flink笔记12 [Table API和SQL] 创建表环境创建表
Posted Aurora1217
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink笔记12 [Table API和SQL] 创建表环境创建表相关的知识,希望对你有一定的参考价值。
Table API和SQL(一)
1.创建表环境
TableEnvironment 是 Table API 和 SQL 的核心概念。它负责:
- 在内部的 catalog 中注册 Table
- 注册外部的 catalog
- 执行 SQL 查询
- 将 DataStream 或 DataSet 转换成 Table
- 持有对 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用
- 加载可插拔模块
- 注册自定义函数 (scalar、table 或 aggregation)
val tableEnv = StreamTableEnvironment.create(env) // 最简单的创建表环境// 基于老版本planner的流处理
val settings = EnvironmentSettings.newInstance()
.useOldPlanner()
.inStreamingMode()
.build()
val oldStreamTableEnv = StreamTableEnvironment.create(env, settings)
// 基于老版本planner的批处理
val batchEnv = ExecutionEnvironment.getExecutionEnvironment
val oldBatchTableEnv = BatchTableEnvironment.create(batchEnv)// 基于blink planner的流处理
val blinkStreamSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val blinkStreamTableEnv = StreamTableEnvironment.create(env,
blinkStreamSettings)
// 基于blink planner的批处理
val blinkBatchSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inBatchMode()
.build()
val blinkBatchTableEnv = TableEnvironment.create(blinkBatchSettings)// 上一篇导入的是老版本planner
// 如果想使用blink planner 需在pom.xml里引入它的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.12.3</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.12.3</version>
<scope>provided</scope>
</dependency>2.在catalog中创建表
TableEnvironment 维护着一个由标识符(identifier)创建的表 catalog 的映射。标识符由三个部分组成:catalog 名称、数据库名称以及对象名称。如果 catalog 或者数据库没有指明,就会使用当前默认值
Table 可以是虚拟的(视图 VIEWS)也可以是常规的(表 TABLES)。视图 VIEWS可以从已经存在的Table中创建,一般是 Table API 或者 SQL 的查询结果。 表TABLES描述的是外部数据,例如文件、数据库表或者消息队列
2.1直接将流转换成表
val dataTable = tableEnv.fromDataStream(datastream)完整实例:
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.scala.StreamTableEnvironment, tableConversions
case class sensorReading(id:String,timestamp:Long,temperature:Double)
object example
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputstream = env.socketTextStream("localhost",7777)
val datastream = inputstream
.map(
data =>
var arr = data.split(",")
sensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
)
val tableEnv = StreamTableEnvironment.create(env)
val dataTable = tableEnv.fromDataStream(datastream)
val resultTable = dataTable
.select("id,temperature")
.filter("id =='sensor_2'")
resultTable.toAppendStream[(String,Double)].print("result")
env.execute("example test")
2.2通过 connector 声明创建表
Connector 描述了存储表数据的外部系统。存储系统例如 Apache Kafka 或者常规的文件系统都可以通过这种方式来声明。
tableEnvironment
.connect(...)
.withFormat(...)
.withSchema(...)
.inAppendMode()
.createTemporaryTable("MyTable")(1)从文件读取数据
tableEnv
.connect(new FileSystem().path(inputPath)) //连接文件
.withFormat(new OldCsv()) //以csv格式对数据格式化
// .withFormat(new Csv()) //新版本csv,需在pom.xml引入依赖后使用
.withSchema( new Schema()
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("temperature", DataTypes.DOUBLE())
) //定义表结构
.createTemporaryTable(“inputTable”) // 创建临时表 注册表
使用新版csv要引入的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.10.1</version>
</dependency>完整实例:
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.scala.StreamTableEnvironment, tableConversions
import org.apache.flink.table.descriptors.Csv, FileSystem, Schema
object Createtable_field
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv = StreamTableEnvironment.create(env)
tableEnv
.connect(new FileSystem().path("src/main/resources/test.txt"))
.withFormat(new Csv())
.withSchema(
new Schema()
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("inputTable")
// 从表环境获取表
val inputTable = tableEnv.from("inputTable")
val resultTable = inputTable
.select("id, temperature")
.filter("id == 'sensor_2'")
resultTable.toAppendStream[(String,Double)].print("result")
env.execute("test")
test.txt文件(太多了,没截全,前面全是sensor_1,只有最后一个是sensor_2)

结果:
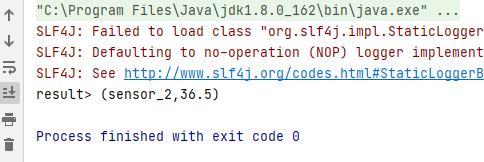
(2)从kafka读取数据转换成表
tableEnv
.connect(
new Kafka()
.version("0.11")
.topic("sensor")
.property("zookeeper.connect","192.168.100.3:2128")
.property("bootstrap.servers","192.168.100.3:9092")
)
.withFormat(new Csv())
.withSchema(
new Schema()
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("kafkaInputTable")完整代码:
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.scala.StreamTableEnvironment, tableConversions
import org.apache.flink.table.descriptors.Csv, Kafka, Schema
object createtable_kafka
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tableEnv = StreamTableEnvironment.create(env)
tableEnv
.connect(
new Kafka()
.version("0.11")
.topic("sensor")
.property("zookeeper.connect","192.168.100.3:2128")
.property("bootstrap.servers","192.168.100.3:9092")
)
.withFormat(new Csv())
.withSchema(
new Schema()
.field("id",DataTypes.STRING())
.field("timestamp",DataTypes.BIGINT())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("kafkaInputTable")
val kafkaInputTable = tableEnv.from("kafkaInputTable")
kafkaInputTable.toAppendStream[(String,Long,Double)].print()
env.execute("table from kafka")
虚拟机运行kafka步骤:
[root@master ~]# cd /home/hadoop/softs/zookeeper-3.5.6/
[root@master zookeeper-3.5.6]# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/softs/zookeeper-3.5.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@master zookeeper-3.5.6]# jps
6952 QuorumPeerMain
6984 Jps
[root@master zookeeper-3.5.6]# cd ../kafka_2.11-0.11.0.3/
[root@master kafka_2.11-0.11.0.3]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
[root@master kafka_2.11-0.11.0.3]# jps
7558 Jps
6952 QuorumPeerMain
7483 Kafka
[root@master kafka_2.11-0.11.0.3]# ./bin/kafka-console-producer.sh --broker-list 192.168.100.3:9092 --topic sensor
>sensor_1,1619492175,36.1
>sensor_2,1619492176,36.6
>sensor_3,1619492177,36.5实验结果:
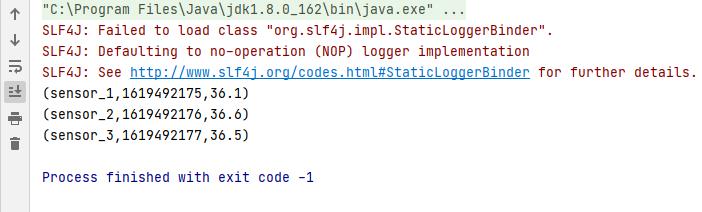
以上是关于flink笔记12 [Table API和SQL] 创建表环境创建表的主要内容,如果未能解决你的问题,请参考以下文章