Redis源码剖析 - Redis内置数据结构之压缩列表ziplist
Posted Fred^_^
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码剖析 - Redis内置数据结构之压缩列表ziplist相关的知识,希望对你有一定的参考价值。
原创作品,转载请标明:http://blog.csdn.net/Xiejingfa/article/details/51072326
在前面的一篇文章【Redis源码剖析】 - Redis内置数据结构之双向链表中,我们介绍了Redis封装的一种“传统”双向链表list,分别使用prev、next指针来指向当前节点的前一个节点和下一个节点。这种数据结构需要花费额外的空间存储两个指针,空间利用率不高。比如,考虑比较极端的情况,如果每个节点保存的只是一个char类型的字符,在32位机上每个节点需要占用9个字节,而其中只有1个字节用来存储数据,其余8个字节需要用来存储指针。为了解决这个问题,Redis提供了一种称作ziplist的数据结构,称作压缩列表。ziplist使用一串字符串来实现双向链表结构。与list结构相比,ziplist可以减少存储空间(主要是节省了链表指针的存储空间开销),ziplist在实现上并不存储上指向上一个链表节点和指向下一个链表节点的指针,而转为存储上一个节点长度和当前节点长度从而在大多数情况下节省很多空间开销。
ziplist结构主要定义在ziplist.h和ziplist.c两个文件中,下面我们就来看看ziplist在Redis中的实现。
1、ziplist的存储结构
ziplist的存储结构如下图:
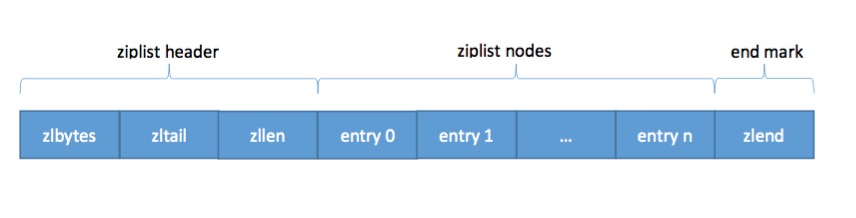
上图中各个域的作用如下:
- zlbytes是一个4字节无符号整型,存储的是整个ziplist占用的字节数。它主要用于重新分配内存时使用,这样就不必遍历整个列表以确定其长度。
- zltail是一个4字节无符号整型,存储的是链表最后一个节点的偏移值,即链表开头地址 + zltail的值为最后一个节点的起始地址。这样对链表尾部执行pop操作时就无需遍历链表(以找到最后一个节点)。
- zllen是一个2字节无符号整型,存储的是链表中的节点总数。当这个值超过2^16-2时就需要遍历整个链表来获取链表的节点总数
- entry是ziplist所保存的节点,下面会具体介绍。
- zlend是一个链表尾部的占位符,表示链表结束。它占用1个字节,值为255。
为了快速取出ziplist中各个域的数据,ziplist.c中定义了下面的宏操作:
/* Utility macros */
/* 下面是一些可以用于直接定位的工具宏 */
/* 访问ziplist的zlbytes字段 */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
/* 访问ziplist的zltail字段*/
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
/* 获取ziplist的zllen字段 */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
/* ziplist头部长度: 4字节的zlbytes + 4字节的zltail + 2字节的zllen */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
/* 获取ziplist的第一个节点的首地址 */
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
/* 获取ziplist的最后一个节点的首地址 */
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
/* 获取ziplist的结尾符 */
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)2、ziplist的节点结构
前面我们看到,一个ziplist可以包含多个节点(在ziplist称作entry),每个节点可以保存一个整数或一个字符数组(或称作字符串,但这里并不是C风格字符串,因为其结尾不含‘\\0’。为了方面后面我们统一称为字符串)。
节点的定义如下:
/* 压缩链表结构体 */
typedef struct zlentry
// prevrawlen为上一个链表节点占用的长度
// prevrawlensize为存储上一个链表节点的长度数值所需要的字节数
unsigned int prevrawlensize, prevrawlen;
// len为当前链表节点占用的长度
// lensize为存储当前链表节点长度数值所需要的字节数
unsigned int lensize, len;
// 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小
unsigned int headersize;
// 编码方式
unsigned char encoding;
// 压缩链表以字符串的形式保存,该指针指向当前节点起始位置
unsigned char *p;
zlentry;如果光看zlentry结构体的定义,我们很难想象每个节点在ziplist是如何存储的,这里我们暂且将zlentry抛在一边,先来看看节点在ziplist的存储结构。如下图:
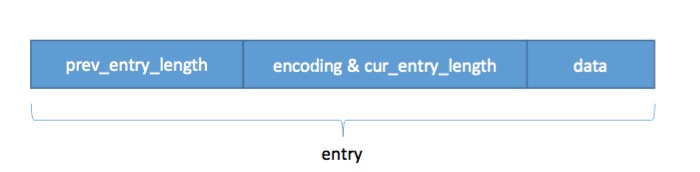
ziplist中的节点包括三部分信息:
(1)、第一部分存储的是上一个链表节点的长度prev_entry_length,利用这个值就可以通过指针运算直接跳转到前一个节点。
prev_entry_length域,也就是上一个链表节点的长度占用的字节数根据编码类型而定,可能是1个字节或者5个字节:
- 1字节:当前一个链表节点的长度值小于254时使用1个字节存储,该字节存储的数值就是上一个节点的长度值。
- 5字节:当前一个链表节点的长度值大于或等于254时使用5个字节存储,第1个字节的数值为254,表示上一个节点的长度值大于等于254接下来的4个字节才是真正的长度。
(2)第二部分存储的是编码类型encoding和当前节点的长度cur_entry_length。其中encoding域占用2个bit,这样encoding就有四种不同的取值,分别是00、01、10、11。redis规定如下:
- 如果encoding域的取值为11,表示整型编码,该节点数据域存储的是一个整型值。
- 如果encoding域的取值为00、01和10,表示字符串编码,该节点数据域存储的是一个字符串。
具体如下:
对于字符串编码,规则如下:
| 编码 | 编码长度 | 含义 |
|---|---|---|
| 00pppppp | 1 byte | 表示长度小于等于63(只有后六位存放字符串长度,2^6 - 1 = 63)字节的字符串,后6位用于存储字符串长度。 |
| 01pppppp,qqqqqqqq | 2 bytes | 表示长度小于等于16383(2^14 - 1)字节的字符串,后14用于存储字符串长度 |
| 10______,qqqqqqqq,rrrrrrrr,ssssssss,tttttttt | 5 bytes | 表示长度大于等于16384字节的字符串,前1个字节的后6位无意义,后4个字节用来存储字符串长度 |
对于整形编码,规则如下:
| 编码 | 编码长度 | 含义 |
|---|---|---|
| 11000000 | 1 byte | int16_t整型 |
| 11010000 | 1 byte | int32_t整型 |
| 11100000 | 1 byte | int64_t整型 |
| 11110000 | 1 byte | 24bit有符号整数 |
| 11111110 | 1 byte | 8bit有符号整型 |
| 1111xxxx | 1 byte | 4bit无符号整型,表示[0,12]范围的数 |
(3)、第三部分为数据data域,即该节点真正存放的数据,其类型由第二部分的encoding和cur_entry_length决定。
介绍了ziplist节点的存储结构,我们可以看到zlentry结构和节点在ziplist的真实的存储结构并不是一一对应的。为了便于理解我们可以将第一部分prev_entry_length域看做对prevrawlensize、prevrawlen字段的抽象,将第二部分cur_entry_length域看做是对lensize、len字段的抽象。另外,我们经常需要跳过节点的header部分(第一部分和第二部分)读取节点真正存储的数据,所以zlentry结构定义了headersize字段记录节点头部长度。我们看看ziplist怎么从一段字符数组转换为zlentry结构:
/* 将p指向的内容解析为一个链表节点zlentry结构并返回 */
static zlentry zipEntry(unsigned char *p)
zlentry e;
// 求出上一个节点的长度prevrawlen和存储该数值所占用的字节数prevrawlensize
ZIP_DECODE_PREVLEN(p, e.prevrawlensize, e.prevrawlen);
// 求出当前节点的长度len和存储该长度值所占用的字节数lensize,以及编码方式encoding
ZIP_DECODE_LENGTH(p + e.prevrawlensize, e.encoding, e.lensize, e.len);
e.headersize = e.prevrawlensize + e.lensize;
e.p = p;
return e;
到这里我们可以看到,整个ziplist的存储结构是这样的:
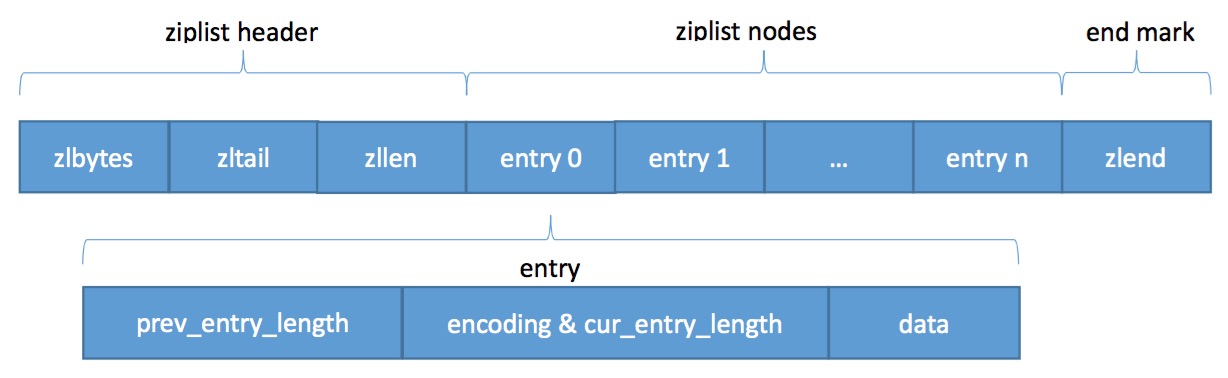
3、ziplist的几个关键操作
3.1、级联扩展操作__ziplistCascadeUpdate
当一个新的节点插入链表时,如果原节点的prevlen不足以保存新节点的长度,那么就需要对原节点的空间进行扩展,也就是从1个字节扩展到5个字节。特别是这种扩展操作又可能导致下一个节点需要扩展……如此反复,这种情况在多个连续节点的长度都接近254(上一节点长度小于254只要1个字节保存即可)的时候很可能发生。
__ziplistCascadeUpdate就是用来处理这种级联扩展操作。
另外,还可能出现相反的情况:因为插入节点的长度比较小而引起连续的缩小操作。但是,为了避免出现“扩展-缩小-扩展-缩小”这种“抖动”情况反复出现,redis对这种因插入节点的长度较小而引起的缩小操作采取“不处理”的策略,也就是任由prevlen比所需的长度长。
该函数返回更新后的ziplist,参数p指向需要扩展prevlensize的节点首地址。该函数具体如下:
static unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p)
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize;
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
// 从p指向的节点开始遍历到ziplist列表尾部
while (p[0] != ZIP_END)
// 取得当前节点
cur = zipEntry(p);
// 当前节点的占用的字节数
rawlen = cur.headersize + cur.len;
// 存储rawlen所需要的字节数
rawlensize = zipPrevEncodeLength(NULL,rawlen);
/* Abort if there is no next entry. */
// 如果到达表尾,直接退出
if (p[rawlen] == ZIP_END) break;
// 获得下一个节点
next = zipEntry(p+rawlen);
/* Abort when "prevlen" has not changed. */
// 如果下一个节点的prevlen等于当前节点的rawlen,则此后的节点都无需调整,直接退出
if (next.prevrawlen == rawlen) break;
// 下一个节点的长度空间不足,需要进行扩展操作
if (next.prevrawlensize < rawlensize)
/* The "prevlen" field of "next" needs more bytes to hold
* the raw length of "cur". */
// 下面的ziplistResize发生了空间的重新分配,所以需要记录p对于zl的偏移量
offset = p-zl;
// 求出需要扩展的字节数
extra = rawlensize-next.prevrawlensize;
zl = ziplistResize(zl,curlen+extra);
// ziplistResize发生了空间的重新分配,这里重新获取p指针
p = zl+offset;
/* Current pointer and offset for next element. */
// 新的下一个节点的首地址
np = p+rawlen;
noffset = np-zl;
/* Update tail offset when next element is not the tail element. */
// zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))为最后一个节点的首地址
// 如果下一个节点不是最后一个节点,发生扩展操作需要更新最后一个节点的偏移量
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np)
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
/* Move the tail to the back. */
// 这里将原节点的下一个节点的数据区域到ziplist尾部的全部数据向后偏移,空余出rawlensize个字节
// 用来存放上一个节点的长度
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
// 空余出来的rawlensize个字节用来存储上一个节点的长度
zipPrevEncodeLength(np,rawlen);
/* Advance the cursor */
// 指向下一个节点
p += rawlen;
// 更新当前节点的长度
curlen += extra;
else
// 如果下一节点的长度空间有冗余,则不进行压缩以防止“抖动”现象。
if (next.prevrawlensize > rawlensize)
/* This would result in shrinking, which we want to avoid.
* So, set "rawlen" in the available bytes. */
zipPrevEncodeLengthForceLarge(p+rawlen,rawlen);
else
zipPrevEncodeLength(p+rawlen,rawlen);
/* Stop here, as the raw length of "next" has not changed. */
break;
return zl;
3.2、删除节点操作
删除节点后也需要考虑级联扩展的情况。
/* Delete "num" entries, starting at "p". Returns pointer to the ziplist. */
/* 从p指针开始删除num个节点*/
static unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num)
unsigned int i, totlen, deleted = 0;
size_t offset;
int nextdiff = 0;
zlentry first, tail;
// 需要删除的首个节点
first = zipEntry(p);
for (i = 0; p[0] != ZIP_END && i < num; i++)
// 偏移到下一个节点
p += zipRawEntryLength(p);
// 统计待删除节点数量
deleted++;
// 得到待删除节点的字节总数
totlen = p-first.p;
if (totlen > 0)
// 注意此时p指向的是待删除节点后第一个不被删除的节点
if (p[0] != ZIP_END)
/* Storing `prevrawlen` in this entry may increase or decrease the
* number of bytes required compare to the current `prevrawlen`.
* There always is room to store this, because it was previously
* stored by an entry that is now being deleted. */
// 计算待删除的第一个节点first的prevrawlensize与p节点prevrawlensize的差值
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen);
// 根据nextdiff的值对p进行前移或后移操作,用来保存frist节点上一个节点的长度,即first.prevrawlen
p -= nextdiff;
// 删除后first节点前一个节点的下一个节点就是p节点,更新p节点的prevrawlen数值
zipPrevEncodeLength(p,first.prevrawlen);
/* Update offset for tail */
// 更新最后一个节点的偏移量
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
tail = zipEntry(p);
// 如果p节点不是尾节点,尾节点的偏移量还需要加上nextdiff值
if (p[tail.headersize+tail.len] != ZIP_END)
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
/* Move tail to the front of the ziplist */
// 删除first.p到p节点之间的节点,其实就是简单的数据移动操作
// 这里为什么要减1呢,因为zlend不需要处理,在后面的ziplistResize中重新设置了zlend
memmove(first.p,p,
intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
else
/* The entire tail was deleted. No need to move memory. */
// 如果已经删除到zlend,值最后一个节点就是first节点的前一个节点,需要更新其偏移量
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe((first.p-zl)-first.prevrawlen);
/* Resize and update length */
// 重新调整ziplist大小,更新其长度
offset = first.p-zl;
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff);
ZIPLIST_INCR_LENGTH(zl,-deleted);
p = zl+offset;
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
// 如果nextdiff的值不为0,说明p节点的长度发生改变,需要执行级联更新操作
if (nextdiff != 0)
zl = __ziplistCascadeUpdate(zl,p);
return zl;
3.3、插入操作
/* 在p节点前插入一个新节点。各参数的含义如下:
zl:ziplist首地址
p:插入位置
s:待插入字符串的首地址
slen:带插入字符串长度
*/
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen)
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END)
// 如果p节点后面还有节点,取出p节点前一个节点的长度信息和存储该长度值所需要的字节数信息
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
else
// 如果p节点为ziplist结束标识,则取出尾节点,即最后一个节点
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END)
prevlen = zipRawEntryLength(ptail);
/* See if the entry can be encoded */
// 尝试看能否将s保存为整数,如果可以则返回1,且value和encoding分别保存新值和编码信息
if (zipTryEncoding(s,slen,&value,&encoding))
/* 'encoding' is set to the appropriate integer encoding */
// 如果s可以保存为整数,则进一步计算保存该数值所需要的字节数
reqlen = zipIntSize(encoding);
else
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
// 如果s不能保存为整数,则直接使用其字符串长度
reqlen = slen;
/* We need space for both the length of the previous entry and
* the length of the payload. */
// 计算编码prevlen所需要的字节数,prevlen用于保存前一个节点的长度
reqlen += zipPrevEncodeLength(NULL,prevlen);
// 计算编码slen所需要的长度
reqlen += zipEncodeLength(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
// 当插入的位置不是ziplist尾部时,需要确保下一个节点(即p节点)的prevlen能够用来保存即将插入节点的长度
// 这里计算两者差值
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
/* Store offset because a realloc may change the address of zl. */
// ziplistResize操作会重新分配空间,需要事前记录p节点偏移量
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
// 重新取得p节点
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END)
/* Subtract one because of the ZIP_END bytes */
/* 将原来 p-nextdiff 开始的数据全部后移,中间出现reqlen个字节保存即将插入的数据
主要需要考虑一下几种情况:
nextdiff == 0:p节点中用来存储原先前一个节点长度信息的数据区域正好保存待插入节点的长度
nextdiff == 4:原先p节点只需要1个字节来存储上一个节点的长度,现在需要5个字节。那就将p-4后面的数据偏移到p+reqlen
nextdiff == -4:原先p节点需要5个字节来存储上一个节点的长度,现在只需要1个字节。那就将p+4后面的数据偏移到p+reqlen
*/
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
// 为p节点的prevlen设置新值,即待插入节点的长度
zipPrevEncodeLength(p+reqlen,reqlen);
/* Update offset for tail */
// 更新尾节点偏移量
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
tail = zipEntry(p+reqlen);
// 同样,如果p节点不是尾节点,尾节点的偏移量还需要加上nextdiff值
if (p[reqlen+tail.headersize+tail.len] != ZIP_END)
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
else
/* This element will be the new tail. */
// 如果p节点指向zlend,更新zltail值,待添加节点为尾部节点
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
// 同样,如果nextdiff的值不为0,说明原节点节点(此时的首地址为p+reqlen)的长度发生改变,需要执行级联更新操作
if (nextdiff != 0)
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
// 下面才是真正执行插入操作
/* Write the entry */
// 填写上一节点的长度
p += zipPrevEncodeLength(p,prevlen);
// 填写当前节点的长度
p += zipEncodeLength(p,encoding,slen);
// 根据编码方式执行相应的插入操作
if (ZIP_IS_STR(encoding))
memcpy(p,s,slen);
else
zipSaveInteger(p,value,encoding);
// 长度加1
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
4、小结
ziplist最关键的操作就是上面介绍的三个函数,这三个函数的重点其实就是“空间的再分配 + memmove操作维护后续节点的链接性”。剩余的一些我们就不一一分析了。我把注释版的代码贴在本文后面供大家参考。
这里总结一下ziplist的优缺点:
- 与list相比,ziplist最大的优点就是主要是节省了链表指针的存储空间开销,最好情况下只需要两个字节,这一点充分体现了“压缩”的特点。而且ziplist通过memmove操作来操作其维护的内存块,效率比较高。
- ziplist的缺点是每一次insert、delete节点等操作都涉及到内存的重新分配,所以如果对ziplist频繁地进行插入和删除操作,其效率又变得很低。
下面是完整的注释版代码(ziplist.c):
/* The ziplist is a specially encoded dually linked list that is designed
* to be very memory efficient. It stores both strings and integer values,
* where integers are encoded as actual integers instead of a series of
* characters. It allows push and pop operations on either side of the list
* in O(1) time. However, because every operation requires a reallocation of
* the memory used by the ziplist, the actual complexity is related to the
* amount of memory used by the ziplist.
* ziplist是一个经过特殊编码的双向链接表,其内存操作非常高效。ziplist可以存放字符串和整型,并
* 且它在头部和尾部支持O(1)的push和pop操作。但是每次操作涉及内存的重新分配释放,所以ziplist得
* 实际复杂度与其使用的内存空间相关
*
* ----------------------------------------------------------------------------
*
* ziplist的整体存储结构如下:
* ZIPLIST OVERALL LAYOUT:
* The general layout of the ziplist is as follows:
* <zlbytes><zltail><zllen><entry><entry><zlend>
*
* <zlbytes> is an unsigned integer to hold the number of bytes that the
* ziplist occupies. This value needs to be stored to be able to resize the
* entire structure without the need to traverse it first.
*
* zlbytes是一个4字节无符号整形,存储的是整个ziplist占用的字节数。它主要用于重新分配内存时使用,
* 这样就不必遍历整个列表以确定其长度。
*
* <zltail> is the offset to the last entry in the list. This allows a pop
* operation on the far side of the list without the need for full traversal.
* zltail是一个4字节无符号整形,存储的是链表最后一个节点的偏移值,即链表开头地址 + zltail的值为
* 最后一个节点的起始地址。这样对链表尾部执行pop操作时就无需遍历链表(以找到最后一个节点)
*
* <zllen> is the number of entries.When this value is larger than 2**16-2,
* we need to traverse the entire list to know how many items it holds.
* zllen是一个2字节无符号整形,存储的是链表中的节点总数。当这个值超过2^16-2时就需要遍历整个链表
* 来获取链表的节点总数
*
* <zlend> is a single byte special value, equal to 255, which indicates the
* end of the list.
* zlend是一个链表尾部的占位符,表示链表结束。它占用1个字节,值为255。
*
*
* 链表节点存储结构
* ZIPLIST ENTRIES:
* Every entry in the ziplist is prefixed by a header that contains two pieces
* of information. First, the length of the previous entry is stored to be
* able to traverse the list from back to front. Second, the encoding with an
* optional string length of the entry itself is stored.
*
* ziplist中每个节点的头部包含两部分的信息,第一个是上一个节点占用的长度,这样就可以从后往前遍历整个
* 列表。第二个是编码类型和当前链表节点占用的长度。
*
* 也就是说ziplist的节点结构为:
* <上一个链表结点占用的长度><编码方式 & 当前链表结点占用的长度><当前结点数据>
*
*
* The length of the previous entry is encoded in the following way:
* If this length is smaller than 254 bytes, it will only consume a single
* byte that takes the length as value. When the length is greater than or
* equal to 254, it will consume 5 bytes. The first byte is set to 254 to
* indicate a larger value is following. The remaining 4 bytes take the
* length of the previous entry as value.
*
* 上一个节点占用的长度按照如下的方式组织:
* (1)、当长度值小于254时使用1个字节存储,该字节存储的数值就是上一个节点的长度值。
* (2)、当长度值大于或等于254时使用5个字节存储,第1个字节的数值为254,表示上一个节点的长度值大于等于254
* 接下来的4个字节才是真正的长度
*
* The other header field of the entry itself depends on the contents of the
* entry. When the entry is a string, the first 2 bits of this header will hold
* the type of encoding used to store the length of the string, followed by the
* actual length of the string. When the entry is an integer the first 2 bits
* are both set to 1. The following 2 bits are used to specify what kind of
* integer will be stored after this header. An overview of the different
* types and encodings is as follows:
*
* 链表节点头部的第二部分内容取决于链表本身存储的内容。
* 当节点存储的是一个字符串,该部分的前2位有00、01、10共3中不同的类型
* 当节点存储的是一个整数,该部分的前2为都被设置为1(即为11),接下来的2位代表实际存储的是什么类型的整型数值
*
*
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* 长度小于等于63(只有后六位存放字符串长度,2^6 - 1 = 63)字节的字符串,后6位用于存储字符串长度。
* |01pppppp|qqqqqqqq| - 2 bytes
* String value with length less than or equal to 16383 bytes (14 bits).
* 长度小于等于16383(2^14 - 1)字节的字符串,后14用于存储字符串长度
* |10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
* String value with length greater than or equal to 16384 bytes.
* 长度大于等于16384字节的字符串,前1个字节的后6位无意义,后4个字节用来存储字符串长度
* |11000000| - 1 byte
* Integer encoded as int16_t (2 bytes).
* int16_t整型
* |11010000| - 1 byte
* Integer encoded as int32_t (4 bytes).
* int32_t整型
* |11100000| - 1 byte
* Integer encoded as int64_t (8 bytes).
* int64_t整型
* |11110000| - 1 byte
* Integer encoded as 24 bit signed (3 bytes).
* 24bit有符号整数
* |11111110| - 1 byte
* Integer encoded as 8 bit signed (1 byte).
* 8bit有符号整型
* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
* Unsigned integer from 0 to 12. The encoded value is actually from
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* 4bit无符号整数,表示从[0,12]范围的数
* |11111111| - End of ziplist.
*
* All the integers are represented in little endian byte order.
* 所有整数用小端模式表示
*
* ----------------------------------------------------------------------------
*
* Copyright (c) 2009-2012, Pieter Noordhuis <pcnoordhuis at gmail dot com>
* Copyright (c) 2009-2012, Salvatore Sanfilippo <antirez at gmail dot com>
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* * Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of Redis nor the names of its contributors may be used
* to endorse or promote products derived from this software without
* specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
* POSSIBILITY OF SUCH DAMAGE.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include <limits.h>
#include "zmalloc.h"
#include "util.h"
#include "ziplist.h"
#include "endianconv.h"
#include "redisassert.h"
#define ZIP_END 255 // ziplist结束标识
#define ZIP_BIGLEN 254 // ziplist节点头部第一部分需要使用到的开始标识,当上一个节点长度值大于或等于254时使用5个字节存储
/* Different encoding/length possibilities */
/* 所有编码方式汇总 */
#define ZIP_STR_MASK 0xc0 // 字符串编码 < 0xc0 (1100,0000)
#define ZIP_INT_MASK 0x30 // |11000000]
#define ZIP_STR_06B (0 << 6) // |00pppppp|
#define ZIP_STR_14B (1 << 6) // |01pppppp|qqqqqqqq|
#define ZIP_STR_32B (2 << 6) // |10______|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt|
#define ZIP_INT_16B (0xc0 | 0<<4) // |11000000| - int16_t整形类型 (2 bytes).
#define ZIP_INT_32B (0xc0 | 1<<4) // |11010000| - int32_t整形类型 (4 bytes).
#define ZIP_INT_64B (0xc0 | 2<<4) // |11100000| - int64_t整形类型t (8 bytes).
#define ZIP_INT_24B (0xc0 | 3<<4) // |11110000| - 24bit有符号整数 (3 bytes).
#define ZIP_INT_8B 0xfe // |11111110| - 8bit有符号整形 (1 byte).
/* 4 bit integer immediate encoding */
#define ZIP_INT_IMM_MASK 0x0f
#define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */
#define ZIP_INT_IMM_MAX 0xfd /* 11111101 */
#define ZIP_INT_IMM_VAL(v) (v & ZIP_INT_IMM_MASK)
#define INT24_MAX 0x7fffff
#define INT24_MIN (-INT24_MAX - 1)
/* Macro to determine type */
/* 判断是否是字符串编码 */
#define ZIP_IS_STR(enc) (((enc) & ZIP_STR_MASK) < ZIP_STR_MASK)
/* Utility macros */
/* 下面是一些可以用于直接定位的工具宏 */
/* 访问ziplist的zlbytes字段 */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
/* 访问ziplist的zltail字段*/
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
/* 获取ziplist的zllen字段 */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
/* ziplist头部长度: 4字节的zlbytes + 4字节的zltail + 2字节的zllen */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
/* 获取ziplist的第一个节点 */
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
/* 获取ziplist的最后一个节点 */
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
/* 获取ziplist的结尾符 */
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
/* We know a positive increment can only be 1 because entries can only be
* pushed one at a time. */
/* 更新ziplist长度,如果incr为正数则只能取1,因为每次只能push一个节点 */
#define ZIPLIST_INCR_LENGTH(zl,incr) \\
if (ZIPLIST_LENGTH(zl) < UINT16_MAX) \\
ZIPLIST_LENGTH(zl) = intrev16ifbe(intrev16ifbe(ZIPLIST_LENGTH(zl))+incr); \\
/* 压缩链表结构体 */
typedef struct zlentry
// prevrawlen为上一个链表节点占用的长度
// prevrawlensize为存储上一个链表节点的长度数值所需要的字节数
unsigned int prevrawlensize, prevrawlen;
// len为当前链表节点占用的长度
// lensize为存储当前链表节点长度数值所需要的字节数
unsigned int lensize, len;
// 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小
unsigned int headersize;
// 编码方式
unsigned char encoding;
// 压缩链表以字符串的形式保存,该指针指向当前节点起始位置
unsigned char *p;
zlentry;
/* Extract the encoding from the byte pointed by 'ptr' and set it into
* 'encoding'. */
/* 从ptr指向的字符串中提取出编码方式,可以以此判断是否为字符串编码 */
#define ZIP_ENTRY_ENCODING(ptr, encoding) do \\
(encoding) = (ptr[0]); \\
if ((encoding) < ZIP_STR_MASK) (encoding) &= ZIP_STR_MASK; \\
while(0)
/* Return bytes needed to store integer encoded by 'encoding' */
/* 返回指定整型编码方式所占用的字节长度 */
static unsigned int zipIntSize(unsigned char encoding)
switch(encoding)
case ZIP_INT_8B: return 1; // 1byte
case ZIP_INT_16B: return 2; // 2bytes
case ZIP_INT_24B: return 3; // 3bytes
case ZIP_INT_32B: return 4; // 4bytes
case ZIP_INT_64B: return 8; // 8bytes
default: return 0; /* 4 bit immediate */
assert(NULL);
return 0;
/* Encode the length 'rawlen' writing it in 'p'. If p is NULL it just returns
* the amount of bytes required to encode such a length. */
/* 将编码方式encoding和数据长度rawlen进行编码并写入p指向的缓冲区中,返回保存该编码所占用的字节数 */
static unsigned int zipEncodeLength(unsigned char *p, unsigned char encoding, unsigned int rawlen)
unsigned char len = 1, buf[5];
if (ZIP_IS_STR(encoding))
// 处理字符串编码
/* Although encoding is given it may not be set for strings,
* so we determine it here using the raw length. */
if (rawlen <= 0x3f)
// 字符串长度小于等于63,为00编码类型
if (!p) return len;
buf[0] = ZIP_STR_06B | rawlen;
else if (rawlen <= 0x3fff)
// 字符串长度小于等于16383(2^14 - 1),为01编码类型
len += 1;
if (!p) return len;
buf[0] = ZIP_STR_14B | ((rawlen >> 8) & 0x3f);
buf[1] = rawlen & 0xff;
else
// 长度大于等于16384,为10编码类型
len += 4;
if (!p) return len;
buf[0] = ZIP_STR_32B;
buf[1] = (rawlen >> 24) & 0xff;
buf[2] = (rawlen >> 16) & 0xff;
buf[3] = (rawlen >> 8) & 0xff;
buf[4] = rawlen & 0xff;
else
// 处理整形编码
/* Implies integer encoding, so length is always 1. */
if (!p) return len;
buf[0] = encoding;
/* Store this length at p */
memcpy(p,buf,len);
return len;
/* Decode the length encoded in 'ptr'. The 'encoding' variable will hold the
* entries encoding, the 'lensize' variable will hold the number of bytes
* required to encode the entries length, and the 'len' variable will hold the
* entries length. */
/* 从ptr指向的字符串中取出链表节点的编码、保存节点长度所需要的字节数、节点长度,并分别保存在
* encoding、lensize、len3个变量中。
*/
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do \\
ZIP_ENTRY_ENCODING((ptr), (encoding)); \\
if ((encoding) < ZIP_STR_MASK)
// 处理三种不同的字符串编码 \\
if ((encoding) == ZIP_STR_06B)
// 00编码方式,占用1个字节,该字节的后6位为字符串长度 \\
(lensize) = 1; \\
(len) = (ptr)[0] & 0x3f; // 通过bit操作获取字符串长度 \\
else if ((encoding) == ZIP_STR_14B)
// 01编码方式,占用2个字节 \\
(lensize) = 2;
/* 这里详细解释一下怎么通过位操作取得字符串长度(下面的操作类似,不再解释)
01编码方式,占用2个字节,第一个字节的后6bit和后一个字节的8bit表示字符串
长度。(ptr)[0] & 0x3f操作获取第一个字节的后6bit,然后左移8位再与第二个
字节相或就是字符串的长度
*/ \\
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; \\
else if (encoding == ZIP_STR_32B)
// 10编码方式,占用5个字节 \\
(lensize) = 5; \\
(len) = ((ptr)[1] << 24) | \\
((ptr)[2] << 16) | \\
((ptr)[3] << 8) | \\
((ptr)[4]); \\
else \\
assert(NULL); \\
\\
else
// 处理整形编码 \\
(lensize) = 1; \\
(len) = zipIntSize(encoding); \\
\\
while(0);
/* Encode the length of the previous entry and write it to "p". Return the
* number of bytes needed to encode this length if "p" is NULL. */
/* 将链表中上一个节点的长度值编码放入p指针指向的缓冲区中,返回编码后所占有的字节数 */
static unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len)
if (p == NULL)
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1;
else
if (len < ZIP_BIGLEN)
// 如果上一个节点的长度值小于254,只需要用一个字节表示即可
p[0] = len;
return 1;
else
// 当长度值大于或等于254时使用5个字节存储,第1个字节的数值为254,
// 表示上一个节点的长度值大于等于254,接下来的4个字节才是真正的长度
p[0] = ZIP_BIGLEN;
memcpy(p+1,&len,sizeof(len));
memrev32ifbe(p+1);
return 1+sizeof(len);
/* Encode the length of the previous entry and write it to "p". This only
* uses the larger encoding (required in __ziplistCascadeUpdate). */
/* 该函数与zipPrevEncodeLength功能相似,只不过它只处理len >= 254的情形 */
static void zipPrevEncodeLengthForceLarge(unsigned char *p, unsigned int len)
if (p == NULL) return;
p[0] = ZIP_BIGLEN;
memcpy(p+1,&len,sizeof(len));
memrev32ifbe(p+1);
/* Decode the number of bytes required to store the length of the previous
* element, from the perspective of the entry pointed to by 'ptr'. */
/* 获取存储上一个节点长度值所占用的字节数。这个很简单,只要看每个节点第一个字节的数据即可。
具体来说如果第一字节数值小于254,则只需要1个字节即可存储上一个节点的长度,否则需要5个
字节(第1个字节的数值为254,接下来的4个字节才是真正的长度)
*/
#define ZIP_DECODE_PREVLENSIZE(ptr, prevlensize) do \\
if ((ptr)[0] < ZIP_B以上是关于Redis源码剖析 - Redis内置数据结构之压缩列表ziplist的主要内容,如果未能解决你的问题,请参考以下文章