HashMap 源码put()方法
Posted HaSaKing_721
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap 源码put()方法相关的知识,希望对你有一定的参考价值。
前言
关于线程安全,put方法是能够暴露出线程安全的问题的,当两个不同的hashcode经过hash计算得到同样的index时,应该构成链表,但是如果多线程放到同一个index时,有可能发生覆盖,就是在判断table[index]是否为空的时候会出现这个问题。
废话不多说直接上源码
源码
public V put(K var1, V var2)
return this.putVal(hash(var1), var1, var2, false, true);
hash()方法
static final int hash(Object var0)
int var1;
// h = key.hashCode() 计算哈希值
// ^ (h >>> 16) 高 16 位与自身进行异或计算,保证计算出来的 hash 更加离散
return var0 == null ? 0 : (var1 = var0.hashCode()) ^ var1 >>> 16;
问题:为什么哈希桶组table的长度length必须是2的n次方
比如我们设定length=16;在jdk1.8中,HashMap在put的时候会对key进行运算之后变成index就是table数组的位置,就是这队K,V要存放的位置,那么K->index,就要满足三个特点:
- 必须为int;
- 要保证足够的散列;
- 得到的index一定要在table数组的范围内,就是0-15;
这下要求正是对应了源码中的Hash方法,
- 第一步:int h = key.hashCode();
- 第二步:h ^ (h >>> 16); 这个就叫做
扰动函数 - 第三步:(n-1) & h;
扰动函数
第二步为了降低哈希码的冲突,这样保证lenth在比较小的情况下高低Bit位都参与到Hash的计算中。hashcode无符号右移16位,高位补0,并与hashcode进行*按位异或^ 运算*。为什么要右移16位,因为看到在进行与运算的时候只有后面几位参与到了运算,所以进行右移,让他结果做到足够的分散;那为什么有要异或运算呢,这要是异或运算的一个特点,一位发生变化记过一定变化,也是为了结果足够的散列
注:异或运算,相同位不同则为1,相同则为0。00101 ^ 11100 = 11001,异或运算的特点就是有一位发生变化结果一定变化。
第三步,这里我们假设h=834957084,如果想要保证834957084在0-15之间,我们可以用取模运算:834957084 % 16,得到的结果一定是0-15之间,但是HashMap源码中选择的是*与运算*:
二进制计算:
16的二进制为: 0001 0000
16-1=15 二进制为: 0000 1111
0000 1111任意一个h:0110 1110 &(与运算,两个为1则为1)结果:0000 1110
最后得到的结果,二进制最小值一定是0000,最大值一定是1111,即十进制:0-15,这就是保证了上面第三步的范围,其实与取模运算是一样的;但是为什么选择了&与运算,因为&与运算是位运算,效率要比取模%高很多
再说第二步,通过上面的运算,我们发现,h的高4位是没有参与运算的,那么要想让高4位参与到运算过程中,就要右移,h右移:0000 0110,再进行异或操作,就能够让散列性更好,对应第二步
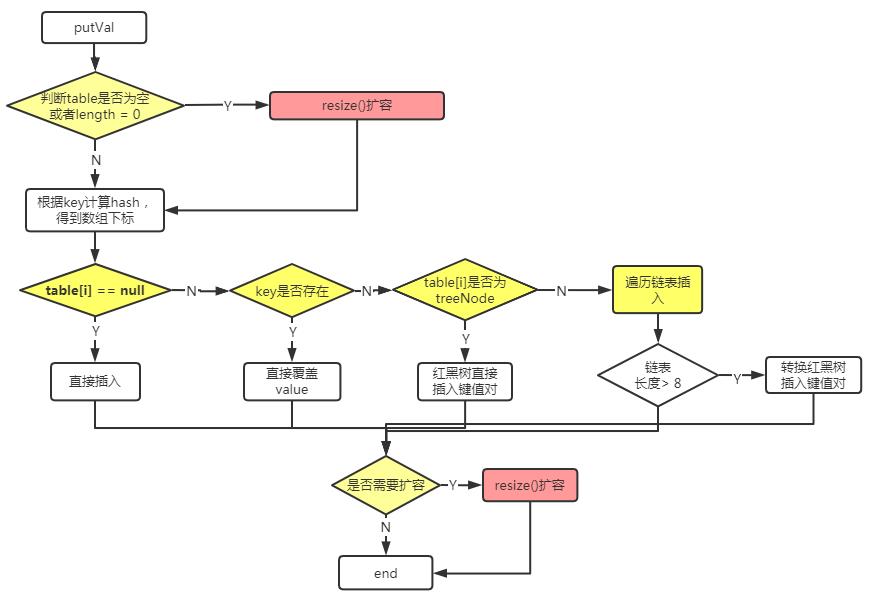
putVal()方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict)
Node<K,V>[] tab; // tables 数组
Node<K,V> p; // 对应位置的 Node 节点
int n; // 数组大小
int i; // 对应的 table 的位置
// 如果 table 未初始化,或者容量为 0 ,则进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果对应位置的 Node 节点为空,则直接创建 Node 节点即可。
if ((p = tab[i = (n - 1) & hash] /*获得对应位置的 Node 节点*/) == null)
tab[i] = newNode(hash, key, value, null);
// 如果对应位置的 Node 节点非空,则可能存在哈希冲突
else //Hash冲突逻辑
Node<K,V> e; // key 在 HashMap 对应的老节点
K k;
// 如果找到的 p 节点,就是要找的,则则直接使用即可
if (p.hash == hash && // 判断 hash 值相等
((k = p.key) == key || (key != null && key.equals(k)))) // 判断 key 真正相等
e = p;
// 如果找到的 p 节点,是红黑树 Node 节点,则直接添加到树中
else if (p instanceof TreeNode)//红黑树逻辑
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 如果找到的 p 是 Node 节点,则说明是链表,需要遍历查找
else //链表逻辑
// 顺序遍历链表
for (int binCount = 0; ; ++binCount)
// `(e = p.next)`:e 指向下一个节点,因为上面我们已经判断了最开始的 p 节点。
// 如果已经遍历到链表的尾巴,则说明 key 在 HashMap 中不存在,则需要创建
if ((e = p.next) == null)
// 创建新的 Node 节点
p.next = newNode(hash, key, value, null);
// 链表的长度如果数量达到 TREEIFY_THRESHOLD(8)时,则进行树化。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break; // 结束
// 如果遍历的 e 节点,就是要找的,则则直接使用即可
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break; // 结束
// p 指向下一个节点
p = e;
//如果找到了对应的节点
if (e != null) // existing mapping for key
V oldValue = e.value;
// 修改节点的 value ,如果允许修改
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 节点被访问的回调
afterNodeAccess(e);
// 返回老的值
return oldValue;
// <4.2>
// 增加修改次数
++modCount;
// 如果超过阀值,则进行扩容
if (++size > threshold)
resize();
// 添加节点后的回调
afterNodeInsertion(evict);
// 返回 null
return null;
附流程图
以上是关于HashMap 源码put()方法的主要内容,如果未能解决你的问题,请参考以下文章