简单算法汇总
Posted 流云易采
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单算法汇总相关的知识,希望对你有一定的参考价值。
一、全排列问题(Permutation)
问题描述:即给定1,2,3,返回123,132,213,231,312,321
《Permutation》
1)无顺序的全排列问题:
将序列P(n) = 1….. n的全排列问题看成P(n)=1,P(n-1) + 2,P(n-1)…..的问题,即确定第一个元素的值为1,然后和剩下n-1个元素的全排列结果组合到一起;然后再将1和剩下的每个元素进行交换,然后和其剩下的n-1个元素排列结果进行组合;显然这是一个递归问题。
// 递归实现
public void permutation(int[] datas, int index )
if (datas == null || index < 0 || index >= datas. length) // 差错控制
return;
// 递归终点
if (index == datas .length - 1)
print_data( datas);
for (int i = index ; i < datas .length ; i ++)
// 交换(注意i==index时,其实并没有交换)
swap( datas, i , index);
permutation( datas, index + 1);
swap( datas, i , index);
2)有重复值的全排列问题:
注意每次递归的时候去除重复值即可,即有重复值就不进行交换。
// 非重复情况
public void permutationNoRepeat(int[] datas, int index )
if (datas == null || index < 0) // 差错控制
return;
if (index >= datas .length - 1)
print_data( datas);
return;
for (int i = index ; i < datas .length ; i ++)
// 取出重复值
if ((i != index ) && (datas[i] == datas[index]))
continue;
swap( datas, i , index);
permutationNoRepeat( datas, index + 1);
swap( datas, i , index);
3)找到下一个更大值(next_permutation)
即1342,找到下一个更大值1423;
解题思路:
基本思想是从后往前遍历,找到第一个递增的二元对(即a[j] < a[j+1]);然后从后往前遍历到j+1位置,找到第一个k值a[k]>a[j],交换k和j,然后将j+1后面的序列反转;
注意增序列则表示字典序较小,减序列则表示字典序较大;如果遍历找不到增序列,表示当前数值已经是最大值。
原理:
http://jingyan.baidu.com/article/63acb44a90370061fcc17e18.html
public boolean next_permutation(int[] datas)
if (datas == null || datas.length == 0)
return true ;
int p1 = datas .length - 2;
int p2 = datas .length - 1;
for (; p1 >= 0; p1 --)
if (datas [p1 ] < datas [p1 + 1])
break;
if (p1 == -1)
reverse( datas, 0, datas. length - 1);
return true ;
else
for (; p2 > p1 ; p2 --)
if (datas [p2 ] > datas [p1 ])
swap( datas, p1, p2);
reverse( datas, p1 + 1, datas. length - 1);
print_data( datas);
return false ;
// 颠倒数组
private void reverse(int[] datas, int start , int end)
while (start < end )
swap( datas, start ++, end --);
4)有顺序的全排列(可以看做非递归实现)
解题思路:使用next_permutation也以获得全排列,即不断调用next_permutation来获得更大值,然后依次输出
public void permutation(int[] datas)
if (datas == null)
return;
do
print_data( datas);
while (!next_permutation(datas )) ;
5)有特殊要求的全排列,比如要求4必须在3前面
解题思路:进行全排列,然后判断4和3的位置再进行输出;(?更好方法)
6)查找数字排列组合中的第k个组合:(Permutation Sequence)
解题思路:
即给定1,2,3,和3,返回全排列(123,132,213,231,312,321)中的第三个,即213
注意:
这里不需要将全排列计算出来,然后再得到第k个;
或者使用nextPermutation来计算第k个;这两种时间复杂度都较大;
最好的做法:是直接利用数学知识进行计算:
还是分为两层来看,第一位确定的话,后面P(n-1)的全排列为(n-1)!,则可以根据算法判断出第一位是哪个数值;剩下的类推。
public class Solution
public String getPermutation( int n , int k)
if ((n <= 0) || (n > 9) || ( k <= 0) || ( k > countN( n)))
return "" ;
// 记录结果字符串
StringBuilder resBder = new StringBuilder();
// 记录当前数字集合中剩下的未使用数字
List<Integer> remainList = new ArrayList <>();
// 初始化remainList
for (int i = 1; i <= n ; i ++)
remainList.add(i );
k--;
while (n > 1)
int count = countN(n - 1);
int index = k / count ;
// 添加结果数字
resBder.append( remainList.get(index ));
// 更新,进行下一层循环
remainList.remove(index );
k %= count;
n--;
resBder.append( remainList.get(0));
return resBder .toString();
// 计算每个数字的阶乘
private int countN(int n )
int result = 1;
while (n > 0)
result *= n--;
return result ;
一、二叉树问题汇总:
1)二叉树三种遍历非递归实现
2)重建二叉树
3)判断树A是否为树B的子树
4)二叉树镜像
5)从上往下打印二叉树
6)二叉搜索树的后序遍历
7)二叉搜索树转化为双向链表
8)二叉树中和为某一值的路径
9)求二叉树的深度
10)平衡二叉树
二、递归问题汇总
1)魔术索引问题
即一个递增序列,满足A[i]=i的称为魔术索引;
1>无重复值的魔术索引问题:二分法
2>有重复值:缩小范围法
2)跳台阶、斐波那契
3)机器人走方格:都注意使用空间存储来优化;
4)N皇后问题:
回溯法:因为每一行只能有一个皇后,所以使用一个一维数组index[]来记录每一行的皇后的列的位置即可,然后给数组中的每个元素赋个初始值-1,表示当前行的位置还没有确定;
然后从第一个皇后开始赋值,从0开始,再给第二个皇后赋值,也是从0开始遍历,然后写一个判断当前index[]矩阵是否合法的函数,每次给一个皇后赋值的时候,都需要进行一次判断,如果合法,则继续给下一个皇后赋值;如果不合法,就取这一层对应的index里面的记录的数值比如说是m,然后给这个皇后赋值m+1,继续判断是否合法,重复之前操作;
如果在这一层,0-n-1全部都赋值完了,皇后仍然没有找到合法的位置,那就采用回溯法,把这一层的index值重新置为-1,回到上一层设置上一层的皇后的位置,往右移一步,重复之间操作。
直到赋值到第N层,所有皇后位置都合法之后,再将结果输出;
因为可能的结果不止有一种,当输出一种结果之后,回溯到N-1层,重新开始之前的设置,检查操作;
递归法:递归法比较简单,比如八皇后问题,就可以看成已知其中一个皇后位置,求其他7个的位置;然后再确定第二个皇后的位置,求剩下6个皇后的位置;以此类推进行递归,直至递归到最后一层,输出结果。
三、最远距离问题JumpGame:
即判断[3,1,3,1,1,0,4]是否可到达。
解决方法:很简单,一直往前走,计算每一步能到达的最远位置index+A[index];和之前记录的最远位置reach做比较,大于则更新reach值;循环的终点是到了终点即i==n了或者i>reach了,这个时候判断i==n(注意是n,因为在n-1后,还会再i++,然后循环才能推出)。
public boolean canJump(int[] nums)
int i = 0;
int n = nums.length;
for ( int reach = 0; i < n && i <= reach; ++i)
reach = Math. max(i + nums[i], reach);
return i == n;
四、构造顺序矩阵和打印循环顺序矩阵Matrix:
《leetcode-54 Spiral Matrix 顺时针打印矩阵(《剑指offer》面试题20)》
《leetcode 58、Length of Last Word;59、Spiral Matrix II ;60、Permutation Sequence》
解题思路:定义上下左右四个维度的限定值,然后向右,向下,向左,向上进行遍历,并注意更新相应值。
// 构造序列
public int [][] generateMatrix(int n)
if (n < 0)
return null ;
int[][] matrix = new int[n][n];
// 记录上下左右边界值
int left = 0;
int right = n - 1;
int top = 0;
int bottom = n - 1;
// 注意起始值为1
int count = 1;
while ((left <= right ) && (top <= bottom))
// 往右走进行赋值
for (int j = left ; j <= right ; j ++)
matrix[ top][ j] = count++;
++ top; // 更新边界值
// 向下走进行赋值
for (int i = top ; i <= bottom ; i ++)
matrix[ i][ right] = count++;
-- right;
// 向左走进行赋值
for (int j = right ; j >= left ; j --)
matrix[ bottom][ j] = count++;
-- bottom;
// 向上走进行赋值
for (int i = bottom ; i >= top ; i --)
matrix[ i][ left] = count++;
++ left;
return matrix ;
// 打印序列
public List<Integer> spiralOrder(int[][] matrix)
List<Integer> result = new ArrayList<>();
if ((matrix == null) || (matrix.length == 0) || ( matrix[0]. length == 0))
return result ;
int left = 0; int right = matrix[0].length - 1;
int top = 0; int bottom = matrix.length - 1;
while ((left <= right ) && (top <= bottom))
// ==== 先向右遍历 ===== //
for (int j = left ; j <= right ; j ++)
result.add( matrix[ top][ j]);
top++; // 遍历后要注意更新四个维度的值
// ===== 向下遍历 ===== //
for (int i = top ; i <= bottom ; i ++)
result.add( matrix[ i][ right]);
right--;
// ===== 向左遍历 ===== //
for (int j = right ; j >= left ; j --)
result.add( matrix[ bottom][ j]);
bottom--;
// ===== 向上遍历 ===== //
for (int i = bottom ; i >= top ; i --)
result.add( matrix[ i][ left]);
left++;
return result ;
五、连续子数组的最大和
解题思路:使用一个max记录当前最大值,使用一个curSum来记录遍历数组时候的临时的和;
遍历数组,比如来到第i个元素,如果之前的curSum<0,那么curSum再加上a[i]只会使得相加值更小,因此取更大值,也就是令curSum=a[i],把前面的和序列舍弃掉;
如果curSum>=0,则可以直接把两个值相加来作为新的curSum;
然后再将curSum和max做比较,去更大值来更新max值,最后遍历完一遍,返回max值就是最大的值。
六、数值的整数次方pow:
解题思路:注意处理n<0的情况,n<0时,要把a转化成1/a;
还要注意处理底数为0,而指数却为负数的不合法情况;
private double power(double x, int n)
if (n < 0)
n = - n; x = 1.0 / x;
double result = 1.0;
for ( double base = x ;n > 0; n >>= 1)
if ((n & 0x1) == 1)
result *= base;
base *= base;
return result;
七、判断是否为同位词:
即“ate””eat” “tae”为同位词;从一串字符串中找出同位词:
解题思路:使用HashMap,先对所有词进行字典序排序,然后比对。
八、字符串数组排序:
由于字符串实现了Comparable接口,可以比较两个字符串之间的大小,因此可以像实现int数组排序一样实现字符串数组的排序。
九、k个排序链表合并成一个排序链表(或者k个排序数组合并成一个排序数组)
解题思路:创建一个k阶的最小堆,创建堆的时间复杂度o(n*logn);取最小值的事件复杂度为O(1);删除最小值,加入一个新值,调整堆的时间复杂度为O(lgn);
每次取最小值,最为新链表(新数组)的下一个值;然后再从该数值对应数组中取出一个新值放在堆顶,然后调整堆,重复上述过程;
也可以使用败者树来实现。
相关题:找到一个数组中的第k大的值
思路:维护一个k阶最小堆,新值和堆顶元素进行比较,如果大于堆顶元素值,则替换堆顶元素,调整堆;
十、求两个整数的最大公约数;最小公倍数(辗转相除法)
public int maxgcp(int x, int y)
int num1 = x, num2 = y;
// 向排序,即将较大值移到前面
if (x < y)
int temp = x ;
x = y;
y = temp;
// 辗转相除法
int r = 1;
while ( r != 0)
r = x % y;
x = y;
y = r;
System. out.println("最大公约数:" + x );
System. out.println("最小公倍数:" + num1 * num2 / x );
return x;
十一、求格雷码:
格雷码是二进制转化成的编码,它的相邻两个数的格雷码只有一个位是不同的;最大数和最小数也只有一个位不同;所以适应了真正电气环境下数值不能连续变化多位的情况;
编码:二进制转化为格雷码: 第一位保持不变,然后从最右边一位开始,与左边一位进行异或,得到的异或值即为格雷码;
1001001010 ==> 1101101111
解码:格雷码转化为二进制: 解码从最左边开始,一个为解码值保持不前,然后从左边第二位开始,每一位和前一位的解码值进行异或,得到的值即为解码值。
十二、两个链表的公共交点:
解法:两个链表相交,则链表相交的第一个公共点之后的所有节点一定是相交的;即两个链表是呈Y型的;
1)两个链表无环时的解法:
(1)可以先遍历两条链表,得到两个链表的长度m,n;然后双指针,一个先走m-n步(假设m>n),然后两个指针同时出发,第一个相交的节点即为公共节点;若一直遍历结束也没有公共节点,则两个链表不相交;
(2)方法同一,但不需要遍历完两个链表来获得两个链表的长度;记两个链表为A、B,可以设置两个指针p、q,同时出发,当q到达链表尾(即为NULL时),此时从链表A头部出发一个指针a;当p到达链表尾时,此时从链表B头部出发一个指针b;则a,b转化为方法一中的问题;(两个方法的时间复杂度相同)
(3)如果两个链表相交,由于其公共节点之后的链表相同;此时将其中一个链表链接到另一个链表之后,形成的新链表一定有环,则原问题转化为求一个有环链表的环的公共交点问题;
2)考虑链表有环
如果两个有环的链表相交,那么它们的环必定为公共环。如果交点不在环上,即在环前面的直链上,即转化为前面的连个无环链表求解公共点的问题,第一个公共点就是第一个交点。但是如果交点在环上,即环的入口点不同,那么任一环的入口点都可为第一公共点。
十三、删除字符串中的指定字符:
题目:输入两个字符串,从第一字符串中删除第二个字符串中所有的字符。例如,输入”They are students.”和”aeiou”,则删除之后的第一个字符串变成”Thy r stdnts.”。
解题思路:基本思想是遍历字符串s1,判断字符串s1中的每个字符在s2中是否存在,如果存在则删除;
这里就需要考虑两个细节:
1)删除字符问题
一个是删除字符的处理;传统方法是删除之后,让字符串数组后的所有字节往前移一位,这样操作完所有字符的时间复杂度为O(n^2);明显有可以优化的空间:
使用两个指针,pFast,pSlow;当有字符需要删除时,pSlow不变,pFast前移;当有字符不需要删除时,将pSlow和pFast指向的字符交换;最后取0-pSlow数组的字符组成的字符串即可。基本思想是将后面不需要删除的字符替换到前面来。
2)判断字符是否需要删除:
判断字符是否需要删除,即该字符是否在s2字符串中;可以使用的方法如Hash,使用HashMap或则HashSet把s2中的字符存储进来,然后遍历s1每个字符c在HashMap是否已经存在即可;时间复杂度为O(1);
同样的方法可以是使用一个boolean[256]数组,记录char(共256个)是否存在;原理类似Hash
十四、计算一个字符串中的最长无重复字符串:
问题描述:计算给定一个字符串,如”abcabcbb” 则其最长无重复字符串为 “abc”;字符串”bbbbb”其最长无重复字符串为”b”;
解题思路:使用一个256的int数组indexs来记录每个char在字符串中出现的位置;
如果indexs[i]为-1,表示当前测试字符串中没有出现过字节i,因此直接将indexs[i]赋值为i,即记录其出现位置;
如果indexs[i]不为-1,则表示已经出现过,这里要根据此算法分成两种情况讨论;这里使用一个start记录当前测试字符串的起始位置,即当前测试的字符串为start–i;如果indexs[i]小于start,表示该字节出现在测试字符串之前,因此可以当做-1情况对待;再者,如果已经存在,则当前字符串已经不是满足要求的唯一性字符串了,因此计算当前的非重复最大值,和系统当前记录的最大值作比较,记录更大值;然后测试下一个字符串,为满足非重复条件,则下一个测试字符串的起始位置需要从index[start]+1开始;
十五、求数组的最大值与最小值
1)基本的遍历法需要比较2N次;
2)采用双元素法,记录max和min;每次比较两个值,较小值和min做比较,较大值和max作比较;这样最终的比较次数为1.5*N次。
3)采用分治法;将数组分为两部分,分别得到两个子数组的最大值最小值,然后再合并在一起进行比较;
十六、找出数组中只出现一次的数:
1)其他的数都出现了偶数次:直接使用全部异或即可;
2)其他数出现的是奇数m次:则如果没有该特殊值,其他所有值二进制时二进制各个位相加之和肯定都能被m整数整除;再加上异常值,则所有位对于n进行取余,得到的值必然是该特殊值的二进制表示。
十七、数组中出现次数超过一半的数:
解题思路:
解法一:将原问题转化为求数组的中位数,采用快速排序的思想,每一次Partition取末位为哨兵,遍历将小于、大于哨兵的数分别移至哨兵左右,最后返回哨兵在处理后的数组中的位置。不断缩小要处理的数组的长度大小,最终确定返回值为数组长度一半的元素,即为中位数。
解法二:由于题设该数字出现的次数大于其他所有数字出现的次数,故用两个变量,一个表示数字num_data,一个表示次数;当下一个数字等于num_data时,则times加1;如若不等于,time减1;直至times等于0,则将num_data更换为下一个数字;由题知,最后得到的num_data的结果必为所要求得的值。
十八、旋转数组:
问题描述:即给定一个数组如[1,2,3,4,5,6,7] ,及一个k=3,将后面k个数字旋转到前面来,则旋转之后的数组为[5,6,7,1,2,3,4].
解题思路:和旋转字符串问题比较类似,即先将数组分为两部分,后面k个数字为一组,前面n-k个为一组,将两组分别反转,然后再将整个数组反转即可;反转可以采用双指针法。
十八、判断一个数是否是2的n次方:
解题思路:
一个数num是2的n次方则二进制表示为(000010000…),则num-1是(000001111111…);其num与num-1二进制位必然没有一个相等;
因此判断num&(num - 1)是否等于0即可。
十九、计算一个数的二进制中1的个数:
解题思路:
解法一:直接转换成二进制然后循环右移取出二进制中每一位判断是否为1即可
解法二:使用n&(n-1);二进制中有几个1,就循环几次n&(n-1)得到0
二十、2Sum,3Sum,4Sum问题:
《leetcode-1 Two Sum 找到数组中两数字和为指定和》
《Leetcode-15 3Sum》
《leetcode-18 4Sum》
《leetcode-16 3Sum Closest》
问题描述:给定一个数组和一个target结果值,求2个/3个/4个数字的和为target的解法;
**解题思路:**2Sum问题典型的解决方式是使用双指针,从头部尾部同时往中间走进行判断;
首先对数组进行排序,时间复杂度为O(NlogN)
然后从i=0,j=end开始和末位的两个数字开始,计算两个之和sum,若sum大于目标值target,则需要一个较小的因子,j–;反之,i++;直至找到最终的结果
二十一、排序算法
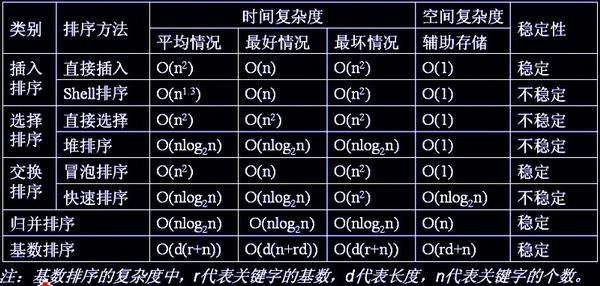
1、冒泡排序(交换排序):
在循环遍历中,每一次遍历数组将最大的数字通过交换沉到最后一位
时间复杂度(O(n^2)):最坏O(n^2),最好O(n);空间复杂度:O(1); 稳定
优化:
1)设置一个flag标示,当一次遍历有交换设置为true,没有交换时则表示前面数组已经有序,无需再做遍历
2)记录每一次遍历发生交换的最后位置,因为这个位置之后的数组肯定是有序的;最后交换位置为0时,循环结束
2、直接插入排序:
在循环遍历中,第j次遍历过程向已经排好序的数组a[1..j-1]插入a[j]
时间复杂度(O(n^2)):最坏O(n^2),最好O(n);空间复杂度:O(1);稳定
优化:查找插入排序,在插入的时候使用二分法
3、希尔排序(插入排序):将数组分为很多小序列,然后分别进行直接插入排序;待整个数组基本有序的时候,最后进行一次插入排序
时间复杂度(O(n^(1-2))):最坏O(n^2),最好O(n);空间复杂度:O(1);不稳定
实现,选取一个增量序列(递减到1)(比如x/2序列)
void ShellInsertSort(int a[], int n, int dk)
for(int i = dk ; i < n ; ++i )
if(a [i] < a [i - dk]) //若第i个元素大于i-1元素,直接插入。小于的话,移动有序表后插入
int j = i - dk ;
int x = a [i]; //复制为哨兵,即存储待排序元素
a[i] = a[i - dk]; //首先后移一个元素
while(x < a[j]) //查找在有序表的插入位置
a[j + dk] = a[j];
j -= dk; //元素后移
a[j + dk] = x; //插入到正确位置
print(a, n,i );
/**
* 先按增量d(n/2,n为要排序数的个数进行希尔排序
*
*/
void shellSort(int a[], int n)
int dk = n /2;
while(dk >= 1)
ShellInsertSort( a, n, dk);
dk = dk/2;
4、快速排序:
每一次循环选取一个中间值,将比这个值大的元素移动到中间的后面,比中间值小的移到中间值前面;这样分成了两个子序列,然后再对子序列进行快速排序。
时间复杂度:O(nlogn), 最好O(nlogn),最坏(基本有序时退化成冒泡)O(n^2);空间复杂度:O(1)+(递归栈的缓存空间最大O(n),最小O(logn)) 不稳定
private void quickSort(int[] a, int start , int end)
if (start < end )
int mid = partition(a, start, end);
quickSort( a, start, mid - 1);
quickSort( a, mid + 1, end);
private int partition(int[] a, int low , int high)
int temp = a [low ];
while (low < high )
while ((low < high ) && (a[high] >= temp))
-- high;
swap( a, low, high);
while ((low < high ) && (a[low] <= temp))
++ low;
swap( a, low, high);
a[ low] = temp;
return low ;
实现:单指针法,双指针法
快速排序的改进:
1)中枢值的选取:传统方法中使用最左元素或者最右元素,这样在数组基本有序时的性能较差(会退化成冒泡算法);
改进方法一:中枢值 pivot使用随机数来取代(但是产生随机数也会带来性能损耗)
方法二:pivot选取first-middle-last中的中间大小的那个值,时间复杂度会减少到12/7 ln(n)
方法三:median-of-three对小数组来说有很大的概率选择到一个比较好的pivot,但是对于大数组来说就不足以保证能够选择出一个好的pivot,因此还有个办法是所谓median-of-nine,这个怎么做呢?它是先从数组中分三次取样,每次取三个数,三个样品各取出中数,然后从这三个中数当中再取出一个中数作为pivot,也就是median-of-medians。取样也不是乱来,分别是在左端点、中点和右端点取样。什么时候采用median-of-nine去选择pivot,这里也有个数组大小的阀值,这个值也完全是经验值,设定在40,大小大于40的数组使用median-of-nine选择pivot,大小在7到40之间的数组使用median-of-three选择中数,大小等于7的数组直接选择中数,大小小于7的数组则直接使用插入排序
5、归并排序:
通过分治的思想,对数组序列进行切割,切割到最后每个子序列中只有一个元素的时候,然后再两两合并,最后每一次循环都是两个有序数组合并成一个有序数组的操作。 稳定
O(nlogn); O(nlogn); O(nlogn); 空间复杂度O(n);
private void mergeSort(int[] datas, int[] copy , int start, int end)
if (start < end )
int mid = (end + start ) / 2;
mergeSort( datas, copy, start, mid);
mergeSort( datas, copy, mid + 1, end);
merge( datas, copy, start, mid, end);
private void merge(int[] datas, int[] copy, int start , int mid, int end)
int i = start ;
int j = mid + 1;
int index = start ;
while ((i <= mid ) && (j <= end))
if (datas [i ] <= datas [j ])
copy[ index++] = datas[ i++];
else
copy[ index++] = datas[ j++];
while (i <= mid )
copy[ index++] = datas[ i++];
while (j <= end )
copy[ index++] = datas[ j++];
System. arraycopy(copy, start, datas, start, end - start + 1);
非递归实现方法:
void mergeSort2(int n)
int s =2,i ;
while(s <=n )
i=0;
while(i +s <=n )
merge(i,i+s-1,i+s/2-1);
i+= s;
//处理末尾残余部分
merge(i,n-1,i+s/2-1);
s*=2;
//最后再从头到尾处理一遍
merge(0,n-1,s/2-1);
6、简单选择排序:第i次遍历的时候,从i-n序列中找到最小值,与第i个元素进行交换。也就是每一趟遍历都选取一个最小元素作为第i元素值。
时间复杂度:O(n^2);最优: O(n^2);最差:O(n^2); 空间复杂度O(1);不稳定
7、堆排序:
叶子节点的值都大于或等于根节点的值(最小堆)
建堆:从n/2+1开始剩下的都为叶子节点,因此从n/2到0递减顺序,分别以每个节点为根节点建立最小堆。
堆的调整:比较左右子节点的值得到最小值,然后比较根节点与最小值,如果根节点的值要大,则不满足最小堆的概念,需要进行调整,将两者进行交换。然后再以交换后的位置为根节点,重复前面过程。
时间复杂度:O(nlogn);最优: O(nlogn);最差:O(nlogn); 空间复杂度O(1);不稳定
private void heapSort(int[] datas)
buildHeap( datas);
for (int i = datas .length - 1; i >= 0; i--)
System. out.printf("%d " , datas [0]);
// 交换data[0]和data[i];
swap( datas, i, 0);
// 注意这里的length为i
HeapAdjust( datas, 0, i);
// 建立堆
private void buildHeap(int[] datas)
for (int i = (datas .length - 1) / 2; i >= 0; i--)
HeapAdjust( datas, i, datas. length);
// 调整堆中节点位置
private void HeapAdjust(int[] datas, int s , int length)
int child = 2 * s + 1;
while (child < length )
// 如果右节点存在,并且小于左节点的值
if ((child + 1 < length) && ( datas[ child] > datas[ child + 1]))
child++;
// 如果大于子节点的值,则不满足最小堆的概念,故要进行调整
if (datas [s ] > datas [child ])
swap( datas, s, child);
s = child;
child = 2 * s + 1;
else
break;
8、基数排序/桶排序:线性,时间复杂度为O(n);
排序算法性能比较:
时间复杂度:
O(n^2)的有:直接插入排序,冒泡排序,简单选择排序
O(n^(1-2)): 希尔排序
O(nlogn):快速排序,归并排序,堆排序
O(n):线性:桶排序;基数排序
选择上:
基本有序时,选择直接插入排序,希尔排序;而快速排序会退化成冒泡排序;
平均性能上最优的是快速排序;在最坏情况下,性能上不如堆排序和归并排序,而n较大时,归并排序优于堆排序,但是其需要的存储空间要大。
直接插入排序在基本有序或者n较小时最佳。
稳定性:
即值相同的关键字在排序前后位置先后顺序不变
稳定的:冒泡、插入、归并、基数
不稳定:选择、希尔、快速、堆;
设待排序元素的个数为n.
1)当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序序。
快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
堆排序 : 如果内存空间允许且要求稳定性的,
归并排序:它有一定数量的数据移动,所以我们可能过与插入排序组合,先获得一定长度的序列,然后再合并,在效率上将有所提高。
2) 当n较大,内存空间允许,且要求稳定性 =》归并排序
3)当n较小,可采用直接插入或直接选择排序。
直接插入排序:当元素分布有序,直接插入排序将大大减少比较次数和移动记录的次数。
直接选择排序 :元素分布有序,如果不要求稳定性,选择直接选择排序
5)一般不使用或不直接使用传统的冒泡排序。
6)基数排序
它是一种稳定的排序算法,但有一定的局限性:
1、关键字可分解。
2、记录的关键字位数较少,如果密集更好
3、如果是数字时,最好是无符号的,否则将增加相应的映射复杂度,可先将其正负分开排序。
二十二、外部排序:
1)根据内存能够缓存的大小,将全部数据进行分段,加入到内存,进行内部排序。
2)然后进行k-路归并;k路归并使用败者树;
http://blog.csdn.net/whz_zb/article/details/7425152
胜者树:锦标赛排序
败者树:使用节点来记录失败的元素;胜者往上一层进行比较,扩展一个节点来记录最终的冠军;
败者树重构只需要新添加的元素和父节点进行比较(即败者进行比较);而胜者树则是需要和右节点进行比较;
二十四、二分查找:
考虑有数值的相同情况
private static int binarySearch(int[] datas, int start , int end, int target)
int mid = 0;
while (start <= end )
mid = start + ( end - start) / 2;
if (datas [mid ] > target )
end = mid - 1;
else
start = mid + 1;
// return mid表示查找到相同值;或者未查找到时的可插入位置
// 如果是查找顺序的可插入位置,则需要返回start
return mid ;
// 获取next数组
private void getNext(char[] p, int[] next )
// 初始化的值
int j = 0;
next[ j] = -1;
int k = next [0];
// j对应的获取next[j+1]
while (j < p .length - 1)
// 注意k的初始值
if (k == -1 || p[j] == p[k])
next[++ j] = ++ k;
else
k = next[ k];
private int KMP(String s, String p)
if (s .length() < p.length())
return -1;
int i = 0;
int j = 0;
// 获取next数组
int[] next = new int[p.length()];
getNext( p.toCharArray(), next);
while ((i < s .length()) && (j < p.length()))
if (j == - 1 || s.charAt(i) == p.charAt(j))
++ i; ++ j;
else
j = next[ j];
// 返回匹配位置
if (j >= p .length())
return i - p .length();
return -1;
改进的算法:
// 获取nextval数组
private void getNextval(char[] p, int[] next )
int j = 0;
next[ j] = -1;
int k = next [0];
while (j < p .length - 1)
if (k == -1 || p[k] == p[j])
k++;
j++;
if (p [k ] != p [j ])
next[ j] = k;
else
next[ j] = next[ k];
else
k = next[ k];
以上是关于简单算法汇总的主要内容,如果未能解决你的问题,请参考以下文章