损失函数MSECross entropyHinge Loss-杂记
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了损失函数MSECross entropyHinge Loss-杂记相关的知识,希望对你有一定的参考价值。
目录
损失函数是机器学习模型的关键部分:定义了衡量模型性能的目标,通过最小化损失函数来确定模型学习的权重参数的设置。有几种不同的常见损失函数可供选择:交叉熵损失、均方误差、huber loss和hinge loss等等。给定一个特定的模型,每个损失函数都有其特性,例如,(L2正则)hinge loss具有最大裕度(maximum-margin)特性,而与线性回归结合使用时的均方误差具有凸性保证。
1.均方误差损失函数(MSE)
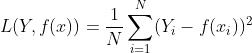
MSE 计算模型的预测与真实标签的接近程度,常用作回归问题的损失函数。损失函数越小,表明预测值与真实值越贴近。
从概率统计的角度来看,其背后的最终支撑是:最小二乘估计假设误差是服从高斯分布的。
以线性回归为例,预测值表示如下:
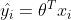 ,令预测值与真实值的误差表示为
,令预测值与真实值的误差表示为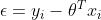
通常误差满足均值为0的高斯分布,即正态分布,即给定条件下样本点 x 来预测回归值 y 的条件概率密度就是:
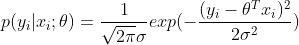
我们期待模型能够在全部样本上预测最准,即概率积最大,这个概率积就称为最大似然估计:
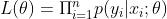
两边同时取ln,得到对数似然
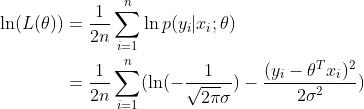
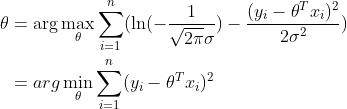
这就是均方误差。
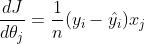
2.交叉熵损失
2.1 二分类
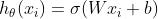
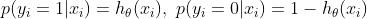
在二分的情况下,模型最后需要预测的结果只有两种情况,可以理解为在线性回归的结果上套了一层sigmoid函数,将实数域的结果压缩到0-1之间,压缩后的结果可以理解为预测为正的概率,对于类别1 的概率是 p,则类别0的概率是1-p, 此时损失函数表示如下:
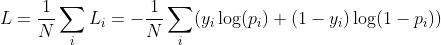
其中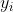 表示样本的类别,正类为1,负类为0。p_i表示预测为正类的概率。
表示样本的类别,正类为1,负类为0。p_i表示预测为正类的概率。
直观解释:
当 即正例时,只有第一部分对损失函数产生贡献,从下图蓝色线可以看出预测概率p越接近1损失越小,越接近0损失越大;当
即正例时,只有第一部分对损失函数产生贡献,从下图蓝色线可以看出预测概率p越接近1损失越小,越接近0损失越大;当 即负例时,只有第二部分对损失函数产生贡献,从下图黄色线可以看出预测概率p越接近0损失越小,越接近1损失越大;这些是符合直觉的。
即负例时,只有第二部分对损失函数产生贡献,从下图黄色线可以看出预测概率p越接近0损失越小,越接近1损失越大;这些是符合直觉的。
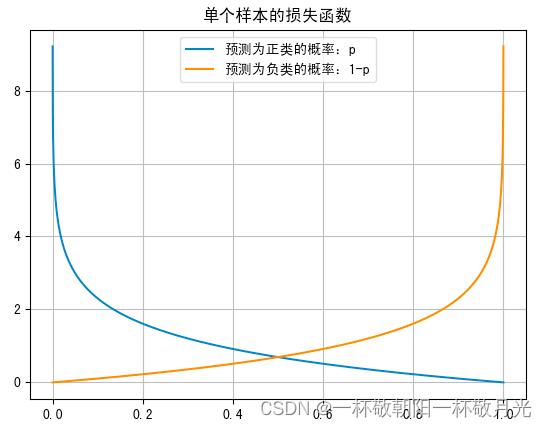
CS231n Convolutional Neural Networks for Visual Recognition
概率解释:
将上面的两种情况合并:
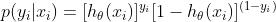
最大似然:
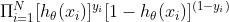
cross entropy loss:
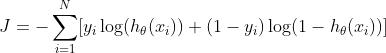
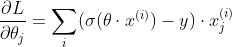
2.2多分类
softMax:
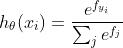
令多分类的标签是one-hot编码的,共有K个类别。
常用的cross entropy loss
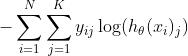
内层求和,由于我们有多个类,我们需要对所有类求和。特别的,由于标签是one-hot编码,所以内层的求和只会有一处不为0,这不为0的数值是正确的类别对应的预测值(归一化后的概率)的对数。其值在[0,1]之间,越接近1取负的对数后越小,越接近0取负的对数之后越大。这种形式的交叉熵只关心正确类别上的预测值
另一种形式的交叉熵损失
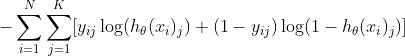
内层求和项,两部分只会有一部分是有值的。第二部分是对非正确类别预测的概率值的损失,当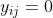 时,即错误类别,我们会期待
时,即错误类别,我们会期待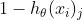 尽量大,也就是在这个类别上的预测值
尽量大,也就是在这个类别上的预测值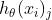 尽可能小。
尽可能小。
2.3 交叉熵损失 和 KL 散度
KL散度与交叉熵区别与联系_nia_wish的博客-CSDN博客_kl散度和交叉熵的区别
熵是表示随机变量不确定性的度量
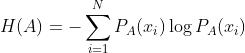
KL散度,又称相对熵,可用于度量两个概率分布之间的差异,KL散度不满足对称性,即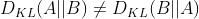 。
。
对于连续事件,
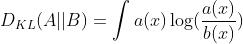
对于离散事件,
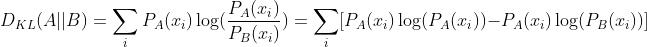
若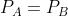 ,即两个事件完全相同,则KL散度等于0。
,即两个事件完全相同,则KL散度等于0。
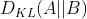 A 与 B 的对数差 在 A 上的期望值。
A 与 B 的对数差 在 A 上的期望值。
交叉熵 VS KL 散度,只考虑第一种情况的交叉熵,这边A表示真实分布,B表示预测分布,
熵
交叉熵
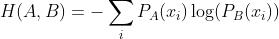
则:

若H(A)是一个常量,则KL散度和交叉熵是等价的。
交叉熵的性质:
- 与KL散度一样,交叉熵也不具备对称性
- 从名字上来看,cross(交叉)主要用于描述两个事件之间的相互关系,对自己求交叉熵等于熵。
2.4交叉熵损失函数的梯度
只考虑第一种情况的交叉熵损失函数,单个样本的交叉熵损失
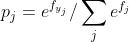 ,
,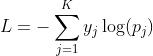
(1)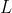 对
对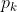 求偏导
求偏导
令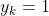 , 其他为0。则
, 其他为0。则 ,则
,则
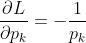
(2) 对 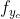 求偏导
求偏导
a) c=k的时候
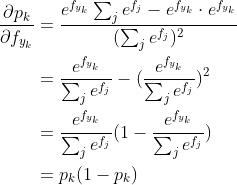
b) 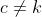 的时候
的时候
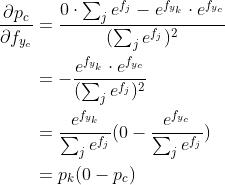
(3)对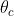 求偏导
求偏导
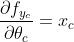
最终的导数:
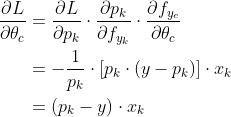
3.Hinge Loss
https://cs231n.github.io/linear-classify/
以上是关于损失函数MSECross entropyHinge Loss-杂记的主要内容,如果未能解决你的问题,请参考以下文章