02. Redis 数据类型
Posted IT BOY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02. Redis 数据类型相关的知识,希望对你有一定的参考价值。
目录
04 Redis 数据类型
Pt1 STRING
String是Redis最常用的数据类型,Redis基于String的操作都是二进制安全的,我们具体分析Redis的String数据类型。
Pt1.1 存储类型
String类型可以存放三种数据类型:
-
INT(整数)
-
FLOAT(单精度浮点型)
-
String(字符串)
Pt1.2 操作命令
## String-操作命令
set mvp steveNash # 设置字符串值
getrange mvp 0 2 # 获取字符串值指定范围的字符
strlen mvp # 获取值的长度
append mvp Twice # 字符串追加内容
setnx champion kobe # 设置值,如果key存在,则返回失败,不存在则成功(分布式锁)
del champion # 删除key为champion的数据,也可以释放分布式锁
mset spurs 96 lakers 92 # 设置多个值(批量操作,原子性)
mget spurs lakers # 获取多个值
incr spurs # (整数)值递增(值不存在时从0增长到1)
incrby lakers 3 # (整数)值递增
decr spurs # (整数)值递减
decrby spurs 2 # (整数)值递减
set score 92.6 # 浮点数
incrbyfloat score 7.3 # 性点数增量
set key value [expiration EX seconds|PX milliseconds][NX|XX] # 过期时间Pt1.3 实现原理
先来看一个示例:
127.0.0.1:6379[1]> set name lucas
OK
127.0.0.1:6379[1]> type name
string
127.0.0.1:6379[1]> object encoding name
"embstr"Key为name的数据,对外表现为string类型,但是还有一个embstr类型的编码类型,为什么要这么设计呢,我们来看看Redis的内部实现。
(1)C语言数组的弊端
Redis是基于C语言来实现的,但是C语言本身没有字符串类型,只能用字符数组char[]来实现,但是字符数组在操作上有以下弊端:
-
使用字符数组必须提前给目标变量分配足够的内存空间,否则可能会溢出;
-
如果要获取string长度,必须遍历数组,时间复杂度是O(n),性能差;
-
C语言中字符串长度变更会对字符数组做内存重新分配,性能会下降;
-
C语言通过从字符串开始到结尾碰到的第一个'\\0'来标记字符串的结束,当存储图片、压缩文件、音视频等二进制数据时,不能保证二进制安全;
(2)Simple Dynamic String
char[]存储的弊端这么多,肯定是不能用了,否则Redis也不会有这么出众的性能。Redis实现了一种叫简单动态字符串(Simple Dynamic String,简称SDS)的数据类型类存储string值,当然SDS本质上是通过C语言的char[]实现。
我们来看源码实现:
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
;
struct __attribute__ ((__packed__)) sdshdr8
uint8_t len; /* 当前字符数组的长度 */
uint8_t alloc; /* 当前字符数组总共分配的内存大小 */
unsigned char flags; /* 低3个bit用来表示header的类型。header的类型共有5种,在sds.h中有常量定义。 */
char buf[]; /* 存放字符串真正的数据 */
;
struct __attribute__ ((__packed__)) sdshdr16
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
;
struct __attribute__ ((__packed__)) sdshdr32
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
;
struct __attribute__ ((__packed__)) sdshdr64
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
;从源码可以看到,SDS有5种类型的结构,sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,用来存储不同长度的字符串,分别可以存储2^5=32byte,2^8=256byte,2^16=65536byte=64K,2^32byte=4GB。
(3)SDS的优势
SDS相对比char[]有如下优势:
-
不用担心内存溢出问题,如果需要会对SDS进行扩容;
-
定义了len属性,获取字符串长度的时间复杂度为O(1);
-
通过“空间预分配”和“惰性空间释放”,防止多次重分配内存;
-
根据len长度读取数据,二进制安全;
什么是空间预分配?
空间预分配用于优化 SDS 的字符串增长操作: 当 SDS 的 API 对一个 SDS 进行修改, 并且需要对 SDS 进行空间扩展的时候, 程序不仅会为 SDS 分配修改所必须要的空间, 还会为 SDS 分配额外的未使用空间。
其中, 额外分配的未使用空间数量由以下公式决定:
-
如果对 SDS 进行修改之后, SDS 的长度(也即是 len 属性的值)将小于 1 MB , 那么程序分配和 len 属性同样大小的未使用空间, 这时 SDS len 属性的值将和 free 属性的值相同。 举个例子, 如果进行修改之后, SDS 的 len 将变成 13 字节, 那么程序也会分配13 字节的未使用空间, SDS 的 buf 数组的实际长度将变成 13 + 13 + 1 = 27 字节(额外的一字节用于保存空字符)。
-
如果对 SDS 进行修改之后, SDS 的长度将大于等于 1 MB , 那么程序会分配 1 MB 的未使用空间。 举个例子, 如果进行修改之后, SDS 的 len 将变成 30 MB , 那么程序会分配 1 MB 的未使用空间, SDS 的 buf 数组的实际长度将为 30 MB + 1 MB + 1 byte 。
通过空间预分配策略, Redis 可以减少连续执行字符串增长操作所需的内存重分配次数。
什么是惰性空间释放?
惰性空间释放用于优化 SDS 的字符串缩短操作:当 SDS 的 API 需要缩短 SDS 保存的字符串时,程序并不立即使用内存重分配来回收缩短后多出来的字节,而是使用 free 属性将这些字节的数量记录起来,并等待将来使用。这样做的原因是释放内存空间也需要性能消耗,并且下次可能还会对字符串进行扩容操作。尽管如此,Redis也提供了相应的API对惰性空间进行释放。
(4)KV存储结构
是不是KV值都是以SDS来存储的呢?这么一问,肯定知道没这么简单,大佬的设计确实是牛逼的。
string类型存储式,key值(肯定是字符串)是使用SDS来存储的,但是value值却不是,value值是存储在redisObject的数据结构中,我们来看具体源码实现:
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define LRU_BITS 24
typedef struct redisObject
unsigned type:4; /* 对象的类型,包括OBJ_STRING, OBJ_LIST, OBJ_SET, OBJ_ZSET, OBJ_HASH */
unsigned encoding:4; /* 具体的数据结构,定义如上面的常量,在string中主要涉及raw,embstr和int三种 */
unsigned lru:LRU_BITS; /* 24bit,对象最后一次被应用程序访问的时间,与垃圾回收操作相关 */
int refcount; /* 引用计数,为0的时候表示对象已经不被任何其他对象引用,可以执行垃圾回收*/
void *ptr; /* 指向对象实际的数据结构 */
robj;所以当value存储一个string的时候,Redis并没有直接使用SDS存储,而是存储在RedisObject中,5种常用的数据类型的value都是通过redisObject来存储的,redisObject中通过指针指向实际存放数据的SDS,如下图所示。
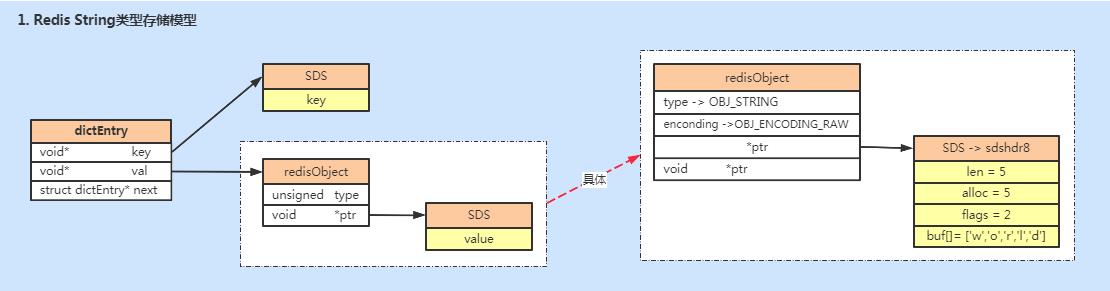
redisObject和sds的设计,是为了根据存储的不同内容选择不同的存储方式,已达到尽可能节省内存空间和提升查询速度的目标。
(5)内部编码
除了redisObject和SDS的设计,Redis还提供了内部编码的属性,也就是redisObject.encoding。在string类型中encoding主要有3种:
-
int,存储8个字节的长整型(long, 2^63 - 1);
-
embstr,代表embstr格式的sds,存储小于44个字节的string;
-
raw,存储大于44个字节的string;
# 源码object.c中定义
# define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
# 代码示例
127.0.0.1:6379> set str1 1
OK
127.0.0.1:6379> set str3 "12345678901234567890123456789012345678901234"
OK
127.0.0.1:6379> set str4 "123456789012345678901234567890123456789012345"
OK
127.0.0.1:6379> type str1
string
127.0.0.1:6379> type str3
string
127.0.0.1:6379> type str4
string
127.0.0.1:6379> object encoding str1
"int"
127.0.0.1:6379> object encoding str3
"embstr"
127.0.0.1:6379> object encoding str4
"raw"int编码类型不同,容易理解,那embstr和raw有什么区别呢?先看下图。
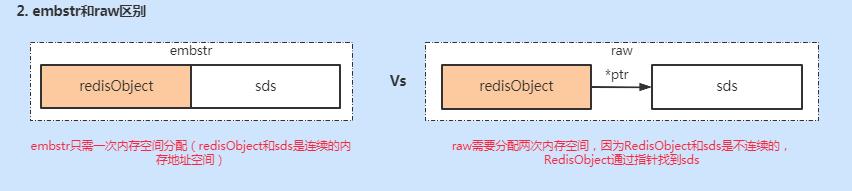
embstr只需要分配一次内存空间,因为RedisObject和sds是连续的。而raw则不同,因为RedisObject是通过指针找到sds,二者在空间分配上不连续,所以需要两次内存空间的分配。所以raw相比embstr,在创建是多分配一次内存空间,删除时多释放一次内存空间,查找时对象不在一起需要多一次内存查找,整体上性能embstr更好。
不过,raw相比embstr来说,因为通过指针关联,string长度增加需要重新分配内存时,只需要重新分配sds的内存,然后变更RedisObject指针即可。但是embstr则不行,string长度增加需要重新分配内存时,整个RedisObject和sds都需要重新分配内存空间。所以embstr的实现更适合只读类型的数据。
在下面的场景中,int和embstr会转化为raw(过程均不可逆):
-
int数据不再是整数,将转换为raw;
-
int大小超过了long的范围(2^63 - 1),将转换为embstr;
-
embstr长度超过44字节,将转换为raw;
-
embstr对象发生修改(使用append等命令修改原值,如果使用set重新设值则不会发生改变),将转换为raw;
127.0.0.1:6379> set key1 1
OK
127.0.0.1:6379> set key2 9223372036854775807
OK
127.0.0.1:6379> set key3 9223372036854775808
OK
127.0.0.1:6379> set key4 abc
OK
127.0.0.1:6379> set key4 abcd
OK
127.0.0.1:6379> append key1 a
(integer) 2
127.0.0.1:6379> object encoding key1
"raw"
127.0.0.1:6379> object encoding key2
"int"
127.0.0.1:6379> object encoding key3
"embstr"
127.0.0.1:6379> object encoding key4
"embstr"
127.0.0.1:6379> append key4 e
(integer) 5
127.0.0.1:6379> object encoding key4
"raw"变更导致编码转换在redis写入数据时完成,且转换过程不可逆,只能从小内存编码向大内存编码转换(不包括使用set重新设值)。
Pt1.4 应用场景
(1)数据缓存
string类型可以缓存热点数据,比如字典数据,热点访问数据等,可以显著提升热点数据的访问速度,如果是持久化的数据,也可以降低后端数据库的性能压力。
(2)分布式数据共享
分布式应用多个节点通常会面临数据共享的问题,最常见的就是访问session共享的问题,应用节点本地数据可能会存在数据一致性问题,使用Redis这种第三方独立服务,可以在多个应用、或者应用的多个节点之间共享数据,并且保证数据的一致性。
(3)分布式锁
Redis在操作string的setnx方法时,只有数据不存在才会返回成功,这个功能通常会被用作分布式锁的实现。
(4)全局ID
INT类型的incr/incrby操作是原子性的,可以用来实现全局自增ID。使用incrby可以一次性拿一段数据来提升性能,类似数据库sequence的cache。
(5)计数器
同样适用INT类型的INCR操作,可以实现计数器的功能,比如统计文章的阅读量,点赞数,先写入redis再同步到数据库。
(6)限流
使用INT类型的incr方法,比如基于IP和功能id信息作为key,每访问一次增加一次技术,超过次数返回false。这些都是利用Redis的相关特性和存储结构,来实现业务上的逻辑判断。
Pt2 HASH
Pt2.1 存储类型
Hash用来存储多个无序的键值对,最大存储数量2^32 - 1(40亿左右)。如下所示的结构:
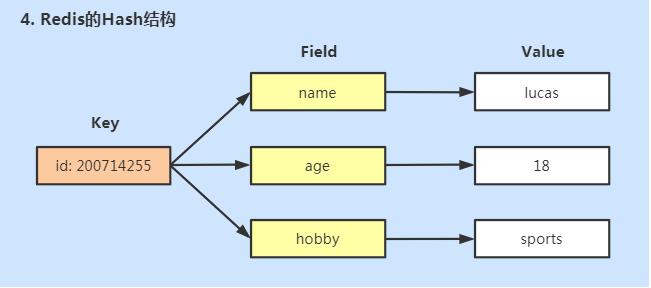
前面介绍了dictht是Redis哈希表的实现,这是外层哈希,可以存放KV键值对dictEntry。这里的Hash是键值对中保存哈希表,属于内层Hash。这个篇幅下,我们讲的哈希都是指内层哈希结构。
Hash的value只能存放字符串类型,不能再嵌套其它复杂类型。同样是存储字符串,Hash和String有什么区别呢?
-
把所有相关的值聚集到一个key中,结构清晰,节省内存空间;
-
减少KEY的数量,减少KEY冲突;
-
使用单个命令可以批量获取数据,减少内存/IO/CPU的消耗;
以下场景Hash不适用:
-
Field不能单独设置过期时间,只能放在KEY这个层级;
Pt2.2 操作命令
hset h1 f 6 # 设置数据 key:field:value
hmset h1 a 1 b 2 c 3 d 4 # 设置多组数据 key:field1:value1:field2:value2:field3:value3...
hget h1 a # 获取数据 key:field
hmget h1 a b c d # 获取多组数据 key:field1:field2:field3
hkeys h1 # 获取key的全部fields
hvals h1 # 获取key的全部values
hgetall h1 # 获取key的全部field和value
hdel h1 a # 删除key的对应field数据
hlen h1 # key的KV个数
del h1 # 删除key的全部数据Pt2.3 实现原理
在string我们提到过,5种基本数据类型的value都是存放的redisObject,然后RedisObject保存了指向实际数据的指针,所以实现了对外一种数据类型,对内3中编码的设计。Hash也是一样的,hash也有两种数据结构实现:
-
ziplist:OBJ_ENCODING_ZIPLIST(压缩表)
-
hashtable:OBJ_ENCODING_HT(哈希表)
(1) ziplist
ziplist在Redis5种常用数据结构中使用最为广泛,包括后面的LIST、ZET、ZSET都用到或者用过ziplist来实现其数据结构,我们重点看下ziplist的数据结构。
ziplist存储结构如下所示:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>ziplist是一个经过特殊编码,由连续内存块组成的双向链表。但是呢,它不存储指向前后链表节点的指针,而是存储上一个节点长度和当前节点的长度,在读写的时候通常计算长度来找到位置。通过时间换空间,虽然计算长度会损耗一些性能,但是可以节省内存空间。
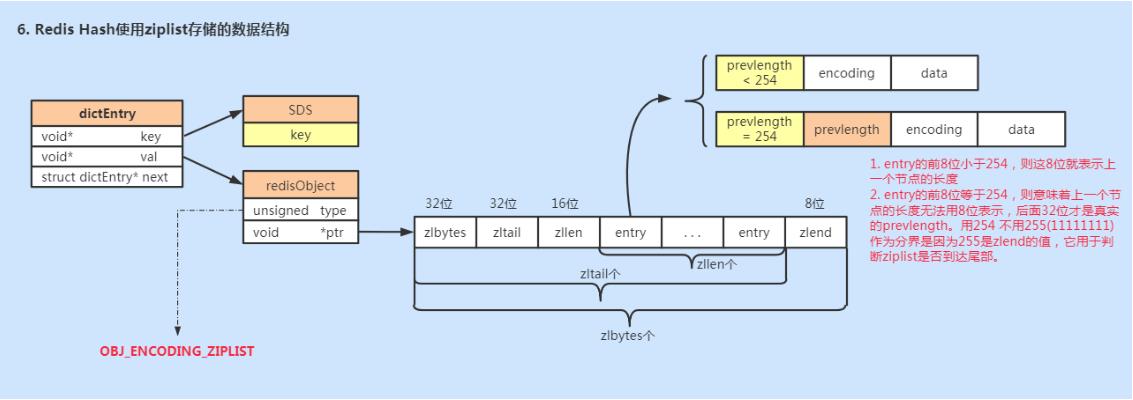
-
zlbytes: ziplist的长度(单位: 字节),是一个32位无符号整数
-
zltail: ziplist最后一个节点的偏移量,反向遍历ziplist或者pop尾部节点的时候有用。
-
zllen: ziplist的节点(entry)个数
-
entry: 节点
-
zlend: 值为0xFF,用于标记ziplist的结尾
看看Redis源码是如何实现的:
typedef struct zlentry
unsigned int prevrawlensize; /* 存储上一个链表节点的长度数值所需要的字节数*/
unsigned int prevrawlen; /* 上一个链表节点占用长度 */
unsigned int lensize; /* 存储当前链表节点长度数值所需要的字节数.*/
unsigned int len; /* 当前链表节点占用的长度 */
unsigned int headersize; /* 当前链表头部大小(非数据域)prevrawlensize + lensize. */
unsigned char encoding; /* 编码方式 */
unsigned char *p; /* ziplist以字符串形式保存,改指针指向当前节点的其实位置 */
zlentry;每个节点由三部分组成:prevlength、encoding、data
-
prevlengh: 记录上一个节点的长度,为了方便反向遍历ziplist
-
encoding: 当前节点的编码规则
-
data: 当前节点的值,可以是数字或字符串
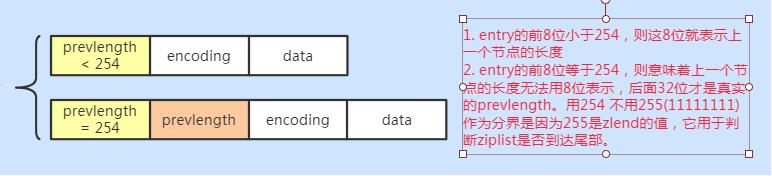
为了节省内存,根据上一个节点的长度prevlength 可以将ziplist节点分为两类:
-
entry的前8位小于254,则这8位就表示上一个节点的长度
-
entry的前8位等于254,则意味着上一个节点的长度无法用8位表示,后面32位才是真实的prevlength。用254 不用255(11111111)作为分界是因为255是zlend的值,它用于判断ziplist是否到达尾部。
encoding有8种(int5种 + string3种)类型,分别代表存储不同长度的数据:
#define ZIP_INT_16B (0xc0 | 0<<4) //整数data,占16位(2字节)
#define ZIP_INT_32B (0xc0 | 1<<4) //整数data,占32位(4字节)
#define ZIP_INT_64B (0xc0 | 2<<4) //整数data,占64位(8字节)
#define ZIP_INT_24B (0xc0 | 3<<4) //整数data,占24位(3字节)
#define ZIP_INT_8B 0xfe //整数data,占8位(1字节)
#define ZIP_STR_06B (0 << 6) //字符串data,最多有2^6字节(encoding后半部分的length有6位,length决定data有多少字节)
#define ZIP_STR_14B (1 << 6) //字符串data,最多有2^14字节
#define ZIP_STR_32B (2 << 6) //字符串data,最多有2^32字节(2) hashtable
hashtable则使用的是dict结构,如下图所示。
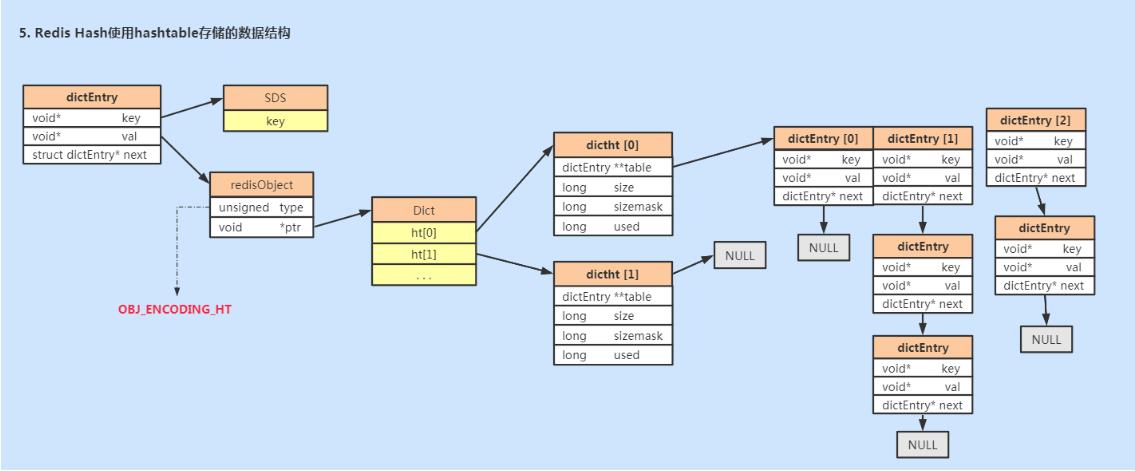
负载因子
和Java中hashmap一样,使用了拉链法解决哈希冲突的问题。但是,如果哈希冲突过多,hashtable的效率就会下降,当没有发生冲突时效率最好。所以当数据量不断增加,哈希冲突严重的时候就需要进行扩容操作。
hashtable也有负载因子,当哈希冲突产生的链表长度超过5时,就会触发扩容。
// dict.c
static int dict_can_resize = 1; // 是否需要扩容
static unsigned int dict_force_resize_ration = 5; // 扩容因子扩容步骤
-
Dict对象保存了两个哈希表ht[0]和ht[1],默认使用的是ht[0],ht[1]不会初始化和分别空间。
-
当需要扩容时,为ht[1]分配空间,ht[1] = ht[0].used * 2, 找到大于等于这个数的2次幂;
-
将ht[0]上的借贷拿数据rehash到ht[1]上,重新计算hash值和索引;
-
当ht[0]数据完成迁移后,释放ht[0]的空间,将ht[1]设置为ht[0];
(3) 使用说明
当hash对象同时满足两个条件的时候,使用ziplist编码:
-
哈希对象保存的键值对数量 < 512个;
-
所有键值对的键和值的字符串长度都 < 64 byte;
在redis.conf可以配置这两个参数
hash-max-ziplist-value 64 # ziplist中最大能存放的值长度
hash-max-ziplist-entries 512 # ziplist中最多能存放的entry节点数量Pt2.4 应用场景
string支持的场景hash都可以处理,此外hash还可以处理更加复杂的场景。
(1) 购物车
# key(用户):filed(商品id):value(商品数量)
127.0.0.1:6379> hset lucas table 2
(integer) 1
127.0.0.1:6379> hset lucas tv 1
(integer) 1
127.0.0.1:6379> hset lucas phone 3
(integer) 1
127.0.0.1:6379> hkeys lucas
1) "table"
2) "tv"
3) "phone"Pt3 LIST
Pt3.1 存储类型
存储有序的字符串(从左到右),元素可以重复,最大可存储数量2^32 - 1(40亿左右)。

Pt3.2 操作命令
LIST是一个有序数据列表,Redis也提供了非常便捷的API,可以在列表头部进行各种操作,也可以再列表的尾部进行各种操作,这就让LIST的使用变得非常灵活。
# 在LIST头部(左边)增加元素
lpush queue a
# 在LIST头部增加多个元素
lpush queue b c
# 在LIST尾部(右边)增加元素
rpush queue d
# 在LIST尾部增加多个元素
rpush queue e f
# 从LIST头部获取数据
lpop queue
# 从LIST尾部获取数据
rpop queue
# 获取指定位置的数据
lindex queue 0
# 获取范围下标的数据
lrange queue 0 -1
# 阻塞弹出:生产者消费者队列
blpop queue 1
brpop queue 1Pt3.3 实现原理
在Redis早期版本中,数据量小时使用ziplist实现LIST,当数据量到达一定临界点,使用LinkedList来实现LIST。在3.2版本之后,Redis统一用quicklist来存储LIST类型数据。
(1) quicklist
quicklist存储了一个双向链表,链表中每个节点quicklistnode都指向一个ziplist,所以quicklist是ziplist和linkedlist的结合体。
quicklist整体结构如下图所示:

我们再来看看源码的实现:
# quicklist是最外层数据结构,它包含了双向链表中quickNode节点。
typedef struct quicklist
quicklistNode *head; /* 指向双向链表的表头位置 */
quicklistNode *tail; /* 指向双向链表的表尾位置 */
unsigned long count; /* 所有quicklistNode中存放的ziplist元素个数 */
unsigned long len; /* 双向链表长度,quicklistNode节点个数 */
int fill : QL_FILL_BITS; /* ziplist最大大小,对应list-max-ziplist-size */
unsigned int compress : QL_COMP_BITS; /* 压缩深度,对应list-compress-depth */
unsigned int bookmark_count: QL_BM_BITS;/* 4位,bookmarks数组大小 */
quicklistBookmark bookmarks[]; /* 可选字段,quicklist重新分配内存空间时使用,不使用时不占用内存空间 */
quicklist;
# quicklistNode是双向链表的节点,指向了具体的ziplist数据结构。
typedef struct quicklistNode
struct quicklistNode *prev; /* 指向前一个节点 */
struct quicklistNode *next; /* 指向后一个节点 */
unsigned char *zl; /* 指向实际存放数据的ziplist指针 */
unsigned int sz; /* 当前node指向的ziplist占用多少字节 */
unsigned int count : 16; /* 当前node指向的ziplist中存储多少元素,占16bit,最多65535个 */
unsigned int encoding : 2; /* 是否采用LZF压缩算法压缩节点,RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* 当前ziplist是否已经被解压出来作临时使用 */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* 预留,more bits to steal for future usage */
quicklistNode;(2) 插入数据
quicklist可以选择在头部或者尾部进行插入(quicklistPushHead和quicklistPushTail),而不管是在头部还是尾部插入数据,都包含两种情况:
-
如果头节点(或尾节点)上ziplist大小没有超过限制(即_quicklistNodeAllowInsert返回1),那么新数据被直接插入到ziplist中(调用ziplistPush)。
-
如果头节点(或尾节点)上ziplist太大了,那么新创建一个quicklistNode节点(对应地也会新创建一个ziplist),然后把这个新创建的节点插入到quicklist双向链表中。
也可以从任意指定的位置插入。quicklistInsertAfter和quicklistInsertBefore就是分别在指定位置后面和前面插入数据项。这种在任意指定位置插入数据的操作,要比在头部和尾部的进行插入要复杂一些。
-
当插入位置所在的ziplist大小没有超过限制时,直接插入到ziplist中就好了;
-
当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小没有超过限制,那么就转而插入到相邻的那个quicklist链表节点的ziplist中;
-
当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小也超过限制,这时需要新创建一个quicklist链表节点插入。
-
对于插入位置所在的ziplist大小超过了限制的其它情况(主要对应于在ziplist中间插入数据的情况),则需要把当前ziplist分裂为两个节点,然后再其中一个节点上插入数据。
(3) 查找
quicklist的节点是由一个一个的ziplist构成的,每个ziplist都有大小,所以我们就只需要先根据每个quicklistnode的个数,从而找到对应的ziplist,调用ziplist的index就能成功找到。
(4) 删除
区间元素删除的函数是 quicklistDelRange
quicklist 在区间删除时,会先找到 start 所在的 quicklistNode,计算删除的元素是否小于要删除的 count,如果不满足删除的个数,则会移动至下一个 quicklistNode 继续删除,依次循环直到删除完成为止。
quicklistDelRange 函数的返回值为 int 类型,当返回 1 时表示成功的删除了指定区间的元素,返回 0 时表示没有删除任何元素。
Pt3.4 应用场景
(1) 有序列表
LIST主要用在存储有序数据的场景,比如评论列表,消息列表等。
# 评论列表增加文章评论
127.0.0.1:6379> rpush comments good
(integer) 1
127.0.0.1:6379> rpush comments better
(integer) 2
127.0.0.1:6379> rpush comments best
(integer) 3
# 查看所有的评论信息
127.0.0.1:6379> lrange comments 0 -1
1) "good"
2) "better"
3) "best"(2)队列/栈
前面说过,LIST支持在头部进行各种操作,也支持在尾部进行各种操作,这就让LIST变得非常灵活,有各种可能。比如先进先出的队列,先进后出的栈等。
LIST还提供了两个阻塞的弹出操作:BLPOP和BRPOP,可以设置超时时间(单位秒)。
-
blpop key timeout:移除并获取列表第一个元素,如果没有元素会阻塞直到超时或者有元素为止;
-
brpop key timeout:移除并获取列表最后一个元素,如果没有元素会阻塞直到超时或者有元素为止;
是不是感觉很熟悉,是不是好像跟生产者消费者队列很相似:
# 添加元素
127.0.0.1:6379> rpush workqueue 1
(integer) 1
# 阻塞弹出元素
127.0.0.1:6379> blpop workqueue 5
1) "workqueue"
2) "1"
# 没有元素时等待超时或者有元素
127.0.0.1:6379> blpop workqueue 5
(nil)
(5.04s)Pt4 SET
Pt4.1 存储类型
Set存储string类型的无序集合,且set中元素不可重复,最大存储数量2^32 - 1(40亿左右)。
Pt4.2 操作命令
# Set集合基本命令
sadd myset a b c d e f g # 添加一个或多个元素
smembers myset # 获取所有元素
scard myset # 统计元素个数
srandmember myset # 随机获取一个元素(元素还在Set中)
spop myset # 随机弹出一个元素
srem myset d e f # 移除一个或多个元素
sismember myset a # 查看元素是否存在于Set中
del myset # 删除Set
# 针对Set集合的处理
sdiff set1 set2 # 获取两个Set差集
sinter set1 set2 # 获取两个集合交集(intersection)
sunion set1 set2 # 获取并集Pt4.3 实现原理
Redis用intset或hashtable存储Set类型,如果所有元素都是整数类型,用intset存储,如果不是整数类型,就用hashtable来存储。
使用hashtable存储比较简单,key-field-value结构中,value为null就可以了。我们看下intset的结构。
intset是一个整数集合, 只能存储整数类型的数据, 可以是16位, 32位, 或者是64位, 是以升序排列的数组进行保存数据
typedef struct intset
/*编码*/
uint32_t encoding;
/*长度*/
uint32_t length;
/*集合内容,按升序排列数组*/
int8_t contents[];
intset;intset实质就是一个有序数组(使用二分查找),可以看到添加删除元素都比较耗时,查找元素是O(logN)时间复杂度,数据量大时性能表现很糟糕。所以存储结构除了和数据类型有关,如果元素的个数超过一定数量,也会使用hashtable存储(查找效率O(1)),redis.conf有相关配置:
set-max-intset-entries 512可以看出,使用hashtable性能更好,但是会浪费很多空间,比如没有使用的value、指针数据等,intset节省内存空间,但是性能略差。所以综合考虑,在存储少量的整数类型是使用intset,排序简单,二分查找性能相对没有特别差。
Pt4.4 应用场景
(1)抽奖
使用Set存储不重复的结果,spop命令可以随机获取元素进行抽奖。
(2)点赞、签到、打卡
比如某一天考勤打卡,使用日期等信息作为key,打卡用户add到set中统计打卡信息;
或者统计某条微博朋友圈点赞记录,使用该信息唯一ID作为key,将点赞的用户Id添加到set中;
其它场景也类似。
# 使用日期作为key,域账户作为打卡凭证:
# 模拟打卡
127.0.0.1:6379> sadd 20201222 tracy.chen
(integer) 1
127.0.0.1:6379> sadd 20201222 zhouzhongmao
(integer) 1
127.0.0.1:6379> sadd 20201222 sunhao
(integer) 1
127.0.0.1:6379> sadd 20201222 kobe
(integer) 1
# 查看打卡人数
127.0.0.1:6379> scard 20201222
(integer) 4
# 查看具体打卡信息
127.0.0.1:6379> smembers 20201222
1) "tracy.chen"
2) "kobe"
3) "sunhao"
4) "zhouzhongmao"(3)京东、天猫商品评价页面的标签信息实现
# 使用tag:i5001维护商品所有标签(还可以进一步扩展增加每个标签的统计信息)
127.0.0.1:6379> sadd tag1:i5001 beautiful
(integer) 1
127.0.0.1:6379> sadd tag1:i5001 clear
(integer) 1
127.0.0.1:6379> sadd tag1:i5001 good
(integer) 1
127.0.0.1:6379> smembers tag1:i5001
1) "clear"
2) "beautiful"
3) "good"(4)用户关注的推荐模型
我关注的人,你关注的人,共通关注的人
127.0.0.1:6379> sadd ikown kobe tim shark tracy
(integer) 4
127.0.0.1:6379> sadd ukown kobe james durant tracy
(integer) 4
127.0.0.1:6379> sinter ikown ukown
1) "tracy"
2) "kobe"上面这个模型,在电商场景中,搜索商品是选择不同的标签筛选结果不同也同样能够解决。
Pt5 ZSET
Pt5.1 存储类型
ZSET是有序集合,存储有序的元素,每个元素有score值,按照score从小到大排名,如果score相同按照key的ASCII码排序。
Pt5.2 操作命令
# 添加元素
zadd myzset 10 java 20 php 30 ruby 40 cpp 50 python
# 获取全部元素
zrange myzset 0 -1 withscores
zrevrange myzset 0 -1 withscores
# 根据分值区间获取元素
zrangebyscore myzset 20 30
# 移除元素
zrem myzset php cpp
# 统计元素个数
zcard myzset
# 分值递增
zincrby myzset 5 python
# 根据分值统计个数
zcount myzset 20 60
# 获取元素排名rank
zrank myzset python
# 获取元素分值score
zscore myzset pythonPt5.3 实现原理
ZSET也有两种存储方式,ziplist和skiplist。如果元素数据小于128个,且元素长度均小于64字节时,使用ziplist,否则使用skiplist。
redis.confg有具体配置:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64分值的变动,会导致ziplist和skiplist元素的移动。ziplist前面已经介绍了,来看下什么是skiplist。
什么是SkipList
对于单链表来说,即使数据是已经排好序的,想要查询其中的一个数据,只能从头开始遍历链表,这样效率很低,时间复杂度是 O(n)。我们可以为链表建立一个“索引”,来提高查询的效率。

如下图所示,我们在原始链表的基础上,每两个结点提取一个结点建立索引,我们把抽取出来的结点叫做索引层或者索引,down 表示指向原始链表结点的指针。当数据量增大到一定程度的时候,效率将会有显著的提升。如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表。
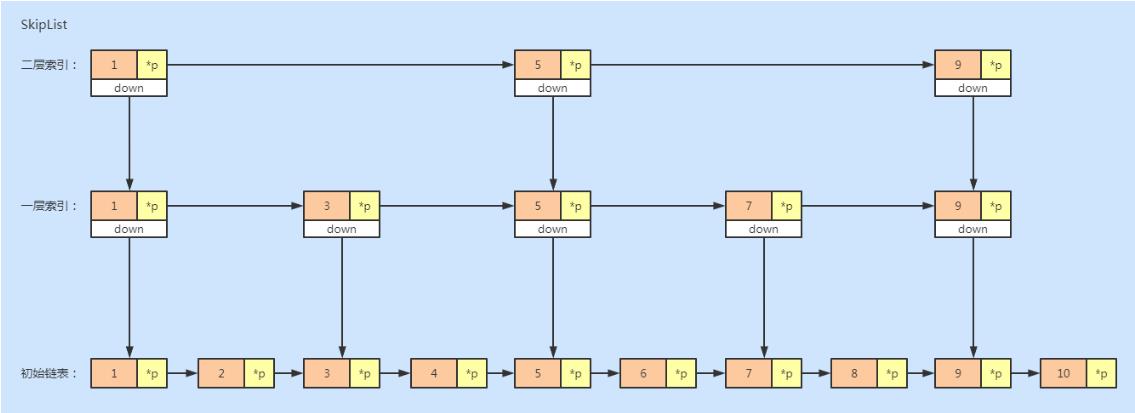
跳表是用空间来换时间
跳表的效率比链表高了,但是跳表需要额外存储多级索引,所以需要的更多的内存空间。
跳表的空间复杂度分析并不难,如果一个链表有 n 个结点,如果每两个结点抽取出一个结点建立索引的话,那么第一级索引的结点数大约就是 n/2,第二级索引的结点数大约为 n/4,以此类推第 m 级索引的节点数大约为 n/(2^m),我们可以看出来这是一个等比数列。
这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2,所以跳表的空间复杂度为 o(n)。
那么我们有没有办法减少索引所占的内存空间呢?可以的,我们可以每三个结点抽取一个索引,或者没五个结点抽取一个索引。这样索引结点的数量减少了,所占的空间也就少了。
跳表的插入和删除
我们想要为跳表插入或者删除数据,我们首先需要找到插入或者删除的位置,然后执行插入或删除操作,前边我们已经知道了,跳表的查询的时间复杂度为 O(logn),因为找到位置之后插入和删除的时间复杂度很低,为 O(1),所以最终插入和删除的时间复杂度也为 O(longn)。
删除操作的话,如果这个结点在索引中也有出现,我们除了要删除原始链表中的结点,还要删除索引中的。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。当然,如果我们用的是双向链表,就不需要考虑这个问题了。
如果我们不停的向跳表中插入元素,就可能会造成两个索引点之间的结点过多的情况。结点过多的话,我们建立索引的优势也就没有了。所以我们需要维护索引与原始链表的大小平衡,也就是结点增多了,索引也相应增加,避免出现两个索引之间结点过多的情况,查找效率降低。
跳表是通过一个随机函数来维护这个平衡的,当我们向跳表中插入数据的的时候,我们可以选择同时把这个数据插入到索引里,那我们插入到哪一级的索引呢,这就需要随机函数,来决定我们插入到哪一级的索引中。
这样可以很有效的防止跳表退化,而造成效率变低。
Pt5.4 应用场景
(1)排行榜
ZSET适合顺序会动态变化的列表场景,比如百度热榜、微博热搜等,实现也比较简单。
# 初始化排行榜
127.0.0.1:6379> zadd hotrank 0 new1 0 new2 0 new3
(integer) 3
127.0.0.1:6379> zrange hotrank 0 -1 withscores
1) "new1"
2) "0"
3) "new2"
4) "0"
5) "new3"
6) "0"
# 发生点击事件时,增加分数
[root@VM-0-17-centos redis]# ./redisCli.sh
127.0.0.1:6379> zincrby hotrank 1 new1
"1"
127.0.0.1:6379> zincrby hotrank 1 new1
"2"
127.0.0.1:6379> zincrby hotrank 1 new3
"1"
# 查看排行榜
127.0.0.1:6379> zrevrange hotrank 0 -1 withscores
1) "new1"
2) "2"
3) "new3"
4) "1"
5) "new2"
6) "0"Pt6 其它数据类型
除了5种基本数据类型,Redis还提供了BitMaps、Hyperloglogs、Geo和Stream,这些不是特别常用,只在特定场景下使用,简单说明下。
Pt6.1 BitMaps
Bitmaps是在字符串类型上定义的位操作,一个字节由8个二进制位组成,基于Bitmaps可以操作字节的每个二进制位。
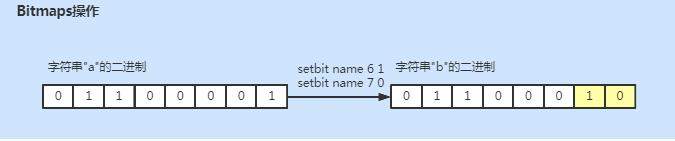
# 定义字符串,查看二进制
127.0.0.1:6379> set name a
OK
127.0.0.1:6379> getbit name 1
(integer) 1
127.0.0.1:6379> getbit name 2
(integer) 1
# 修改对应位的二进制
127.0.0.1:6379> setbit name 6 1
(integer) 0
127.0.0.1:6379> setbit name 7 0
(integer) 1
127.0.0.1:6379> get name
"b"
# 查看二进制位中1的个数
127.0.0.1:6379> bitcount name
(integer) 3
# 获取第一个1的二进制位置
127.0.0.1:6379> bitpos name 1
(integer) 1Bitmaps还支持按位与、按位或等操作,使用Bitmaps相当于把字符串当8位的二进制使用,1MB=8388608位,可以统计大量的数据,并且节省空间。
Pt6.2 Hyperloglogs/Geo/Stream
Hyperloglogs:提供了一种不太精确的基数统计方法,用来统计一个集合中不重复的元素个数,比如网站的UV,应用的日活月活等,存在细微误差。
Geo:用于存放经纬度信息,并且提供了API基于经纬度的计算。
Stream:支持多播的可持久化消息队列。
Redis的数据类型非常重要,尤其是在对缓存要求高的场景下,熟悉每种数据类型才能更好地选型,实现更复杂的能力。
以上是关于02. Redis 数据类型的主要内容,如果未能解决你的问题,请参考以下文章