Linux内存管理之SLAB内存分配器
Posted yxtxiaotian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内存管理之SLAB内存分配器相关的知识,希望对你有一定的参考价值。
目录
三、两个重要的数据结构kmem_cache和array_cache
1、 kmem_cache和array_cache数据结构之间的连接关系
一、前言
1、 为什么需要SLAB内存分配器
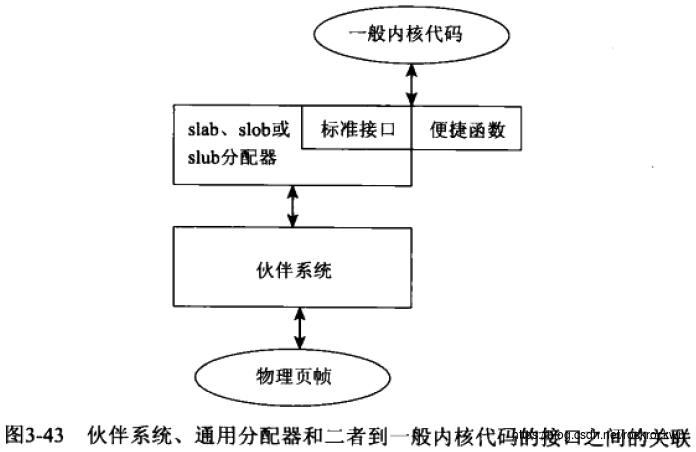
slab内存分配器是linux内核中比较经典的内存分配器(目前已经被slub内存分配器取代了)。之所以提出slab分配器,是因为buddy system只能按page对齐来分配内存。然而大多数情况下,需要的内存size都不是按page对齐的,如果直接通过buddy system分配内存,就会出现很大的内存碎片,内存碎片即分配了却没有使用,也无法再被分配的内存。正是由于buddy system的这种限制,slab分配器应运而生。slab分配器的底层依托于buddy system,上层却对用户提供了更加灵活的内存分配服务。如下图:
2、 SLAB内存分配器作用
提供小内存块不是slab分配器的唯一任务. 由于结构上的特点. 它也用作一个缓存. 主要针对经常分配并释放的对象. 通过建立slab缓存, 内核能够储备一些对象, 供后续使用, 即使在初始化状态, 也是如此。
举例来说, 为管理与进程关联的文件系统数据, 内核必须经常生成struct fs_struct的新实例. 此类型实例占据的内存块同样需要经常回收(在进程结束时). 换句话说, 内核趋向于非常有规律地分配并释放大小为sizeoffs_struct的内存块. slab分配器将释放的内存块保存在一个内部列表中. 并不马上返回给伙伴系统. 在请求为该类对象分配一个新实例时, 会使用最近释放的内存块. 这有两个优点. 首先, 由于内核不必使用伙伴系统算法, 处理时间会变短. 其次, 由于该内存块仍然是”新”的,因此其仍然驻留在CPU高速缓存的概率较高.
3、 SLAB内存分配器工作机制
- 从buddy system分配pages,放入slab分配器内存池,也可以称为cache。
- 用户调用slab分配器提供的内存分配接口如kmalloc,从slab分配器内存池中分配内存,内存的size没有按page size对齐的要求。
注:本文说明的cache缓存指的并不是真正的缓存,真正的缓存指的是硬件缓存,也就是我们通常所说的L1 cache、L2 cache、L3 cache,硬件缓存是为了解决快速的CPU和速度较慢的内存之间速度不匹配的问题,CPU访问cache的速度要快于内存,如果将常用的数据放到硬件缓存中,使用时CPU直接访问cache而不用再访问内存,从而提升系统速度。下文中的缓存实际上是用软件在内存中预先开辟一块空间,使用时直接从这一块空间中去取,是SLAB分配器为了便于对小块内存的管理而建立的。
4、 SLAB相关说明
(1)SLAB与伙伴(Buddy)算法
伙伴系统Buddy System的相关介绍可以参加其他博客。在伙伴系统中,根据用户请求,伙伴系统算法会为用户分配2^order个页框,order的大小从0到11。在上文中,提到SLAB分配器是建立在伙伴系统之上的。简单来说,就是用户进程或者系统进程向SLAB申请了专门存放某一类对象的内存空间,但此时SLAB中没有足够的空间来专门存放此类对象,于是SLAB就像伙伴系统申请2的幂次方个连续的物理页框,SLAB的申请得到伙伴系统满足之后,SLAB就对这一块内存进行管理,用以存放多个上文中提到的某一类对象。
(2)SLAB与对象
对象实际上指的是某一种数据类型。一个SLAB只针对一种数据类型(对象)。为了提升对对象的访问效率,SLAB可能会对对象进行对齐【slab着色区和着色补偿区:着色区的大小使Slab中的每个对象的起始地址都按高速缓存中的”缓存行(cache line)”大小进行对齐】。
(3)SLAB与per-CPU缓存
为了提升效率,SLAB分配器为每一个CPU都提供了对应各个CPU的数据结构struct array_cache,该结构指向被释放的对象。当CPU需要使用申请某一个对象的内存空间时,会先检查array_cache中是否有空闲的对象,如果有的话就直接使用。如果没有空闲对象,就像SLAB分配器进行申请。
二、SLAB内存分配器结构分析
1、SLAB内存分配器高层组织结构
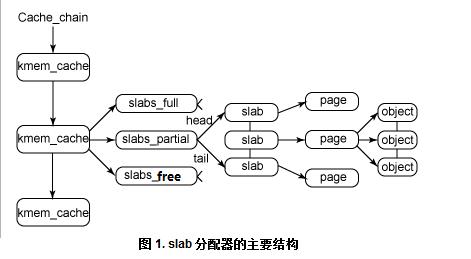
图 1 给出了 slab 结构的高层组织结构。在最高层是 cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit 算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。
2、 kmem_cache定义
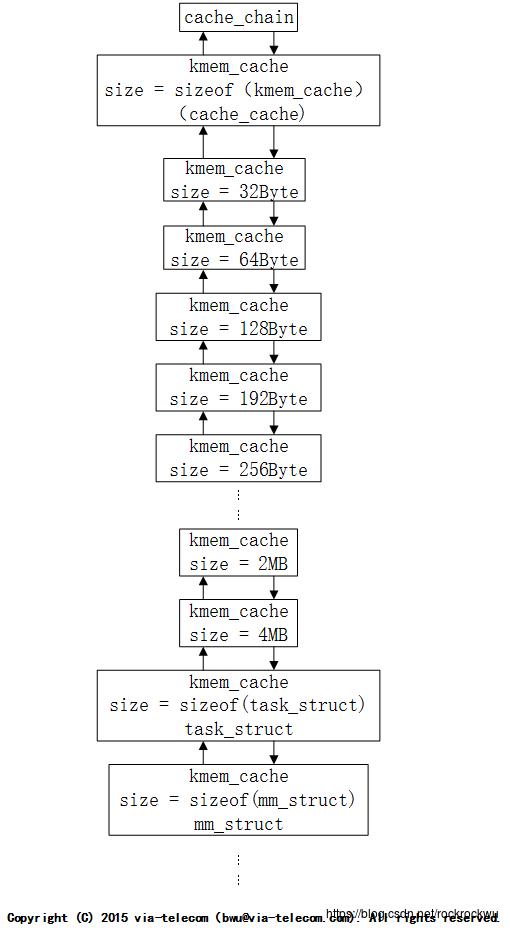
cache_chain 的每个元素都是一个 kmem_cache 结构的引用(称为一个 cache)。每一个kmem_cache定义了一个要管理的给定大小的对象池。
内核在初始化的时候根据kmalloc_sizes.h文件中定义的obj大小(参见 kmalloc分配内存大小的限制和宏的一种用法),初始化了管理这些obj的slab,以及相关kmem_cache。cache_chain上挂着系统中所有的kmem_cache。前面我们提到初始化的时候会根据kmalloc_sizes.h中的定义初始化好固定大小obj的slab以及对应的kmem_cache,这些kmem_cache称之为通用缓存,提供给kmalloc来使用的。kmalloc根据传入size大小来选择合适的kmem_cache,然后从他的array_cache中取出obj。在初始化之后,系统中kmem_cache的链表大致如下。
3、kmem_cache中的slab类型
每个kmem_cache缓存都包含了一个 slabs 列表,这是一段连续的内存块(通常都是页面)。存在 3 种 slab:
- slabs_full:完全分配的 slab
- slabs_partial:部分分配的 slab
- slabs_free:空 slab,或者没有对象被分配
注意 slabs_free 列表中的 slab 是进行回收(reaping)的主要备选对象。正是通过此过程,slab 所使用的内存被返回给操作系统供其他用户使用。
slab 列表中的每个 slab 都是一个连续的内存块(一个或多个连续页),它们被划分成一个个对象。这些对象是从特定缓存中进行分配和释放的基本元素。注意 slab 是 slab 分配器进行操作的最小分配单位,因此如果需要对 slab 进行扩展,这也就是所扩展的最小值。通常来说,每个 slab 被分配为多个对象。
由于对象是从 slab 中进行分配和释放的,因此单个 slab 可以在 slab 列表之间进行移动。例如,当一个 slab 中的所有对象都被使用完时,就从 slabs_partial 列表中移动到 slabs_full 列表中。当一个 slab 完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到 slabs_partial 列表中。当所有对象都被释放之后,就从 slabs_partial 列表移动到 slabs_free 列表中。
4、SLAB内存分配器结构详解
(1)slab内存分配器结构图解
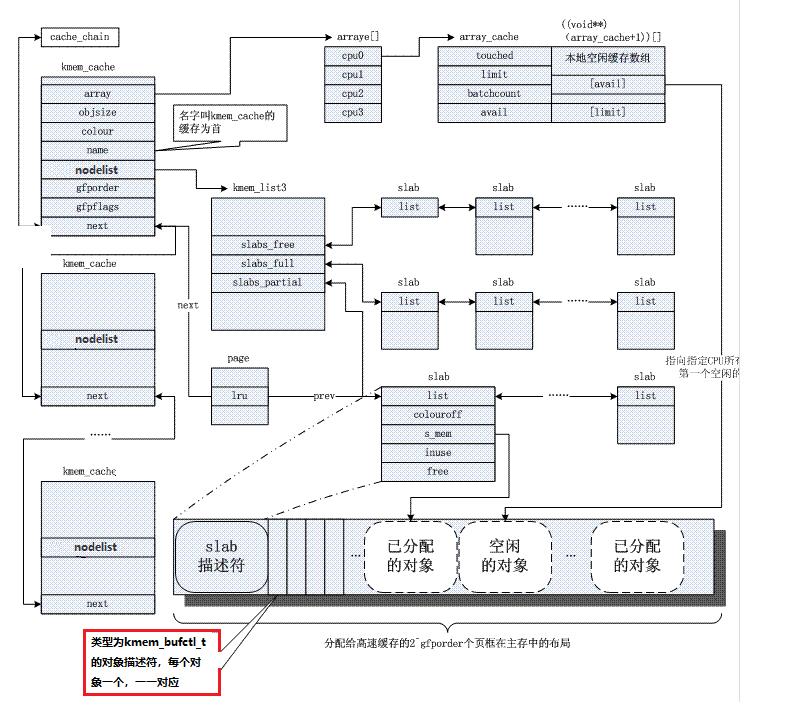
注:SLAB分配器把对象分组放进高速缓存。每个高速缓存都是同种类型对象的一种“储备”。包含高速缓存的主内存区被划分为多个SLAB,每个SLAB由一个或多个连续的页框组成,这些页框中既包含已分配的对象,也包含空闲的对象。如上图所示。
(2)数据结构源码
1、kmem_cache数据结构描述:
struct kmem_cache
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];//array是一个指向数组的指针,每个数组项都对应于系统中的一个CPU。每个数组项都包含了另一个指针,指向下文讨论的array_cache结构的实例
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount;//指定了在每CPU列表为空的情况下,从缓存的slab中获取对象的数目。它还表示在缓存增长时分配的对象数目
unsigned int limit;//limit指定了每CPU列表中保存的对象的最大数目,如果超出该值,内核会将batchcount个对象返回到slab
unsigned int shared;
unsigned int buffer_size;//指定了缓存中管理的对象的长度
u32 reciprocal_buffer_size;//buffer_size的倒数值,为了克服出发运算对性能的影响
/* 3) touched by every alloc & free from the backend */
unsigned int flags;//是一个标志寄存器,定义缓存的全局性质,当前只有一个标志位,用于标记slab头得管理数据是在slab内还是外
unsigned int num;//保存了可以放入slab的对象的最大数目
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;//指定了slab包含的页数目以2为底得对数
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags;//与伙伴系统交互时所提供的分配标识
size_t colour;//指定了颜色的最大数目
unsigned int colour_off;//是基本偏移量乘以颜色值获得的绝对偏移量
struct kmem_cache *slabp_cache;//如果slab头部的管理数据存储在slab外部,则slabp_cache指向分配所需内存的一般性缓存;如果slab头部在slab上,则其为NULL
unsigned int slab_size;//slab管理区的大小
unsigned int dflags;//另一个标志集合,描述slab的“动态性质”,但目前还没有定义标志
/* constructor func */
void (*ctor)(struct kmem_cache *, void *);//创建高速缓存时的构造函数指针
/* 5) cache creation/removal */
const char *name;//缓存的名称
struct list_head next;//用于将kmem_cache的所有实例保存在全局链表cache_chain上
/* 6) statistics */
#if STATS//统计数据字段
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
#endif
#if DEBUG
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES];//nodelists是一个数组,每个数组对应于系统中一个可能的内存结点。每个数组项都包含kmem_list3的一个实例
/*
* Do not add fields after nodelists[]
*/
2、array_cache数据结构描述:
struct array_cache
/*保存了per-CPU缓存中可使用对象的指针的个数*/
unsigned int avail;
/*保存的对象的最大的数量*/
unsigned int limit;
/*如果per-CPU列表中保存的最大对象的数目超过limit值,内核会将batchcount个对象返回到slab*/
unsigned int batchcount;
/*从per—CPU缓存中移除一个对象时,此值将被设置为1,缓存收缩时,此时被设置为0.这使得内核能够确认在缓存上一次
收缩之后是否被访问过,也是缓存重要性的一个标志*/
unsigned int touched;
/*一个伪指针数组,指向per-CPU缓存的对象*/
void *entry[];
;3、kmem_list3数据结构描述:
struct kmem_list3
struct list_head slabs_partial;//部分空闲的slab链表
struct list_head slabs_full;//非空闲的slab链表
struct list_head slabs_free;//完全空闲的slab链表
unsigned long free_objects;//部分空闲的slab链表和完全空闲的slab链表中空闲对象的总数
unsigned int free_limit;//指定了所有slab上容许未使用对象的最大数目
unsigned int colour_next;//内核建立的下一个slab的颜色
spinlock_t list_lock;
struct array_cache *shared;//结点内共享
struct array_cache **alien;//在其他结点上
unsigned long next_reap;//定义了内核在两次尝试收缩缓存之间,必须经过的时间间隔
int free_touched;//表示缓存是否是活动的
;4、 slab数据结构描述:
struct slab
struct list_head list;
unsigned long colouroff;//该Slab上着色区的大小
void *s_mem;//指向对象区的起点
unsigned int inuse;//Slab中所分配对象的个数
kmem_bufctl_t free;//指明了空闲对象链中的第一个对象,kmem_bufctl_t其实是一个整数
unsigned short nodeid;//结点标识号
;注:与SLAB有关的比较重要的两个属性:s_mem和freelist,其中s_mem指向slab中的第一个对象的地址(或者已经被分配或者空闲)。freelist指向空闲对象链表。
(3)slab结构

每个Slab的首部都有一个小小的区域是不用的,称为“着色区(coloring area)”。着色区的大小使Slab中的每个对象的起始地址都按高速缓存中的”缓存行(cache line)”大小进行对齐(80386的一级高速缓存行大小为16字节,Pentium为32字节)。因为Slab是由1个页面或多个页面(最多为32)组成,因此,每个Slab都是从一个页面边界开始的,它自然按高速缓存的缓冲行对齐。但是,Slab中的对象大小不确定,设置着色区的目的就是将Slab中第一个对象的起始地址往后推到与缓冲行对齐的位置。因为一个缓冲区中有多个Slab,因此,应该把每个缓冲区中的各个Slab着色区的大小尽量安排成不同的大小,这样可以使得在不同的Slab中,处于同一相对位置的对象,让它们在高速缓存中的起始地址相互错开,这样就可以改善高速缓存的存取效率。
每个Slab上最后一个对象以后也有个小小的废料区是不用的,这是对着色区大小的补偿,其大小取决于着色区的大小,以及Slab与其每个对象的相对大小。但该区域与着色区的总和对于同一种对象的各个Slab是个常数。
每个对象的大小基本上是所需数据结构的大小。只有当数据结构的大小不与高速缓存中的缓冲行对齐时,才增加若干字节使其对齐。所以,一个Slab上的所有对象的起始地址都必然是按高速缓存中的缓冲行对齐的
三、两个重要的数据结构kmem_cache和array_cache
1、 kmem_cache和array_cache数据结构之间的连接关系
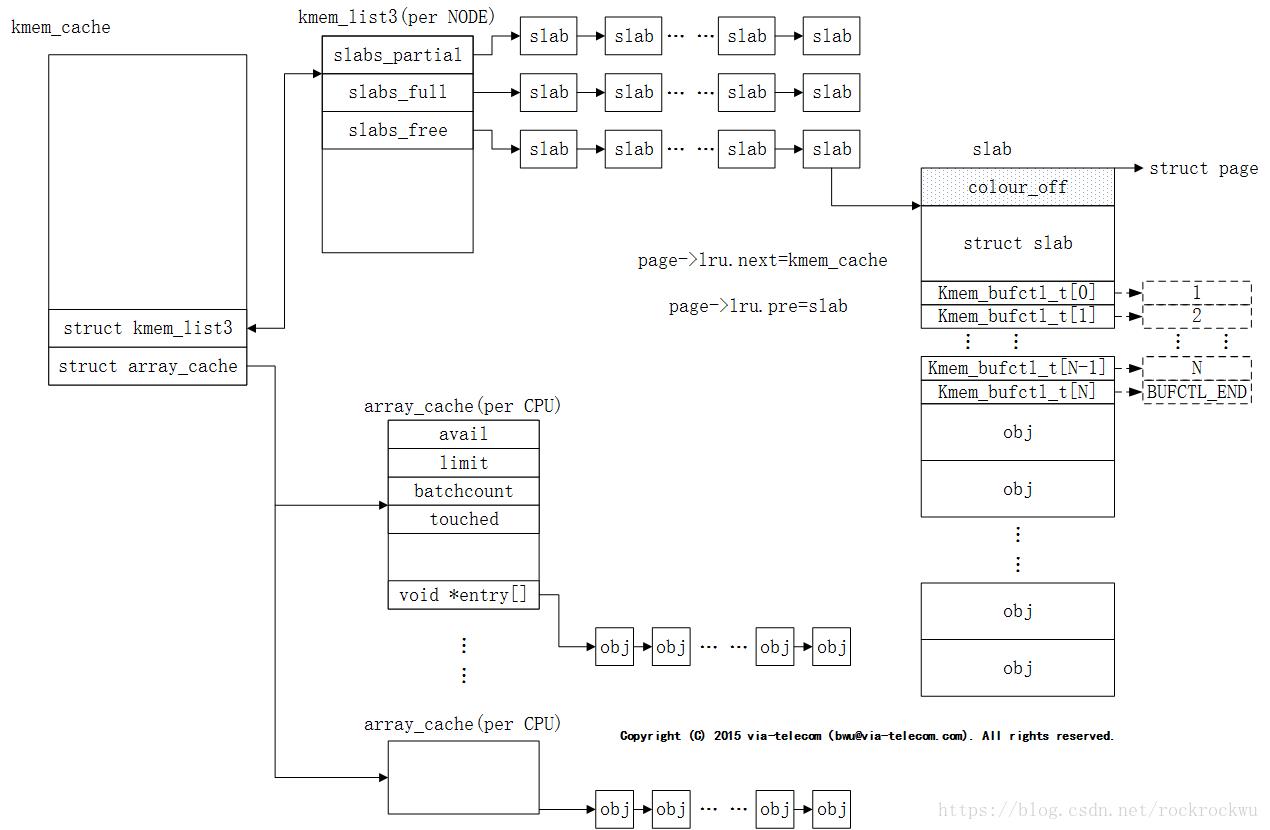
2、struct kmem_list3
kmem_list3是per node类型数据,一个node对应一个kmem_list3结构,我们的系统是UMA,所以只有一个kmem_list3结构。
kmem_list3中有三个链表slabs_partial、slabs_full、slabs_free,每个链表中挂着都是slab结构。其中,已经有部分obj被分配出去的slab均挂在slabs_partial下;全部obj都被分配出去的slab挂在slabs_full下;全部obj都未分配出去的slab挂在slabs_free下。
3、struct array_cache
array_cache是per cpu类型数据,每个core对应一个array_cache结构。
当array_cache中的obj为空时,系统会以batchcount值为准,一次性从kmem_list3中搬运batchcount个obj到arry_cache中,存放在entry里。
3、 slab
slab主要包含两大部分:
- 管理性数据:管理性数据包括struct slab和kmem_bufctl_t;
- obj对象;
slab有两种形式的结构,管理数据外挂式或内嵌式。如果obj比较小,那么struct slab和kmem_bufctl_t可以和obj分配在同一个物理page中,可称为内嵌式;如果obj比较大,那么管理性数据需要单独分配一块内存来存放,称之为外挂式。我们在上图中所画的slab结构为内嵌式。
4、kmem_bufctl_t对象描述符
管理性数据kmem_bufctl_t的类型是unsigned int,本质上是一个空闲obj链表,用于描述下一个可用obj序号。初始化时,当前slab中的obj均可用,所以图中kmem_bufctl_t中的值依次就是下一个可用的obj序。
kmem_bufctl_t中使用方法可参考下图场景。 
系统初始化时slab->free执行0#slab,某时刻系统已将0#—3# obj分配出去,此时slab->free指向4# slab,而4#slab对应的kmem_bufctl_t中存放的值是5。表明slab中current可用obj是4#,next可用obj是5#。
系统运行一段时间后,1# obj需回收。此时,1#obj对应的kmem_bufctl_t中填入slab->free值4,并将slab->free修正为1。这表明slab中current可用obj是1#,next可用的obj为4#。
四、SLAB分配流程以及管理逻辑
1、SLAB与分区页框分配器
先介绍一下分区页框分配器,分区页框分配器用于处理对连续页框组的内存分配请求。其中有一些函数和宏请求页框,一般情况下,它们都返回第一个所分配的页的线性地址,如果分配失败,则返回NULL。这些函数简介如下:
// 请求2^order个连续的页框,他返回第一个所分配页框的描述符的地址。分配失败则返回NULL。
alloc_pages(gfp_mask,order);
// 与函数alloc_pages(gfp_mask,orser)类似,但是此函数返回第一个所分配页的线性地址。
__get_free_pages(gfp_mask,order);
// 该函数先检查page指向的页描述符,如果该页框未被保留(PG_reserved标志位为0),就把描述符的count字段值减1。如果count字段的值变为0,就假定从与page对应的页框开始的2^order个连续的页框不再被使用。在这种情况下该函数释放页框。
__free_pages(page,order);
// 类似于__free_pages(),但是它接收的参数为要释放的第一个页框的线性地址addr。
free_pages(addr,order);
在内核完成slab分配器的初始化之后(SLAB分配器的初始化参见链接 SLAB分配器初始化),后续当SLAB分配器创建新的SLAB时,需要依靠分区页框分配器来获得一组连续的空闲页框。为了达到此目的,需要调用kmem_getpages()函数,函数定义如下:
static struct page *kmem_getpages(struct kmem_cache *cachep, gfp_t flags,int nodeid);其中,参数cachep指向需要额外页框的高速缓存描述符(请求页框的个数存放在cachep->gfporder字段中的order决定),flags说明如何请求页框,nodeid指明从哪个NUMA节点的内存中请求页框。与kmem_getpages()函数相对的是kmem_freepages(),kmem_freepages()函数可以释放分配给slab的页框。kmem_freepages()函数定义如下:
static void kmem_freepages(struct kmem_cache *cachep, struct page *page);2、SLAB与创建高速缓存
创建新的slab缓存需要调用函数kmem_cache_create()。该函数定义如下:
/*
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a interrupt, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void *));kmem_cache_create()函数在调用成功时返回一个指向所构造的高速缓存的指针,失败则返回NULL。
与kmem_cache_create()函数相对应的是销毁高速缓存的函数kmem_cache_destroy(),该函数定义如下:
void kmem_cache_destroy(struct kmem_cache *s)
LIST_HEAD(release);
bool need_rcu_barrier = false;
int err;
if (unlikely(!s))
return;
get_online_cpus();
get_online_mems();
kasan_cache_destroy(s);
mutex_lock(&slab_mutex);
s->refcount--;
if (s->refcount)
goto out_unlock;
err = shutdown_memcg_caches(s, &release, &need_rcu_barrier);
if (!err)
err = shutdown_cache(s, &release, &need_rcu_barrier);
if (err)
pr_err("kmem_cache_destroy %s: Slab cache still has objects\\n",
s->name);
dump_stack();
out_unlock:
mutex_unlock(&slab_mutex);
put_online_mems();
put_online_cpus();
release_caches(&release, need_rcu_barrier);
EXPORT_SYMBOL(kmem_cache_destroy);
需要注意的是:kmem_cache_destroy()函数销毁的高速缓存中应该只包含未使用对象,如果一个高速缓存中含有正在使用的对象时调用kmem_cache_destroy()函数将会失败,从kmem_cache_destroy()函数的源代码中我们很容易看出。
3、SLAB对象分配和释放
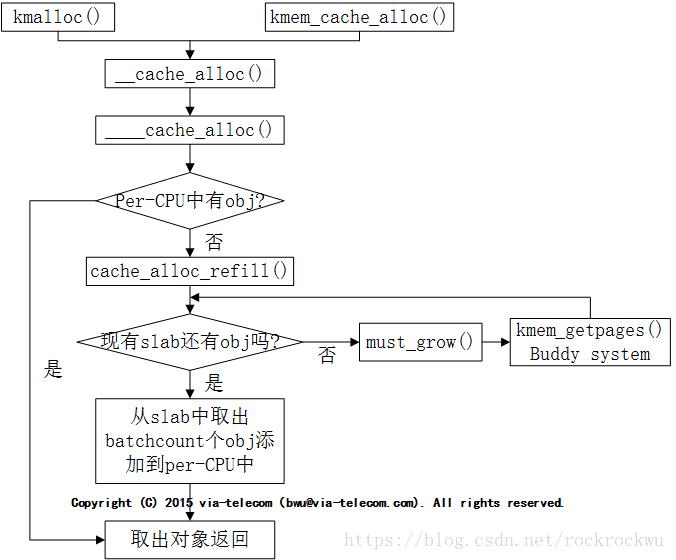
(1)对象分配概述
obj分配优先考虑从array_cache的entry中取,取的规则遵循LIFO原则,先从enry的末尾取出obj,因为这个obj很有可能还在硬件cache中,是热的。如果entry为空,则说明是第一次从array_cache中分配obj或者是array_cache中的所有obj都已分配,所以需要先从kmem_cache的kmem_list3中取出batchcount个obj,把这些obj全部填充到enty中,然后再分配。
(2)对象释放概述
obj释放也是优先考虑释放到array_cache中,而不是直接释放到kmem_list3中。只有array_cache中的obj超过了limit上限,系统才会将enty中的头batchcount个obj搬到kmem_cache所在的kmem_list3中,然后将entry中剩余obj向前移动,然后再将准备释放的obj放到entry的末尾。
(3)kmem_cache_alloc
创建完成某一种数据类型或者某一种对象的高速缓存之后,我们可以从该对象的高速缓存中分配与释放对象。其中,kmem_cache_alloc()函数用于从特定的缓存中获取对象,该函数定义如下:
/**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
void *ret = slab_alloc(cachep, flags, _RET_IP_);
kasan_slab_alloc(cachep, ret, flags);
trace_kmem_cache_alloc(_RET_IP_, ret,
cachep->object_size, cachep->size, flags);
return ret;
EXPORT_SYMBOL(kmem_cache_alloc);从函数的名称、参数、返回值、注释中,我们很容易知道kmem_cache_alloc()函数从给定的slab高速缓存中获取一个指向空闲对象的指针。实际上,进行获取空闲对象的时候,会先从per-CPU缓存中也就是array_cache中查找空闲对象,如果没有则会从kmem_cache_node中获取空闲对象,如果也没有则需要利用伙伴算法分配新的连续页框,然后从新的页框中获取空闲对象。
[1]、kmem_cache_alloc大致的调用链如下:
kmem_cache_alloc()——>slab_alloc()——>__do_cache_alloc()——>____cache_alloc()——>cpu_cache_get()(这里实际上是从array_cache中获取空闲对象)——>cache_alloc_refill()(这里会在array_cache中没有空闲对象时执行)——>cpu_cache_get()(经过cache_alloc_refill()的执行基本保证array_cache中有空闲对象)——>返回可用空闲对象
[2]、cache_alloc_refill()函数执行步骤分解如下:
cache_alloc_refill()——>尝试从被一个NUMA节点所有CPU共享的缓冲中获取空闲对象(源代码注释中写道:See if we can refill from the shared array),如果有则返回可用对象,refill结束——>从kmem_cache_node中的slab中获取空闲对象,有则返回,没有就执行下一步——>kmem_getpages()
(4)kmem_cache_free
kmem_cache_free()函数用于从特定的缓存中释放对象,函数定义如下:
/**
* kmem_cache_free - Deallocate an object
* @cachep: The cache the allocation was from.
* @objp: The previously allocated object.
*
* Free an object which was previously allocated from this
* cache.
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
unsigned long flags;
cachep = cache_from_obj(cachep, objp);
if (!cachep)
return;
local_irq_save(flags);
debug_check_no_locks_freed(objp, cachep->object_size);
if (!(cachep->flags & SLAB_DEBUG_OBJECTS))
debug_check_no_obj_freed(objp, cachep->object_size);
__cache_free(cachep, objp, _RET_IP_);
local_irq_restore(flags);
trace_kmem_cache_free(_RET_IP_, objp);
EXPORT_SYMBOL(kmem_cache_free);五、扩展
1、内部碎片和外部碎片
(1)外部碎片
外部碎片指的是还没有被分配出去(不属于任何进程)但由于太小而无法分配给申请内存空间的新进程的内存空闲区域。外部碎片是除了任何已分配区域或页面外部的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。简单示例如下图:

如果某进程现在需要向操作系统申请地址连续的32K内存空间,注意是地址连续,实际上系统中当前共有10K+23K=33K空闲内存,但是这些空闲内存并不连续,所以不能满足进程的请求。这就是所谓的外部碎片,造成外部碎片的原因主要是进程或者系统频繁的申请和释放不同大小的一组连续页框。Linux操作系统中为了尽量避免外部碎片而采用了伙伴系统(Buddy System)算法。
(2)内部碎片
内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;内部碎片是处于区域内部或页面内部的存储块,占有这些区域或页面的进程并不使用这个存储块,而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。简单示例如下图:
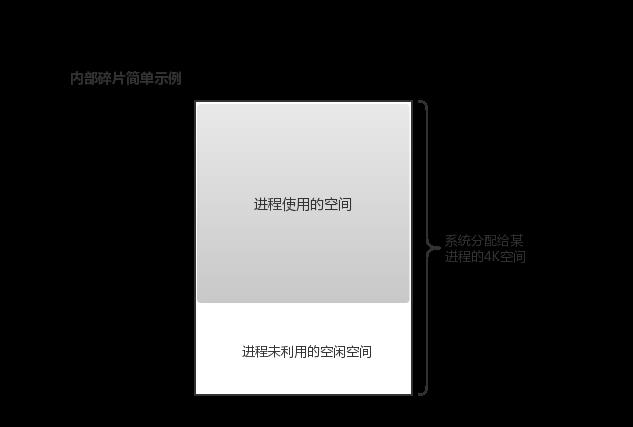
某进程向系统申请了3K内存空间,系统通过伙伴系统算法可能分配给进程4K(一个标准页面)内存空间,导致剩余1K内存空间无法被系统利用,造成了浪费。这是由于进程请求内存大小与系统分配给它的内存大小不匹配造成的。由于伙伴算法采用页框(Page Frame)作为基本内存区,适合于大块内存请求。在很多情况下,进程或者系统申请的内存都是小于4K(一个标准页面)的,依然采用伙伴算法必然会造成系统内存的极大浪费。为满足进程或者系统对小片内存的请求,对内存管理粒度更小的SLAB分配器就产生了。(注:Linux中的SLAB算法实际上是借鉴了Sun公司的Solaris操作系统中的SLAB模式)。
2、SLAB分配器初始化
slab分配器的初始化涉及到一个鸡与蛋的问题。为了初始化slab数据结构,内核需要很多远小于一页的内存区,很显然由kmalloc分配这种内存最合适,但是kmalloc只有在slab分配器初始化完才能使用。内核借助一些技巧来解决该问题。
kmem_cache_init函数被内核用来初始化slab分配器。它在伙伴系统启用后调用。在SMP系统中,启动CPU正在运行,其它CPU还未初始化,它要在smp_init之前调用。slab采用多步逐步初始化slab分配器,其工作过程:
- 创建第一个名为kmem_cache的slab缓存,此时该缓存的管理数据结构使用的是静态分配的内存。在slab分配器初始化完成后,会将这里使用的静态数据结构替换为动态分配的内存。
- 初始化其它的slab缓存,由于已经初始化了第一个slab缓存,因此这一步是可行。
将初始化过程由于“鸡与蛋”的问题而使用的静态数据结构替换为动态分配的。
3、slab替代品:slob和slub
尽管slab分配器对许多可能的工作负荷都工作良好, 但也有一些情形, 它无法提供最优性能. 如果某些计算机处于当前硬件尺度的边界上, 在此类计算机上使用slab分配会出现一些问题:微小的嵌入式系统, 配备有大量物理内存的大规模并行系统. 在第二种情况下, slab分配器所需的大量元数据可能成为一个问题:开发者称在大型系统上仅slab的数据结构就需要很多字节内存。对嵌入式系统来说, slab分配器代码量和复杂性都太高。
为处理此类情形, 在内核版本2.6开发期间, 增加了slab分配器的两个替代品:
(1)slob分配器
slob分配器进行了特别优化, 以便减少代码量. 它围绕一个简单的内存块链表展开(因此而得名). 在分配内存时, 使用了同样简单的最先适配算法.slob分配器只有大约600行代码, 总的代码量很小. 事实上, 从速度来说, 它不是最高效的分配器, 也肯定不是为大型系统设计的.
(2)slub分配器
slub分配器通过将页帧打包为组,并通过struct page中未使用的字段来管理这些组,试图最小化所需的内存开销。读者此前已经看到,这样做不会简化该结构的定义,但在大型计算机上slub比slab提供了更好的性能,说明了这样做是正确的.
由于slab分配是大多数内核配置的默认选项,我不会详细讨论备选的分配器. 但有很重要的一点需要强调:内核的其余部分无需关注底层选择使用了哪个分配器,所有分配器的前端接口都是相同的。
每个分配器都必须实现一组特定的函数, 用于内存分配和缓存:
kmalloc、__kmalloc和kmalloc_node // 一般的(特定于结点)内存分配函数.
kmem_cache_alloc、kmem_cache_alloc_node // 提供(特定于结点)特定类型的内核缓存.
本文在讨论slab分配器时,会讲解这些函数的行为. 使用这些标准函数, 内核可以提供更方便的函数, 而不涉及内存在内部具体如何管理. 举例来说, kcalloc为数组分配内存,而kzalloc分配一个填充字节0的内存区。
普通内核代码只需要包含slab.h,即可使用内存分配的所有标准内核函数。连编系统会保证使用编译时选择的分配器,来满足程序的内存分配请求。
4、分区页框
5、参阅:
优雅的slab内存分配器(一)——slab内存分配器基础知识
以上是关于Linux内存管理之SLAB内存分配器的主要内容,如果未能解决你的问题,请参考以下文章