| class RangePartitioner[K: Ordering : ClassTag, V](
@transient partitions: Int,
@transient rdd: RDD[_ <: Product2[K,V]],
private var ascending: Boolean =true)
extends Partitioner
// We allow partitions = 0, which happens when sorting an empty RDD under the default settings.
require(partitions >= 0, s"Number of partitions cannot be negative but found$partitions.")
private var ordering= implicitly[Ordering[K]]
// An array of upper bounds for the first (partitions - 1) partitions前(partitions - 1)的分区边界
private var rangeBounds: Array[K] =
if (partitions <= 1)
Array.empty
else
// This is the sample size we need to have roughly balanced output partitions, capped at 1M.
val sampleSize = math.min(20.0* partitions, 1e6)
// Assume the input partitions are roughly balanced and over-sample a little bit.
val sampleSizePerPartition = math.ceil(3.0* sampleSize / rdd.partitions.size).toInt
// numItems相当于记录rdd元素的总数
// sketched的类型是Array[(Int, Int, Array[K])],记录的是分区的编号、该分区中总元素的个数以及从父RDD中每个分区采样的数据
val (numItems, sketched) = RangePartitioner.sketch(rdd.map(_._1), sampleSizePerPartition)
if (numItems == 0L)
Array.empty
else
// If a partition contains much more than the average number of items, we re-sample from it
// to ensure that enough items are collected from that partition.
val fraction = math.min(sampleSize / math.max(numItems,1L), 1.0)
val candidates = ArrayBuffer.empty[(K, Float)]
val imbalancedPartitions = mutable.Set.empty[Int]
sketched.foreach case (idx,n, sample) =>
if (fraction * n > sampleSizePerPartition)
imbalancedPartitions += idx
else
// The weight is 1 over the sampling probability.
val weight = (n.toDouble / sample.size).toFloat
for (key<- sample)
candidates += ((key, weight))
if (imbalancedPartitions.nonEmpty)
// Re-sample imbalanced partitions with the desired sampling probability.
val imbalanced =new PartitionPruningRDD(rdd.map(_._1), imbalancedPartitions.contains)
val seed = byteswap32(-rdd.id- 1)
val reSampled = imbalanced.sample(withReplacement =false, fraction, seed).collect()
val weight = (1.0/ fraction).toFloat
candidates ++= reSampled.map(x => (x, weight))
RangePartitioner.determineBounds(candidates, partitions)
def numPartitions: Int = rangeBounds.length +1
private var binarySearch: ((Array[K],K) => Int) = CollectionsUtils.makeBinarySearch[K]
def getPartition(key: Any): Int =
val k = key.asInstanceOf[K]
var partition = 0
if (rangeBounds.length <=128)
// If we have less than 128 partitions naive search
while (partition <rangeBounds.length && ordering.gt(k,rangeBounds(partition)))
partition += 1
else
// Determine which binary search method to use only once.
partition = binarySearch(rangeBounds, k)
// binarySearch either returns the match location or -[insertion point]-1
if (partition <0)
partition = -partition-1
if (partition > rangeBounds.length)
partition = rangeBounds.length
if (ascending)
partition
else
rangeBounds.length - partition
private[spark] objectRangePartitioner
/**
* Sketches the input RDD via reservoir sampling on each partition.
*
* @param rdd the input RDD to sketch
* @param sampleSizePerPartition max sample size per partition
* @return (total number of items, an array of (partitionId, number of items, sample))
*/
def sketch[K: ClassTag](
rdd: RDD[K],
sampleSizePerPartition: Int): (Long, Array[(Int, Int, Array[K])]) =
val shift = rdd.id
// val classTagK = classTag[K] // to avoid serializing the entire partitioner object
val sketched = rdd.mapPartitionsWithIndex (idx, iter) =>
val seed = byteswap32(idx ^ (shift <<16))
//Reservoir:水塘抽样
val (sample, n) = SamplingUtils.reservoirSampleAndCount(
iter, sampleSizePerPartition, seed)
Iterator((idx, n, sample))
.collect()
val numItems = sketched.map(_._2.toLong).sum
(numItems, sketched)
/**
* Determines the bounds for range partitioning from candidates with weights indicating how many
* items each represents. Usually this is 1 over the probability used to sample this candidate.
*
* @param candidates unordered candidates with weights
* @param partitions number of partitions
* @return selected bounds
*/
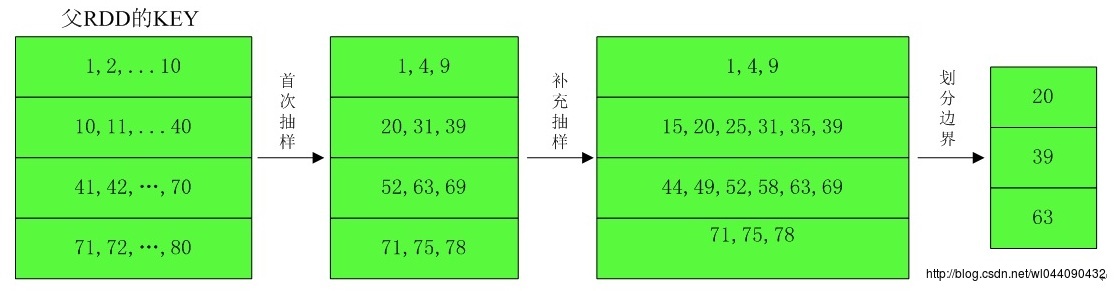
def determineBounds[K: Ordering : ClassTag](
candidates: ArrayBuffer[(K, Float)],
partitions: Int): Array[K] =
val ordering = implicitly[Ordering[K]]
val ordered = candidates.sortBy(_._1)
val numCandidates = ordered.size
val sumWeights = ordered.map(_._2.toDouble).sum
val step = sumWeights / partitions
var cumWeight = 0.0
var target = step
val bounds = ArrayBuffer.empty[K]
var i = 0
var j = 0
var previousBound = Option.empty[K]
while ((i < numCandidates) && (j < partitions -1))
val (key, weight) = ordered(i)
cumWeight += weight
if (cumWeight > target)
// Skip duplicate values.
if (previousBound.isEmpty || ordering.gt(key, previousBound.get))
bounds += key
target += step
j += 1
previousBound = Some(key)
i += 1
bounds.toArray
|