Spark性能优化第九季之Spark Tungsten内存使用彻底解密
Posted 靖-Drei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark性能优化第九季之Spark Tungsten内存使用彻底解密相关的知识,希望对你有一定的参考价值。
一:Tungsten中到底什么是Page?
1.在Spark其实不存在Page这个类的。Page是一种数据结构(类似于Stack,List等),从OS层面上讲,Page代表了一个内存块,在Page里面可以存放数据,在OS中会存放很多不同的Page,当要获得数据的时候首先要定位具体是哪个Page中的数据,找到该Page之后从Page中根据特定的规则(例如说数据的offset和length)取出数据。
到底什么是Spark中的Page呢?
在阅读源码的时候,细致研究MemoryBlock.java,MemoryBlock代表了一个Page的对象。
2.其中:Nullable:可以为空。为什么?Page代表了具体的内存区域以及内存里面具体的数据,Page中的数据可能是On-heap的数据,也可能是Off-heap中的数据。如果是On-heap则有对象,但是Off-heap的话就没有对象。所以用@Nullable,将对象设置为空。
其中offset:偏移量。MemoryBlock封装了Off-heap和On-heap。
public MemoryBlock(@Nullable Object obj, long offset, long length)
super(obj, offset);
this.length = length;
3.On-heap和Off-heap寻址方式:
On-heap:先找到对象,然后再找索引。
Off-heap:根据地址找到索引。
4.Page可以定位到数据,然后又知道数据的偏移量OffSet之后怎么访问数据?这时候需要length,但是length并不知道,所以此时的长度设定为固定的,设置固定长度的length。
二:如何使用Page?
1.在TaskMemoryManager中,通过封装Page来定位数据,定位的时候如果是On-heap的话,则先找到对象,然后对象中通过offset来具体定位地址,而如果是Off-heap的话,则直接定位。
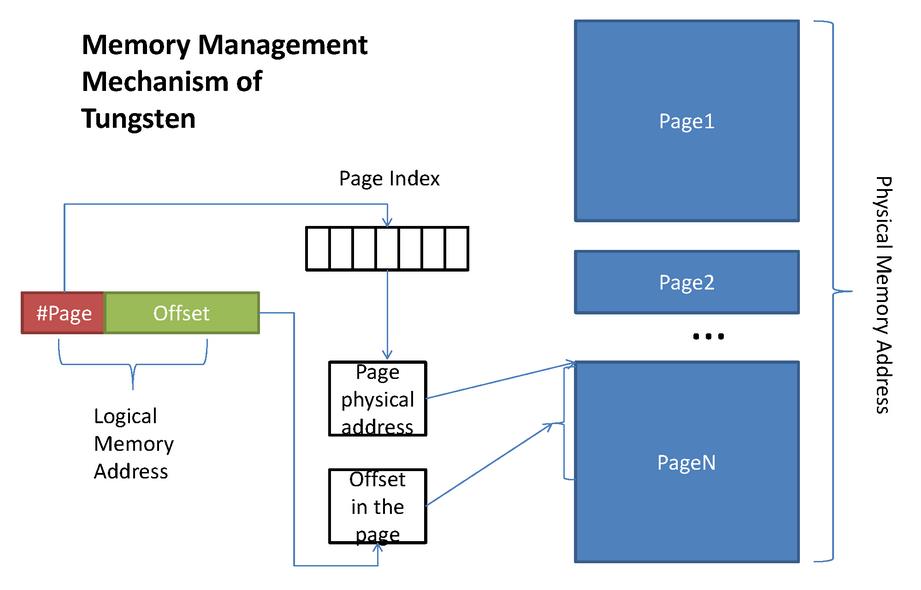
逻辑地址:Pagenumber由13个bit组成,51bit组成Offset
如果是On-heap的方式:内存的分配是是由heapMemoryAllocator完成的。
@Override
public MemoryBlock allocate(long size) throws OutOfMemoryError
if (shouldPool(size))
synchronized (this)
final LinkedList<WeakReference<MemoryBlock>> pool = bufferPoolsBySize.get(size);
if (pool != null)
while (!pool.isEmpty())
final WeakReference<MemoryBlock> blockReference = pool.pop();
final MemoryBlock memory = blockReference.get();
if (memory != null)
assert (memory.size() == size);
return memory;
bufferPoolsBySize.remove(size);
//内存对齐,array里面都是地址,因为GC的时候对象的地址会发生变化,因此就需要
//为了获得对象的引用。也就是对象的地址。
long[] array = new long[(int) ((size + 7) / 8)];
//array里面保存的都是地址,而LONG_ARRAY_OFFSET是偏移量,因此二者就可以定位到绝对地址,然后根据size就可以确定数据。
return new MemoryBlock(array, Platform.LONG_ARRAY_OFFSET, size);
如果是Off-heap的方式:内存的分配是是由UnsafeMemoryAllocator完成的。
@Override
public MemoryBlock allocate(long size) throws OutOfMemoryError
long address = Platform.allocateMemory(size);
//对象的引用为null
//address是绝对地址
return new MemoryBlock(null, address, size);
2.一个关键的问题是如何确定数据呢?这个时候就需要涉及具体的算法。
针对Task是怎么管理内存的?
TaskMemoryManager基于Page的概念屏蔽掉了底层是On-heap或者是Off-heap的概念,使用逻辑地址做指针,通过逻辑地址来具体定位到我们的记录具体在Page中的位置,
逻辑地址的表示:long类型的64bit的一个数字来表示的。
以上是关于Spark性能优化第九季之Spark Tungsten内存使用彻底解密的主要内容,如果未能解决你的问题,请参考以下文章