Oozie4.3.1各种Action及综合实例
Posted fansy1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oozie4.3.1各种Action及综合实例相关的知识,希望对你有一定的参考价值。
Oozie4.3.1各种Action及综合实例
如果没有编译好Oozie,并部署到集群,请参考:Build Oozie4.3.1 on Hadoop3.X及Hadoop生态圈Action调用(一)
- 本篇主要是针对Hadoop生态圈Action的调用。
1. 准备工作
- 确保Hadoop集群启动;
- 确保Oozie启动;
- 确保HiveServer2启动(测试主要使用Hiveserver2);
- 并且参考上篇把相关examples资源上传到HDFS的/user/root/examples目录;
2. Hive2 Action
2.1 准备工作
先读取Hive2的example的代码意思:
oozie-4.3.1/examples/apps/hive2/workflow.xml : 这个代码是一个通用的调用Hive的代码,这里就不贴了。
oozie-4.3.1/examples/apps/hive2/script.q:
-- 删除test表
DROP TABLE IF EXISTS test;
-- 根据路径创建外部表 test
CREATE EXTERNAL TABLE test (a INT) STORED AS TEXTFILE LOCATION '$INPUT';
-- 把外部表test的数据导出到HDFS
INSERT OVERWRITE DIRECTORY '$OUTPUT' SELECT * FROM test;其中$INPUT的值在workflow.xml以及job.properties中有,job.properties设置为:
# 集群相关的配置,需修改为实际地址
nameNode=hdfs://master:8020
jobTracker=master:8032
queueName=default
jdbcURL=jdbc:hive2://master:10000/default
examplesRoot=examples
oozie.use.system.libpath=true
oozie.wf.application.path=$nameNode/user/$user.name/$examplesRoot/apps/hive2匹配后,输入为: /user/root/examples/input-data/table/
输出为:/user/root/example/output-data/hive2
由于这里并没有测试数据,同时根据script.q的创建test表的代码来看,可以只需要用一列数值即可作为其输入,比如(命名为data.txt):
1
2
3
4
5上传到HDFS
hdfs dfs -put data.txt /user/root/examples/input-data/table2.2 执行
在oozie-4.3.1/examples/apps/hive2执行命令:
oozie job --oozie http://master:11000/oozie -config job.properties -run2.3 查看结果
2.3.1 Oozie监控
首先,可以看到任务在Oozie上面的结果:
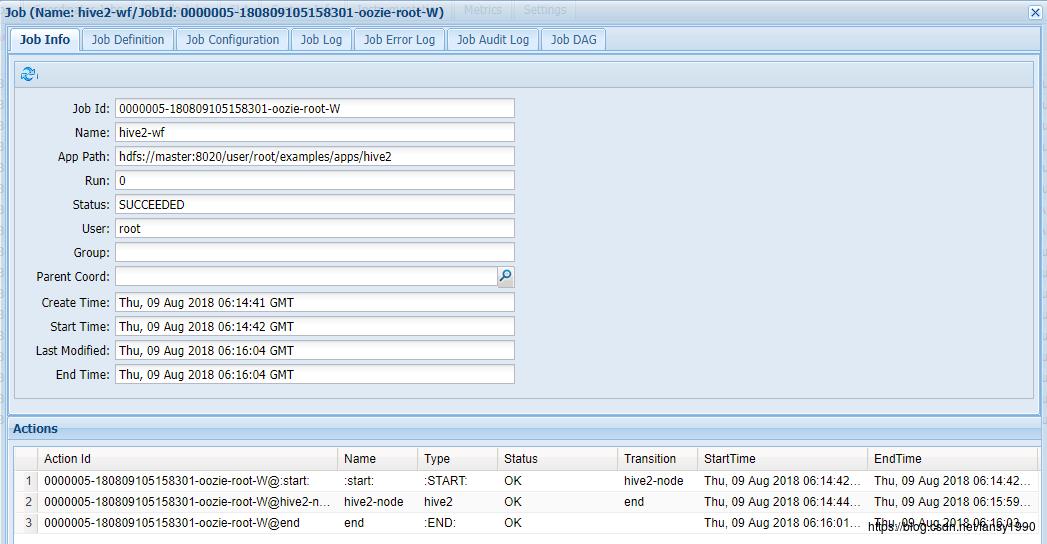
从图中可以看到任务的发起时间及结束时间,及任务运行状态,可以看到是成功执行并完成的。
2.3.2 YARN 监控
Oozie发起Hive任务的时候,会首先发起一个MapReduce的任务,然后在这个任务里面再次发起另外的一个MapReduce任务(这个主要去执行hive的SQL),只有当hive sql的MapReduce任务执行完成之后,Oozie的MapReduce才会完成。
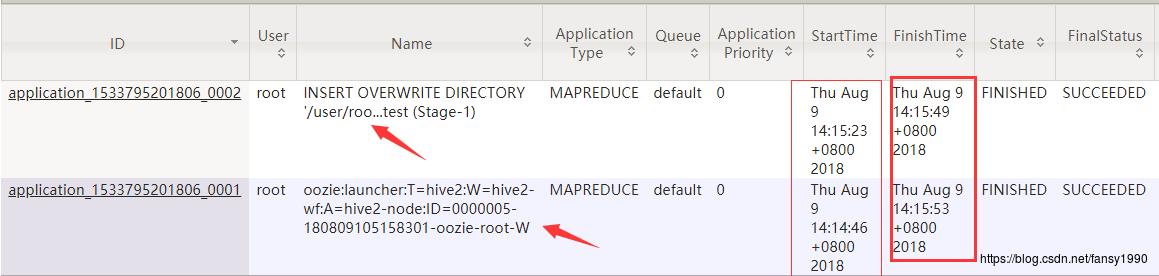
从图中可以看到两个任务的Name,和发起的任务也有很大的关系。其次是两个任务开始的时间和结束的时间。
2.3.3 输出
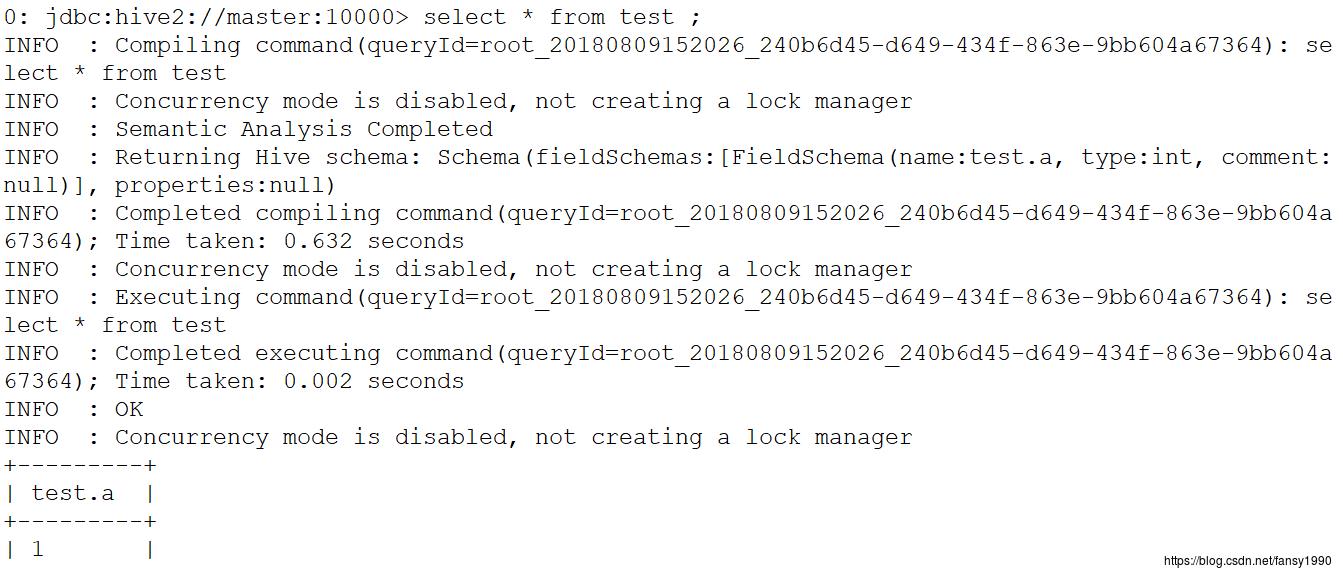
任务输出有两个,第一个,在hive中应该可以看到一个test表,同时查看数据,应该是1,2,3,4,5 ;
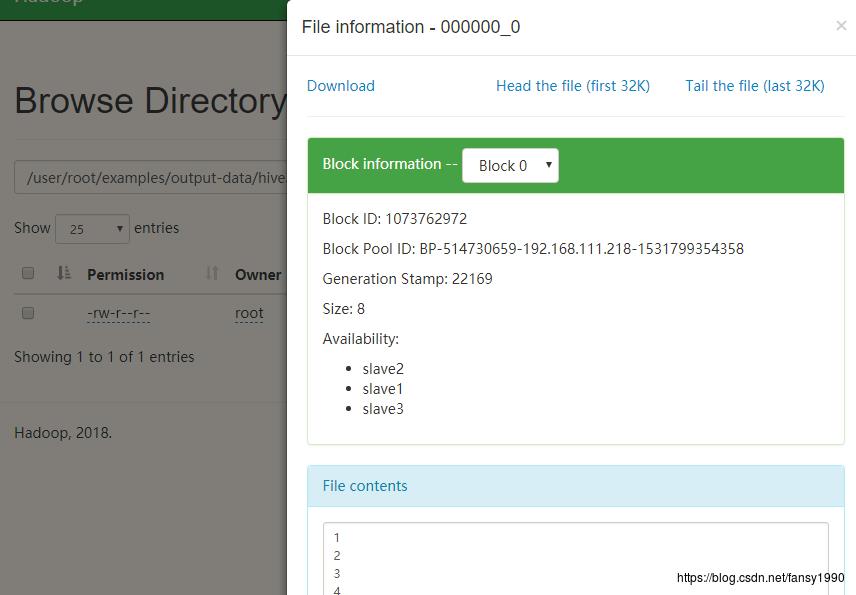
第二个,在HDFS的输出目录应该会有对应的数据产生,同时数据也是一样的。
3. Pig Action
3.1 准备工作
oozie-4.3.1/examples/apps/pig/workflow.xml :
<script>id.pig</script>
<param>INPUT=/user/$wf:user()/$examplesRoot/input-data/text</param>
<param>OUTPUT=/user/$wf:user()/$examplesRoot/output-data/pig</param>从上面可以看到输入以及要执行的pig脚本,输入是在、/user/root/examples/input-data/text;
oozie-4.3.1/examples/apps/pig/id.pig:
A = load '$INPUT' using PigStorage(':');
B = foreach A generate $0 as id;
store B into '$OUTPUT' USING PigStorage();该脚本就是从INPUT中加载数据到关系A(字段间分隔符用冒号:),然后取得里面的第一个字段的值并存入关系B,把关闭B的数据存储到HDFS的Output目录;
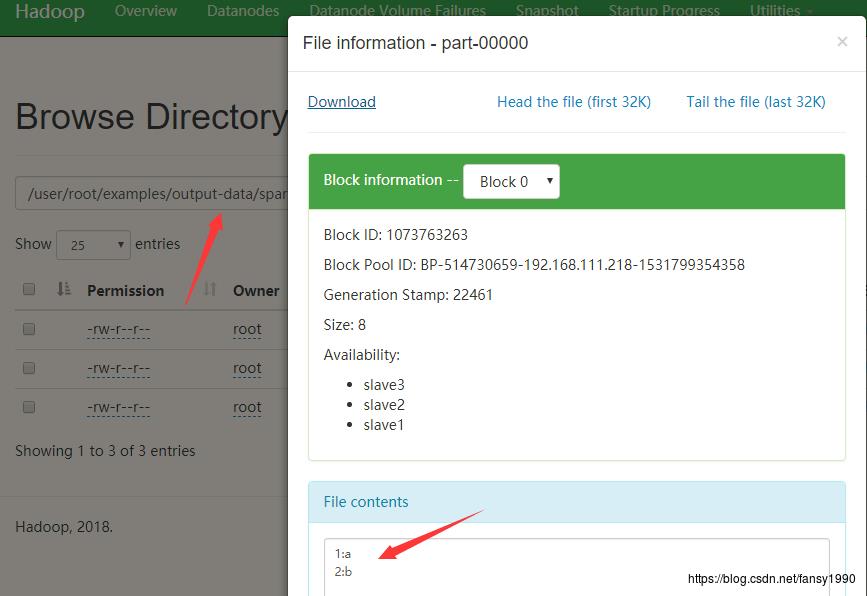
通过观察发现输入数据的是文本,不适合作为id.pig的输入,所以修改下,简单示例如下(假设名字为data.txt):
1:a
2:b
3:c然后存入HDFS:
hdfs dfs -rm -r /user/root/examples/input-data/text/data.txt
hdfs dfs -put data.txt /user/root/examples/input-data/text/3.2 执行
在oozie-4.3.1/examples/apps/pig执行命令:
oozie job --oozie http://master:11000/oozie -config job.properties -run3.3 查看输出
由于这里的监控和Hive的类似,这里不再展开介绍。
3.3.1 Oozie监控
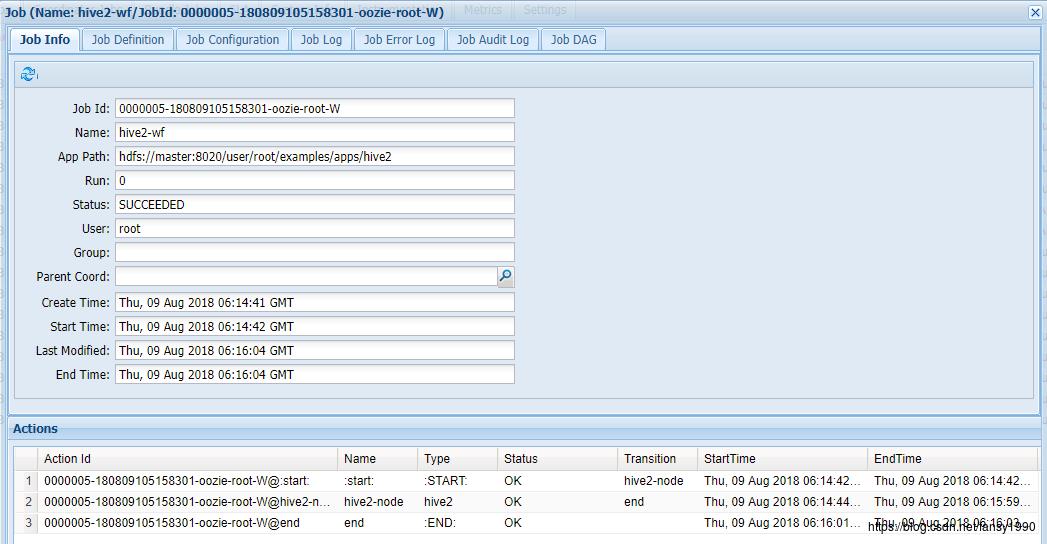
3.3.2 YARN监控
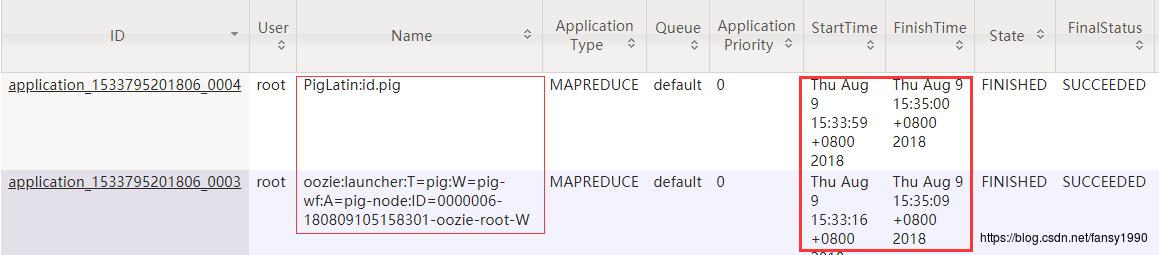
3.3.3 HDFS监控

4. Spark Action
4.1 准备工作
oozie-4.3.1/examples/apps/spark/job.properties:
nameNode=hdfs://master:8020
jobTracker=master:8032
master=yarn-cluster
queueName=default
examplesRoot=examples
oozie.use.system.libpath=true
oozie.wf.application.path=$nameNode/user/$user.name/$examplesRoot/apps/spark
特别注意,把master改为yarn-cluster ,使用这种模式来运行,当然也可以使用其他模式,具体可参考:http://oozie.apache.org/docs/4.3.1/DG_SparkActionExtension.html#Spark_on_YARN
其运行的代码如下所示:
public final class SparkFileCopy
public static void main(String[] args) throws Exception
if (args.length < 2)
System.err.println("Usage: SparkFileCopy <file> <file>");
System.exit(1);
SparkConf sparkConf = new SparkConf().setAppName("SparkFileCopy");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile(args[0]);
lines.saveAsTextFile(args[1]);
System.out.println("Copied file from " + args[0] + " to " + args[1]);
ctx.stop();
这个代码就是读取输入,然后原封不动的写入到输出目录,其实就是复制。
4.2 运行
在oozie-4.3.1/examples/apps/spark执行命令:
oozie job --oozie http://master:11000/oozie -config job.properties -run4.3 查看结果
4.3.1 运行异常
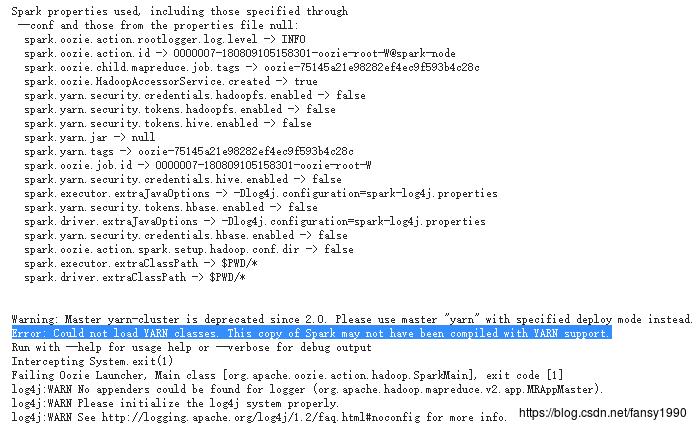
这里应该是缺少YARN的jar包,进行下面的处理:
hdfs dfs -mv /user/root/share/lib/lib_20180809104438/spark /user/root/share/lib/lib_20180809104438/spark_bak
root@master:/usr/local/spark-2.3.0-bin-hadoop2.7# hdfs dfs -mkdir /user/root/share/lib/lib_20180809104438/spark
root@master:/usr/local/spark-2.3.0-bin-hadoop2.7# hdfs dfs -put /usr/local/spark-2.3.0-bin-hadoop2.7/jars/* /user/root/share/lib/lib_20180809104438/spark/
root@master:/usr/local/spark-2.3.0-bin-hadoop2.7# hdfs dfs -cp /user/root/share/lib/lib_20180809104438/spark_bak/oozie* /user/root/share/lib/lib_20180809104438/spark/
Deleted /user/root/share/lib/lib_20180809104438/spark/zkclient-0.3.jar
root@master:/usr/local/spark-2.3.0-bin-hadoop2.7# oozie admin -sharelibupdate
[ShareLib update status]
sharelibDirOld = hdfs://master:8020/user/root/share/lib/lib_20180809104438
host = http://master:11000/oozie
sharelibDirNew = hdfs://master:8020/user/root/share/lib/lib_20180809104438
status = Successful同时,你可以看到其实我Spark安装的版本是2.3的,但是oozie匹配的是2.1 。这个暂时还没出现问题。这段代码解决参考:https://stackoverflow.com/questions/30904316/sparkaction-for-yarn-cluster 。
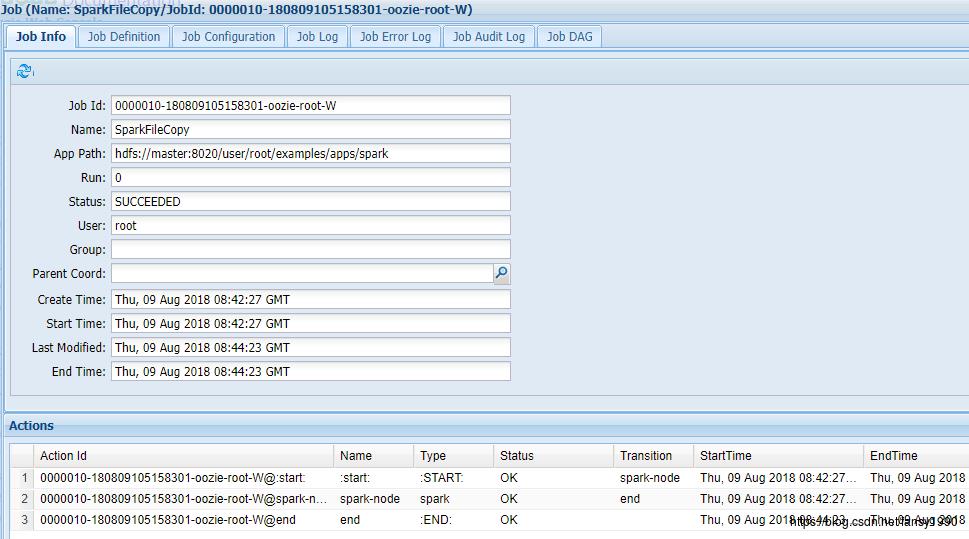
处理完成之后再次运行,即可正确运行程序;
4.3.2 Oozie监控
4.3.3 YARN监控
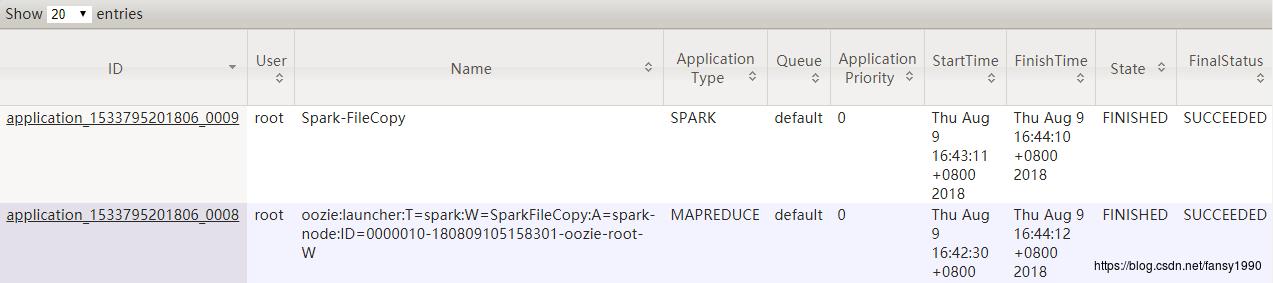
4.3.4 HDFS监控
5. 综合实例
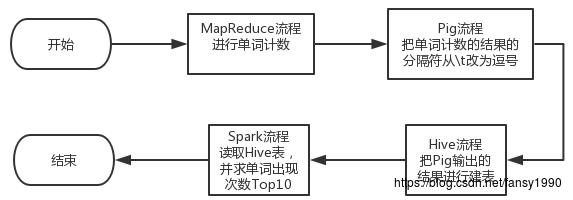
建立一个综合的例子,把spark、pig、MapReduce、Hive都整合起来。
5.1 总流程
5.2 相关资源准备
5.2.1 需编辑资源:
- job.properties:
oozie.use.system.libpath=true
nameNode=hdfs://master:8020
resourceManager=master:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=$nameNode/user/$user.name/$examplesRoot/apps/all/workflow.xml
mr_inputDir=$nameNode/user/$user.name/$examplesRoot/input-data/all
mr_outputDir=$nameNode/user/$user.name/$examplesRoot/output-data/all/mr-output
mr_reducer_num=2
mr_arg_num=2
pig_inputDir=$mr_outputDir
pig_outputDir=$nameNode/user/$user.name/$examplesRoot/output-data/all/pig-output
hive_inputDir=$pig_outputDir
hive_tableName=wordcount_top
jdbcURL=jdbc:hive2://master:10000/default
spark_inputTable=$hive_tableName
spark_outputTable=wordcount_top_10
spark_column=num
spark_hive_file=$nameNode/user/$user.name/$examplesRoot/apps/all/hive-site.xml
master=yarn-cluster- workflow.xml:
<workflow-app xmlns="uri:oozie:workflow:0.2" name="all-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>$resourceManager</job-tracker>
<name-node>$nameNode</name-node>
<prepare>
<delete path="$mr_outputDir"/>
</prepare>
<configuration>
<property>
<name>mapreduce.job.queuename</name>
<value>$queueName</value>
</property>
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<property>
<name>mapreduce.job.map.class</name>
<value>demo.fansy.WordCountMapper</value>
</property>
<property>
<name>mapreduce.job.reduce.class</name>
<value>demo.fansy.WordCountReducer</value>
</property>
<property>
<name>mapreduce.job.inputformat.class</name>
<value>org.apache.hadoop.mapreduce.lib.input.TextInputFormat</value>
</property>
<property>
<name>mapreduce.job.outputformat.class</name>
<value>org.apache.hadoop.mapreduce.lib.output.TextOutputFormat</value>
</property>
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>$mr_reducer_num</value>
</property>
<property>
<name>mapreduce.input.fileinputformat.inputdir</name>
<value>$mr_inputDir</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.outputdir</name>
<value>$mr_outputDir</value>
</property>
<property>
<name>arg.num</name>
<value>$mr_arg_num</value>
</property>
</configuration>
</map-reduce>
<ok to="pig-node"/>
<error to="fail"/>
</action>
<action name="pig-node">
<pig>
<job-tracker>$resourceManager</job-tracker>
<name-node>$nameNode</name-node>
<prepare>
<delete path="$pig_outputDir"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>$queueName</value>
</property>
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
</configuration>
<script>change_splitter.pig</script>
<param>INPUT=$pig_inputDir</param>
<param>OUTPUT=$pig_outputDir</param>
</pig>
<ok to="hive2-node"/>
<error to="fail"/>
</action>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>$resourceManager</job-tracker>
<name-node>$nameNode</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>$queueName</value>
</property>
</configuration>
<jdbc-url>$jdbcURL</jdbc-url>
<script>create_table.hive</script>
<param>hive_inputDir=$hive_inputDir</param>
<param>hive_tableName=$hive_tableName</param>
</hive2>
<ok to="spark-node"/>
<error to="fail"/>
</action>
<action name='spark-node'>
<spark xmlns="uri:oozie:spark-action:0.1">
<job-tracker>$resourceManager</job-tracker>
<name-node>$nameNode</name-node>
<master>$master</master>
<name>find top 10 words</name>
<class>demo.TopTen</class>
<jar>$nameNode/user/$wf:user()/$examplesRoot/apps/all/lib/demo.jar</jar>
<spark-opts>--files $spark_hive_file</spark-opts>
<arg>$spark_inputTable</arg>
<arg>$spark_outputTable</arg>
<arg>$spark_column</arg>
</spark>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[$wf:errorMessage(wf:lastErrorNode())]</message>
</kill>
<end name="end"/>
</workflow-app>- change_splitter.pig
A = load '$INPUT' using PigStorage('\\t');
B = foreach A generate $1 as num,$0 as word;
store B into '$OUTPUT' USING PigStorage(',');
- create_table.hive
DROP TABLE IF EXISTS $hive_tableName;
CREATE TABLE $hive_tableName (num INT, word STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\\n' STORED AS TEXTFILE ;
LOAD DATA INPATH '$hive_inputDir' OVERWRITE INTO TABLE $hive_tableName;- WordCountMapper.java:
package demo.fansy;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @Author: fansy
* @Time: 2018/8/9 17:22
* @Email: fansy1990@foxmail.com
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
private Logger logger = LoggerFactory.getLogger(WordCountMapper.class);
private int num = 0;
@Override
protected void setup(Context context) throws IOException, InterruptedException
num = context.getConfiguration().getInt("arg.num",-1);
logger.info("num:",num);
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens())
word.set(itr.nextToken());
context.write(word, one);
- WordCountReducer.java:
package demo.fansy;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* @Author: fansy
* @Time: 2018/8/9 17:27
* @Email: fansy1990@foxmail.com
*/
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>
private IntWritable result = new IntWritable();
private Logger logger = LoggerFactory.getLogger(WordCountReducer.class);
private int num = 0;
@Override
protected void setup(Context context) throws IOException, InterruptedException
num = context.getConfiguration().getInt("arg.num",-1);
logger.info("reducer num:",num);
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException
int sum = 0;
for (IntWritable val : values)
sum += val.get();
if(sum> num)
result.set(sum);
context.write(key, result);
TopTen.scala
package demo
import org.apache.spark.sql.SparkSession
/**
* //@Author: fansy
* //@Time: 2018/8/9 17:32
* //@Email: fansy1990@foxmail.com
*/
object TopTen
def main(args: Array[String]): Unit =
if (args.length < 3)
System.err.println("Usage: TopTen <inputTable> <outputTable> <column>" )
System.exit(1)
val input = args(0)
val output = args(1)
val column = args(2)
val spark = SparkSession.builder().enableHiveSupport().appName("Top Ten :"+ input).enableHiveSupport().getOrCreate()
val data = spark.sql("select * from " + input +" order by "+ column +" desc limit 10")
val tmpTable = "tmp" + System.currentTimeMillis()
data.createOrReplaceTempView(tmpTable)
spark.sql("drop table if exists "+output)
spark.sql("create table " + output + " as select * from " + tmpTable)
System.out.println("read from " + input + " to " + output)
spark.stop()
5.2.2 资源上传
- 把WordCountMapper、WordCountReducer、TopTen打成jar包,比如名字叫demo.jar ,如下:
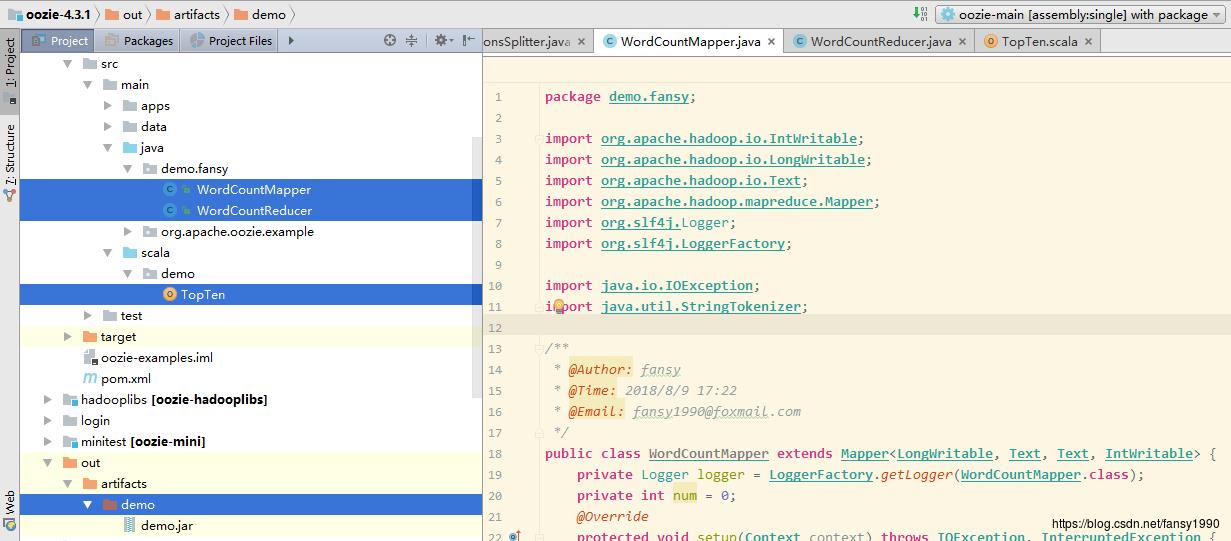
- 把文件workflow.xml , create_table.hive , change_splitter.pig 上传到HDFS 路径:/user/root/examples/apps/all/下面;
- 把demo.jar 上传到HDFS的 /user/root/examples/apps/all/lib/下面;
- 把hive-site.xml(可以在Hive安装路径/conf下面找到)上传到HDFS的/user/root/examples/apps/all/路径下面(这个路径需要和job.properties中对应);
- 把oozie下面的oozie-4.3.1/examples/input-data/text/data.txt 上传到HDFS的/user/root/examples/input-data/all下面,作为整个流程的输入;
5.3 运行:
oozie job --oozie http://master:11000/oozie -config job.properties -run5.4 监控:
5.4.1 oozie :
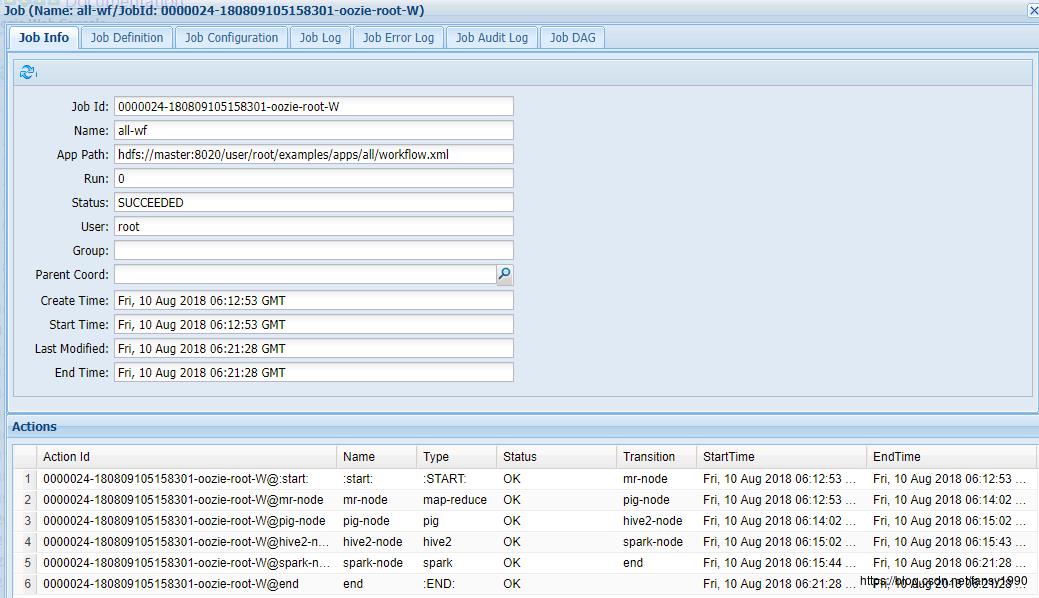
所有发起的MR/Spark任务:
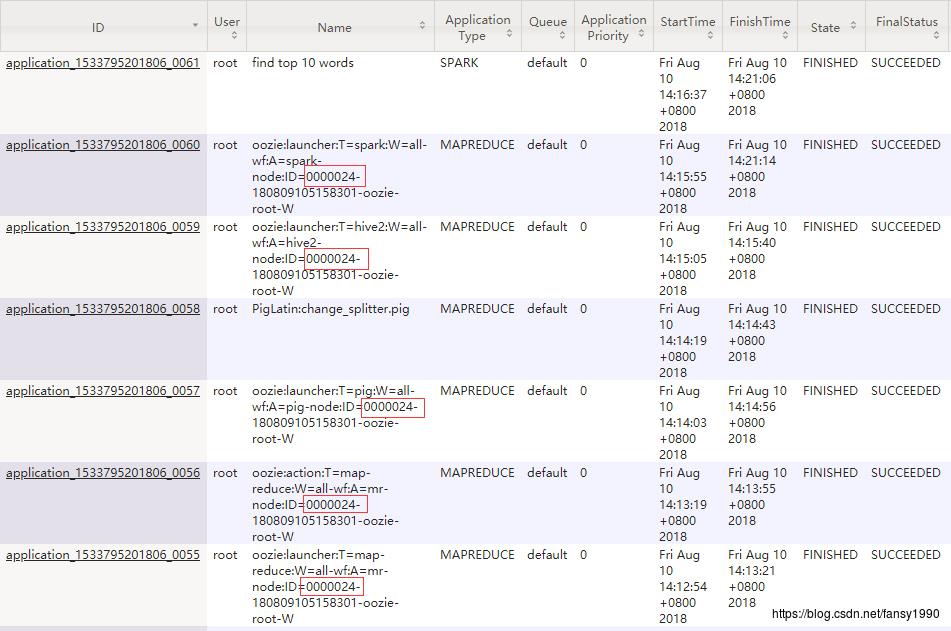
5.4.2 Mapreduce
在MapReduce任务中,传入了一个参数2,用于指定最小的出现次数,可以在MapReduce日志中看到这个参数:
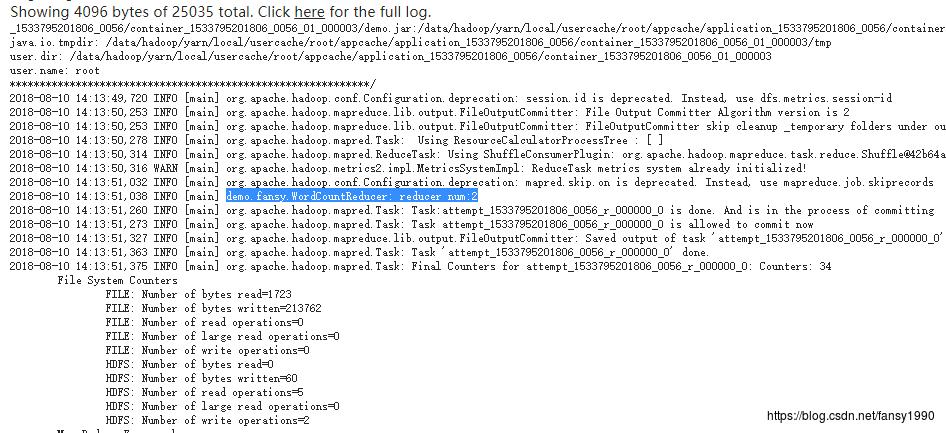
同时设置reduce的个数为2,也可以看出:
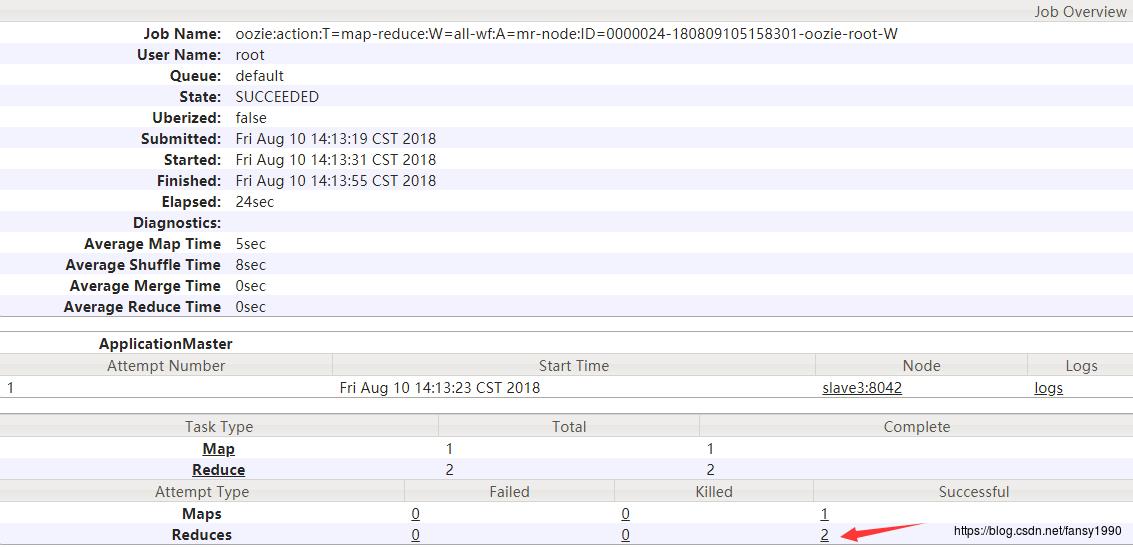
5.4.3 Pig
由于Pig输出的数据导入了Hive,所以数据会经过转移,所以可以查看其在Hive数据中的存储即可,如下:
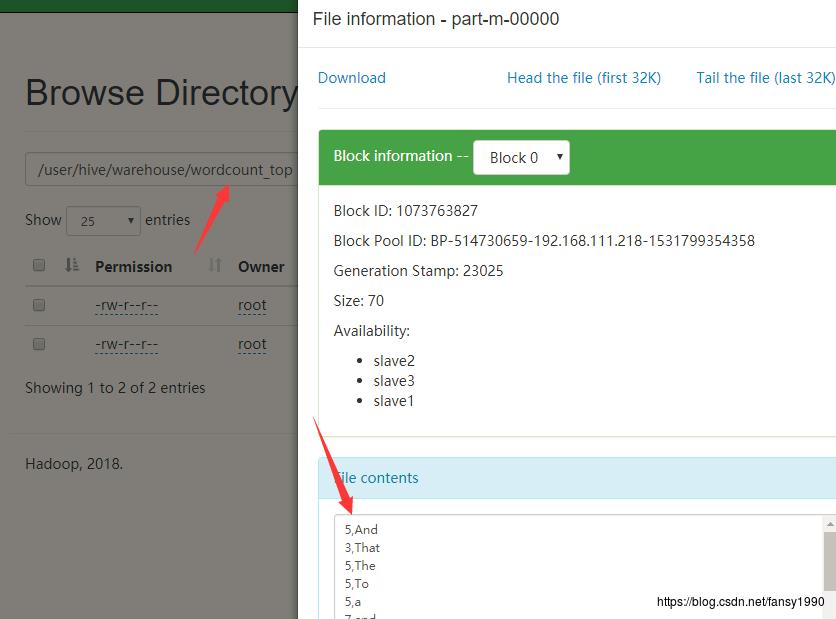
5.4.4 Hive
hive主要是建表,可以通过查看表数据得到:
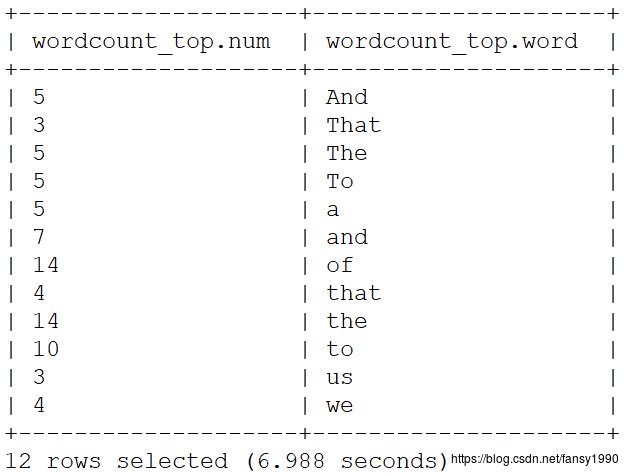
通过上面可以看到数据一共有12条记录,所以也可以通过对比spark的输出,来看spark任务做了哪些工作。
5.4.5
Spark 主要是求top10 ,所以这里有两个工作一个是排序,一个是前10,其结果也是存在Hive表的,所以直接查看Hive表即可。

以上是关于Oozie4.3.1各种Action及综合实例的主要内容,如果未能解决你的问题,请参考以下文章