08-flink-1.10.1- flink Transform api 转换算子
Posted 逃跑的沙丁鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了08-flink-1.10.1- flink Transform api 转换算子相关的知识,希望对你有一定的参考价值。
目录
2.2 滚动聚合算子 rolling aggregation
1 简单转换算子
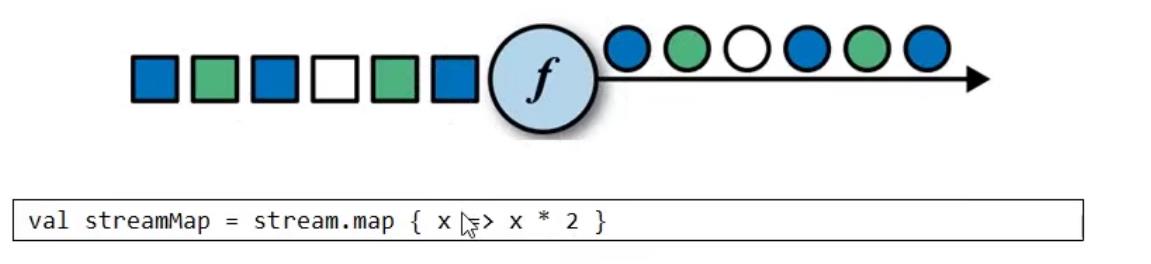
1.1 map
来一个处理一个,one by one
1.2 flatMap
相当于先进行map操作后又进行了flat一个扁平化的操作,可以简单理解成列传行的操作

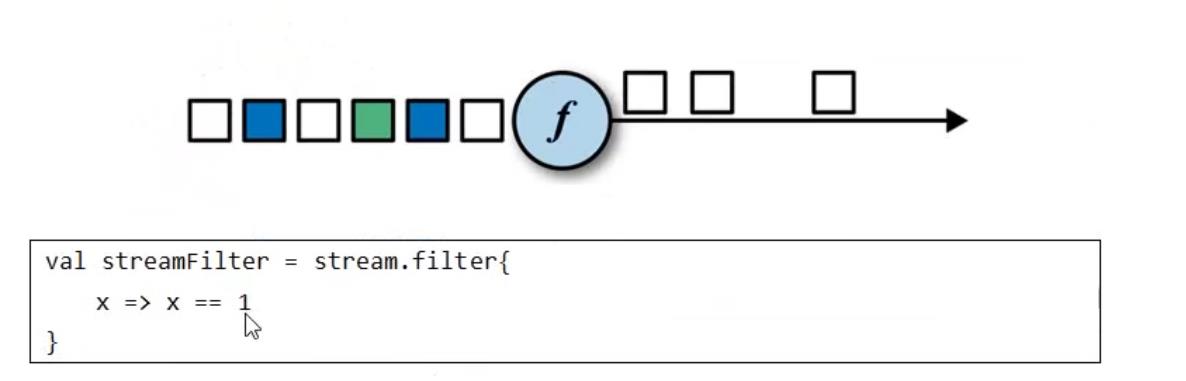
1.3 filter
返回true才继续往下传递数据
2 键控流转换算子
2.1 keyby
同一个分区里有不同key的元素,但是同一个key的元素肯定要进入同一个分区

2.2 滚动聚合算子 rolling aggregation
为什么叫做滚动聚合算子呢,是数据源源不断的来,然后聚合结果不断的更新,有点想滚雪球一样的操作
这些算子可以针对KeyedStream的每一个分支流做聚合。
- sum()
- min()
min() 函数只求指定字段的最小值其他字段保留第一条读取近来的数据对应的值
package com.study.liucf.unbounded.transform
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.scala._
/**
* @Author liucf
* @Date 2021/9/9
*/
object TransformTest1
def main(args: Array[String]): Unit =
//创建flink执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取数据
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
//转换数据类型 string 类型转换成LiucfSensorReding,求最小值
val ds = inputStream.map(r=>
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
).keyBy("id")
.min("temperature")
//输出到控制台
ds.print()
//启动flink执行
env.execute("liucf transform api")
原始数据:
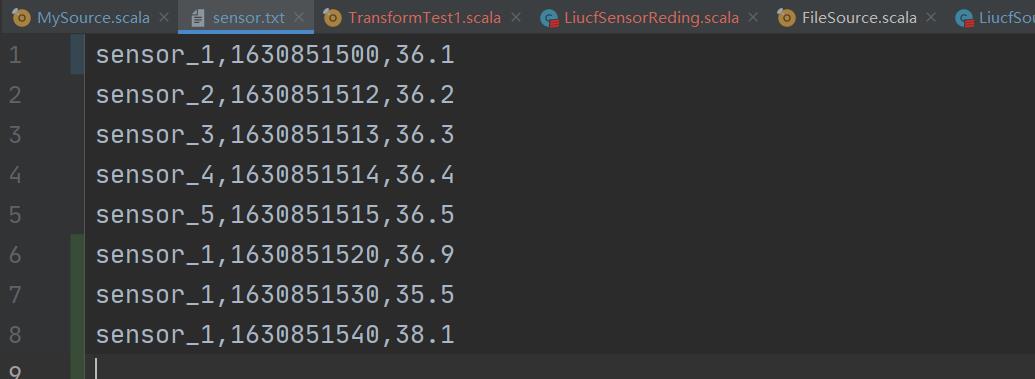
执行后输出
 结论:
结论:
① min() 函数只取指定字段最小值,比如温度值35.5最小,其他字段取第一次出现的数据的值,比如1630851520,后面输出的全是它
② 为什么第一条打印的不是和源数据顺序一致是36.1度,而是36.9度,因为是分布式处理的,36.9这条数据先到,先进行print
③ 滚动取最小值,每次来一条数据滚动计算一次,最小值35.5出现后后面的再比较大于这个只,所以会一直输出35.5
- max()
类似min()
- minBy()
minby() 与min() 不同函数不只求指定字段的最小值其他字段保留最小值对应的那条数据的对应的值
package com.study.liucf.unbounded.transform
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.scala._
/**
* @Author liucf
* @Date 2021/9/9
*/
object TransformMinBy
def main(args: Array[String]): Unit =
//创建flink执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取数据
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
//转换数据类型 string 类型转换成LiucfSensorReding,求最小值
val ds = inputStream.map(r=>
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
).keyBy("id")
.minBy("temperature")
//输出到控制台
ds.print()
//启动flink执行
env.execute("liucf transform api")
源数据:
输出:

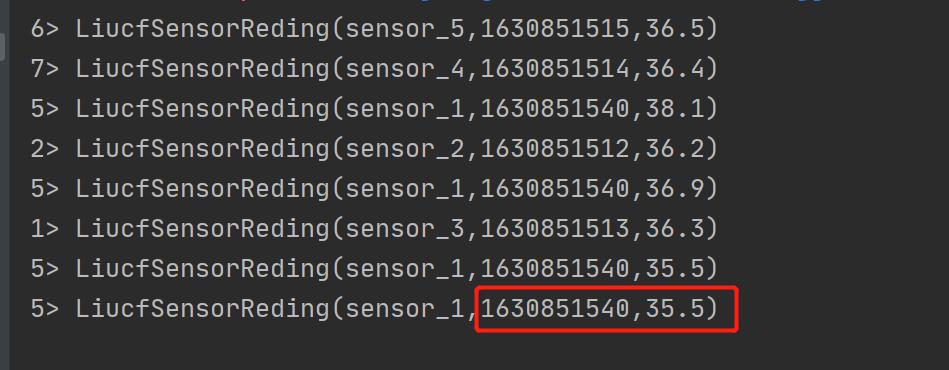
结论:
① minBy() 函数不只取指定字段最小值,比如温度值35.5最小,其他字段取它对应那条数据的值,比如1630851530,后面输出的全是它
② 为什么第一条打印的不是和源数据顺序一致是36.1度,而是36.9度,因为是分布式处理的,36.9这条数据先到,先进行print
③ 滚动取最小值,每次来一条数据滚动计算一次,最小值35.5出现后后面的再比较大于这个只,所以会一直输出35.5
- maxBy()
类似minBy()
2.3 reduce
一,lamda 表达式
package com.study.liucf.unbounded.transform
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.scala._
/**
* @Author liucf
* @Date 2021/9/10
* 需求:输出每个传感器,最小的温度值和最后一次上报温度的时间
*/
object TransformReduceLamda
def main(args: Array[String]): Unit =
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 读取数据流
val inputStream = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
// 转换处理
val ds: DataStream[LiucfSensorReding] = inputStream
.map(r=>
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
)
.keyBy("id")
.reduce((currData,newData)=>
LiucfSensorReding(currData.id,
currData.timestamp.max(newData.timestamp),
currData.temperature.min(newData.temperature))
)
// 输出结果到控制台
ds.print()
//启动flink处理程序
env.execute("flink transform api:reduce test")
其中:currData:当前值,也就是上一条数据处理完成后得到的值
newData:下一条参与滚动计算的新的值
最后:返回一个同样类型的结果
二,自定义reduce function
package com.study.liucf.unbounded.transform
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
/**
* @Author liucf
* @Date 2021/9/10
* 需求:输出每个传感器,最小的温度值和最后一次上报温度的时间
*/
object TransformReduceMyFunction
def main(args: Array[String]): Unit =
// 创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 读取数据流
val inputStream = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
// 转换处理
val ds: DataStream[LiucfSensorReding] = inputStream
.map(r=>
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
)
.keyBy("id")
.reduce(new LiucfReduce())
// 输出结果到控制台
ds.print()
//启动flink处理程序
env.execute("flink transform api:reduce test")
class LiucfReduce extends ReduceFunction[LiucfSensorReding]
override def reduce(value1: LiucfSensorReding, value2: LiucfSensorReding): LiucfSensorReding =
LiucfSensorReding(value1.id,
value1.timestamp.max(value2.timestamp),
value1.temperature.min(value2.temperature))
这种方式:
① 继承 ReduceFunction
② 重写reduce方法
结果:
3 多流转换算子
3.1 split 和 select
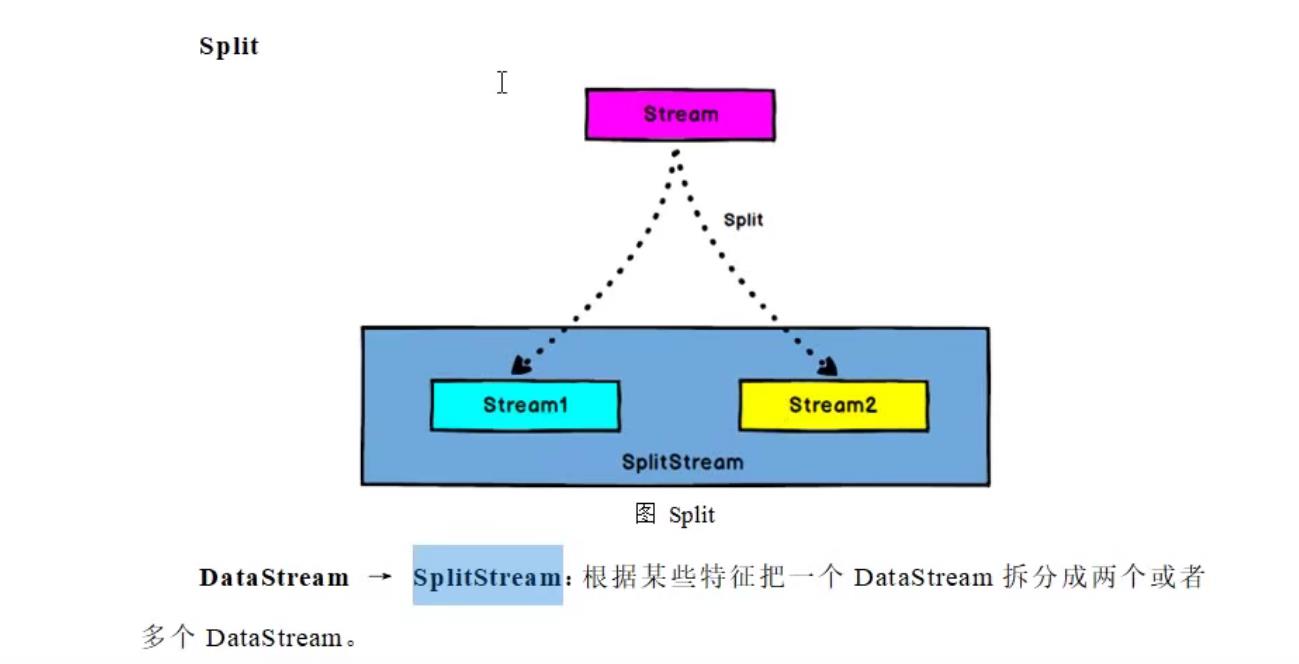
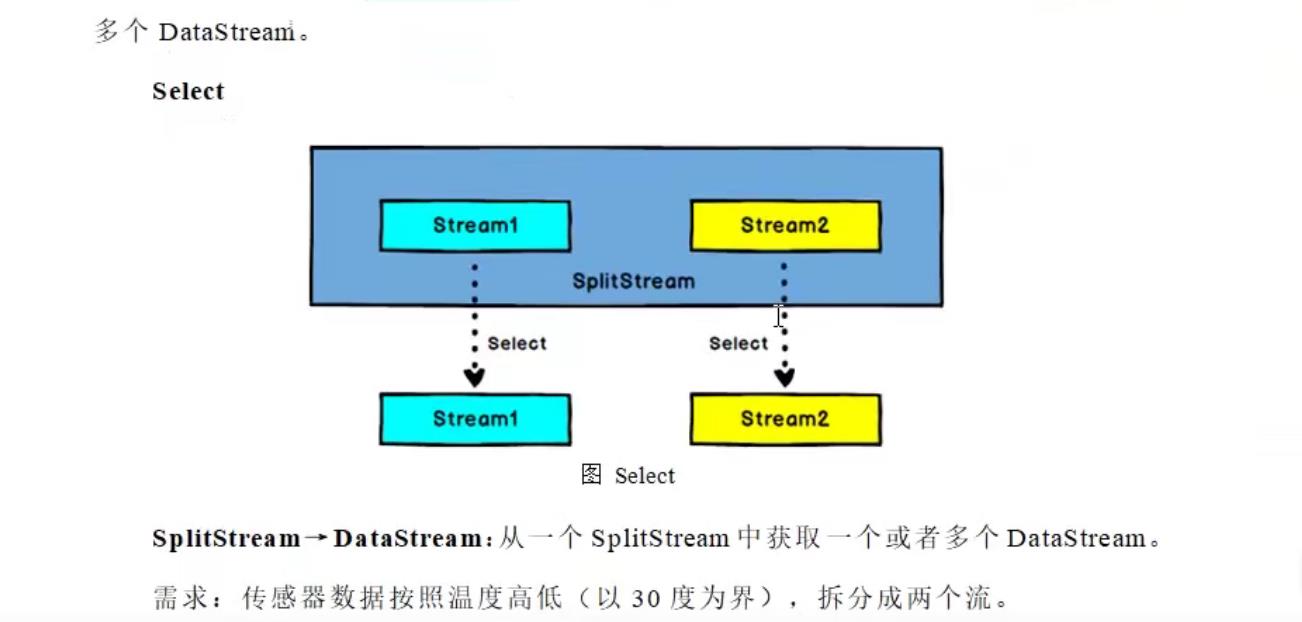
实际上,split 并不是把流分割成多个流,其实是把原来的流打上标记而已,后面再使用select根据split的标记筛选出来。所以经常split和select是配合使用的,就像keyby 后面总是要跟着聚合函数一样。
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.streaming.api.collector.selector;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.SplitStream;
import java.io.Serializable;
/**
* Interface for defining an OutputSelector for a @link SplitStream using
* the @link SingleOutputStreamOperator#split call. Every output object of a
* @link SplitStream will run through this operator to select outputs.
*
* @param <OUT>
* Type parameter of the split values.
*/
@PublicEvolving
public interface OutputSelector<OUT> extends Serializable
/**
* Method for selecting output names for the emitted objects when using the
* @link SingleOutputStreamOperator#split method. The values will be
* emitted only to output names which are contained in the returned
* iterable.
*
* @param value
* Output object for which the output selection should be made.
*/
Iterable<String> select(OUT value);
3.2 connect 和 coMap
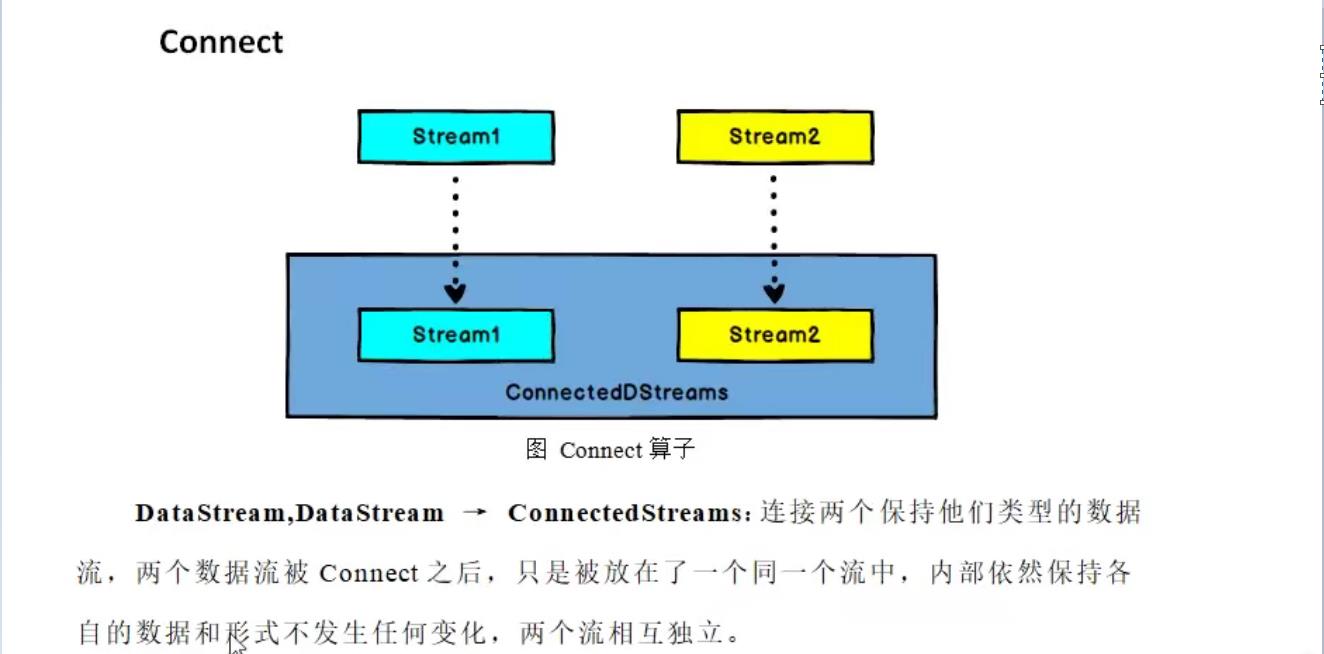

connect 虽然是合流,但是原本不同的流保留自己原有的数据结构,可以类比一国两制。coMap可以输出不同数据类型的流。connect和coMap经常一起使用,注意流只能量量操作,如果有三条流那么就需要先处理完两条再和第三条一起处理。
package com.study.liucf.unbounded.transform
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.functions.co.CoMapFunction
import org.apache.flink.streaming.api.scala._
/**
* @Author liucf
* @Date 2021/9/12
* 把lowDS低温,highDS高温进行告警
*/
object TransformConnectCoMap
def main(args: Array[String]): Unit =
//创建CoMapFunctionflink执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取数据
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
//转换数据类型 string 类型转换成LiucfSensorReding,求最小值
val ds: SplitStream[LiucfSensorReding] = inputStream.map(r=>
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
).split(d=>
if(d.temperature<36.4)
Seq("low")
else if(d.temperature>=36.4 && d.temperature<36.6)
Seq("middle")
else
Seq("high")
)
//把低温数据结构变成二元组,模拟两个流数据结构不一样
val lowDS: DataStream[(String, Double)] = ds.select("low")
.map((d=>(d.id,d.temperature)))
val middleDS: DataStream[LiucfSensorReding] = ds.select("middle")
val highDS: DataStream[LiucfSensorReding] = ds.select("high")
//可见两个流数据结构不一样
val connectedStreamsDS: ConnectedStreams[(String, Double), LiucfSensorReding] = lowDS.connect(highDS)
// 方法一,lamda表达式
//f1和f2返回的数据类型可以不一样,一可以一样
val warningDS1: DataStream[Product] = connectedStreamsDS.map(
f1=>(f1._1,f1._2,"low temperature warning"),
f2=>(LiucfSensorReding(f2.id,f2.timestamp,f2.temperature),"high temperature warning")
)
//方法二,自定义CoMap类
val warningDS2: DataStream[Product] = connectedStreamsDS.map(new LiucfCoMap())
//输出
//warningDS1.print()
warningDS2.print()
// 启动flink执行程序
env.execute("liucf Connect CoMap test")
/**
* 自定义comap类
*/
class LiucfCoMap extends CoMapFunction[(String, Double), LiucfSensorReding, Product]
override def map1(value: (String, Double)): Product =
(value._1,value._2,"low temperature warning")
override def map2(value: LiucfSensorReding): Product =
(LiucfSensorReding(value.id,value.timestamp,value.temperature),"high temperature warning")

3.3 union

package com.study.liucf.unbounded.transform
import com.study.liucf.bean.LiucfSensorReding
import org.apache.flink.streaming.api.scala._
/**
* @Author liucf
* @Date 2021/9/12
*/
object TransformUnion
def main(args: Array[String]): Unit =
//创建flink执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//读取数据
val inputStream: DataStream[String] = env.readTextFile("src\\\\main\\\\resources\\\\sensor.txt")
//转换数据类型 string 类型转换成LiucfSensorReding,求最小值
val ds: SplitStream[LiucfSensorReding] = inputStream.map(r=>
val arr = r.split(",")
LiucfSensorReding(arr(0),arr(1).toLong,arr(2).toDouble)
).split(d=>
if(d.temperature<36.4)
Seq("low")
else if(d.temperature>=36.4 && d.temperature<36.6)
Seq("middle")
else
Seq("high")
)
val lowDS = ds.select("low")
//.map(d=>(d.id,d.temperature)) val middleDS: DataStream[LiucfSensorReding] = ds.select("middle")
val middleDs = ds.select("middle")
val highDS: DataStream[LiucfSensorReding] = ds.select("high")
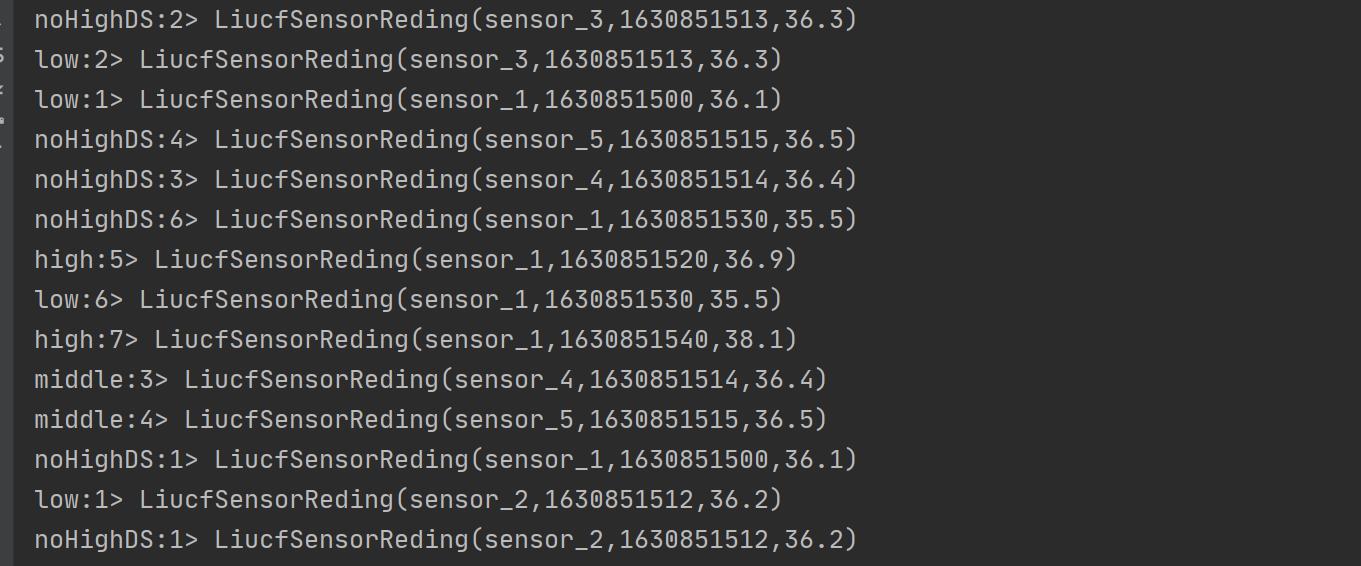
val noHighDS: DataStream[LiucfSensorReding] = ds.select("low","middle")
// union 只允许类型相同的流进行合并,一次可以合并两条或两条以上的流
val allDs: DataStream[LiucfSensorReding] = lowDS.union(highDS,middleDs)
//输出
allDs.print()
// 启动flink执行程序
env.execute("liucf split select test")

以上是关于08-flink-1.10.1- flink Transform api 转换算子的主要内容,如果未能解决你的问题,请参考以下文章