数据库八股系列——MySQL
Posted _瞳孔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库八股系列——MySQL相关的知识,希望对你有一定的参考价值。
如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:瞳孔空间
以前也写了点相关的博客:
1.mysql索引为什么要用B+树实现
- B+树层级较低,能显著减少IO次数,提高效率
- B+树的查询效率更加稳定,因为数据放在叶子节点
- B+树能提高范围查询的效率,因为叶子节点之间由双向链表连接
2.为什么在数据库中建议使用自增主键
- 自增主键往往占用空间比较小,int 占 4 个字节,bigint 占 8 个字节。由于二级索引的叶子节点存储的就是主键,所以如果主键占用空间小,意味着二级索引的叶子节点将来占用的空间小(间接降低 B+Tree 的高度,提高搜索效率)。
- 自增主键插入的时候比较快,直接插入即可,不会涉及到叶子节点分裂等问题(不需要挪动其他记录);而其他非自增主键插入的时候,可能要插入到两个已有的数据中间,就有可能导致叶子节点分裂等问题,插入效率低(要挪动其他记录)。
3.什么是回表
大家知道,MySQL 中的索引有很多中不同的分类方式,可以按照数据结构分,可以按照逻辑角度分,也可以按照物理存储分,其中,按照物理存储方式,可以分为聚簇索引和非聚簇索引。
我们日常所说的主键索引,其实就是聚簇索引(Clustered Index);主键索引之外,其他的都称之为非主键索引,非主键索引也被称为二级索引(Secondary Index),或者叫作辅助索引。
对于主键索引和非主键索引,使用的数据结构都是 B+Tree,的区别在于叶子结点中存储的内容不同:
- 主键索引的叶子结点存储的是一行完整的数据。
- 非主键索引的叶子结点存储的则是主键值。
所以,当我们需要查询的时候:
- 如果是通过主键索引来查询数据,例如
select * from user where id=100,那么此时只需要搜索主键索引的 B+Tree 就可以找到数据。 - 如果是通过非主键索引来查询数据,例如
select * from user where username='javaboy',那么此时需要先搜索 username 这一列索引的 B+Tree,搜索完成后得到主键的值,然后再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。
对于第二种查询方式而言,一共搜索了两棵 B+Tree,次搜索 B+Tree 拿到主键值后再去搜索主键索引的 B+Tree,这个过程就是所谓的回表。
从上面的分析中我们也能看出,通过非主键索引查询要扫描两棵 B+Tree,而通过主键索引查询只需要扫描一棵 B+Tree,所以如果条件允许,还是建议在查询中优先选择通过主键索引进行搜索。
4.什么事覆盖索引
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。
5.什么是最左匹配原则
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
例如:b = 2 如果建立(a,b)顺序的索引,是匹配不到(a,b)索引的;但是如果查询条件是a = 1 and b = 2或者a=1(又或者是b = 2 and b = 1)就可以,因为优化器会自动调整a,b的顺序。再比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
最左匹配原则都是针对联合索引来说的,所以我们有必要了解一下联合索引的原理。了解了联合索引,那么为什么会有最左匹配原则这种说法也就理解了。
我们都知道索引的底层是一颗B+树,那么联合索引当然还是一颗B+树,只不过联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样:
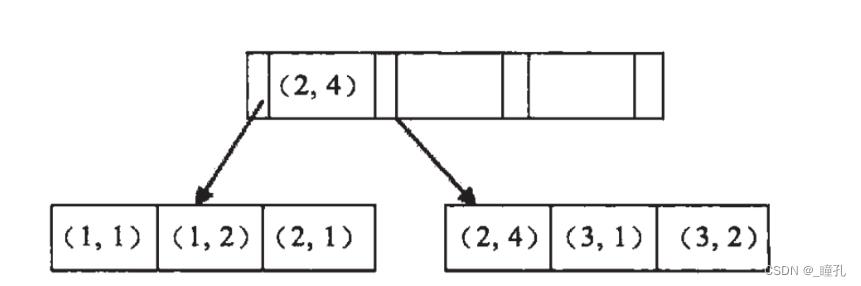
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
6.什么是索引下推
索引下推(Index Condition Pushdown,简称ICP),是MySQL5.6版本的新特性,它能减少回表查询次数,提高查询效率。
我们先简单了解一下MySQL大概的架构:
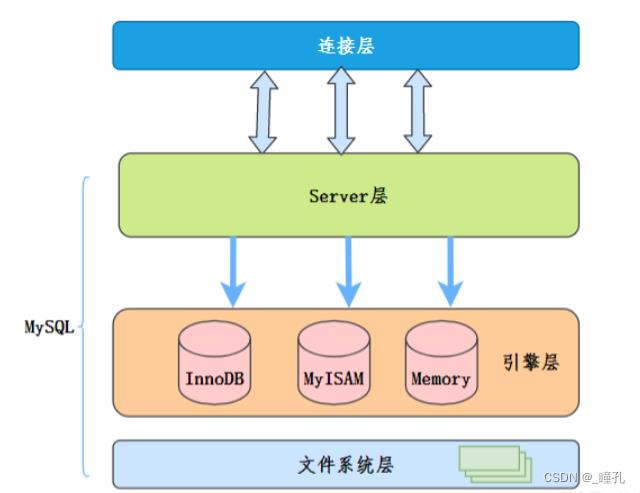
MySQL服务层负责SQL语法解析、生成执行计划等,并调用存储引擎层去执行数据的存储和检索。索引下推的下推其实就是指将部分上层(服务层)负责的事情,交给了下层(引擎层)去处理。
我们来具体看一下,在没有使用ICP的情况下,MySQL的查询:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给Server层去检测该记录是否满足WHERE条件。
使用ICP的情况下,查询过程:
- 存储引擎读取索引记录(不是完整的行记录);
- 判断WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录;
- 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给Server层,Server层检测该记录是否满足WHERE条件的其余部分。
7.MVCC解决的问题是什么
数据库并发场景有三种,分别为:
- 读读:不存在任何问题,也不需要并发控制
- 读写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读、幻读、不可重复读
- 写写:有线程安全问题,可能存在更新丢失问题
MVCC是一种用来解决读写冲突的无锁并发控制,也就是为事务分配单项增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照,所以MVCC可以为数据库解决一下问题:
- 在并发读写数据库时,可以做到在读操作时不用阻塞写操作,写操作也不用阻塞读操作,提高了数据库并发读写的性能
- 解决脏读、幻读、不可重复读等事务隔离问题,但是不能解决更新丢失问题
8.关于自增id
在MySQL里面,如果字段id被定义为AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
- 如果插入数据时id字段指定为0、null 或未指定值,那么就把这个表当前的AUTO_INCREMENT值填到自增字段
- 如果插入数据时id字段指定了具体的值,就直接使用语句里指定的值。根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设,某次要插入的值是X,当前的自增值是Y。
- 如果X<Y,那么这个表的自增值不变;
- 如果X≥Y,就需要把当前自增值修改为新的自增值。
优点:
- 顺序写入,避免了叶的分裂,数据写入效率好
- 缩小了表的体积,特别是相比于UUID当主键,甚至组合字段当主键时,效果更明显
- 查询效率好。Innodb存储数据(索引)的单位是页,这里默认是16K,这也意味着,数据本身越小,一个页中能存数据的量越多,而检索效率不仅仅由索引的层数来决定,更是由一次能够缓存的数据量来定,也就是说数据本身越小,则一次IO能够提取到缓冲区的数据越多(OS每次IO的量是固定的4K),查询的效率越好。
- 某些情况下,我们可以利用自增id来统计大表的大致行数。
- 在数据归档or垃圾数据清理时,也可方便的利用这个id去操作,效率高。
缺点:
- 导入旧数据时,可能会ID重复,导致导入失败。
- 分布式架构,多个Mysql实例可能会导致ID重复。
自增的其他特性:
- 一个表上只能有一个自增列
- Mysql5.7及以下版本,innodb表的自增值保存在内存中,重启后表的自增值会设为max(id)+1,而myisam引擎的自增值是保存在文件中,重启不会丢失。Mysql8.0开始,innodb的自增id能持久化了,重启mysql,自增ID不会丢。
- AUTO_INCREMENT数据列序号的最大值受该列的数据类型约束,如TINYINT数据列的最大编号是127,如加上UNSIGNED,则最大为255。一旦达到上限,AUTO_INCREMENT就会失效。
最佳实践:
- 单实例,单节点:由于InnoDB的特性,自增ID效率大于UUID.
- 20个节点以下小型分布式架构:为了实现快速部署,主键不重复,可以采用UUID
- 20到200个节点:可以采用自增ID+步长的较快速方案。
- 200个以上节点的分布式架构:可以采用twitter的雪花算法全局自增ID
9.数据库的三范式
- 第一范式:数据库表的每一个字段都是不可分割的。
- 第二范式:数据库表中的非主属性只依赖于主键。
- 第三范式:不存在非主属性对关键字的传递函数依赖关系。
10.MySQL 中有哪几种锁
MyISAM 支持表锁,InnoDB 支持表锁和行锁,默认为行锁。
- 表级锁:开销小,加锁快,不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发量最低。
- 行级锁:开销大,加锁慢,会出现死锁。锁力度小,发生锁冲突的概率小,并发度最高。
11.MyISAM的三种状态
- 静态 MyISAM:如果数据表中的各数据列的长度都是预先固定好的,服务器将自动选择这种表类型。因为数据表中每一条记录所占用的空间都是一样的,所以这种表存取和更新的效率非常高。当数据受损时,恢复工作也比较容易做。
- 动态 MyISAM:如果数据表中出现 varchar、text 或 BLOB 字段时,服务器将自动选择这种表类型。相对于静态 MyISAM,这种表存储空间比较小,但由于每条记录的长度不一,所以多次修改数据后,数据表中的数据就可能离散的存储在内存中,进而导致执行效率下降。同时,内存中也可能会出现很多碎片。因此,这种类型的表要经常用optimize table 命令或优化工具来进行碎片整理。
- 压缩 MyISAM:以上说到的两种类型的表都可以用 myisamchk 工具压缩。这种类型的表进一步减小了占用的存储,但是这种表压缩之后不能再被修改。另外,因为是压缩数据,所以这种表在读取的时候要先时行解压缩。
但是,不管是何种 MyISAM 表,目前它都不支持事务,行级锁和外键约束的功能。
以上是关于数据库八股系列——MySQL的主要内容,如果未能解决你的问题,请参考以下文章