mycat
Posted 丶落幕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mycat相关的知识,希望对你有一定的参考价值。
mycat
1 概述
1.1 mycat是什么
mycat是数据库中间件
1、数据库中间件 中间件:是一类连接软件组件和应用的计算机软件,以便于软件各部件之间的沟通。 例子:Tomcat,web中间件。 数据库中间件:连接java应用程序和数据库
2、为什么要用Mycat?
- Java与数据库紧耦合
- 高访问量高并发对数据库的压力。
- 读写请求数据不一致
1.2 能干什么
- 读写分离
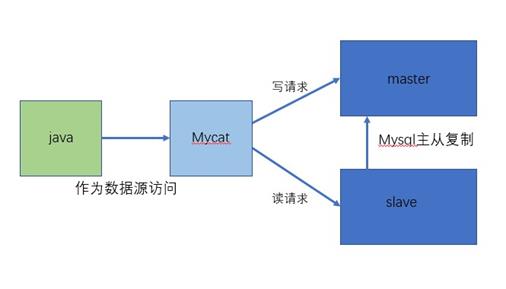
- 数据分片 垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)
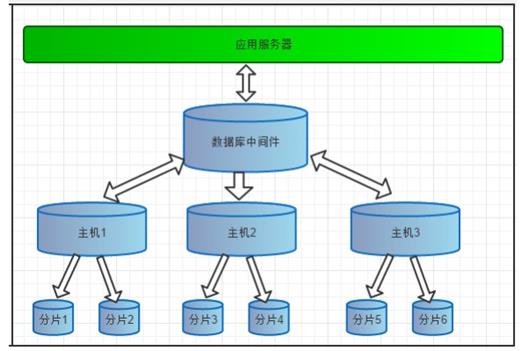
- 多数据源整合
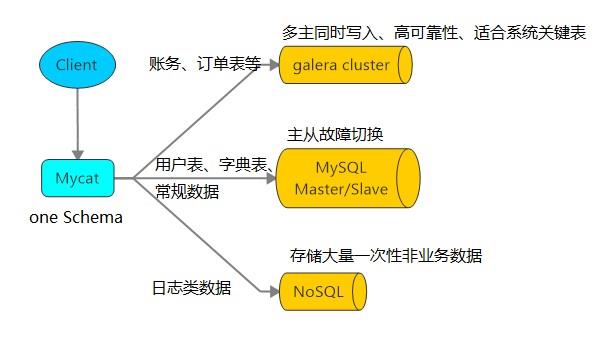
1.3 原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL 语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户
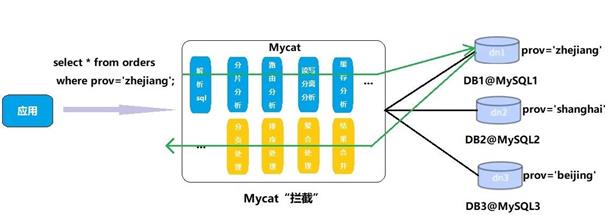
这种方式把数据库的分布式从代码中解耦出来,程序员察觉不出来后台使用 Mycat 还是mysql。
2 安装启动
2.1 配置读写分离
#解压
tar -zxf Mycat-server-1.6.7.1-release-20190627191042-linux.tar.gz
#移动
mv mycat/ /opt/
#进入配置文件目录
cd mycat/conf/
三个配置文件
-
schema.xml:定义逻辑库,表、分片节点等内容
-
rule.xml:定义分片规则
-
server.xml:定义用户以及系统相关变量,如端口等
#编辑配置文件
vim schema.xml
先不配置mysql主从复制
将schema.xml配置文件内容替换成以下内容(这里mysql是用docker起的)
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!--逻辑库-->
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="testdb" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!--写主机-->
<writeHost host="hostM1" url="192.168.59.145:3306" user="root"
password="root">
<!--读主机-->
<readHost host="hostS2" url="192.168.59.145:3307" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
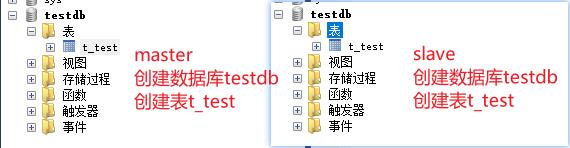
在主从mysql都创建testdb数据库并创建表
#进入启动目录
cd /opt/mycat/bin/
#以控制台方式启动
./mycat console
#后台启动
./mycat start
两个端口: 9066(用于后台管理) 8066(数据处理)
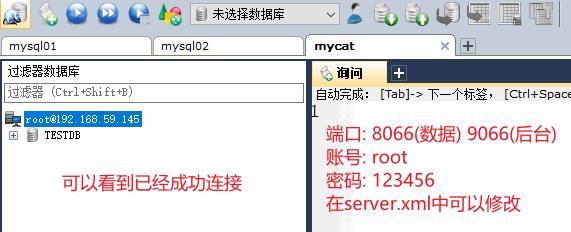
测试(在mycat TESRDB 中执行)
-- 测试1:插入数据
INSERT INTO `t_test` VALUES(1,'zs');
-- 测试2:查询数据
SELECT * FROM `t_test`;
注意: 这时候查询发现可以查到数据,然后我就以为自己配置有问题,经过2个小时的查找,我找到了这个
balance:
-
balance=“0”, 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
-
balance=“1”,全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从 模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
-
balance=“2”,所有读操作都随机的在 writeHost、readhost 上分发。
-
balance=“3”,所有读请求随机的分发到 readhost 执行,writerHost 不负担读压力
writeType:
-
writeType=“0”: 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个
-
writeType=“1”,所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐 #writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties
switchType:
- 1 默认值,自动切换。
- -1 表示不自动切换
- 2 基于 MySQL 主从同步的状态决定是否切换。
将balance的值改为3以后重启mycat,发现确实查不到数据了
2.2 配置mysql的主从复制
logbin日志的三种格式
STATEMENT: 每一条会修改数据的sql都会记录在binlog中。ROW: 不记录sql语句上下文相关信息,仅保存哪条记录被修改MIXED: 是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog
2.2 配置mysql的双主双从
| 角色 | ip |
|---|---|
| master01 | 192.168.59.145:3306 |
| slave01 | 192.168.59.145:3307 |
| master02 | 192.168.59.145:3308 |
| slave02 | 192.168.59.145:3309 |
启动4个mysql,用docker启动
#启动master01
docker run -d -p 3306:3306 --name mysql-m01 --net mynet -v /mydata/mysql-m01/log:/var/log/mysql -v /mydata/mysql-m01/data:/var/lib/mysql -v /mydata/mysql-m01/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root mysql:5.7
#启动slave01
docker run -d -p 3307:3306 --name mysql-s01 --net mynet -v /mydata/mysql-s01/log:/var/log/mysql -v /mydata/mysql-s01/data:/var/lib/mysql -v /mydata/mysql-s01/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root mysql:5.7
#启动master02
docker run -d -p 3308:3306 --name mysql-m02 --net mynet -v /mydata/mysql-m02/log:/var/log/mysql -v /mydata/mysql-m02/data:/var/lib/mysql -v /mydata/mysql-m02/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root mysql:5.7
#启动slave02
docker run -d -p 3309:3306 --name mysql-s02 --net mynet -v /mydata/mysql-s02/log:/var/log/mysql -v /mydata/mysql-s02/data:/var/lib/mysql -v /mydata/mysql-s02/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root mysql:5.7
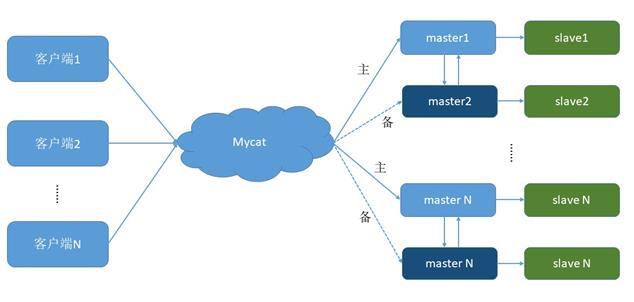
一个主机 m1 用于处理所有写请求,它的从机 s1 和另一台主机 m2 还有它的从机 s2 负责所有读请求。当 m1 主机宕机后,m2 主机负责写请求,m1、m2 互为备机
修改master01配置文件
vi /mydata/mysql-m01/conf/my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
#开启日志
log-bin=mysql-bin
#选择row模式
binlog-format=ROW
#设置服务id,主从不能一致
server-id=1
#设置需要复制的数据库(不设置则代表同步除屏蔽外的所有数据库)
#binlog-do-db=需要复制的主数据库名字
#屏蔽系统库同步
binlog_ignore_db=mysql
binlog_ignore_db=information_schema
binlog_ignore_db=performance_schema
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
#表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1 .. 65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1 .. 65535
auto-increment-offset=1
修改master02配置文件(复制m1的配置,并做如下修改,其他不变)
vi /mydata/mysql-m02/conf/my.cnf
server-id=3
auto-increment-offset=2
修改slave01配置文件
vi /mydata/mysql-s01/conf/my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
character-set-server=utf8
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
skip-name-resolve
#启用中继日志
relay-log=mysql-relay
#设置服务id,主从不能一致
server-id=2
#设置需要复制的数据库(不设置则代表同步除屏蔽外的所有数据库)
#binlog-do-db=需要复制的主数据库名字
修改slave02配置文件(复制s1的配置,并做如下修改,其他不变)
vi /mydata/mysql-s02/conf/my.cnf
server-id=4
重启服务
docker restart $(docker ps -aq)
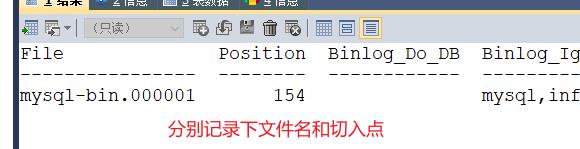
查看master01和master02的master状态
SHOW MASTER STATUS
slave01连接master01,slave02连接master02
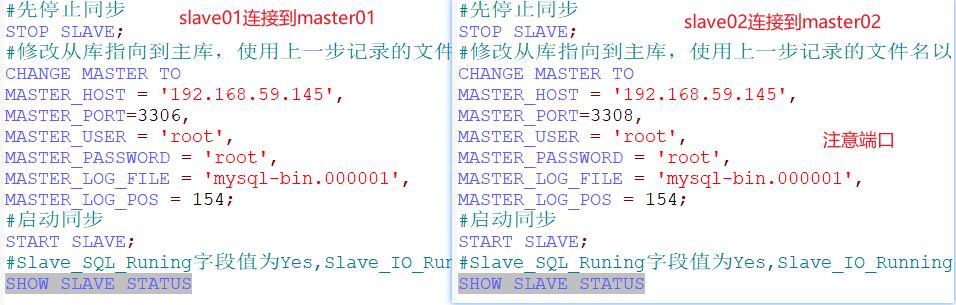
#先停止同步
STOP SLAVE;
#修改从库指向到主库,使用上一步记录的文件名以及位点
CHANGE MASTER TO
MASTER_HOST = '192.168.59.145',
MASTER_PORT=3306,
MASTER_USER = 'root',
MASTER_PASSWORD = 'root',
MASTER_LOG_FILE = 'mysql-bin.000001',
MASTER_LOG_POS = 154;
#启动同步
START SLAVE;
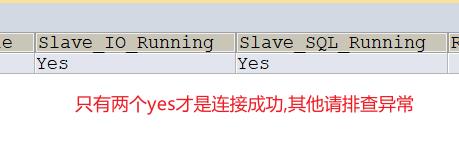
#Slave_SQL_Runing字段值为Yes,Slave_IO_Running字段值为Connecting,表示同步配置成功。
SHOW SLAVE STATUS
#注意 如果之前此从库已有主库指向 需要先执行以下命令清空
#STOP SLAVE IO_THREAD FOR CHANNEL '';
#reset slave all;
master01和master02相互复制(互为备机)
即把slave02上面的命令放在master01上运行一遍,让master01连接master02
然后把slave01上面的命令放在master02上运行一遍,让master02连接master01
可能有点绕,就是让master01和master02互为主从
测试: 在master01上创建数据库testdb,创建表mytbl

也可以测试数据插入,但是要注意,增删改操作必须要master执行,如果在slave执行,会造成数据不一致而断开主从复制
2.3 mycat实现双主双从读写分离
修改mycat配置文件schema.xml
注意: 此时balance值为1 ,还有host不能重名
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host1" database="testdb" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.59.145:3306" user="root"
password="root">
<readHost host="hostS1" url="192.168.59.145:3307" user="root" password="root" />
</writeHost>
<writeHost host="hostM2" url="192.168.59.145:3308" user="root"
password="root">
<readHost host="hostS2" url="192.168.59.145:3309" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
启动mycat测试
- 测试1: 只能测试插入了,因为是单机搭的伪集群,所以不能像视频里面那样测试了,插入没问题应该就没啥大问题了
- 测试2: 高可用测试,停止master01,然后测试mycat是否能进行写入操作
docker stop mysql-m01
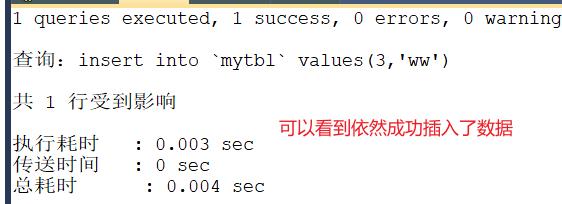
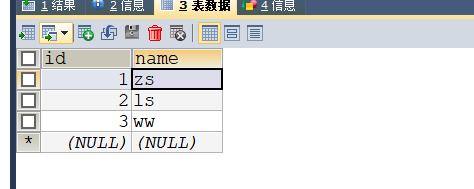
再启动master01,会发现,数据同步了,master01沦为读主机,master02自动成为写主机
docker start mysql-m01
3 垂直拆分-分库
删除之前双主双从环境,重新布置环境,反正docker搞起来也快
启动两台mysql( mysql01:3306 和 mysql02:3307 ),不需要主从复制,所以 balance 为 0
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2" ></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="orders" />
<dataNode name="dn2" dataHost="host2" database="orders" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.59.145:3306" user="root"
password="root">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.59.145:3307" user="root"
password="root">
</writeHost>
</dataHost>
</mycat:schema>
在mysql01和mysql02上面分别创建数据库orders
启动mycat,连接mycat,并创建表,只能用sql语句创建,不然会报错(因为它是逻辑库)
#客户表 rows:20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
#订单表 rows:600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
#订单详细表 rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
#订单状态字典表 rows:20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);
结论: 只有customer表被创建在了dn2数据源上.其他表都被创建在了dn1数据源上
4 水平拆分-分表
4.1 实现分表
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据
简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中
修改配置文件mycat配置文件schema.xml
<table name="orders" dataNode="dn1,dn2" rule="mod_rule" ></table>

修改配置文件rule.xml(在下面规则中,复制一个,修修改改就可以了)
<tableRule name="mod_rule">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>

因为之前的垂直拆分,mysql02(也就是dn2)上并没有orders这张表,所以需要在mysql02中创建orders表
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
启动mycat并测试插入数据,规则是customer_id%2
INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
以上是关于mycat的主要内容,如果未能解决你的问题,请参考以下文章