Distilling the Knowledge in a Neural Network
Posted 爆米花好美啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Distilling the Knowledge in a Neural Network相关的知识,希望对你有一定的参考价值。
其实应该最先写这篇文章的总结的,之前看了忘了记录
Motivation
one hot label会将所有不正确的类别概率都设置为0,而一个好的模型预测出来的结果,这些不正确的类别概率是有不同的,他们之间概率的相对大小其实蕴含了更多的信息,代表着模型是如何泛化判别的。
比如一辆轿车,一个模型更有可能把它预测成卡车而不是猫,这其实给出了比one hot label更多的信息即轿车和卡车更像,而和猫不像。
如果一个大的模型做到了很好的泛化性能,那我们可以用一个小的模型去模拟他的泛化结果去达到较好的效果
Method
Loss = CE(softmax(predict), one hot label) + alpha * T * T * CE(softmax(predict/T), soft target)
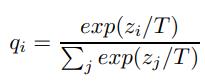
T作为一个超参,当T很大时,qi会更加soft,比如T趋于无穷大,则qi=(1/n, 1/n…)
当T较小时(比如T=1),需要去匹配更多的不正确类别的概率。如果student和teacher性能相差较大,可设置T为中等大小
VS Matching logits(Caruana提出的)
Matching logits(https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf) is a special case of distillation
C = CE(softmax(predict/T), soft target),根据CE的求导公式得
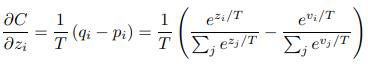
如果temperature T比logits的量级(magnitude)要大得多,那么zi/T->0,zi<0时从左边趋近0,>0时从右边趋近0,所有e^(zi/T) =1+zi/T
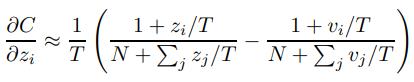
假设对于每一个transfer case,都有logits的均值为0,所以上式可以简化为

所以,如果temperature T很高,如果对于每一个transfer case,都有logits的均值为0,那么distillation就等价于最小化1/2(zi−vi)^2,也就是Caruana提出的使得复杂模型的logits和小模型的logits的平方差最小
https://daiwk.github.io/posts/dl-knowledge-distill.html
Soft Targets as Regularizers
用soft target进行训练避免了过拟合

以上是关于Distilling the Knowledge in a Neural Network的主要内容,如果未能解决你的问题,请参考以下文章