深度学习:batch_size和学习率 及如何调整
Posted -柚子皮-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习:batch_size和学习率 及如何调整相关的知识,希望对你有一定的参考价值。
学习率衰减
1 在神经网络的训练过程中,当accuracy出现震荡或loss不再下降时,进行适当的学习率衰减是一个行之有效的手段,很多时候能明显提高accuracy。
2 经验法则是,如果batch size加倍,那么学习率就加倍。
分布式训练时的batch_size:需要将batch_size/num_process。divide the batch size by the number of replicas in order to maintain the overall batch size of 需要的值.[PyTorch:模型训练-分布式训练]
[深度学习:梯度消失和梯度爆炸]时batch_size和学习度的调整。
随时查看学习率的值
param_groups:optimizer通过param_group来管理参数组,param_group中保存了参数组及其对应的学习率、动量等等。
方法1:
optimizer.param_groups[0]['lr']。
方法2:
如果想要每次迭代都实时打印学习率,这样可以每次step都能知道更新的最新学习率,可以使用
scheduler.get_lr()
它返回一个学习率列表,由参数组中的不同学习率组成,可通过列表索引来得到不同参数组中的学习率。
Pytorch中几种学习率调整(衰减)方法
使用库函数进行调整; 自定义库函数; 手动调整。
使用库函数进行学习率调整
Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现。pytorch提供的学习率调整策略分为三大类,分别是:
(1)有序调整:等间隔调整(Step),多间隔调整(MultiStep),指数衰减(Exponential),余弦退火(CosineAnnealing);
(2)自适应调整:依训练状况伺机而变,通过监测某个指标的变化情况(loss、accuracy),当该指标不怎么变化时,就是调整学习率的时机(ReduceLROnPlateau);
(3)自定义调整:通过自定义关于epoch的lambda函数调整学习率(LambdaLR)。
在每个epoch的训练中,使用scheduler.step()语句进行学习率更新,此方法类似于optimizer.step()更新模型参数(lz:scheduler只是在optimizer外面进行了封装),即一次epoch对应一次scheduler.step()。但在mini-batch训练中,每个mini-bitch对应一个optimizer.step()。
(1) 等间隔调整学习率 StepLR
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
每训练step_size个epoch,学习率调整为lr=lr*gamma.
以下内容中都将epoch和step对等,因为每个epoch中只进行一次scheduler.step(),实则该step指scheduler.step()中的step, 即step_size指scheduler.step()进行的次数。
参数:
- optimizer: 神经网络训练中使用的优化器,如optimizer=torch.optim.SGD(...)
- step_size(int): 学习率下降间隔数,单位是epoch,而不是iteration.
- gamma(float): 学习率调整倍数,默认为0.1
- last_epoch(int): 上一个epoch数,这个变量用来指示学习率是否需要调整。当last_epoch符合设定的间隔时,就会对学习率进行调整;当为-1时,学习率设置为初始值。
等间隔调整学习率:step_size=30, gamma=0.1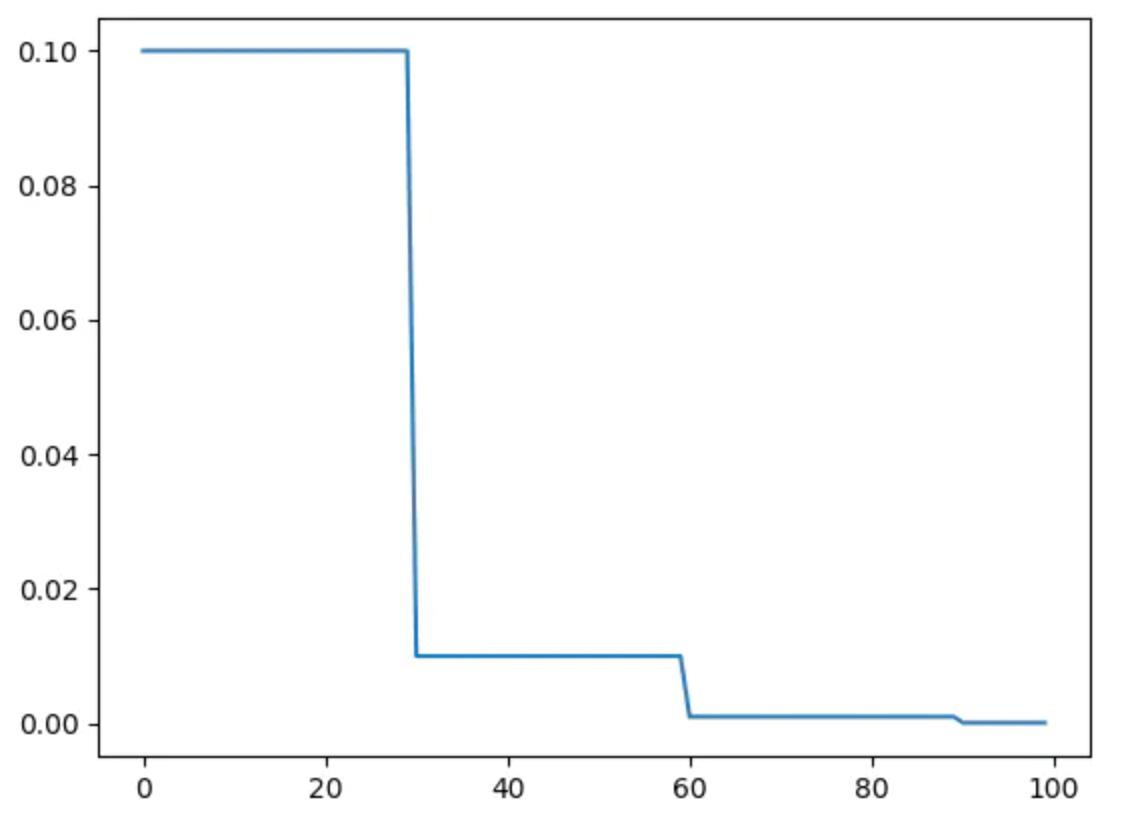
示例1:
示例
import torch.optim as optim
from torch.optim import lr_scheduler
# 训练前的初始化
optimizer = optim.Adam(net.parameters(), lr=0.001)
#学习率衰减
scheduler = lr_scheduler.StepLR(optimizer, 10, 0.1) # # 每过10个epoch,学习率乘以0.1
# 训练过程中
for n in n_epoch:
scheduler.step()
...
示例2:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
def train(...):
for i, data in enumerate(train_loader):
......
y_ = model(x)
loss = criterion(y_,y)
loss.backward()
optimizer.step()
......
for epoch in range(epochs):
scheduler.step()
train(...)
test(...)
(2) 多间隔调整学习率 MultiStepLR
跟(1)类似,但学习率调整的间隔并不是相等的,如epoch=10时调整一次,epoch=30时调整一次,epoch=80时调整一次…
torch.optim.lr_sheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
参数:
milestone(list): 一个列表参数,表示多个学习率需要调整的epoch值,如milestones=[10, 30, 80].
其它参数同(1)。
多间隔调整学习率:milestones=[10, 30, 80], gamma=0.1

(3) 指数衰减调整学习率 ExponentialLR
学习率呈指数型衰减,每训练一个epoch,lr=lrgamma*epoch,即
torch.optim.lr_sheduler.ExponentialLR(optimizer, gamma, last_epoch)
参数:
gamma(float):学习率调整倍数的底数,指数为epoch,初始值我lr, 倍数为
其它参数同上。
指数衰减调整学习率:gamma=0.9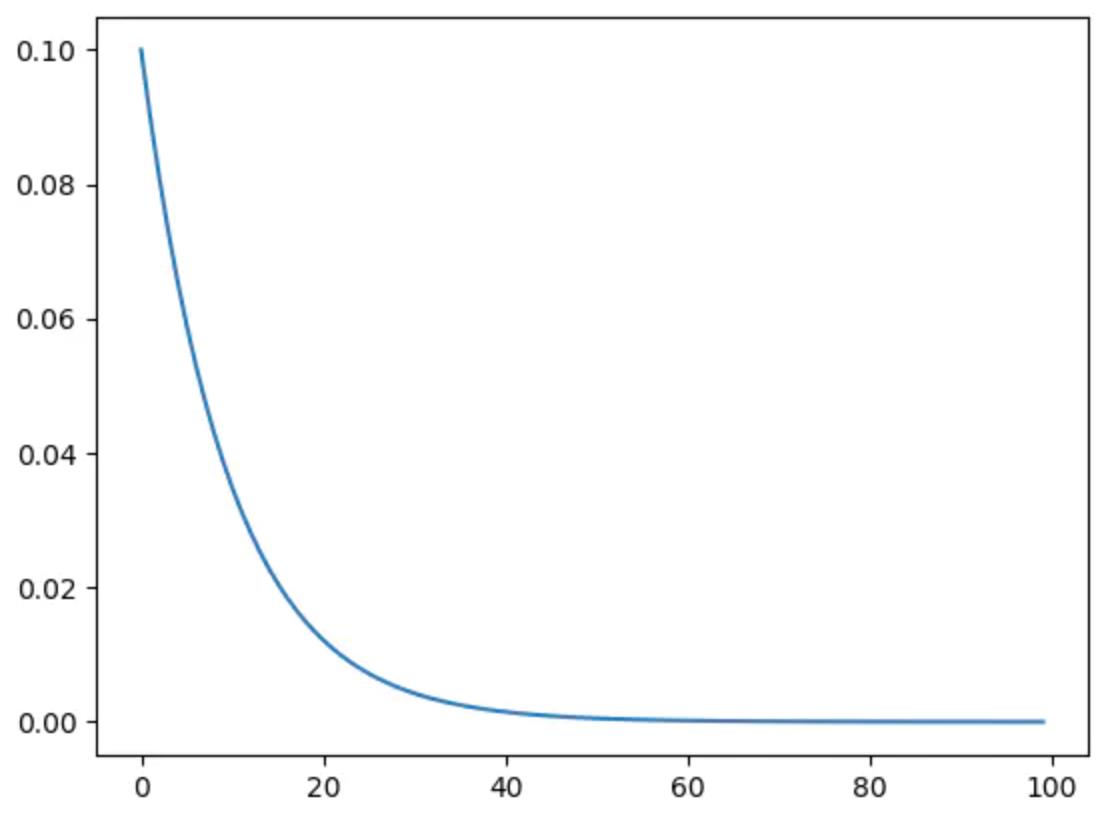
(4) 余弦退火函数调整学习率:
学习率呈余弦函数型衰减,并以2*T_max为余弦函数周期,epoch=0对应余弦型学习率调整曲线的,x=0, y_max = lr, epoch=T_max对应余弦型学习率调整曲线的x = pi, y_min = eta_min处,随着epoch>T_max,学习率随epoch增加逐渐上升,整个走势同cos(x)。
torch.optim.lr_sheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
参数:
- T_max(int): 学习率下降到最小值时的epoch数,即当epoch=T_max时,学习率下降到余弦函数最小值,当epoch>T_max时,学习率将增大;
- eta_min: 学习率调整的最小值,即epoch=T_max时,lr_min = eta_min, 默认为0.
其它参数同上。
学习率余弦衰减:T_max=100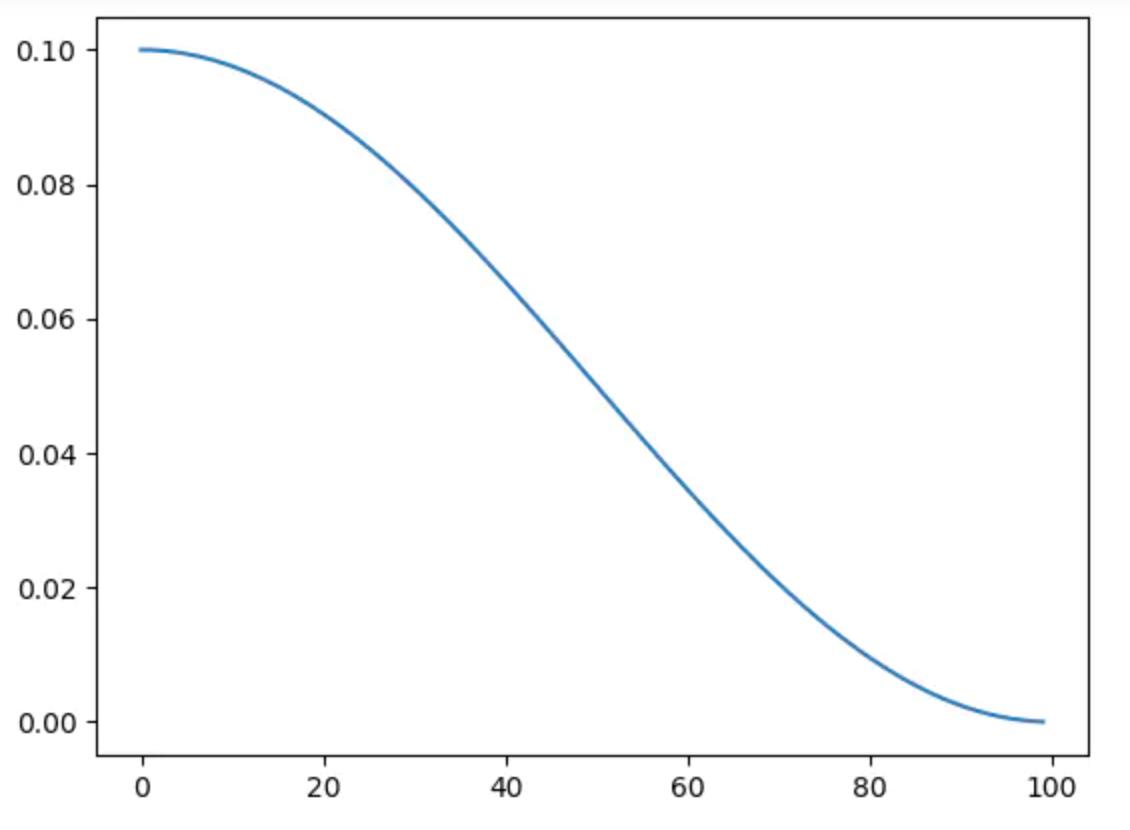
(5) 根据指标调整学习率 ReduceLROnPlateau
不依赖epoch更新学习率:lr_scheduler.ReduceLROnPlateau()提供了基于训练中某些测量值使学习率动态下降的方法。当某指标(loss或accuracy)在最近几个epoch中都没有变化(下降或升高超过给定阈值)时,调整学习率。如当验证集的loss不再下降是,调整学习率;或监察验证集的accuracy不再升高时,调整学习率。
torch.optim.lr_sheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10,
verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
参数:
- mode(str): 模式选择,有min和max两种模式,min表示当指标不再降低(如监测loss),max表示当指标不再升高(如监测accuracy)。参数 mode='min' 还是'max',取决于优化的是损失还是准确率,即使用
scheduler.step(loss)还是scheduler.step(acc)。 - factor(float): 学习率调整倍数,同前面的gamma,当监测指标达到要求时,lr=lr×factor。
- patience(int): 忍受该指标多少个epoch不变化,当忍无可忍时,调整学习率。
- verbose(bool): 是否打印学习率信息,print( 'Epoch :5d reducing learning rate of group to :.4e.'.format(epoch, i, new_lr), 默认为False, 即不打印该信息。
- threshold_mode (str): 选择判断指标是否达最优的模式,有两种模式:rel 和 abs.
当threshold_mode == rel, 并且 mode == max时,dynamic_threshold = best * (1 + threshold);
当threshold_mode == rel, 并且 mode == min时,dynamic_threshold = best * (1 - threshold);
当threshold_mode == abs, 并且 mode == max时,dynamic_threshold = best + threshold;
当threshold_mode == abs, 并且 mode == min时,dynamic_threshold = best - threshold; - threshold(float): 配合threshold_mode使用。
- cooldown(int): “冷却时间”,当调整学习率之后,让学习率调整策略冷静一下,让模型在训练一段时间,再重启监测模式。
- min_lr(float or list): 学习率下限,可为float,或者list,当有多个参数组时,可用list进行设置。
- eps(float): 学习率衰减的最小值,当学习率的变化值小于eps时,则不调整学习率。
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum, weight_decay=args.weight_decay)
scheduler = ReducelROnPlateau(optimizer,'min')
for epoch in range( args.start epoch, args.epochs ):
train(train_loader , model, criterion, optimizer, epoch )
result_avg, loss_val = validate(val_loader, model, criterion, epoch)
# Note that step should be called after validate()
scheduler.step(loss_val )
自定义调整学习率 LambdaLR
为不同参数组设定不同学习率调整策略。调整规则为:
lr = base_lr * lambda(self.last_epoch)
在fine-tune中特别有用,我们不仅可以为不同层设置不同的学习率,还可以为不同层设置不同的学习率调整策略。
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
参数:
- lr_lambda(function or list): 自定义计算学习率调整倍数的函数,通常时epoch的函数,当有多个参数组时,设为list.
其它参数同上。
示例1:
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda epoch:1/(epoch+1))
示例2:
ignored_params = list(map(id, net.fc3.parameters()))
base_params = filter(lambda p: id(p) not in ignored_params, net.parameters())
optimizer = optim.SGD([
'params': base_params,
'params': net.fc3.parameters(), 'lr': 0.001*100], 0.001, momentum=0.9,weight_decay=1e-4)
# Assuming optimizer has two groups.
lambda1 = lambda epoch: epoch // 3
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
print('epoch: ', i, 'lr: ', scheduler.get_lr())
输出:
epoch: 0 lr: [0.0, 0.1]
epoch: 1 lr: [0.0, 0.095]
epoch: 2 lr: [0.0, 0.09025]
epoch: 3 lr: [0.001, 0.0857375]
epoch: 4 lr: [0.001, 0.081450625]
epoch: 5 lr: [0.001, 0.07737809374999999]
epoch: 6 lr: [0.002, 0.07350918906249998]
epoch: 7 lr: [0.002, 0.06983372960937498]
epoch: 8 lr: [0.002, 0.06634204312890622]
epoch: 9 lr: [0.003, 0.0630249409724609]为什么第一个参数组的学习率会是 0 呢? 来看看学习率是如何计算的。
第一个参数组的初始学习率设置为 0.001,
lambda1 = lambda epoch: epoch // 3,
第 1 个 epoch 时,由 lr = base_lr * lmbda(self.last_epoch),
可知道 lr = 0.001 *(0//3) ,又因为 1//3 等于 0,所以导致学习率为 0。
第二个参数组的学习率变化,就很容易看啦,初始为 0.1, lr = 0.1 * 0.95^epoch ,当
epoch 为 0 时, lr=0.1 , epoch 为 1 时, lr=0.1*0.95。
手动调整学习率
手动调整学习率,通常可以定义如下函数:
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
又如:
def adjust_learning_rate(epoch, lr):
if epoch <= 81: # 32k iterations
return lr
elif epoch <= 122: # 48k iterations
return lr/10
else:
return lr/100
该函数通过修改每个epoch下,各参数组中的lr来进行学习率手动调整,用法如下:
for epoch in range(epochs):
lr = adjust_learning_rate(optimizer, epoch) # 调整学习率
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
......
optimizer.step() # 采用新的学习率进行参数更新不同层使用不同学习率
我们对模型的不同层使用不同的学习率,可以通过更改param_group['lr']的值来更改对应参数组的学习率。
示例1
# 例1:有两个`param_group`即,len(optim.param_groups)==2
optim.SGD([
'params': model.base.parameters(),
'params': model.classifier.parameters(), 'lr': 1e-3
], lr=1e-2, momentum=0.9)
# 例2:一个参数组
optim.SGD(model.parameters(), lr=1e-2, momentum=.9)
上面第一个例子中,我们分别为 model.base 和 model.classifier 的参数设置了不同的学习率,即此时 optimizer.param_grops 中有两个不同的param_group:
param_groups[0]: 'params': model.base.parameters(),
param_groups[1]: 'params': model.classifier.parameters(), 'lr': 1e-3
每一个param_group都是一个字典,它们共同构成了param_groups,所以此时len(optimizer.param_grops)==2,aijust_learning_rate() 函数就是通过for循环遍历取出每一个param_group,然后修改其中的键 'lr' 的值,称之为手动调整学习率。
第二个例子中len(optimizer.param_grops)==1,利用for循环进行修改同样成立。
示例2
net = Network() # 获取自定义网络结构
for name, value in net.named_parameters():
print('name: '.format(name))
# 输出:
# name: cnn.VGG_16.convolution1_1.weight
# name: cnn.VGG_16.convolution1_1.bias
# name: cnn.VGG_16.convolution1_2.weight
# name: cnn.VGG_16.convolution1_2.bias
# name: cnn.VGG_16.convolution2_1.weight
# name: cnn.VGG_16.convolution2_1.bias
# name: cnn.VGG_16.convolution2_2.weight
# name: cnn.VGG_16.convolution2_2.bias
对 convolution1 和 convolution2 设置不同的学习率,首先将它们分开,即放到不同的列表里:
conv1_params = []
conv2_params = []
for name, parms in net.named_parameters():
if "convolution1" in name:
conv1_params += [parms]
else:
conv2_params += [parms]
# 然后在优化器中进行如下操作:
optimizer = optim.Adam(
[
"params": conv1_params, 'lr': 0.01,
"params": conv2_params, 'lr': 0.001,
],
weight_decay=1e-3,
)
我们将模型划分为两部分,存放到一个列表里,每部分就对应上面的一个字典,在字典里设置不同的学习率。
当这两部分有相同的其他参数时,就将该参数放到列表外面作为全局参数,如上面的`weight_decay`。也可以在列表外设置一个全局学习率,当各部分字典里设置了局部学习率时,就使用该学习率,否则就使用列表外的全局学习率。
[https://zhuanlan.zhihu.com/p/76459295]
学习率 warm-up 策略
训练神经网络时,在初始使用较大学习率而后期切换为较小学习率是一种广为使用的做法。而 warmup 策略则与上述 scheme 有些矛盾,warmup 需要在训练最初使用较小的学习率来启动,并很快切换到大学习率而后进行常见的 decay,那么最开始的这一步 warmup 为什么有效呢?
warmup_lr 的初始值是跟训练预料的大小成反比的,也就是说训练预料越大,那么warmup_lr 初值越小,随后增长到我们预设的超参 initial_learning_rate相同的量级,再接下来又通过 decay_rates 逐步下降。这样做有什么好处?
1)这样可以使得学习率适应不同的训练集合size实验的时候经常需要先使用小的数据集训练验证模型,然后换大的数据集做生成环境模型训练。
2)即使不幸学习率设置得很大,那么也能通过warmup机制看到合适的学习率区间(即训练误差先降后升的关键位置附近),以便后续验证。
[神经网络中 warmup 策略为什么有效;有什么理论解释么?]
from: -柚子皮-
ref:
以上是关于深度学习:batch_size和学习率 及如何调整的主要内容,如果未能解决你的问题,请参考以下文章