重温 C/C++ 笔记
Posted 拭心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重温 C/C++ 笔记相关的知识,希望对你有一定的参考价值。
文章目录
- 一些细节点
- 笔记
- 问题记录
工作里用到 C/C++ 越来越多,花了些时间加强。
本文主要是学习极客时间的 C++ 课程笔记。
弄懂这些位于“犄角旮旯”里的特性(无贬义),需要花费我们很多的脑力,但在我们一般的开发过程中,通常很少会触及这些点,或者说是会尽力避免,它们通常只是对编译器有意义,所以在这些“细枝末节”上下功夫就不是很值了,说白了,就是性价比太低。
我个人认为,在掌握了专栏里 C++11/14 知识的基础上,如果再面对一个 C++ 新的语言特性,你不能够在五分钟(或者再略长一点)的时间里理解它的含义和作用,就说明它里面的“坑”很深。
你应当采用“迂回战术”,暂时放弃,不要细究,把精力集中在现有知识的消化和理解上,练好“基本功”,等你以后真正不得不用它的时候,通过实践再来学习会更好。
一些细节点
-
使用条件编译可以提早优化代码,产生最适合系统、编译环境的代码
-
“deprecated”属性只会导致编译警告,函数和类仍然可
-
属性标签是由编译器负责解释的,自定义标签编译器无法识别。
-
const 常量也是变量,可以修改,但修改通常会被优化掉,无法直接体现
-
const 成员函数可以修改 mutable 成员变量,不是完全不可以修改变量
-
mutable 与 volatile 不冲突,但与 const 无法共存
-
“const int ”和“int const”的意思?
-
前者是指向常量的指针,后者指向的是变量,但指针是常量
-
shared_ptr 的行为最接近原始指针,但不能滥用
-
shared_ptr 有少量的成本,而且有无法克服的循环引用风险,需要搭配 weak_ptr 才能获得最佳效果。
-
lambda 表达式不是函数是变量,但可以像函数一样被调用
-
字符串的拷贝、修改代价比较高,应当尽量用 const string& 的方式来引用字符串
-
原始指针可以拷贝,符合值语义,可以放进容器,但需要用户自己管理指针的生命周期
-
只排序部分数据,最佳的算法是 partial_sort
-
二进制格式与复杂数据结构无关,MessagePack 可以序列化任意数据类型,无论多复杂的结构。
-
top 只能看 CPU 和内存,其他指标要用别的工具(比如网络 I/O 看不了)。
-
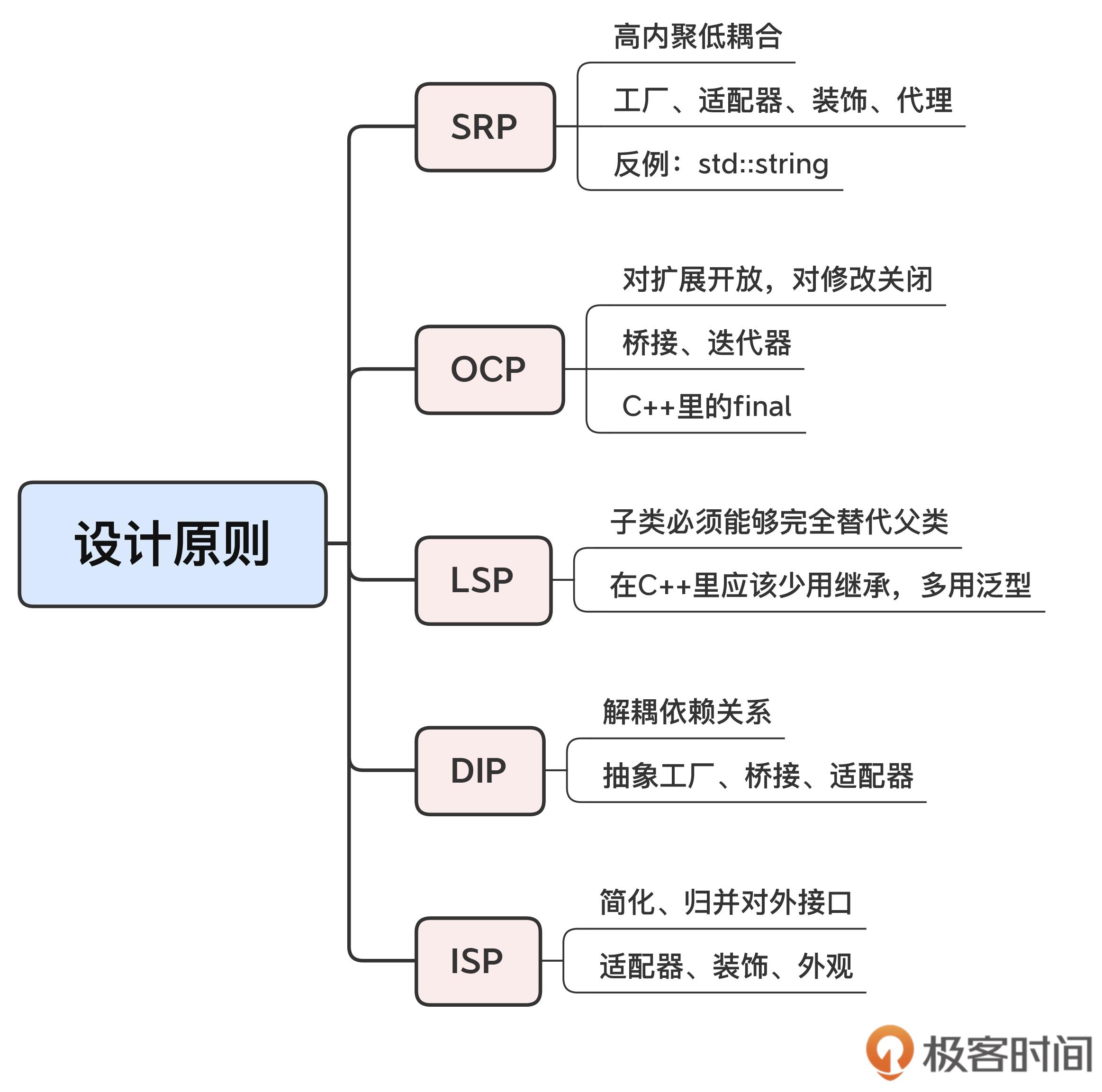
设计原则只是一些基本思想,所以没有具体的操作方式。
-
DRY 和 KISS 不涉及面向对象,更多地偏向代码编写规范
笔记
- 类内部为什么不能用 auto
- 无捕获的 lambda 才能转成函数指针?
- g++ 参数都什么意思?
- -E 是只输出预处理后的结果
02 编码阶段
编码风格:http://openresty.org/cn/c-coding-style-guide.html
03 预编译
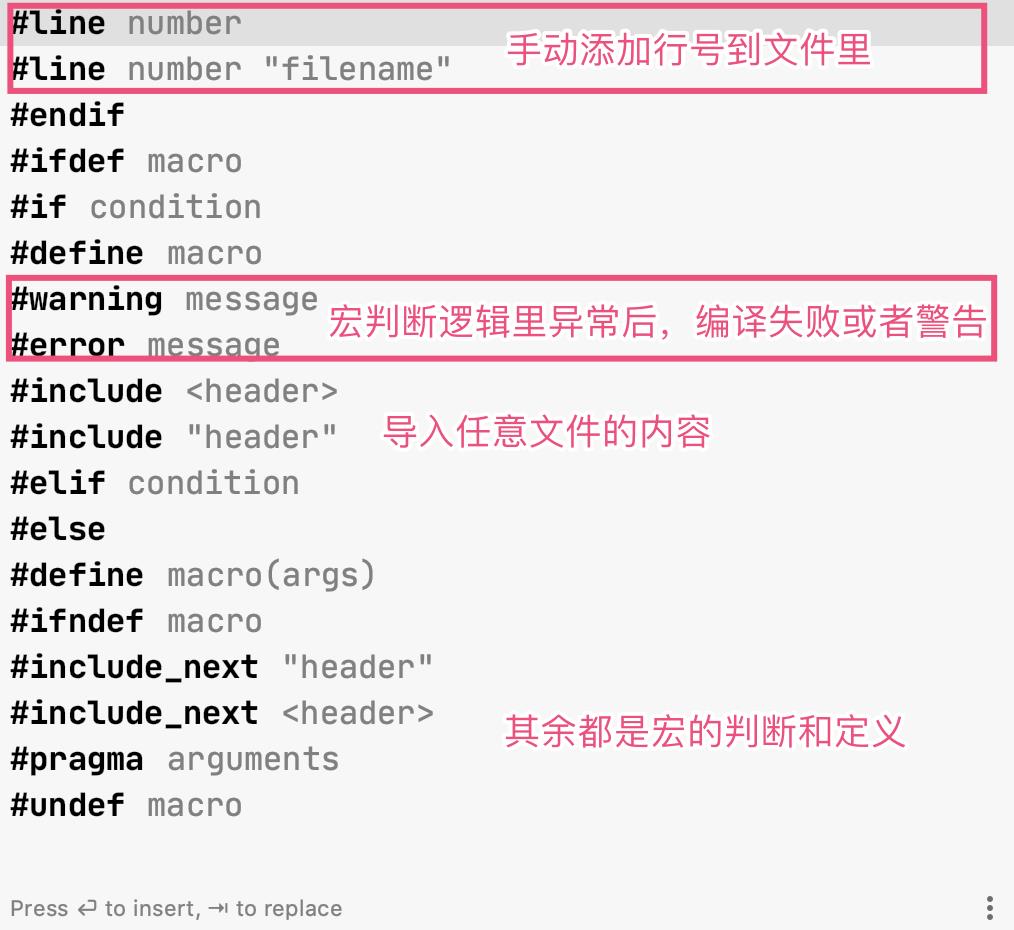
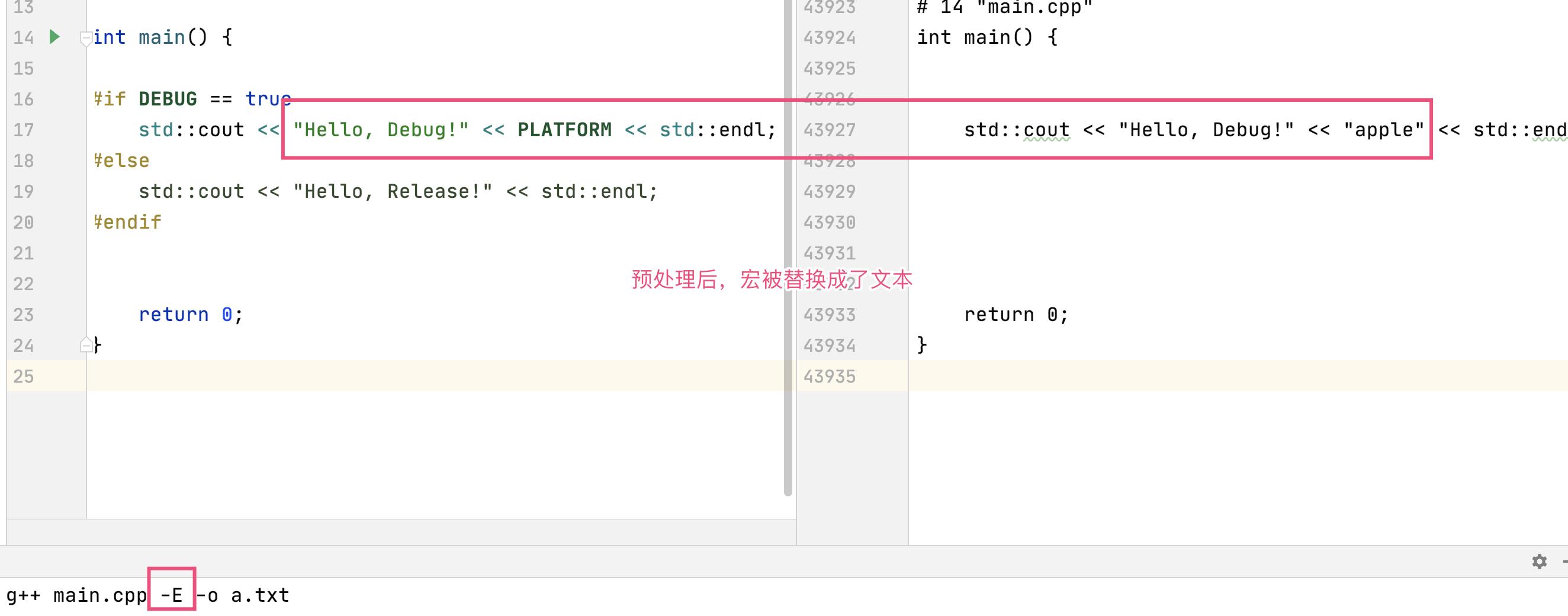
C++ 预编译期间,通过各种宏和条件判断修改代码逻辑。

#if必须得以#endif配对出现



内置的宏:
g++ -E -dM - < /dev/null //查看内置的宏

基于它们,你就可以更精细地根据具体的语言、编译器、系统特性来改变源码,有,就用新特性;没有,就采用变通实现
__cplusplus: 目前使用的 c++ 标准,201402, 201103
04 编译阶段:属性和静态断言
属性:可以给变量、函数、类添加一个标签(类似注解),方便编译器识别处理。
用两对方括号的形式,方括号中间就是属性标签:[[noreturn]], [[depreacated]]
attribute :
- attribute 详解及应用
- https://gcc.gnu.org/onlinedocs/gcc/Attribute-Syntax.html
attribute 参数:
- constructor 在构造器之前执行
- destructor 在析构后执行
- cleanup
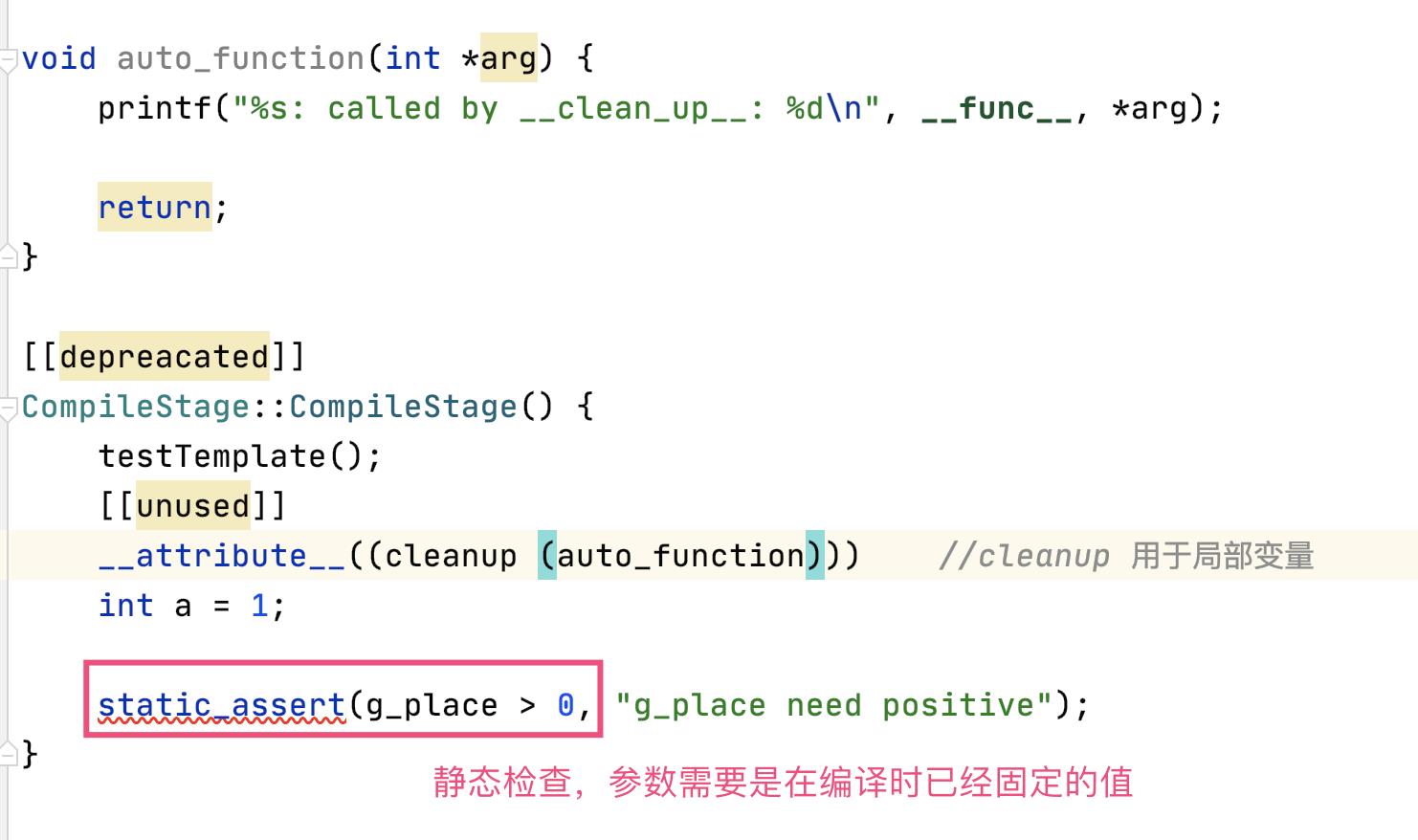
static_assert 运行在编译阶段,只能看到编译时的常数和类型,看不到运行时的变量、指针、内存数据等,
(__visibility__("default"): 某个符号是否导出
试想这样的情景,程序调用某函数A,A函数存在于两个动态链接库liba.so,libb.so中,并且程序执行需要链接这两个库,此时程序调用的A函数到底是来自于a还是b呢?
这取决于链接时的顺序,比如先链接liba.so,这时候通过liba.so的导出符号表就可以找到函数A的定义,并加入到符号表中,链接libb.so的时候,符号表中已经存在函数A,就不会再更新符号表,所以调用的始终是liba.so中的A函数。
为了避免这种混乱,所以使用__attribute__((visibility(“default”)))attribute((visibility(“hideen”))) 设置这个属性。
05 面向对象编程
https://time.geekbang.org/column/article/235301
- C 语言中,也可以使用
struct实现抽象和封装。 - 建议设计时,少用继承和虚函数,多使用组合。
多重继承、纯虚接口类、虚析构函数,动态转型、对象切片、函数重载等很多危险的陷阱
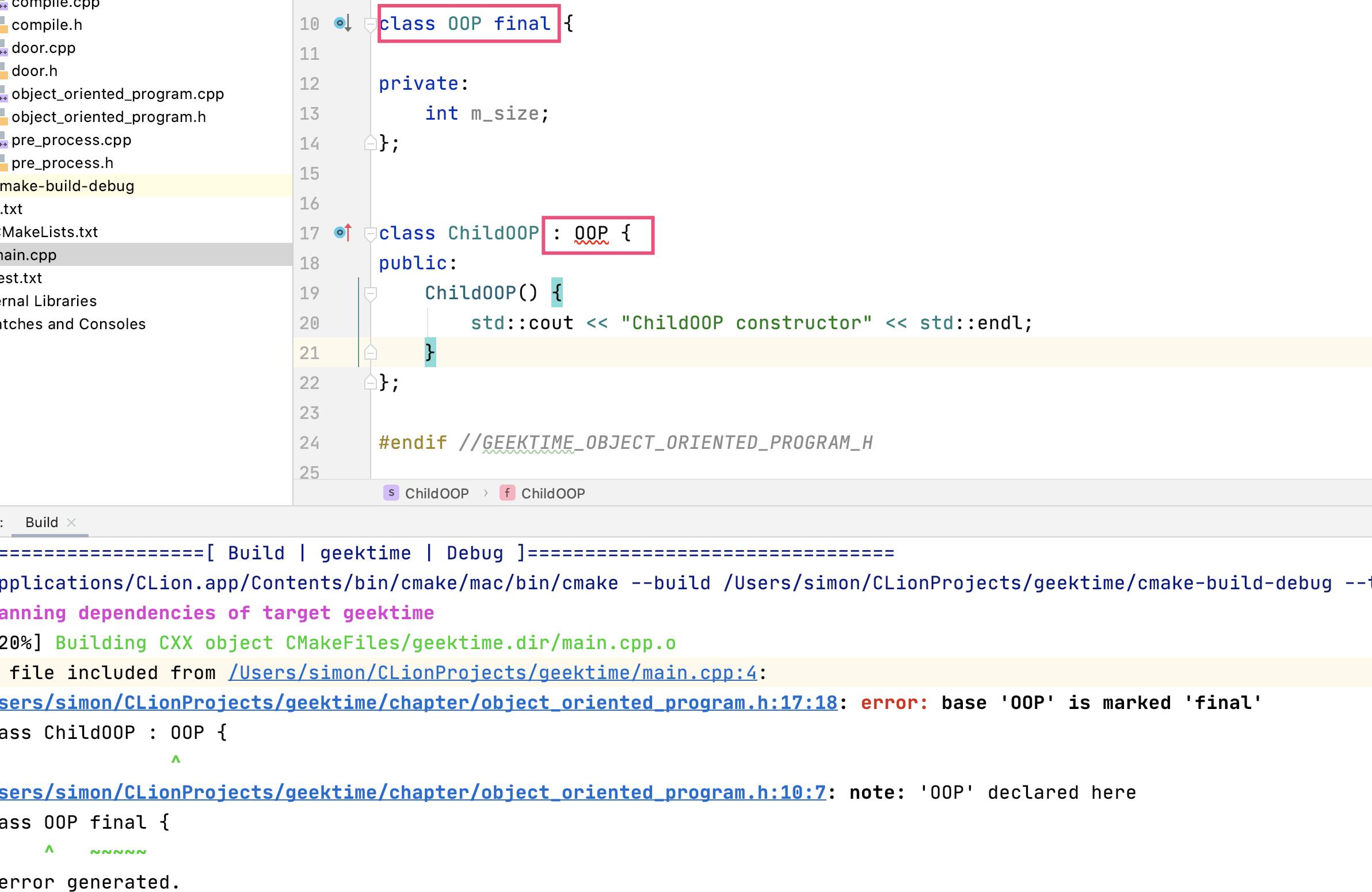
- C++ 用
:表示继承,final 放在类名后面
C++ 四大函数:
- 构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值函数
为了减少创建对象成本,C++ 11 引入了右值 (Rvalue) 和转移(move):
- 转移构造函数
- 转移赋值函数

对于比较重要的构造、析构函数,可以使用
= default,让编译器生成默认实现。
= delete表示明确禁用某个函数(非构造、析构也可以用),让外界无法调用
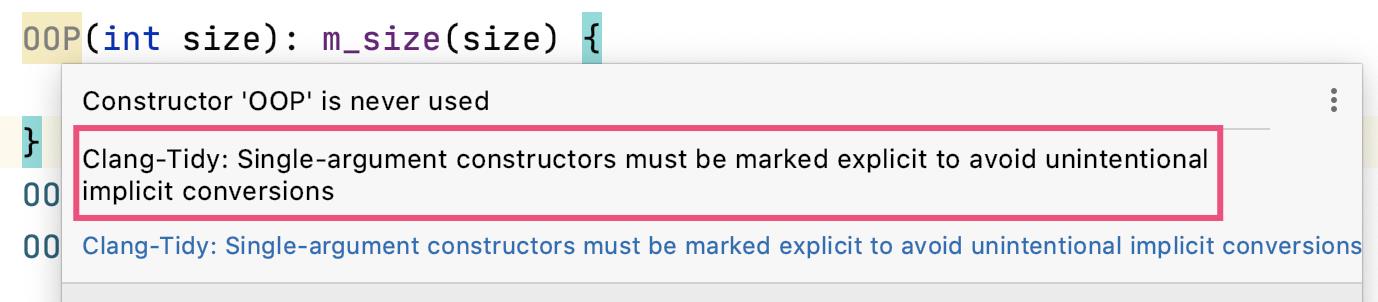
C++ 有隐式构造和隐式转型的规则。
隐式类型转换:类型 A 被自动转成表达式需要的类型 B。


两种类型别名:
using name = type
typedef type name
第一种比较直观。
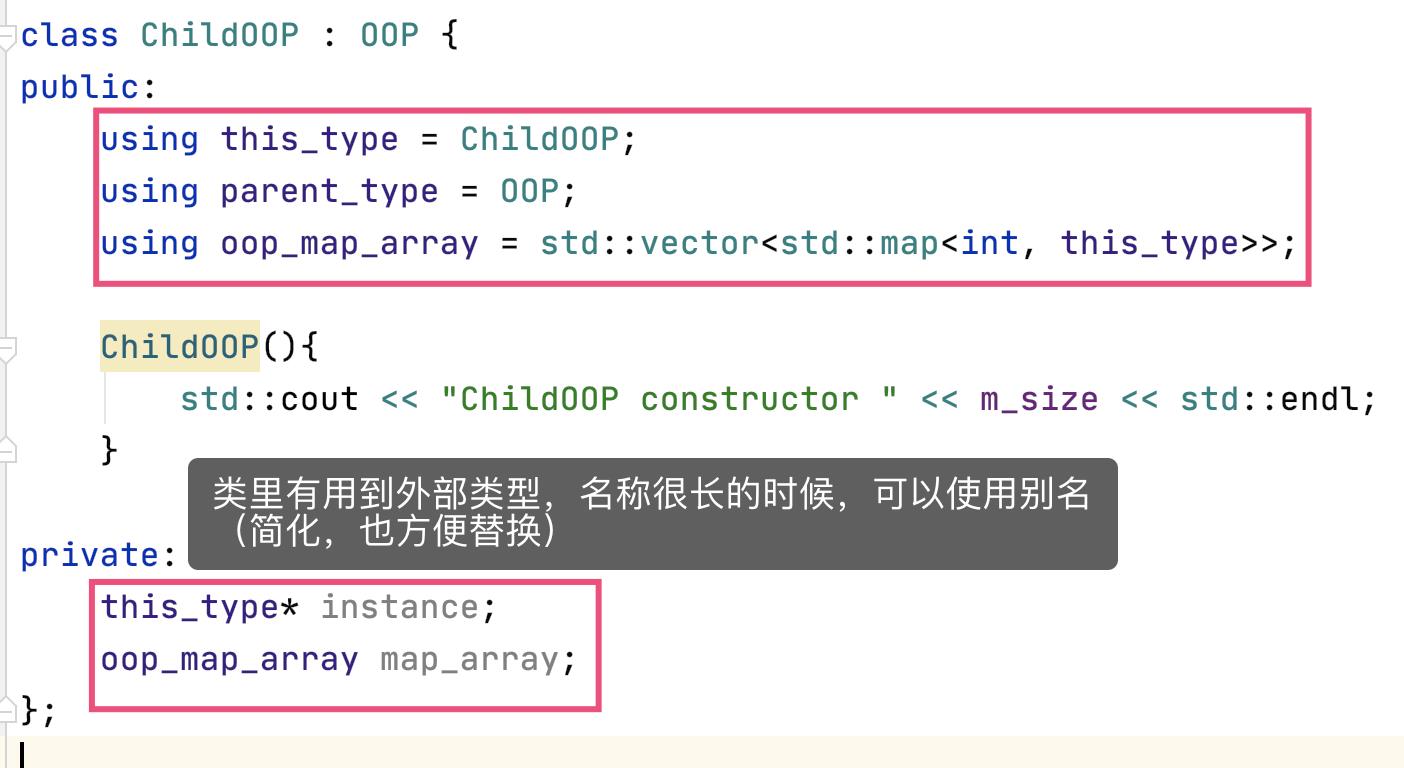
如果类里有外部类型,名称比较长,可以定义个别名。
06 自动类型推导
auto:初始化时类型推导,总是“值”类型,没办法是引用类型decltype, 表达式的方式计算类型,可以用于任何场合
“自动类型推导”实际上和“attribute”一样,是编译阶段的特殊指令,指示编译器去计算类型。所以,它在泛型编程和模板元编程里还有更多的用处。
auto 的“自动推导”能力只能用在“初始化”的场合。
赋值初始化或者花括号初始化(初始化列表、Initializer list),变量右边必须要有一个表达式(简单、复杂都可以)
很容易理解,只是声明,没有赋值,无法推导类型。
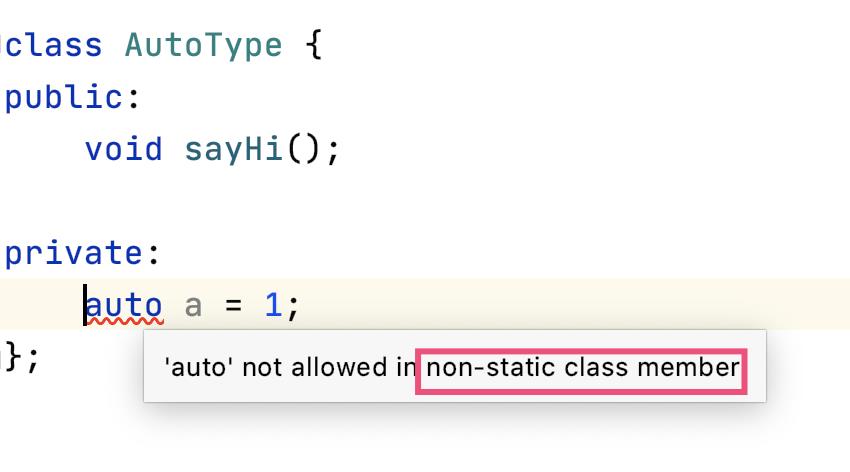
另外,auto 也不能用于类成员变量:
但可以使用 using + decltype 的方式,简化类变量的类型声明:
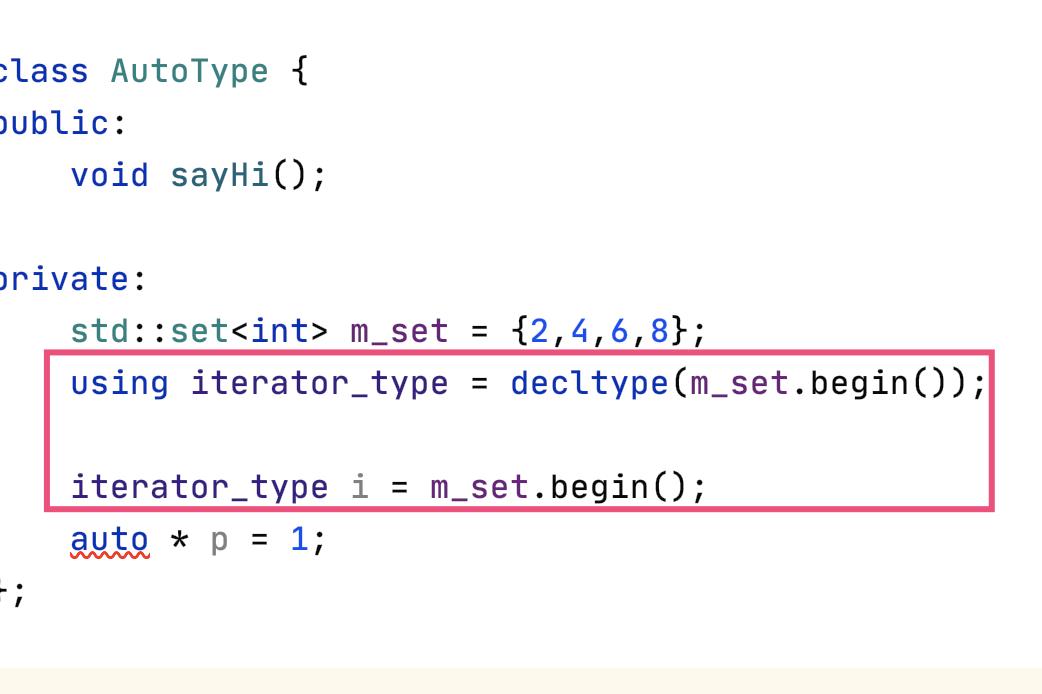
除了简化代码,auto 还避免了对类型的“硬编码”。方便后续修改。
自动类型推导”实际上和“attribute”一样(第 4 讲),是编译阶段的特殊指令,指示编译器去计算类型。所以,它在泛型编程和模板元编程里还有更多的用处
auto 用于有表达式的时候,decltype 用于没有表达式,但先确定类型的情况。
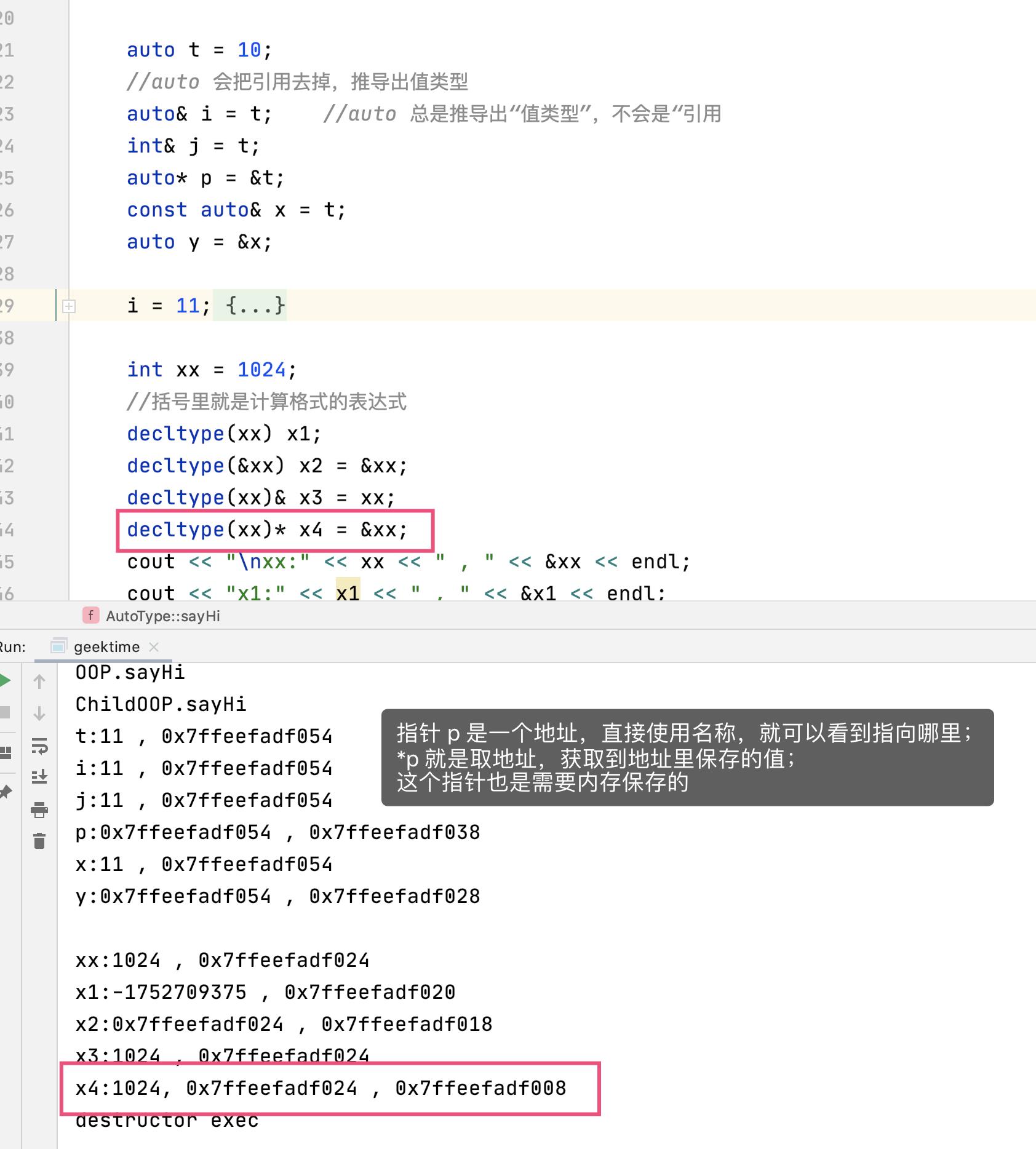
上图里的名称写错了,*p 是取值符。
一个数取地址,得到的类型就是一个指针:


使用 auto 可以简化遍历的方式,使用 rang-for-loop
07 常量变量:const/volatile/mutable

const 其实是只读变量,编译保证了不会被修改。
const- 可以修改引用和指针,
const&是函数参数的最佳选择 - 修饰成员函数的话,这个函数只能访问常量变量;const 函数,实际上是传入一个 const this
- const 常量在预处理阶段不存在,在运行阶段才出现。
- 编译器看到 const 常量会做一些优化,比如把这个变量直接换成对应的值
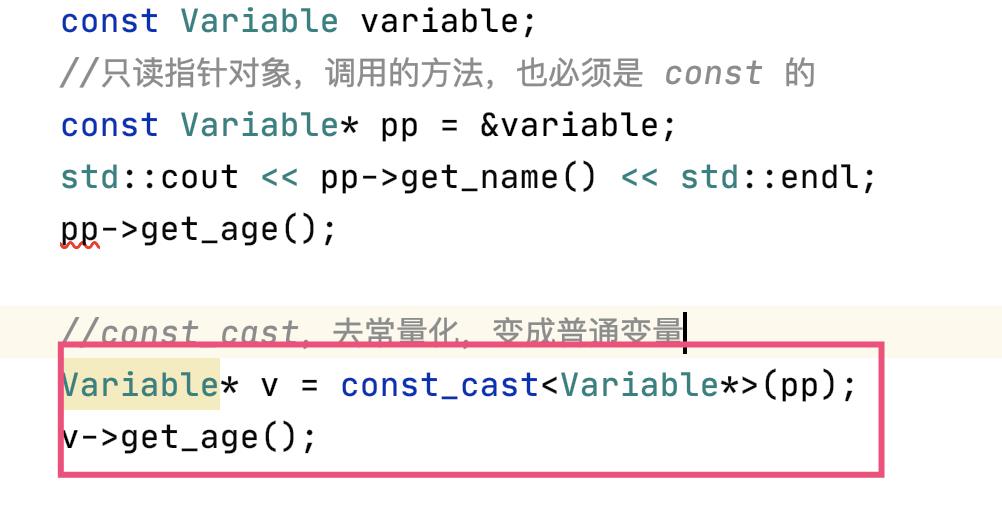
- 只读指针对象,调用它的方法,只能调用 const 的
const_cast,去常量化,变成普通变量volatile- 表示变量会随时会被修改,禁止编译器优化,应该少用
mutable- volatile 可以用来修饰任何变量,而 mutable 却只能修饰类里面的成员变量,表示变量即使是在 const 对象里,也是可以修改的
- mutable 像是 C++ 给 const 对象打的一个“补丁”,让它部分可变
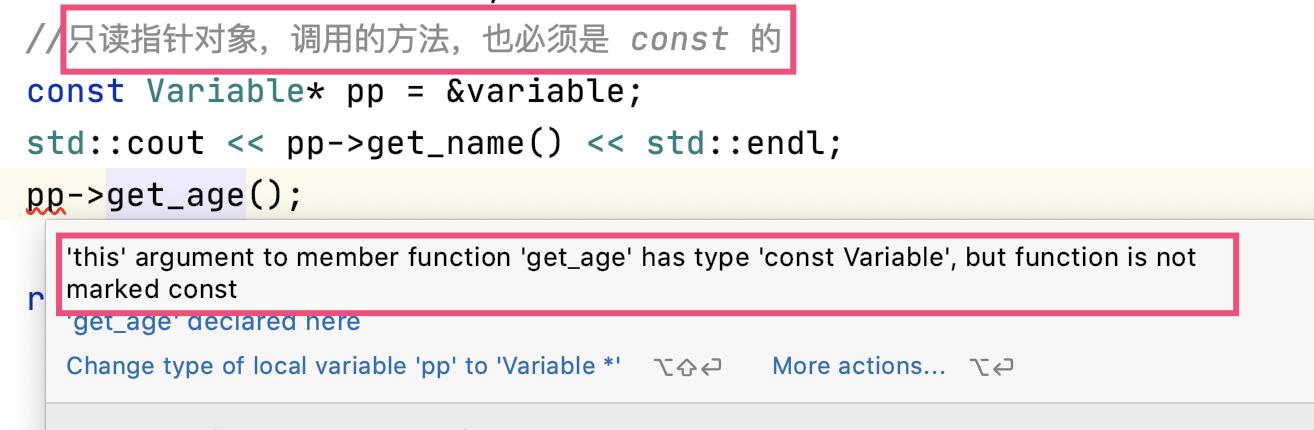
既然对象是 const,那么它所有的相关操作也必然是 const。

const_cast,去常量化,变成普通变量
08 智能指针
#include <memory>
智能指针,使用代理模式,利用 RAII 技术代替裸指针(重载了 * 和 -> 操作符,所以使用和裸指针一样),能够在指针对象析构时自动释放内存。用于替代手动创建裸指针和手动释放内存。
什么是 RAII 技术:
- Resource Acquisition Is Initialization
- 利用对象生命周期控制对资源的使用
函数内部的一些成员是放置在栈空间上的,当函数返回时,这些栈上的局部变量就会立即释放空间,于是Bjarne Stroustrup就想到确保能运行资源释放代码的地方就是在这个程序段(栈)中放置的对象的析构函数了。
RAII就利用了栈里面的变量的这一特点。
RAII 的一般做法是这样的:
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在对象析构的时候释放资源。
指针与引用的区别?
- 指针是内存地址,引用是变量别名,指针可以是空,而引用不能为空(引用必须初始化,否则编译失败)
- 引用是通过指针常量实现的
指针完全映射了计算机硬件,操作效率高,是 C++ 效率高的根源。
同时也导致了很多问题:访问无效地址,指针越界,内存没有即使释放等。
Java/Go 没有这方面问题。
- unique_ptr
- 独占使用的指针,不能直接赋值给其他指针,需要通过右值转移,转移后之前指针变成空指针
make_unique()- shared_ptr
- 共享使用的指针
- 内部使用了引用计数,
use_count可以查看有几个引用,引用为 0 时,才会 delete 内存 make_shared()- 还可以定制内存删除函数
- 缺点:
- 引用计数的存储和管理都是成本
- 在运行阶段,引用计数的变动很复杂,很难知道它真正释放资源的时机
- 对象的析构函数,不要有非常复杂、严重阻塞的操作。一旦 shared_ptr 在某个不确定时间点析构释放资源,就会阻塞整个进程或者线程
- 可能遇到循环引用导致计数始终不为 0,无法 delete 内存
- weak_ptr
- 专门为打破循环引用设计,只观察引用,不计数
- 可以调用
lock()获取shared_ptr

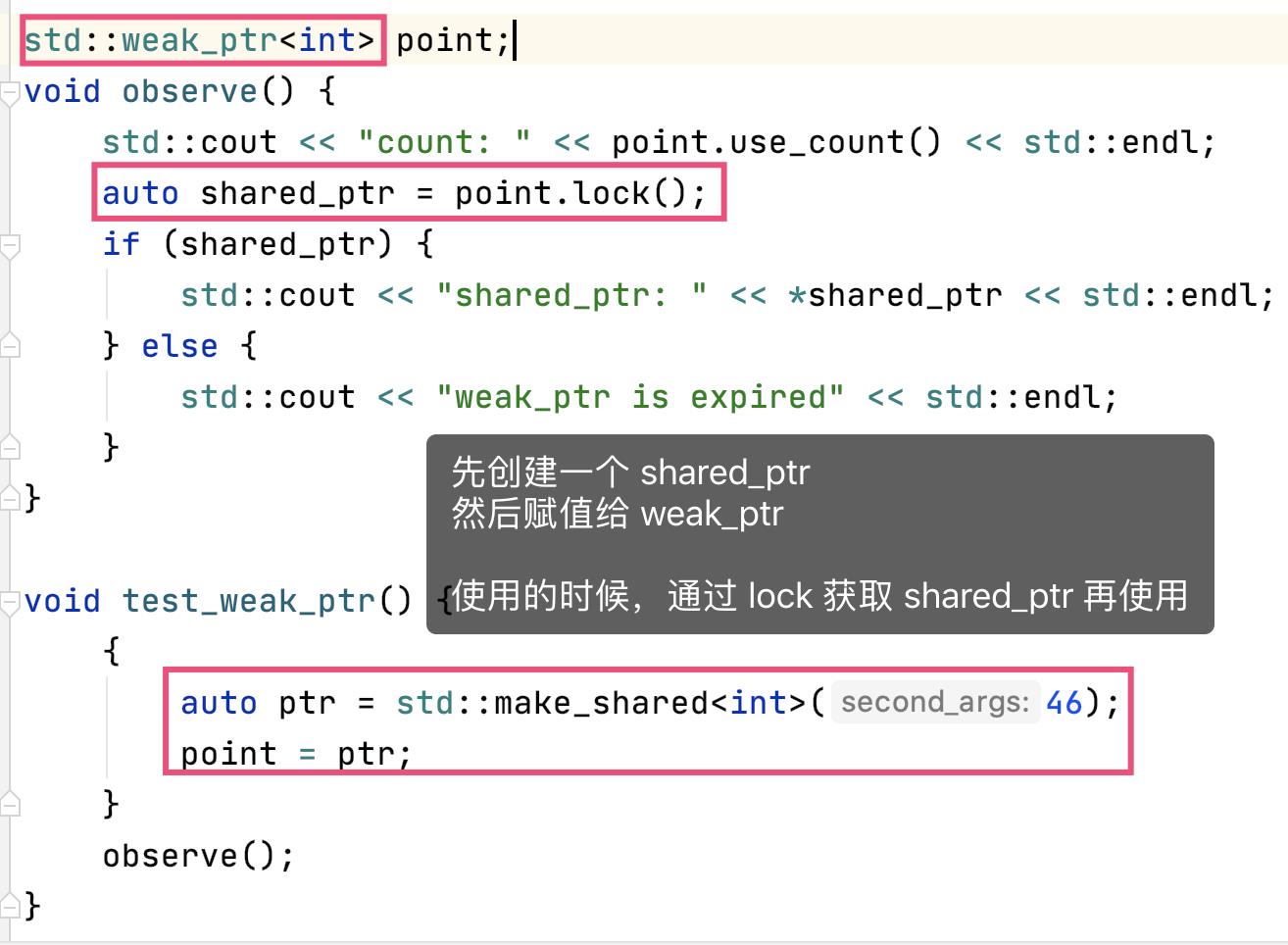
自定义智能指针工厂方法:
template<class T, class... Args> //可变参数模板
std::unique_ptr<T> //返回智能指针
my_make_unique(Args&&... args) //可变参数模板的入口参数
return std::unique_ptr<T>( //构造智能指针
new T(std::forward<Args>(args)...) //转发参数
);
09 exception
#include <stdexcept>
C++ 处理异常的方式:
- 判断函数返回值
- 判断全局错误码,
errno
- 业务逻辑和错误处理混在一起
- 很容易被忽略,出现异常还继续执行,导致出现意料之外的情况
- 抛出、处理异常
- 错误处理集中在 catch 代码块
- 异常不能被忽略,必须处理,否则向上传播,直到被处理或者崩溃。不会带病工作
- 使用范围更广,比如没有返回值的函数,出现异常

使用 noexcept 修饰不会抛出异常的函数,方便编译器做优化:
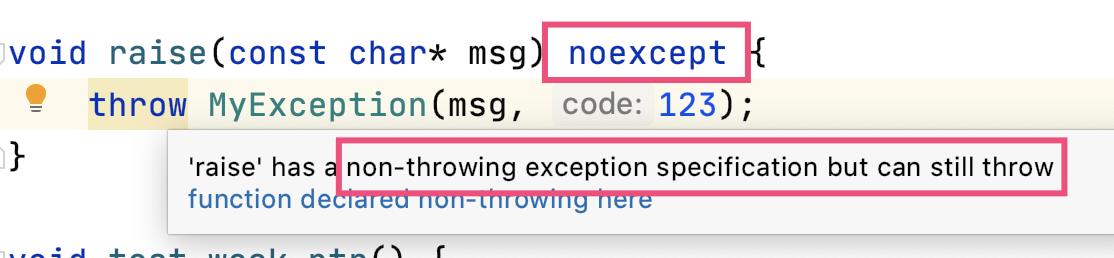
noexcept 的真正意思是:“我对外承诺不抛出异常,我也不想处理异常,如果真的有异常发生,请让我死得干脆点,直接崩溃(crash、core dump)。”
一般认为,重要的构造函数(普通构造、拷贝构造、赋值构造、转移构造)、析构函数,尽量声明为noexcept,优化性能。
10 节 函数式编程
函数的目的:封装执行的细节,简化程序的复杂度。
面向对象编程:程序由一个个对象组成,彼此组合、通信完成任务;
函数式编程:程序由一个个函数组成,彼此组合、调用完成任务。
C++ 函数的特点:
- 没有类型,只能通过函数指针间接操作
- 函数都是全局的,没有生命周期的概念(static、namespace 只是限制了范围,避免名字重复)
- 函数里不能嵌套函数
C++ 中的 lambda:
- 是一个变量,可以赋值、嵌套
- 全新编程思维 — 函数式编程:把计算机程序的函数,等价于数学上的求解函数。
- 结合 auto 声明 lambda 类型的函数变量
- 捕获时注意外部变量的生命周期,小心失效
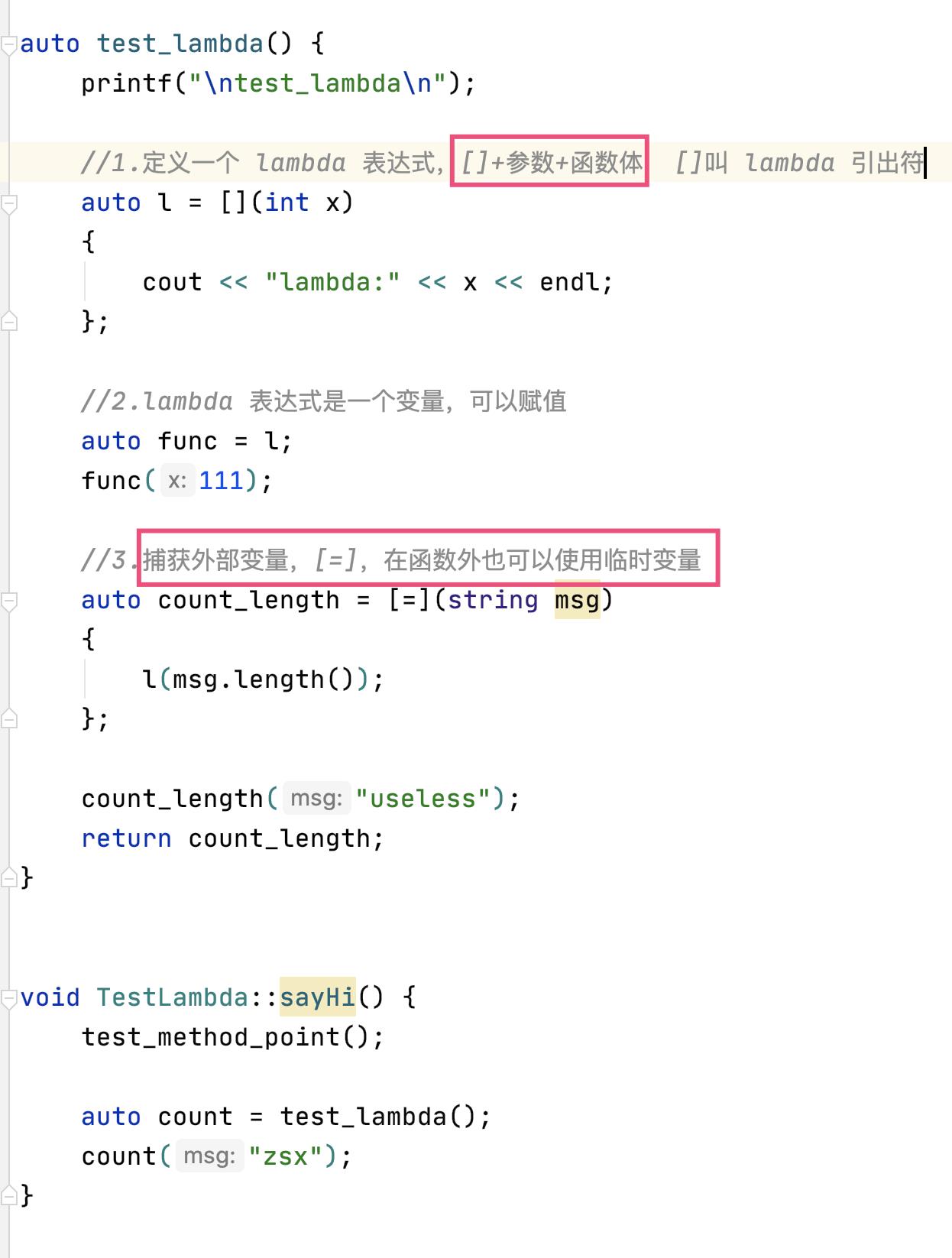
void test_lambda_2()
//4.嵌套 lambda 定义、调用
auto open_website = [](string website)
string local_ip = "192.168.77.33";
//按值捕获,指定捕获变量名
auto dns = [local_ip](string website)
cout << "Transform website to ip: " << website << " to " << local_ip << endl;
;
auto tcp = [local_ip](string server)
cout << "Establish connect from " << local_ip << " to " << server << endl;
;
cout << "Your website is opening... " << website << endl;
dns(website);
tcp("202,184,293,23");
;
open_website("www.baidubaike.com");
和 JS 的闭包差不多
lambda 保存了定义时捕获的外部变量,就可以跳离定义点,把这段代码“打包”传递到其他地方去执行
在 C++ 里,每个 lambda 表达式都会有一个独特的类型,而这个类型只有编译器才知道,我们是无法直接写出来的,所以必须用 auto。
捕获外界变量:
- =:按值捕获所有外部变量,不可修改
- &:按引用捕获,可以修改,比较危险,可能出现被修改地址已经不可使用的情况!
- 也可以明确指定变量名和捕获方式
参数使用 auto 声明,可以让 lambda 表达式处理不同类型的参数:
//5.泛型的 lambda
void test_lambda_3()
//参数使用 auto 声明,泛型化
auto f = [](const auto& i)
cout << i+i << endl;
;
f(6);
f(0.24f);
string str = "hao";
f(str);
用“map+lambda”的方式来替换难以维护的 if/else/switch,可读性要比大量的分支语句好得多。
11节 STL-字符串
template <class _CharT, // for <stdexcept>
class _Traits = char_traits<_CharT>,
class _Allocator = allocator<_CharT> >
class _LIBCPP_TEMPLATE_VIS basic_string;
typedef basic_string<char, char_traits<char>, allocator<char> > string;
typedef basic_string<wchar_t, char_traits<wchar_t>, allocator<wchar_t> > wstring;
#ifndef _LIBCPP_HAS_NO_UNICODE_CHARS
typedef basic_string<char16_t> u16string;
typedef basic_string<char32_t> u32string;
#endif // _LIBCPP_HAS_NO_UNICODE_CHARS
- Unicode,统一的编码处理人类语言,使用 32 位(4个字节)容纳文字
- C 里的
char是单个字符,因此增加了wchar_t - 后来又有了
char16_t,适配 UTF-16 char32_t,适配 UTF-32
wstring 等新字符串基本上没人用,大多数程序员为了不“自找麻烦”,还是选择最基本的 string。
Unicode 还有一个 UTF-8 编码方式,与单字节的 char 完全兼容,用 string 也足以适应大多数的应用场合
-
建议你只用 string,而且在涉及 Unicode、编码转换的时候,尽量不要用 C++,目前它还不太擅长做这种工作,可能还是改用其他语言来处理更好
-
字符串后缀s是C++14的特性,C++11没有,需要升级gcc到5.4,然后启用C++14标准。

-
*end = 0,这一句很重要,执行前,end 指向的是第一个换行符的位置;执行后,把换行符改成了 0 -
这时操作的是 line 指向的内存数据,因此 line 也被截断了
void test_other_string_api()
//单纯保存的是字符序列,使用 vector<char>
vector<char> char_array;
//字面量后缀, s 后缀,表示是一个 string 类型
auto str = "shixinzhang hahaha"s;
auto not_raw_string = "zhangshi \\n xin hhha";
//想直接输出各种转义符,使用 raw string
auto raw_string = R"(zhangshi \\n xin hhha)";
cout << not_raw_string << endl;
cout << raw_string << endl;
//字符串转数字 stoi, stof, stod
auto test_integer = "444.4";
cout << stoi(test_integer) << endl;
cout << stof(test_integer) << endl;
//to_string 数字转字符串
cout << to_string(1024) << endl;
void test_string_func()
string name = "shixinzhang";
cout << "\\nlength: " << name.length() << "size:" << name.size() << endl;
//c_str() 和 data() 都返回一个 const char* 指针,但 c_str() 会在末尾加一个 \\0
cout << "c_str strlen: " << strlen((name.c_str())) << endl;
cout << "data strlen: " << strlen((name.data())) << endl;
cout << "substr:" << name.substr(0, 5) << endl;
//既可以查找一个子字符串,也可以查找某个字符(如果有多个,返回的是第一个)
cout << "find:" << name.find("shi") << " , " << name.find('i') << endl;
//也支持查找第一个和最后一个字符
cout << "find_first_of:" << name.find_first_of('n') << endl;
cout << "find_first_not_of:" << name.find_first_not_of('z') << endl;
cout << "find_last_of:" << name.find_last_of('i') << endl;
cout << "find_last_not_of:" << name.find_last_not_of('n') << endl;
void test_string_reg()
auto make_regex = [](const string& str)
return std::regex(str);
;
auto make_match = []()
return std::smatch();
;
//1.创建字符串, s 表明类型
auto str = "name:shixin-2016"s;
//2.创建正则表达式
auto reg = make_regex(R"(^(\\w+):(\\w+)-(\\w+)$)");
//3.创建存储结果的 match
auto match = make_match();
//4.调用匹配
regex_match(str, match, reg);
cout << "regex result:" << match.size() << "\\n" << endl;
//匹配结果可以像容器那样被访问,第0个是整个匹配的内容,后面的匹配的多个子串
for (const auto&x: match)
cout << x << " , ";
cout << endl;
cout << "Parsed name: " << match[2] << endl;
cout << "Parsed age: " << match[3] << endl;
void StringTest::test()
test_string_func();
test_other_string_api();
test_string_reg();
- strchr,查找字符串里某个字符的位置,返回对应位置的指针
- strlen, 获取某个字符串指针的长度
12节 STL-容器
#include <vector>
#include <list>
#include <set>
#include <map>
#include <deque>
#include <forward_list>
容器里存储的是元素的拷贝、副本,而不是引用,尽量为元素实现转移构造和转移赋值函数,在加入容器的时候使用 std::move() 来“转移”,减少元素复制的成本(测试一下内存占用)
- 数组
- array 固定长度
- vector 动态数组,扩容时×2
- deque 双端队列,也可以扩容,可以在 2 端高效的添加、删除(vector 只能往后面插入)
- 链表
- list:双端链表
- forward_list:单向链表
array 和 vector 直接对应 C 的内置数组,内存布局与 C 完全兼容,所以是开销最低、速度最快的容器。
有序容器
- set
- map
- multiset/multimap,multi 表示 key 可以重复
class Student
public:
Student(int age) : age(age)
//const 函数,不修改成员函数
int operator+(int v) const
return this->age + v;
//return-type operator操作符(参数)函数题
//Overloaded 'operator<' must be a binary operator (has 3 parameters)
friend bool operator<(const Student& a, const Student& b)
//这里的顺序,就是有序容器里的顺序(大的在前)
return a.age > b.age; // 自定义比较运算
friend ostream& operator << (ostream & os, const Student& s)
os << "student: " << s.age;
return os;
public:
int age;
;
void test_order_collection()
//set, map, multiset, multimap
auto comparator = [](const Student&a, const Student&b)
return a.age > b.age;
;
//1.自定义类,需要重载比较 < 操作符,才能放入 set
std::set<Student> students ;
//1.2 或者自定义比较器
// std::set<Student, decltype(comparator)> students ;
//emplace 可以直接构造元素,免去了构造后再拷贝、转移的成本
students.emplace(12); //无需 new Student(12)
//每次插入都会排序,如果数量很大时,需要考虑是否合理
students.emplace(16);
students.emplace(13);
//2.要输出内容,需要重载 << 操作符
for(const Student&x: students)
std::cout << x << " , addr:" <<&x << " , size: " << sizeof(x) << std::endl;
无序容器
- unordered_set/unordered_map
- 无序容器用 hash 表实现,而不是红黑树
- 需要重载= 和 hash 函数(敲一下)
Overloaded ‘operator<’ must be a binary operator (has 3 parameters) 为什么重载 < 需要加 friend
https://www.zhihu.com/question/44865154
2 点:
- friend 友元函数可以访问私有方法
- 规定:重载一个二元的全局运算符,需要声明这个函数为友元
- < 比较运算符是个“二元运算符”
13节 STL-算法
https://en.cppreference.com/w/cpp/header/iterator
https://en.cppreference.com/w/cpp/header/algorithm
stl 算法操作的是迭代器,这是泛型编程,分离数据和操作
通过容器的 begin() end() 可以获取指向两个端的迭代器(cbegin() 返回的是常量迭代器);也有通用函数:std::begin(容器对象)。
void test_iterator()
typedef std::array<int, 6> my_array;
my_array a = 0,1,2,3,4, 4;
cout << "print array:" << endl;
for (auto iterator = a.begin(); iterator != a.end(); iterator++)
//迭代器是个指针
cout << *iterator << " , ";
cout << endl;
//全局函数获取迭代器
auto begin = std::begin(a);
auto end = std::end(a);
//逆序迭代
auto reverse_begin = std::rbegin(a);
//返回的是常量迭代器
auto const_begin = std::cbegin(a);
//distance, 计算 2 个迭代器之间的距离
cout << "Distance of two iterator: " << std::distance(begin, end) << endl;
//获取下一步,不修改参数
begin = std::next(begin);
cout << "Distance of two iterator: " << std::distance(begin, end) << endl;
//往前走几步,修改参数
std::advance(begin, 2);
cout << "Distance of two iterator: " << std::distance(begin, end) << endl;
void test_algorithm()
typedef std::array<int, 6> my_array;
my_array a = 4,2,1,3,5, 4;
cout << a[1] << endl;
auto begin = std::begin(a);
auto end = std::end(a);
//1.统计满足条件的个数
//结合 lambda 表达式写的很 easy
auto n =std::count_if(begin, end, [](auto x)
return x > 1;
);
cout << "Number of item which larger than 1 :" << n << endl;
//2.二分查找,返回的是是否存在
auto binary_search_result = std::binary_search(begin, end, 44);
cout << "binary_search_result: " << binary_search_result << endl;
//3.快速排序
std::sort(begin, end);
//4.另一种遍历方式,可以自定义每个 item 的输出内容
cout << "test_for_each" << endl;
//std::for_each 把要做的事情分成了两部分:一个遍历容器元素,另一个操纵容器元素
int index = 0;
std::for_each(begin, end, [&index](const auto&x)
if (x == 4)
//可以通过修改捕获的参数的地址,来向外传递数据
index++;
cout << x << " ; ";
);
cout << "4 count: " << index << endl;
算法
- 用 for_each 代替手写的 for 循环(可以传入 lambda 表达式,逻辑更清晰)
- 很多排序算法(topN等),记在脑图里
https://time.geekbang.org/column/article/243357
要求排序后仍然保持元素的相对顺序,应该用 stable_sort,它是稳定的;
选出前几名(TopN),应该用 partial_sort;
选出前几名,但不要求再排出名次(BestN),应该用 nth_element;
中位数(Median)、百分位数(Percentile),还是用 nth_element;
按照某种规则把元素划分成两组,用 partition;第一名和最后一名,用 minmax_element。
最好在顺序容器 array/vector 上调用!
查找:
- lower_bound (https://en.cppreference.com/w/cpp/algorithm/lower_bound),返回第一个大于等于参数的位置
- upper_bound,返回第一个大于的位置
它俩的返回值构成一个区间,这个区间往前就是所有比被查找值小的元素,往后就是所有比被查找值大的元素:
begin < x <= lower_bound < upper_bound < end
还有很多有用的方法,类似 memcpy 的 copy/move 算法(搭配插入迭代器)、检查元素的 all_of/any_of 算法,用好了都可以替代很多手写 for 循环。
14节 并发
一个最基本但也最容易被忽视的常识:“读而不写”就不会有数据竞争
多用 const 关键字,尽可能让操作都是只读的,为多线程打造一个坚实的基础。
- 仅调用一次:call_flag,call_once(),可以实现类似单例的操作,避免发生并发初始化的问题
- 线程局部变量:thread_local,用于非共享数据
- 互斥量:Mutex,避免同时写;成本太高
- 原子变量:atomic_bool ,数据修改涉及较少的,可以使用原子变量
- 只能有基本类型的(
std::atomic<int>) 和一个 flagstd::atomic_flag - 原子变量禁用了拷贝构造,所以初始化时不能用 = 赋值的方式
- 把原子变量当作线程安全的全局计数器或者标志位
- async(),异步执行一个任务,返回一个 future,通过
get()获取结果
lock_guard, condition_variable, promise 等需要自己去查
c++20 引入了协程,用户态的线程,创建、切换成本低,开销更低,性能更好
#include <iostream>
#include <string>
#include <thread>
#include <unistd.h>
#include <future>
using namespace std;
//仅调用一次
//最好是静态、全局的(线程可见)
static std::once_flag flag;
//线程局部变量
thread_local int n = 0;
void test_once_flag()
auto thread_print = []()
//通过 std::call_once 调用,参数 flag 是否初始化作为是否执行
std::call_once(flag, []()
cout << "thread_print:"<< endl;
);
;
//启动一个线程,执行参数函数
thread t(thread_print);
thread t2(thread_print);
t.join();
t2.join();
void test_thread_local()
//按值捕获外部参数,内部要修改
auto f = [&](int p)
n += p;
cout << this_thread::get_id() << " thread run: " << n << endl;
;
//启动一个线程,执行参数函数
thread t(f, 10);
thread t2(f, 20);
cout << "test_thread_local >>> " << endl;
//等待执行完
t.join();
t2.join();
//原子标记位
static atomic_flag flag_a(false);
void test_atomic()
//atomic 禁用了拷贝构造函数,所以不能 = 赋值,而需要圆/花括号赋值
std::atomic<int> a0;
// std::atomic<int> b(1);
auto f = [&](int sleep_millis)
//修改标记位,通过标记位进行同步
auto set = flag_a.test_and_set();
if (set)
cout << "flag has been set" << endl;
else
cout << "flg set by " << this_thread::get_id() << endl;
//时间字面量?
this_thread::sleep_for(sleep_millis * 100ms);
//修改
a.store(1);
//获取
cout << "load a: " << a.load() << endl;
;
thread thread_a(f, 5);
thread thread_b(f, 7);
thread_a.join();
thread_b.join();
void test_async()
auto task = [](const auto& x)
this_thread::sleep_for(x * 1ms);
cout << this_thread::get_id() << " sleep for " << x << endl;
return x * 2;
;
//不获取返回值的话,就变成了同步?!
std::async(task, 100);
//启动一个异步任务,不保证立刻执行
//返回一个 future
auto f = std::async(task, 100);
//等待执行结束
f.wait();
//获取结果, get 只能调用一次?
cout << "valid ? " << f.valid() << endl;
cout << "get ? " << f.get() << endl;
cout << "get 2 ? " << f.get() << endl;
void ConcurrentTest::run()
test_once_flag();
test_thread_local();
test_atomic();
test_async();
15 节 序列化
https://time.geekbang.org/column/article/245880
- c++如何添加第三方依赖库?
- g++ -I 包含查找路径?
json, messagePack, pb 都敲一下
为什么需要序列化,不能直接 memcpy 吗?
直接memcpy,同一种语言不同机器,或者不同语言可能存在兼容问题(变量内存存储布局、编码可能不同),而Json是一种标准,且不同语言间统一
json不存在大小端,字节序的问题吧,反正就是一个字符串。messagepack这种二进制格式的东西,才要考虑大小端。
16 节 网络通信
使用 libcurl 进行网络请求的四个步骤:初始化句柄、设置参数、发送请求、清理句柄
(无捕获的 lambda 可以转成函数指针)
- cpr:对 libcurl 的封装
- ZMQ:无阻塞传递海量数据;消息队列,可以用于高并发场景
看的时候可以先从代码风格看起,再熟悉C++关键字的用法,再到整体架构、接口设计。不能心急,不要想着几天或者一个月就能看完。而且也没必要完全看懂,只要能从中学到一两个点就可以说是值得了。
17 节 和脚本语言混合使用
写 Lua 扩展模块的时候,内部可以用 C++,但对外的接口必须转换成纯 C 函数(extern “C”)。
C++ 高效、灵活,但开发周期长、成本高,在混合系统里可以辅助其他语言,编写各种底层模块提供扩展功能,从而扬长避短;
Python 很“大众”,但比较复杂、性能不是特别高;而 Lua 比较“小众”,很小巧,有 LuaJIT 让它运行速度极快。你可以结合自己的实际情况来选择,比如语言的熟悉程度、项目的功能 / 性能需求、开发的难易度,等等。
从零开始学C++,我的建议是不要去抠那些内存管理、指针、构造/析构等细枝末节,先把C++当做java、Python来用,有了一些实际经验体会后再了解底层机制。
C++偏向在底层写高性能组件,Python实现业务逻辑,而服务器应用一般业务比较多,这样就难以发挥C++
18 节 性能分析
在运行阶段能做、应该做的事情主要有三件:调试(Debug)、测试(Test)和性能分析(Performance Profiling)
GDB:让高速的 CPU 慢下来,让我们可以理清程序的状态
什么是性能分析呢?
你可以把它跟 Code Review 对比一下。Code Review 是一种静态的程序分析方法,在编码阶段通过观察源码来优化程序、找出隐藏的 Bug。而性能分析是一种动态的程序分析方法,在运行阶段采集程序的各种信息,再整合、研究,找出软件运行的“瓶颈”,为进一步优化性能提供依据,指明方向。
性能分析的关键是测量,而测量就需要使用工具
- Linux 系统自己就内置了很多用于性能分析的工具,比如 top、sar、vmstat、netstat,等等。但是,Linux 的性能分析工具太多、太杂,有点“乱花渐欲迷人眼”的感觉,想要学会并用在实际项目里,不狠下一番功夫是不行的。
- top 还可以按 M 和 P 查看指定内容?!
- pstack:查看进程的调用栈信息(静态数据)【试一下】
- strace:系统正在进行的系统调用(念哥分析 PerfDog 就是通过这个?)
把 pstack 和 strace 结合起来,你大概就可以知道,进程在用户空间和内核空间都干了些什么。当进程的 CPU 利用率过高或者过低的时候,我们有很大概率能直接发现瓶颈所在。
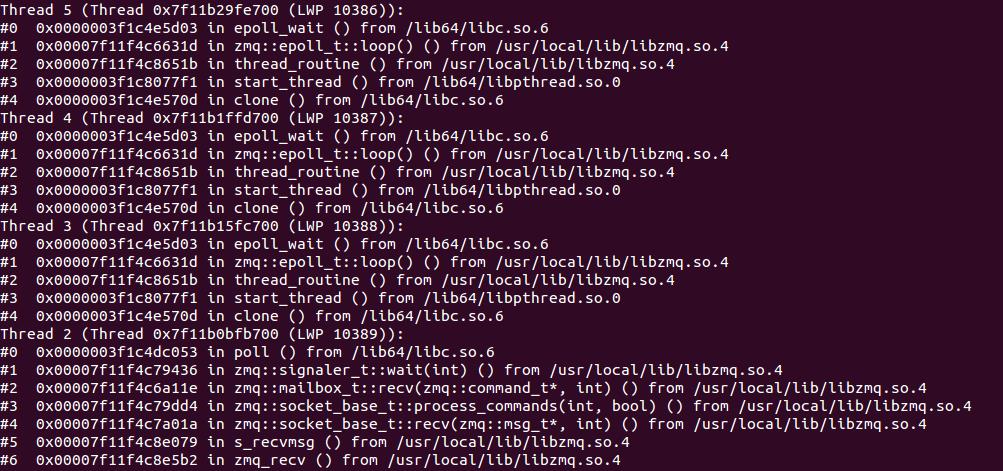

perf 可以说是 pstack 和 strace 的“高级版”,它按照固定的频率去“采样”,相当于连续执行多次的 pstack,然后再统计函数的调用次数,算出百分比。只要采样的频率足够大,把这些“瞬时截面”组合在一起,就可以得到进程运行时的可信数据,比较全面地描述出 CPU 使用情况。
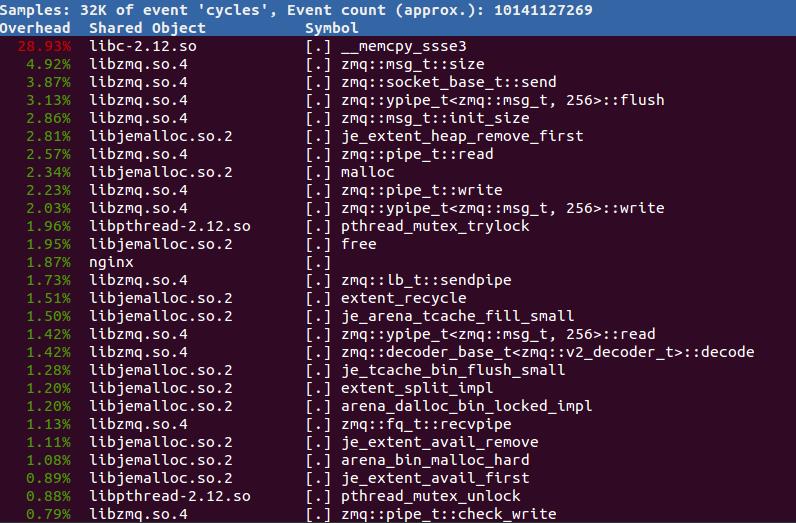
gperftools 是“侵入”式的性能分析工具,能够生成文本或者图形化的分析报告,最直观的方式是火焰图。
ASAN,检测内存问题
19 20 设计模式
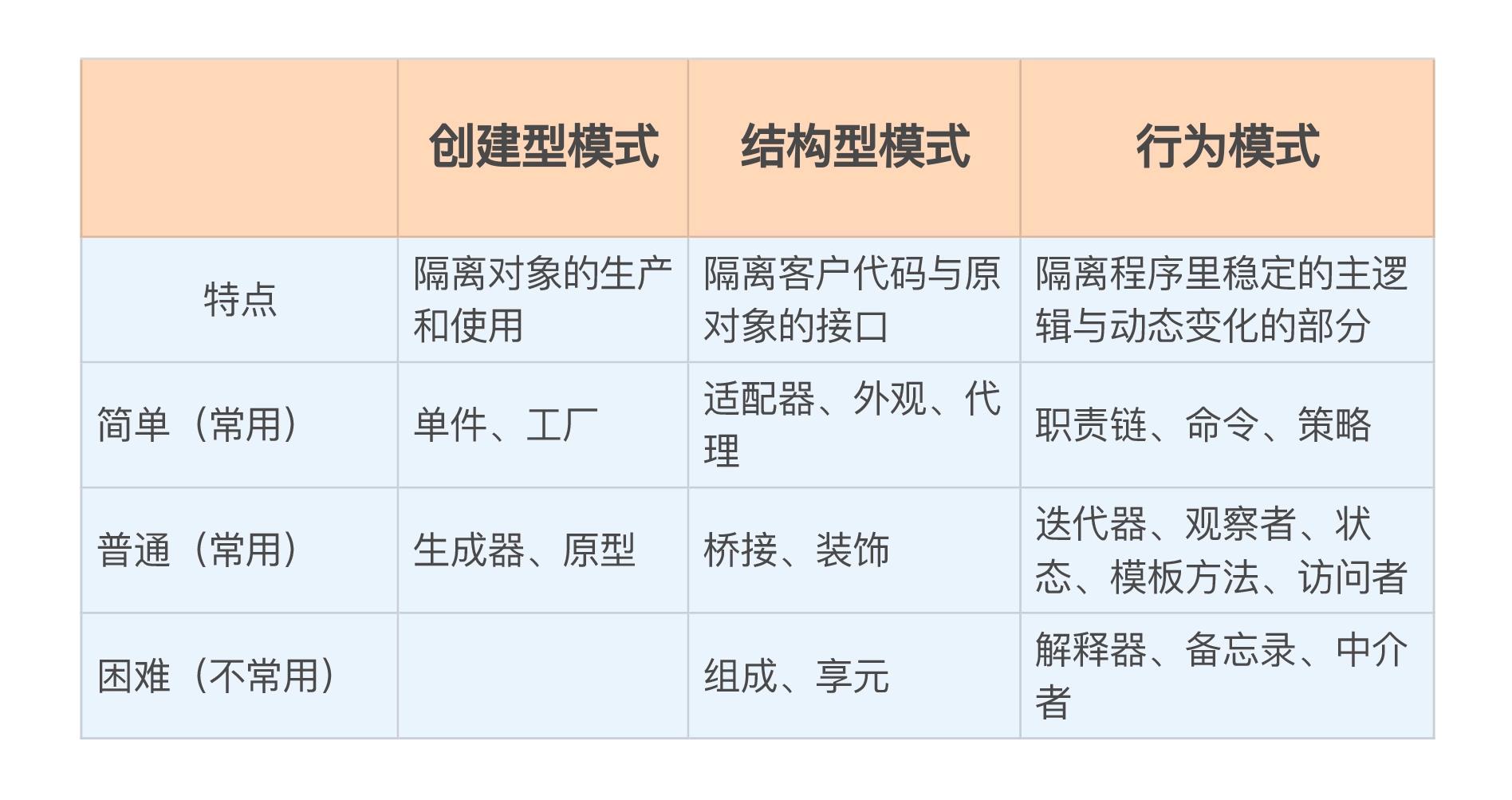
经典的《设计模式》一书里面介绍了 23 个模式,并依据设计目的把它们分成了三大类:创建型模式、结构型模式和行为模式。
这三类模式分别对应了开发面向对象系统的三个关键问题:如何创建对象、如何组合对象,以及如何处理对象之间的动态通信和职责分配。解决了这三大问题,软件系统的“架子”也就基本上搭出来了。
创建,结构,行为
模式里的结构和实现方式直接表现为代码,可能是最容易学习的部分,但我认为,其实这些反而是最不重要的。
你更应该去关注它的参与者、设计意图、面对的问题、应用的场合、后续的效果等代码之外的部分,它们通常比实现代码更重要。
因为代码是“死”的,只能限定由某几种语言实现,而模式发现问题、分析问题、解决问题的思路是“活”的,适用性更广泛,这种思考“What、Where、When、Why、How”并逐步得出结论的过程,才是设计模式专家经验的真正价值。
21 节 实战项目
1.头文件
include guard(其实就是判断 #ifndef xx, #define xx, #endif)
通过判断内置属性,提供兼容处理的方法的宏,比如 deprecated 和 static_assert
2.自旋锁的头文件
类型别名,禁止拷贝构造和赋值函数,通过自旋重试、原子变量的 TAS 来判断获得锁
自定义的 LockGuard,用于在析构函数里 unlock
使用原子变量(atomic)可以实现自旋锁,比互斥量的成本要低,更高效
C++要求静态成员变量必须在cpp文件里定义实现,头文件里只是声明。
而在静态成员函数里声明静态变量,再以函数返回值的形式来使用,就不需要在cpp里重复写一遍,只要在头文件里写就行了。
22 节 实战项目 2
1.类名使用 CamelCase,函数和变量用 snake_case,成员变量加“m_”前缀
在编译阶段使用静态断言,保证整数、浮点数的精度
使用 final 终结类继承体系,不允许别人产生子类
使用 default 显示定义拷贝构造、拷贝赋值、转移构造、转移赋值等重要函数
using 定义类型别名
使用 noexcept 标记不抛出异常,优化函数
使用 const 来修饰常函数;
2.【SalesData】 跟着敲一下
代码里显式声明了转移构造和转移赋值函数,这样,在放入容器的时候就避免了拷贝,能提高运行效率。
3.MessagePack
小巧轻便,而且用起来也很容易,只要在类定义里添加一个宏,就可以实现序列化:public: MSGPACK_DEFINE(m_id, m_sold, m_revenue); // 实现MessagePack序列化功能
4.Summary 类
关联了好几个类的核心类
类型别名对于它来说就特别重要,不仅可以简化代码,也方便后续的维护
锁不影响类的状态,所以要用 mutable 修饰??
lockGuard 使用很简单,申明一个全局 lock 变量,然后在访问数据的函数里,创建临时的 lockGuard(参数是这个 lock)。获取到 lock 时才会继续执行,然后在走出代码块后,就会析构。简单、安全
在使用 lambda 表达式的时候,要特别注意捕获变量的生命周期,如果是在线程里异步执行,应当尽量用智能指针的【值】捕获,虽然有点麻烦,但比较安全
5.搭建 http 服务
介绍及Windows:https://time.geekbang.org/column/article/100124
Mac/Linux:https://time.geekbang.org/column/article/146833
OpenResty 使用介绍:https://www.runoob.com/w3cnote/openresty-intro.html
问题记录
C++ undefined reference:
1.这个符号的确不存在
- 检查依赖的 so 有没有添加到 target_link_libraries 里
2.符号存在,但命名规则不对(C 与 C++ 不同)
- C++ 调用 C 方法,需要在 #include 前,用 extern “C” 包围
android NDK 报错:undefined reference to ‘main‘(invalid character)解决办法
今天遇到一个奇怪的问题,报错如下:
* What went wrong:
Execution failed for task ':profmancompat:externalNativeBuildRelease'.
> Build command failed.
Error while executing process /Users/simon/Library/Android/sdk/cmake/3.10.2.4988404/bin/ninja with arguments -C /Users/simon/AndroidStudioProjects/profmancompat/profmancompat/.cxx/cmake/release/armeabi-v7a profmancompat-lib
ninja: Entering directory `/Users/simon/AndroidStudioProjects/profmancompat/profmancompat/.cxx/cmake/release/armeabi-v7a'
[1/2] Building CXX object CMakeFiles/profmancompat-lib.dir/profmancompat.cpp.o
[2/2] Linking CXX executable profmancompat-lib
FAILED: profmancompat-lib
: && /Users/simon/Library/Android/sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/darwin-x86_64/bin/clang++ --target=armv7-none-linux-androideabi16 --gcc-toolchain=/Users/simon/Library/Android/sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/darwin-x86_64 --sysroot=/Users/simon/Library/Android/sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/darwin-x86_64/sysroot -g -DANDROID -fdata-sections -ffunction-sections -funwind-tables -fstack-protector-strong -no-canonical-prefixes -D_FORTIFY_SOURCE=2 -march=armv7-a -mthumb -Wformat -Werror=format-security -std=c++11 -g -Oz -DNDEBUG -Wl,--exclude-libs,libgcc_real.a -Wl,--exclude-libs,libatomic.a -static-libstdc++ -Wl,--build-id -Wl,--fatal-warnings -Wl,--exclude-libs,libunwind.a -Wl,--no-undefined -Qunused-arguments -Wl,--gc-sections CMakeFiles/profmancompat-lib.dir/profmancompat.cpp.o -o profmancompat-lib -L/Users/simon/AndroidStudioProjects/profmancompat/profmancompat/src/main/cpp/../jniLibs/armeabi-v7a -lprofman-slib -lprofman-29 -llog -latomic -lm && :
/Users/simon/Library/Android/sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/darwin-x86_64/lib/gcc/arm-linux-androideabi/4.9.x/../../../../arm-linux-androideabi/bin/ld: error: CMakeFiles/profmancompat-lib.dir/profmancompat.cpp.o:1:3: invalid character
/Users/simon/Library/Android/sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/darwin-x86_64/lib/gcc/arm-linux-androideabi/4.9.x/../../../../arm-linux-androideabi/bin/ld: error: CMakeFiles/profmancompat-lib.dir/profmancompat.cpp.o:1:3: syntax error, unexpected $end
/Users/simon/Library/Android/sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/darwin-x86_64/lib/gcc/arm-linux-androideabi/4.9.x/../../../../arm-linux-androideabi/bin/ld: error: CMakeFiles/profmancompat-lib.dir/profmancompat.cpp.o: not an object or archive
/Users/simon/Library/Android/sdk/ndk/21.0.6113669/toolchains/llvm/prebuilt/darwin-x86_64/sysroot/usr/lib/arm-linux-androideabi/16/crtbegin_dynamic.o:crtbegin.c:function _start_main: error: undefined reference to 'main'
clang++: error: linker command failed with exit code 1 (use -v to see invocation)
ninja: build stopped: subcommand failed.
重点是这几句:
- profmancompat.cpp.o:1:3: invalid character
- profmancompat.cpp.o:1:3: syntax error, unexpected $end
- crtbegin_dynamic.o:crtbegin.c:function _start_main: error: undefined reference to ‘main’
搜了下关键字,回答基本上是 main 定义的问题,和我实际情况不符。
在尝试把代码里无关的字符删除后,还是不行,那报错信息里的字符究竟是哪儿来的呢?
后来盯着 CMakeList,看到这些编译、link 优化项,心想也没有可能是这些的配置导致的:
add_compile_options(-Oz -flto -ffunction-sections -fdata-sections -fexceptions -frtti)
set(CMAKE_SHARED_LINKER_FLAGS "$CMAKE_SHARED_LINKER_FLAGS -O3 -flto -Wl,--exclude-libs,ALL -Wl,--gc-sections -Wl,--no-fatal-warnings")
从 https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html 里查到,-flto 大概的作用就是:在编译时,会在生成的目标文件里,插入一个特殊的格式信息(GIMPLE 格式)。然后在链接时,读取多个目标文件里的 GIMPLE 信息,合并成一个。这样 gcc 就能做一些内联优化,从而减少最终生成物体积。

那有没有可能是 -flto 优化过程中生成的信息导致了这个问题呢?
试着删除这个信息后,居然真的编译通过了!
这个问题耗费了些时间,虽然具体原因还不清楚,但希望遇到同样问题的同学,可以多一个尝试选择。
以上是关于重温 C/C++ 笔记的主要内容,如果未能解决你的问题,请参考以下文章