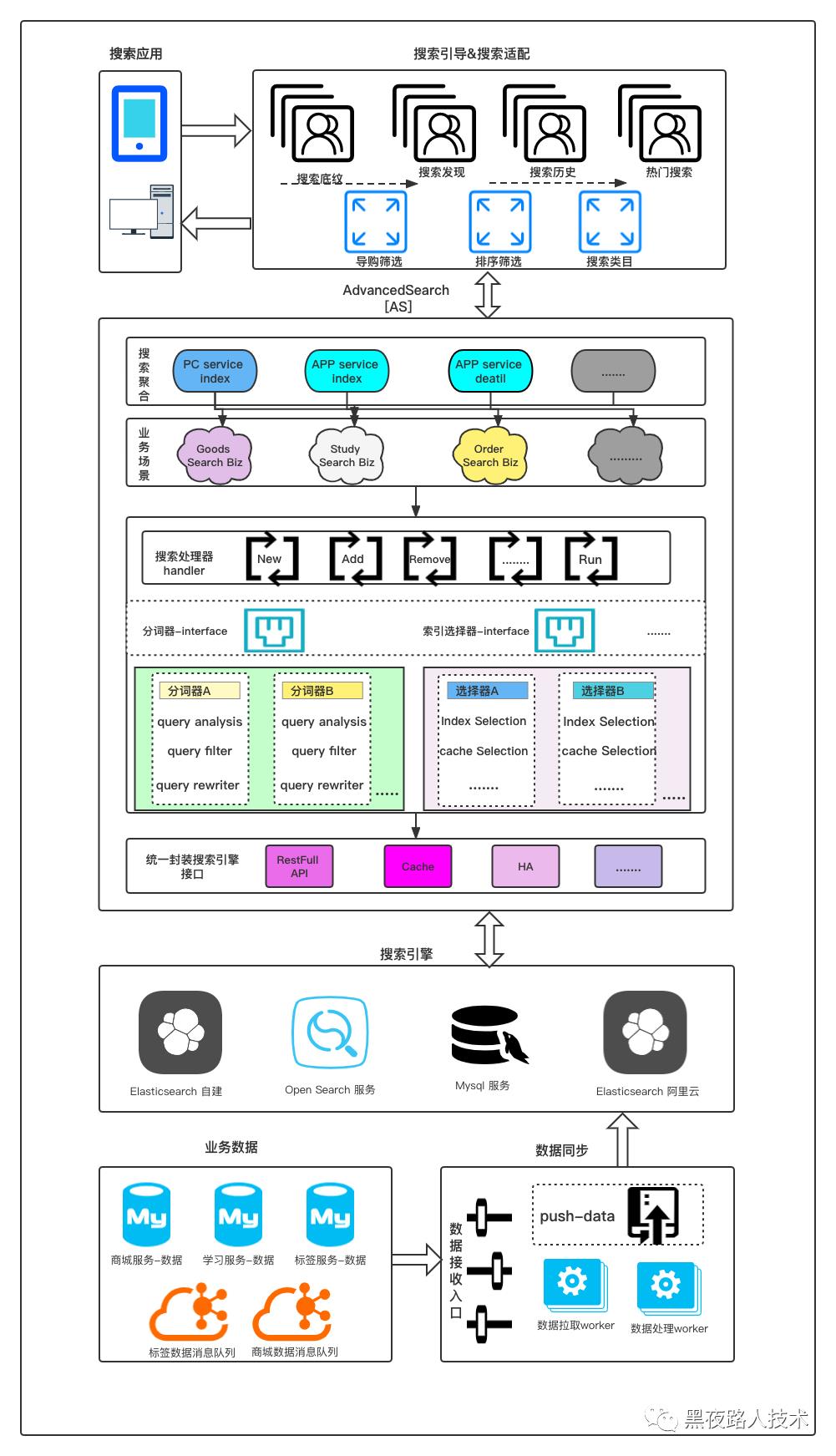
技术实现框架组件:
后端技术框架:Go + Golang技术框架 Kratos 框架进行后端服务开发
搜索索引存储:Elasticsearch(Opensearch)
中间缓存热数据:Redis
实体持久存储:mysql
消息交换MQ:Kafka
按照整个业务流程、从输入到输出链路,我们看看 输入数据(输入/灌数据、索引构建)、搜索前(搜索发现)、搜索中(查询处理、索引召回、排序)等环节把整个技术落地架构进行描述。
整个电商搜索各模块规划:
| 模块 | 数据来源 | 本期实现方式 | 未来扩展 |
| 搜索底纹 | 搜索自闭环 | 运营人员配置 | 通过自然语言处理进行搜索关键词提取。 |
| 历史搜索 | 搜索自闭环 | 记录用户搜索历史 | - |
| 热门搜索 | 搜索自闭环 | - | - |
| Query Process | 用户输入 | 开源分词插件 | 封装开源NLP定制化开发 |
| 搜索展示 | 搜索自闭环 | 基于业务逻辑展示规则实现 | - |
| 搜索引擎 | 外围服务 | ES/Opensearch | elasticsearch + 定制化分词插件 排序插件 |
三、搜索数据索引构建
索引构建主要是把原始内容(商品名等)变成一个倒排索引的过程,整个过程最关键包括:需要索引什么数据、数据分词、构建倒排索引。因为使用的是ES,所以最后构建倒排索引这个环节我们忽略,基本ES把整个环节过程解决了。
整个数据进入ES索引库中,总体的数据索引构建的主要技术架构:
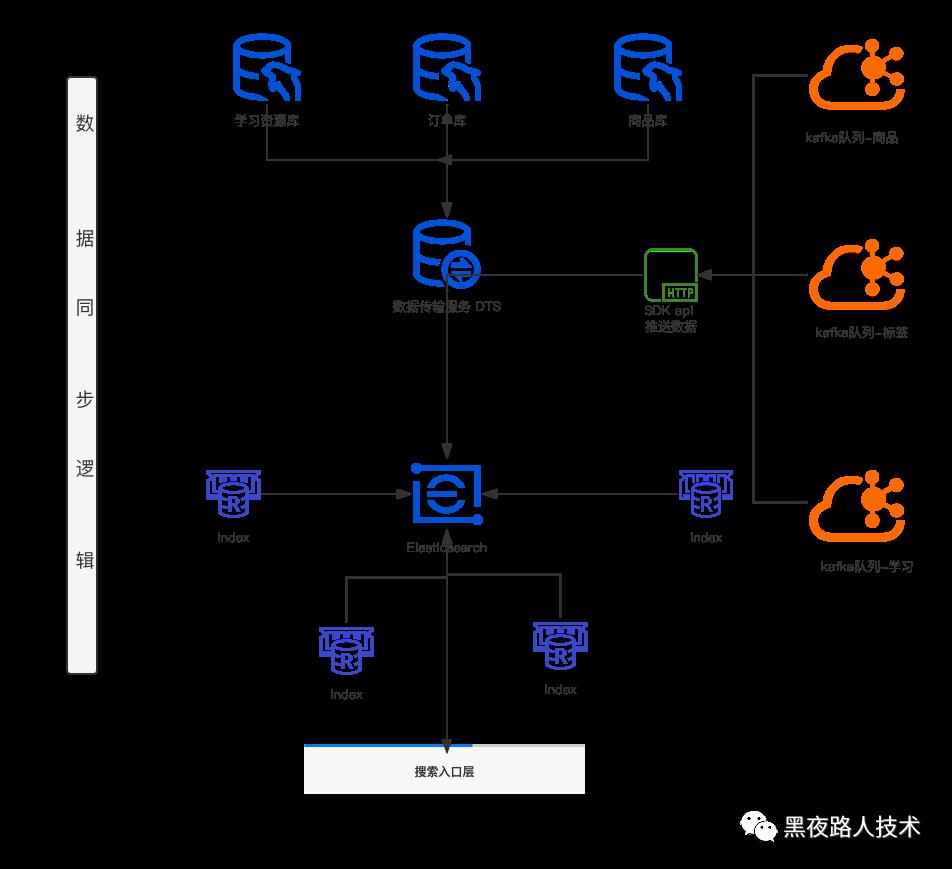
整个电商搜索,最核心的就是商品信息,我们每个上核心的就是商品类别、商品名称、上SKU/SPU 标识、商品的详情描述信息 等关键数据。
我们整个整个存储到ES索引中的核心数据主要设计如下:
商品索引 maping:
//商品整个JSON格式的索引结构
"mappings":
"properties":
"id": "type": "long" , // 自增ID,mspu_id
"spu_id": "type": "integer" , // 商品中心spu_id
"spu_unionid": "type": "keyword" , // 内部生成SPU唯一码
"spu_name": "type": "text" , // 名称
"mall_id": "type": "integer" , // 商城ID
"category_one": "type": "integer" , // 一级分类ID
"category_two": "type": "integer" , // 二级分类ID
"category_three": "type": "integer" , // 三级分类ID
"category_name": "type": "text" , // 分类名称
"head_picture": "type": "text", "index": false , // 头图
"video": "type": "text", "index": false , // 视频
"detail": "type": "text" , // 商品详情
"status": "type": "integer" , // 商品中心数据状态 1:有效 2:无效
"spu_status": "type": "integer" , // 商品中心spu状态 1:已创建 2:已创建待审核 3:已驳回待修改 4:已审核待上架 5:已上架待销售 6:销售中
"sale_status": "type": "integer" , // 商城上下架状态,上下架状态,是否1,上架,2,下架
"owner_id": "type": "integer" , // 所属货主 1:类型1 2:类型2
"product_type": "type": "integer" , // 商品类型 1:实物商品 2:虚拟商品 3:实物+虚拟商品
"pay_type": "type": "integer" , // 支付类型 1:线上支付
"sale_start_time": "type": "integer" , // 售卖开始时间-商城后台设置
"sale_end_time": "type": "integer" , // 售卖结束时间-商城后台设置
"entry_start_time": "type": "integer" , // 商品中心生效开始时间
"entry_end_time": "type": "integer" , // 商品中心生效结束时间
"spu_spec": "type": "text", "index": false , // SPU规格信息
"spu_spec_value_name": "type": "text" , // spu规格值
"spu_spec_value_id": "type": "integer" , // spu规格id
"stock_change_type": "type": "integer" , // 库存扣减类型 1:下单减库存 2:支付减库存
"logistics_mode": "type": "integer" , // 发货模式 1:使用物流发货
"refund_day7": "type": "integer" , // 是否支持7天无理由退款 1:支持 2:不支持
"after_sales_days": "type": "integer" , // 售后天数
"after_sales_times": "type": "integer" , // 售后次数
"delivery_time": "type": "integer" , // 发货时机(支付X小时内发货)单位:小时 默认:48
"sort_no": "type": "integer" , // 排序序号
"weight": "type": "integer" , // 排序权重
"is_home_sort": "type": "integer" , // 首页排序商品标示,1是,0否
"level": "type": "keyword" , // 商品级别:商品级别:S、A、B、C
"operator_workcode": "type": "keyword" , // 修改人ID
"operator_id": "type": "keyword" , // 修改人Name
"create_time": "type": "text" , // 创建日期
"update_time": "type": "text" , // 修改日期
"tags": "type": "text" , // 商品标签
"tag_ids": "type": "keyword" , // 商品标签id
"promotion_name": "type": "text" , // 营销名称
"promotion_id": "type": "keyword" // 营销id
存量数据处理:
一般同步依赖的索引数据包括:商品属性, 商品类目, 商品标签, 商品优惠活动, 商品评价维度, 商品评价标签, SPU信息 等等信息,这些信息都需要考虑比如说用脚本定期任务方式更新数据,如果是过去的存量数据,都需要批量通过脚本灌入到ES中完成索引构建工作。
增量数据索引处理:
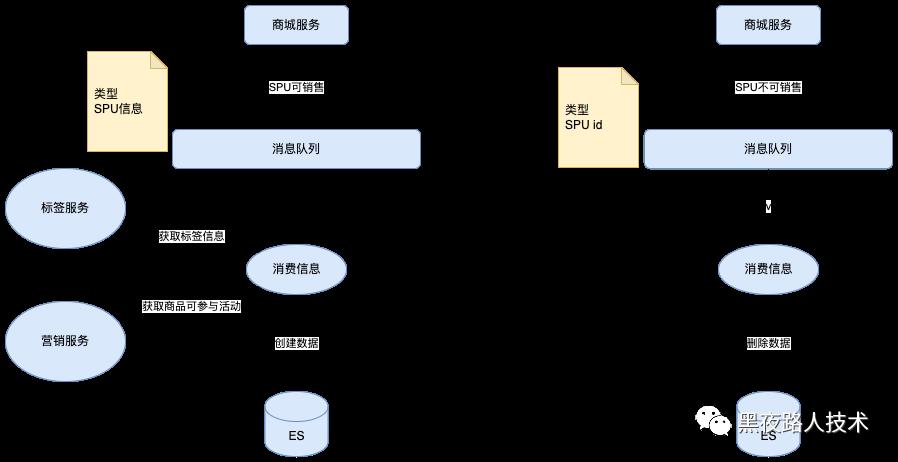
商品标签(标签、评价标签) 数据索引处理:
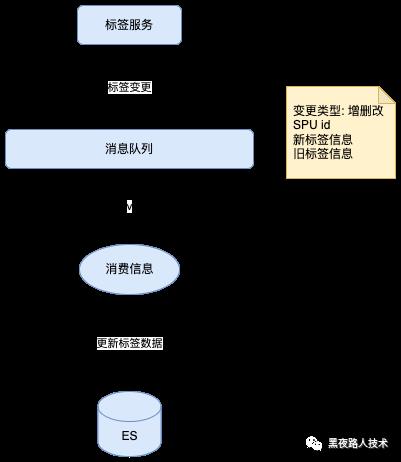
营销标签数据索引处理:
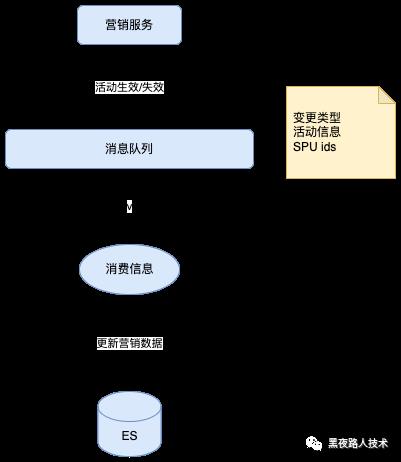
倒排索引的创建:
分词:使用分词器进行文档分词。
分词可以选择不同的规则:后期可以根据召回率来选择不同的分词器。
构建分词词典:把经过分词器处理的分词,创建一个全量分词词典库。
构建倒排链:构建词典跟文档的对应关系,创建一个倒排链。方便后续快速搜索出对应的文档。
针对词条的中文分词技术:
| 分词器名称 | 介绍 | 注意 | 举例 |
| 模糊分析器 | 支持拼音搜索、数字的前后缀搜索(中文不支持前后缀匹配搜索,字母,数字及拼音,这些都支持前后缀匹配)、单字或者单字母搜索。最多支持100个字节字段长度 | 仅适用于SHORT_TEXT短文本类型。 | 例如:文档字段内容为“菊花茶”,则搜索“菊花茶”、“菊花”、“茶”、“花茶”、“菊”、“花”、“菊茶”、“ju”、“juhua”、“juhuacha”、“j”、“jh”、“jhc”等情况下可以召回。例如:文档字段内容为手机号“138****5678”,则通过“^138”来搜索以“138”开头的手机号,通过“5678$”搜索以“5678”结尾的手机号。例如:文档字段内容为“OpenSearch”,则通过单个字母或者组合都可以检索到。 |
| 文本-自定义分析器 | 自定义干预词条 | 自定义分析器的词条是该分析器中分析器类型里的分析器的全部词条和手动添加的词条的总和,并且手动干预的词条优先级高于默认分析器的词条 新控制台自定义分析器的个数最多为20个; 单个自定义分词器最多能包含1000个干预词条; 每个词条中,key为不超过10个字符,value为不超过32个字符;1个字符为1个汉字或1个英文字母; 词条内容中不能包含大写字母(A-Z),全角符号(\\uff01 - \\uff5e),中文标点符号; | 例如:文档字段内容为“比特币”,可以自定义分词为”比“ ”特币" , 或者 ”比特币“ 或者”比特“ ”币“关键词搜索就可以召回 |
| 拼音全拼分析器 | 支持对短文本中的汉字,按照首字母和拼音全拼进行检索。适用于人名、电影名等需要简拼和全拼搜索的场景,而且全拼检索时必须输入汉字的全拼,不能只输部分。 | 仅适用于SHORT_TEXT短文本类型。 | 例如:文档字段内容为“大内密探007”,则搜索“d”、“dn”、“dnm”、“dnmt”、“dnmt007”、“da”、“danei”、“daneimi”、“daneimitan”等都可以召回。搜索“an”、“anei”等无法召回。 |
| 关键词分析器 | 不分词,适合一些需要精确匹配的场景。如标签、关键词等,不分词的字符串或数值内容。 | 该分析器适用于LITERAL、INT 字段类型。 | 例如:文档字段内容为“菊花茶”,则只有搜索“菊花茶”的情况下可以召回 |
| 中文-通用分析器 | 按照检索单元做分词,基于中文语义分词,适用于全网通用行业的分析器。属于行业分析类型。 | 该分析器适用于TEXT、SHORT_TEXT字段类型。 | 例如:文档字段内容为“菊花茶”,则搜索“菊花茶”、“菊花”、“茶”、“花茶”等情况下可以召回。 |
| 中文-电商分析器 | 适用于电商行业的分析器 | 该分析器适用于TEXT、SHORT_TEXT字段类型。 | 例如:文档字段内容为“大宝SOD蜜”,则搜索“大宝”、“sod”、“sod蜜”、“SOD蜜”、“蜜”等情况下均可以召回。 |
| 中文-单字分析器 | 按照单字/单词分词,适合非语义的中文搜索场景,如小说作者名称、店铺名等 | 该分析器适用于TEXT、SHORT_TEXT字段类型 | 例如:文档字段内容为“菊花茶”,则搜索“菊花茶”、“菊花”、“茶”、“花茶”、“菊”、“花”、“菊茶”等情况下可以召回。 |
目前兼容Lucene/ES可以用的分词器比较多,ES有内置的分词器,主要是很对英文场景,如果需要解决中文分词问题,可以自由选择很多开源分词器,目前中文分词内置使用比较多的是IK分词器,当然还有其他选择,包括 ik-analyzer、Jieba(结巴)、ansj_seg、jcseg、HanLP 等等,还有零零总总各种云厂商自己实现的分词器。
如果是在es下场景使用,可以按照自己的业务场景找合适的分词器以达到最好的分词效果,决定整个搜索效果质量,个人推荐 IK 或 Jieba 分词器,应用比较多,可以找到的资料也比较多。(一家之言)
四、前置搜索用户引导类技术设计
在用户准备进行物理实际商品搜索前,还会有很多基本的搜索相关服务,或者是搜索相关推荐类内容给予到用户侧,这些主要是用户引导类的动作,主要包括 搜索底纹、历史搜索、搜索发现等前置搜索场景。
“搜索底纹”:就是在搜索框中底下展示一些其他用户或者是推测用户想要搜索的关键词,方便用户不用自己输入,直接点击,或者是通过这种方式引导用户到某个想要推广的商品中,达到推广的目的。
“历史搜索”:就是记录用户过去搜索过什么词汇,方便用户重新快速点击历史词汇进行搜索,减轻输入词汇负担。
“搜索发现”:主要就是给用户推荐其他用户在搜什么,或者是推测用户喜好,或者同类用户喜好,给用户推荐一些搜索词或商品,达到流量分发的目的。
针对这些前置场景,整个技术流程和技术设计流程如下。
1. 搜索底纹:
通过自建搜索发现词库,轮播展示搜索发现词,进行底纹展示。
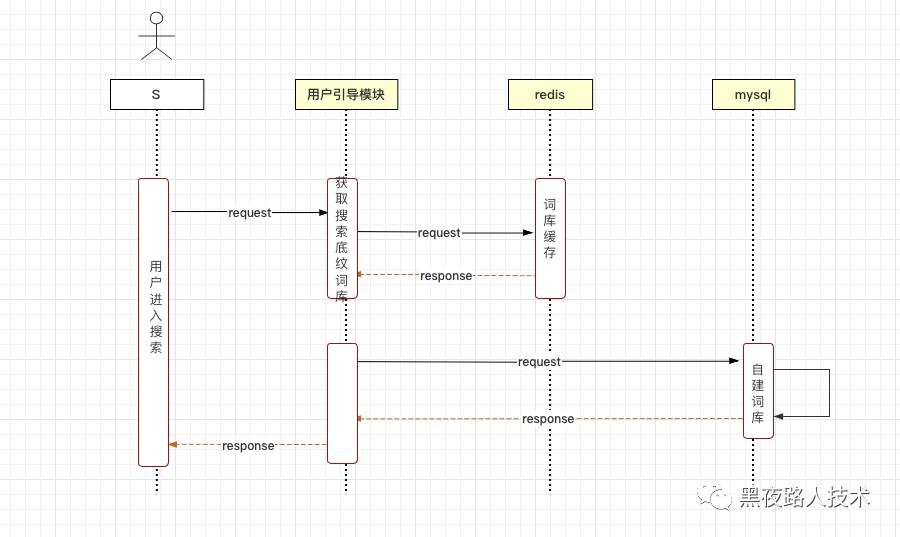
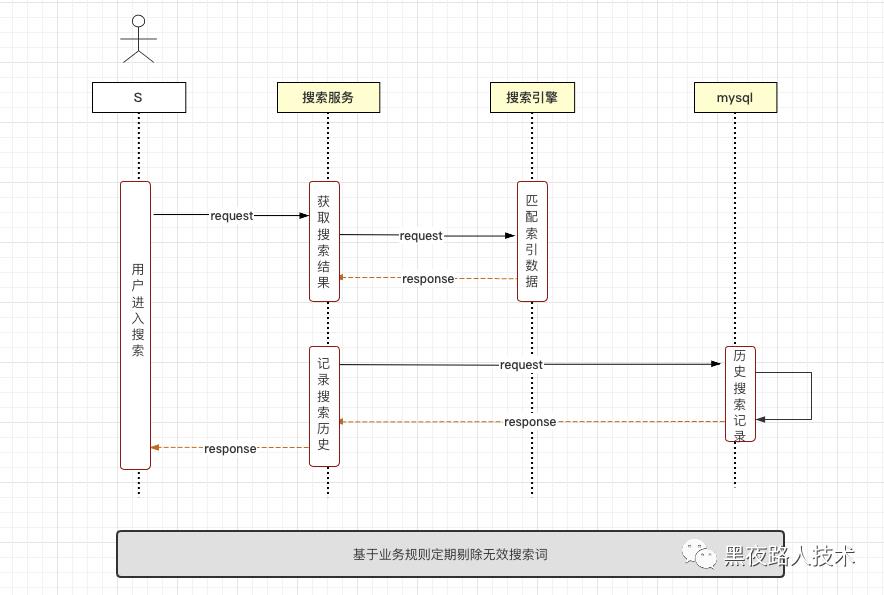
2. 历史搜索:
搜索接口服务记录用户历史搜索关键词,为后续搜索优化提供原始数据。
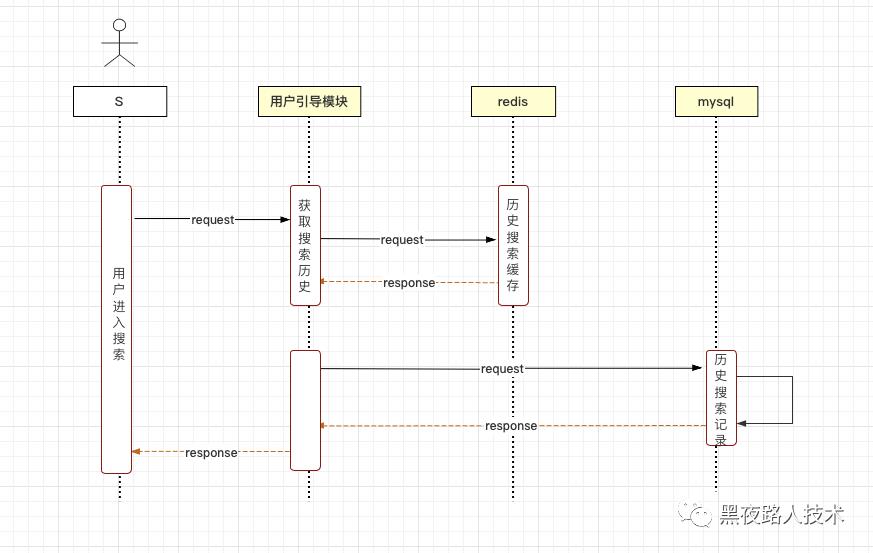
3. 搜索历史 - 数据更新:
搜索接口进行query分析的同时记录用户的搜索关键词,更新至搜索历史记录,定期按规则剔除无效搜索词。
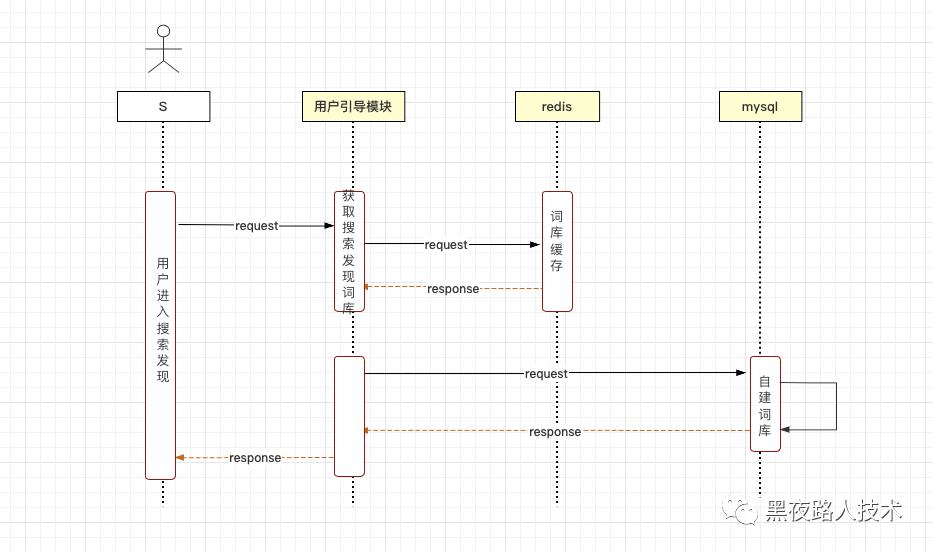
4. 搜索发现:
点击搜索发现词,实现推荐词搜索,通过自建搜索发现词库,获取对应用户所属分组的发现词。
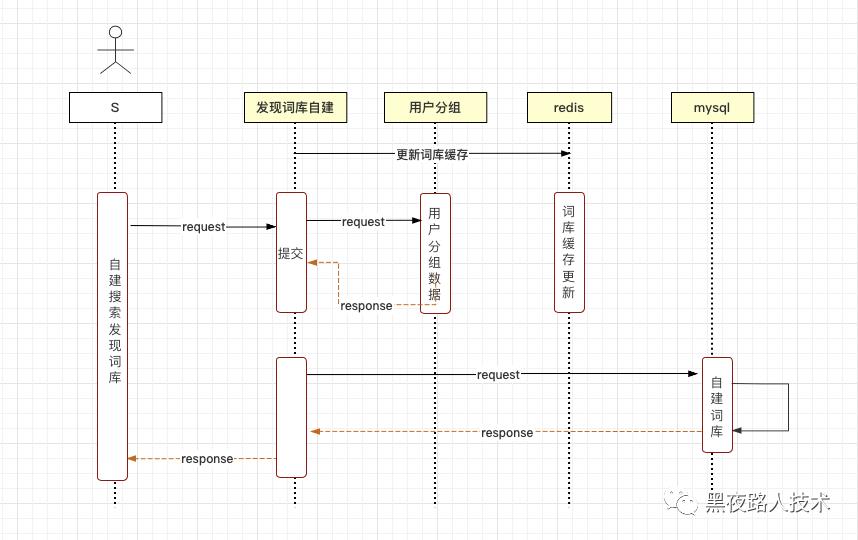
5. 搜索发现 - 词自建更新逻辑:
主要是针对搜索发现场景中的词汇建立和更新逻辑。
用户引导主要实现的是搜索前的业务逻辑,进行搜索提示,快速输出最终的query搜索词,进行索引搜索下发。
五、核心搜索服务的技术设计
1. 整个核心搜索服务架构
从索引构建到前置的用户搜索引导等动作后,就到了实际的关键词搜索的关键步骤中。整个搜索流程主要是包含 QP(查询词处理)、索引获取、索引排序、输出展现 等关键环节。这些环节,单一的ES是无法解决这个问题的,所以需要完成自己的整个前置搜索服务(AS)的设计考虑。
完整的搜索服务可以认为是 AS + ES + DB的架构,整个搜索服务的基本架构图:AS(自有Go搜索服务) -> ES -> DB 的整个层次结构
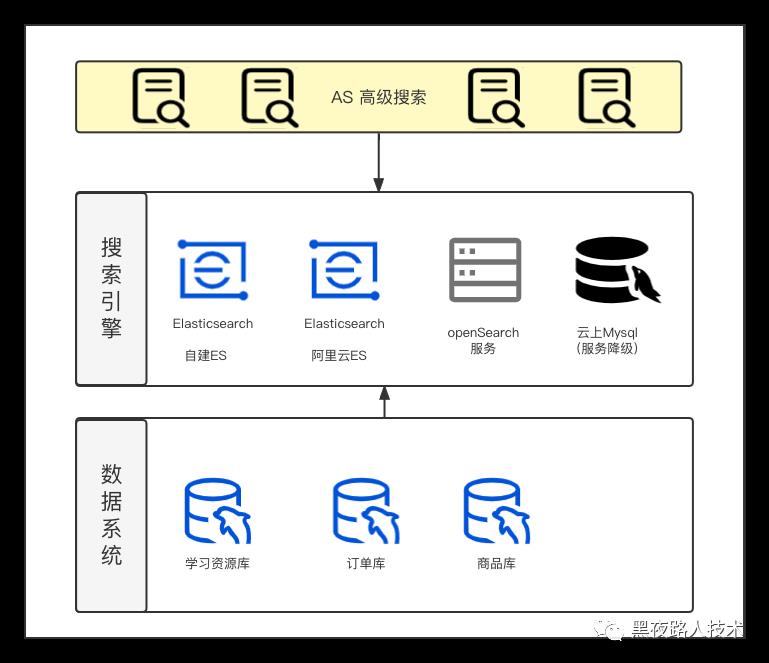
在整个从底到上的搜索服务整合以后,核心自有开发的整个搜索服务(AS)架构图如下:
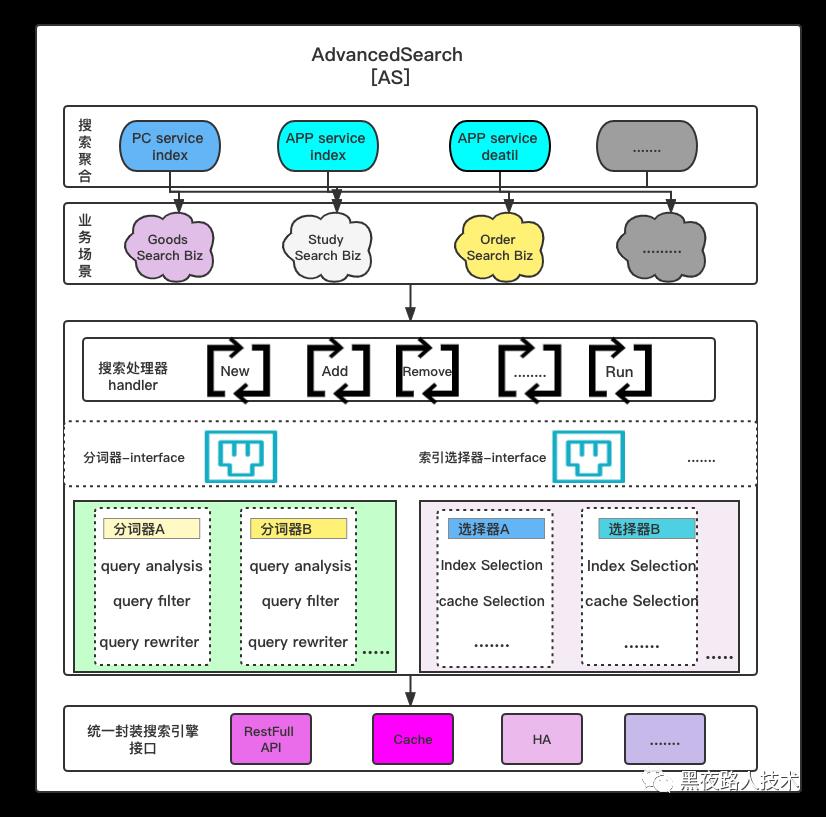
这个架构图可以看到,AS 一个主要的功能是通过一个个业务插件来代表相应的搜索。一个最简单的插件只需要包含对应的ES search API,它实际上就是一个配置项,说明es的地址。这样AS就是一个纯代理。
但是在商品搜索以及推荐需求都是不是ES本身能够支持的,所以就需要根据需求写相应的Query rewriter,rerank等算法插件。这样就实现了框架和业务分离,AS具有极强的扩展性和复用性。
上面家投入总体按照每个分层的描述:
搜索聚合层:提供搜索入口的统一接口,适配 PC搜索,APP搜索,H5搜索等
业务搜索层:管理不同的搜索业务 比如:商城搜索 内容搜索 工具搜索 等,为上层搜索聚合提供领域内搜索数据。
插件化计算层:提供插件化的相关性计算框架,提供丰富的相关性库,比如query分析库,query改写库,排序库,过滤库等,上游不同的搜索服务可以灵活选配插件。
反向代理层:基于底层搜索引擎的代理层,包括了:搜索分片,搜索引擎切换,搜索服务降级,底层数据存储切换,搜索数据缓存。代理层都实现了相同的接口比如:搜索数据,推送数据。
如果整个业务会有未来拍照搜索 语音搜索 扫码搜索 都可以在在AS层进行插件化扩展,充分利用三方图形识别能力等最终得到有效的query搜索词,进行索引下发。
2. QP(Query Processor 查询词处理,获取准确召回的核心入口动作)
上面说了,从索引构建到前置的用户搜索引导等动作后,就到了实际的关键词搜索的关键步骤中。整个搜索流程主要是包含 QP(查询词处理)、索引获取、索引排序、输出展现 等关键环节。
对于整个QP环节,是前置核心环节,为了达到核心的查询效果,能够获取更多相对准确的召回结果,所以QP环节是非常重要的。
QP主要包括这些需要进行的工作:
搜索归一:
读时:搜索引擎中对query查询,需要做归一化处理,以提高结果的召回率。字符串的归一化处理包括:繁体转简体,全角转半角,大写字母转小写。
写时:建联倒排时,会先对字符串做归一化处理,然后再分词取term,用户查询时,也会对查询串做同样的操作,这样就能找到对应的倒排链。
拼写纠错:
用户输入的query并不总是正确的,错误的输入可能导致查询结果不符合预期或者是无结果,因此需要对用户的输入进行拼写检查。
查询分析中提供的拼写检查功能,对查询词中的错误进行纠正,给出正确的查询词。并根据纠错的可信度高低,决定当前查询是否用纠错后的词进行查询。
搜索分词:
分词器:ES 中处理分词的部分被称作分词器,分词器决定了分词的规则。ES 自带了很多默认的分词器,比如Standard、 Keyword、Whitespace等,默认是 Standard。
当我们在读时或者写时分词时可以指定要使用的分词器。对query进行分词可以更有效的命中倒排索引,对应的文档就可以被召回。
词权重:
主要分析了查询中每一个词在文本中的重要程度,并将其量化成权重,权重较低的词可能不会参与召回。这样可以避免当用户输入的查询词中包含一些权重低的词时,仍然按用户输入的查询词限制召回,导致命中结果过少。
停用词:
通过开源停用词库以及自己维护停用词表的方式来判断停用词,去掉在搜索中无任何意义的词。比如:中文 ”的“ ”在“, 英文中的 ”a“ "an" ,所以在处理query词的时候
需要去掉停用词,同样在分词构建索引的时候也会去掉停用词,减少不必要的索引空间。
query改写:
通过上述操作进行query改写,获得最终的改写结果,进行搜索下发。
具体QP示例:
//以杨幂同款耐克修身连衣群包邮.的查询词为例,不配置查询分析前的Query如下:
query=(default:'杨幂' AND default:'同款' AND default:'耐克' AND default:'修身' AND default:'连' AND default:'衣' AND default:'群' AND default:'包邮' AND default:'.')
//配置停用词后实际系统查询词为:
query=(default:'杨幂' AND default:'同款' AND default:'耐克' AND default:'修身' AND default:'连' AND default:'衣' AND default:'群' AND default:'包邮')
//说明:此处停用词将查询词中的标点过滤掉了。
//再添加拼写纠错后实际系统查询词为:
query=(default:'杨幂' AND default:'同款' AND default:'耐克' AND default:'修身' AND default:'连衣裙' AND default:'包邮')
//说明:此处拼写纠错将查询词中的错误输入“连衣群”纠正了。
//再添加词权重后实际系统查询词为:
query1=(default:'杨幂' AND default:'同款' AND default:'耐克' AND default:'修身' AND default:'连衣裙' RANK default:'包邮')
query2=(default:'杨幂' RANK default:'修身' RANK default:'包邮' RANK default:'同款' RANK default:'耐克' RANK default:'连衣裙')
//说明:此处配置词权重后,权重较低的词“包邮”不参与召回。且当Query1无结果时,引擎会自动触发重查(re_search),按Query2召回结果,以避免无结果召回。
//再添加同义词后实际系统查询词为:
query1=(default:'杨幂' AND default:'同款' AND ((default:'耐克') OR (default:'nike')) AND default:'修身' AND default:'连衣裙' RANK default:'包邮')
query2=(default:'杨幂' RANK ((default:'耐克') OR (default:'nike')) RANK default:'修身' RANK default:'包邮' RANK default:'同款' RANK default:'连衣裙')
//说明:此处配置同义词后,将“nike”添加为了“耐克”的同义词。且当Query1无结果时,引擎会自动触发重查(re_search),按Query2召回结果,以避免无结果召回。在QP中关于搜索分词部分内容,可以参考上面“搜索索引构建”内容中分词的一些基本技术参考。
3. 搜索结果排序
我们通过QP把关键字丢给了ES等服务按照某些策略,比如 BM25 等排序算法获取了一些倒排索引中的数据,然后这些数据可能不能满足最终前台显示的搜索结果数据,就需要我们针对整个搜索结果数据进行非常有效的排序。
整个排序过程,可以理解为是一个“漏斗式架构”,就是把检索的数据一层层过滤后,最终输出到前端显示:
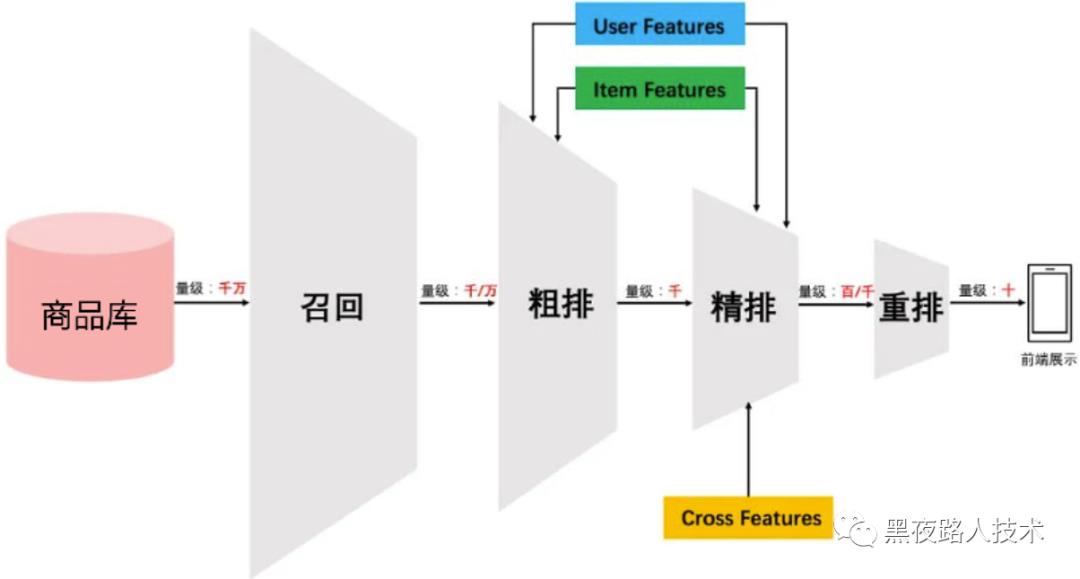
数据排序 - 粗排:
粗排阶段的目标是从大量的候选商品中筛选出合规 相关且成交率高的商品。对搜索结果进行第一轮的海选,按照表达式对文档进行算分,并按照算分结果进行排序。
数据排序 - 精排:
精排阶段的目标是在粗排的基础上,基于用户的行为特征,对搜索结果进行第一轮的海选,按照表达式对文档进行算分,并按照算分结果进行排序。
4. 搜索结果展示
通过以上的层层环节处理,最终我们获取的排序后的搜索结果给前台进行搜索结果显示,完成整个关键环节。整个展现层的业务技术架构设计大概如下:
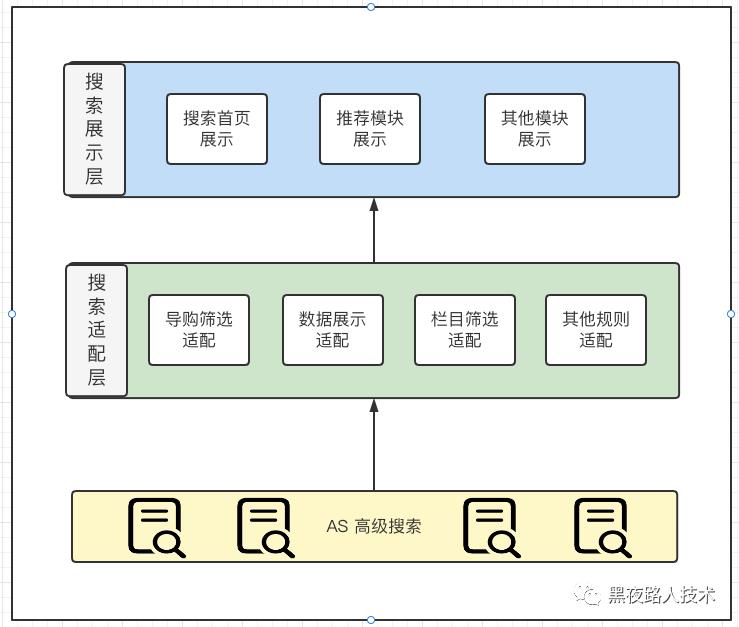
导购筛选:通过搜索结果重新组织导购筛选导购。
数据展示:通过搜索结果重新组织各种搜索场景下需要展示的数据。增加删除相关信息。
类目筛选:通过搜索结果重新组织导购筛选类目。
六、收尾
本文不是展现搜索引擎的内部技术,搜索引擎内部技术大家可以搜索参考我之前写的一个技术文章《黑夜路人:全文搜索引擎技术原理入门》,了解更基本的原理。
本文主要是在现有 ES 等良好开源软件基础上,如果在类似于电商这样的业务场景下面,在类似于使用Golang这种开发语言,去通过工程化方式,设计架构开发一个可靠解决各种业务场景问题的电商搜索引擎,整个是一个搜索引擎工程技术设计的思路。
其实如果需要延展,比如做商品的“以图搜图”,或者是做“推荐”功能,按照用户兴趣或购买习惯推荐更多好商品,或者按照类似商品,推荐其他商品,那么整个技术架构还需要升级成为下面这样的升级机器学习的“搜索+推荐”的引擎技术架构:
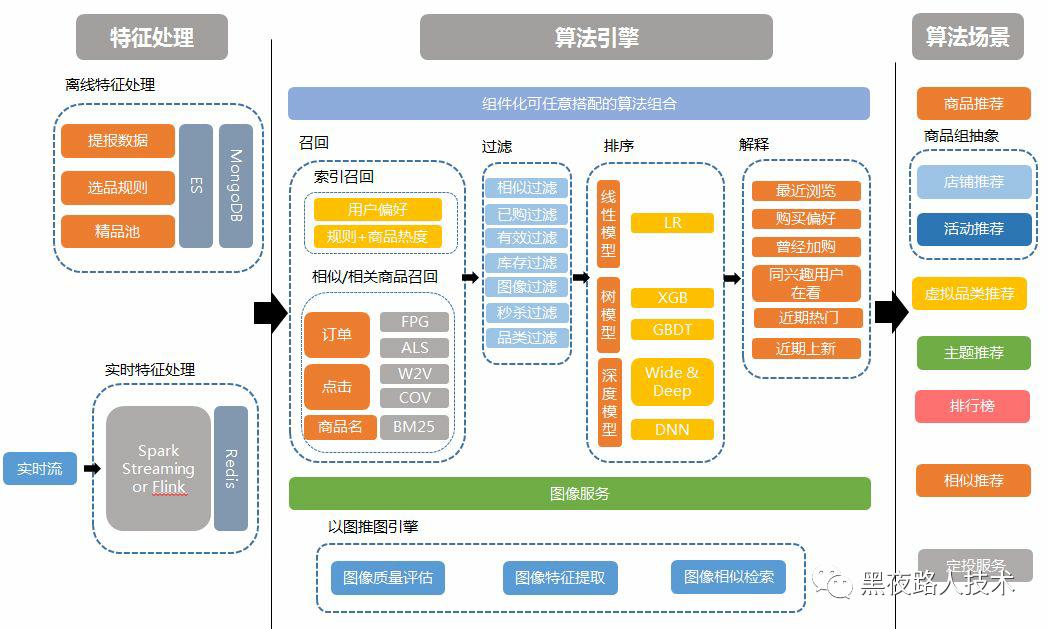
需要变成如上的技术架构,还需要更多工作,主要是需要进行很多工程化机器学习的工作,这个也是未来下一步可以继续延展的。
希望学习完本文,你能够在现有 ES 等良好索引存储开源软件基础上,如何在类似于电商这样的业务场景下面,去通过工程化方式,设计架构开发一个可靠解决各种业务场景问题的电商搜索引擎。
## End ##
----------
想关注更多技术信息,可以关注"黑夜路人技术” 公众号,一起学习进步

以上是关于原创使用Golang的电商搜索技术架构实现的主要内容,如果未能解决你的问题,请参考以下文章