AlexNet原理及Tensorflow实现
Posted yqtaowhu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlexNet原理及Tensorflow实现相关的知识,希望对你有一定的参考价值。
AlexNet的出现点燃了深度学习的热潮,下面对其进行介绍,并使用tensorflow实现.
1. AlexNet网络结构
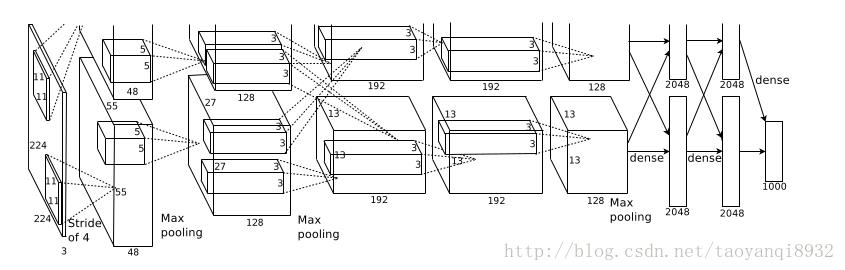
图片来源:AlexNet的论文
整个网络有8个需要训练的层,前5个为卷积层,最后3层为全连接层.
第一个卷积层
输入的图片大小为:224*224*3
第一个卷积层为:11*11*96即尺寸为11*11,有96个卷积核,步长为4,卷积层后跟ReLU,因此输出的尺寸为 224/4=56,去掉边缘为55,因此其输出的每个feature map 为 55*55*96,同时后面跟LRN层,尺寸不变.
最大池化层,核大小为3*3,步长为2,因此feature map的大小为:27*27*96.
第二层卷积层
输入的tensor为27*27*96
卷积和的大小为: 5*5*256,步长为1,尺寸不会改变,同样紧跟ReLU,和LRN层.
最大池化层,和大小为3*3,步长为2,因此feature map为:13*13*256
第三层至第五层卷积层
输入的tensor为13*13*256
第三层卷积为 3*3*384,步长为1,加上ReLU
第四层卷积为 3*3*384,步长为1,加上ReLU
第五层卷积为 3*3*256,步长为1,加上ReLU
第五层后跟最大池化层,核大小3*3,步长为2,因此feature map:6*6*256
第六层至第八层全连接层
接下来的三层为全连接层,分别为:
1. FC : 4096 + ReLU
2. FC:4096 + ReLU
3. FC: 1000
最后一层为softmax为1000类的概率值.
2. AlexNet中的trick
AlexNet将CNN用到了更深更宽的网络中,其效果分类的精度更高相比于以前的LeNet,其中有一些trick是必须要知道的.
ReLU的应用
AlexNet使用ReLU代替了Sigmoid,其能更快的训练,同时解决sigmoid在训练较深的网络中出现的梯度消失,或者说梯度弥散的问题.
Dropout随机失活
随机忽略一些神经元,以避免过拟合,
重叠的最大池化层
在以前的CNN中普遍使用平均池化层,AlexNet全部使用最大池化层,避免了平均池化层的模糊化的效果,并且步长比池化的核的尺寸小,这样池化层的输出之间有重叠,提升了特征的丰富性.
提出了LRN层
局部响应归一化,对局部神经元创建了竞争的机制,使得其中响应小打的值变得更大,并抑制反馈较小的.
使用了GPU加速计算
使用了gpu加速神经网络的训练
数据增强
使用数据增强的方法缓解过拟合现象.
3. Tensorflow实现AlexNet
下面是tensorflow的开源实现:https://github.com/tensorflow/models
AlexNet训练非常耗时,因此只定义网络结构,并进行前向后向的测试.这里自己使用的是CPU运行的…
首先定义一个接口,输入为图像,输出为第五个卷积层最后的池化层的数据,和每一个层的参数信息.都很简单,如果不懂可以参考tensorflow实战这本书或者共同交流.
def print_activations(t):
print(t.op.name, ' ', t.get_shape().as_list())上面的函数为输出当前层的参数的信息.下面是我对开源实现做了一些参数上的修改,代码如下:
def inference(images):
"""Build the AlexNet model.
Args:
images: Images Tensor
Returns:
pool5: the last Tensor in the convolutional component of AlexNet.
parameters: a list of Tensors corresponding to the weights and biases of the
AlexNet model.
"""
parameters = []
# conv1
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 96], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[96], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
parameters += [kernel, biases]
# lrn1
# TODO(shlens, jiayq): Add a GPU version of local response normalization.
# pool1
pool1 = tf.nn.max_pool(conv1,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool1')
print_activations(pool1)
# conv2
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 96, 256], dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)
# pool2
pool2 = tf.nn.max_pool(conv2,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool2')
print_activations(pool2)
# conv3
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)
# conv4
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 384],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)
# conv5
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256],
dtype=tf.float32,
stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32),
trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)
# pool5
pool5 = tf.nn.max_pool(conv5,
ksize=[1, 3, 3, 1],
strides=[1, 2, 2, 1],
padding='VALID',
name='pool5')
print_activations(pool5)
return pool5, parameters测试的函数:
image是随机生成的数据,不是真实的数据
def run_benchmark():
"""Run the benchmark on AlexNet."""
with tf.Graph().as_default():
# Generate some dummy images.
image_size = 224
# Note that our padding definition is slightly different the cuda-convnet.
# In order to force the model to start with the same activations sizes,
# we add 3 to the image_size and employ VALID padding above.
images = tf.Variable(tf.random_normal([FLAGS.batch_size,
image_size,
image_size, 3],
dtype=tf.float32,
stddev=1e-1))
# Build a Graph that computes the logits predictions from the
# inference model.
pool5, parameters = inference(images)
# Build an initialization operation.
init = tf.global_variables_initializer()
# Start running operations on the Graph.
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC'
sess = tf.Session(config=config)
sess.run(init)
# Run the forward benchmark.
time_tensorflow_run(sess, pool5, "Forward")
# Add a simple objective so we can calculate the backward pass.
objective = tf.nn.l2_loss(pool5)
# Compute the gradient with respect to all the parameters.
grad = tf.gradients(objective, parameters)
# Run the backward benchmark.
time_tensorflow_run(sess, grad, "Forward-backward")
输出的结果为:
下面为输出的尺寸,具体的分析过程上面已经说的很详细了.
conv1 [128, 56, 56, 96]
pool1 [128, 27, 27, 96]
conv2 [128, 27, 27, 256]
pool2 [128, 13, 13, 256]
conv3 [128, 13, 13, 384]
conv4 [128, 13, 13, 384]
conv5 [128, 13, 13, 256]
pool5 [128, 6, 6, 256]
下面是训练的前后向耗时,可以看到后向传播比前向要慢3倍.
2017-05-02 15:40:53.118788: step 0, duration = 3.969
2017-05-02 15:41:30.003927: step 10, duration = 3.550
2017-05-02 15:42:07.242987: step 20, duration = 3.797
2017-05-02 15:42:44.610630: step 30, duration = 3.487
2017-05-02 15:43:20.021931: step 40, duration = 3.535
2017-05-02 15:43:55.832460: step 50, duration = 3.687
2017-05-02 15:44:31.803954: step 60, duration = 3.567
2017-05-02 15:45:08.156715: step 70, duration = 3.803
2017-05-02 15:45:44.739322: step 80, duration = 3.584
2017-05-02 15:46:20.349876: step 90, duration = 3.569
2017-05-02 15:46:53.242329: Forward across 100 steps, 3.641 +/- 0.130 sec / batch
2017-05-02 15:49:01.054495: step 0, duration = 11.493
2017-05-02 15:50:55.424543: step 10, duration = 10.905
2017-05-02 15:52:47.021526: step 20, duration = 11.797
2017-05-02 15:54:42.965286: step 30, duration = 11.559
2017-05-02 15:56:36.329784: step 40, duration = 11.185
2017-05-02 15:58:32.146361: step 50, duration = 11.945
2017-05-02 16:00:21.971351: step 60, duration = 10.887
2017-05-02 16:02:10.775796: step 70, duration = 10.914
2017-05-02 16:04:07.438658: step 80, duration = 11.409
2017-05-02 16:05:56.403530: step 90, duration = 10.915
2017-05-02 16:07:34.297486: Forward-backward across 100 steps, 11.247 +/- 0.448 sec / batch完整的代码和测试在我的github:https://github.com/yqtaowhu/MachineLearning
参考资料
- ImageNet Classification with Deep Convolutional Neural Networks
- https://github.com/tensorflow/models
- tensorflow实战
- http://www.cnblogs.com/yymn/p/4553839.html
以上是关于AlexNet原理及Tensorflow实现的主要内容,如果未能解决你的问题,请参考以下文章