:文本生成
Posted Sonhhxg_柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:文本生成相关的知识,希望对你有一定的参考价值。
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
基于转换器的语言模型最不可思议的特性之一是它们能够生成与人类编写的文本几乎无法区分的文本。一个著名的例子是 OpenAI 的 GPT-2,当给出提示时:1
在一个令人震惊的发现中,科学家在安第斯山脉的一个偏远、以前未开发的山谷中发现了一群独角兽。更令研究人员惊讶的是,独角兽的英语说得一口流利。
能够生成一篇关于会说话的独角兽的引人入胜的新闻文章:
这位科学家以其独特的角命名了这个种群,奥维德的独角兽。这些四角银白色独角兽以前不为科学所知。现在,在将近两个世纪之后,引发这种奇怪现象的谜团终于解开了。拉巴斯大学的进化生物学家 Jorge Pérez 博士和几位同伴在探索安第斯山脉时发现了一个小山谷,没有其他动物或人类。佩雷斯注意到山谷似乎有一个天然喷泉,周围环绕着两座岩石和银色雪峰。佩雷斯和其他人随后冒险深入山谷。“当我们到达一座山峰的顶部时,水看起来是蓝色的,上面有一些水晶,”佩雷斯说。佩雷斯和他的朋友们惊讶地看到独角兽群。这些生物可以从空中看到,而不必移动太多就能看到它们——它们离得如此之近,以至于它们的角都可以碰到。在检查这些奇怪的生物时,科学家们发现这些生物还会说一些相当正常的英语……
这个例子之所以如此引人注目,是因为它是在没有任何明确监督的情况下生成的!通过简单地学习预测数百万网页文本中的下一个单词,GPT-2 及其更强大的后代(如 GPT-3)能够获得广泛的技能和模式识别能力,这些技能和模式识别能力可以通过不同种类的输入提示。图 5-1展示了语言模型有时如何在预训练期间暴露于任务序列,在这些任务序列中,它们需要仅根据上下文预测以下标记,例如加法、解读单词和翻译。这使他们能够在微调期间或(如果模型足够大)在推理时有效地传递这些知识。这些任务不是提前选择的,而是自然发生在用于训练十亿参数语言模型的庞大语料库中。
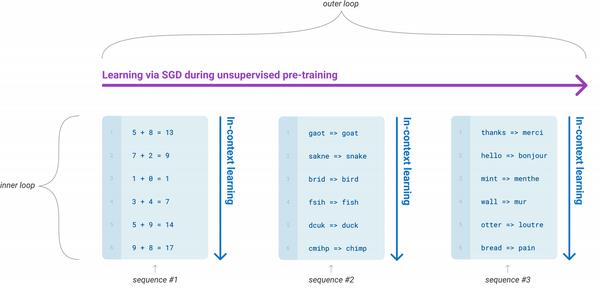
图 5-1。在预训练期间,语言模型暴露于可以在推理过程中调整的任务序列(由 Tom B. Brown 提供)
Transformer 生成逼真文本的能力催生了各种各样的应用,例如 InferKit、Write With Transformer、AI Dungeon ,以及像Google 的 Meena这样甚至可以讲老生常谈的对话代理 ,如图 5-2所示!2
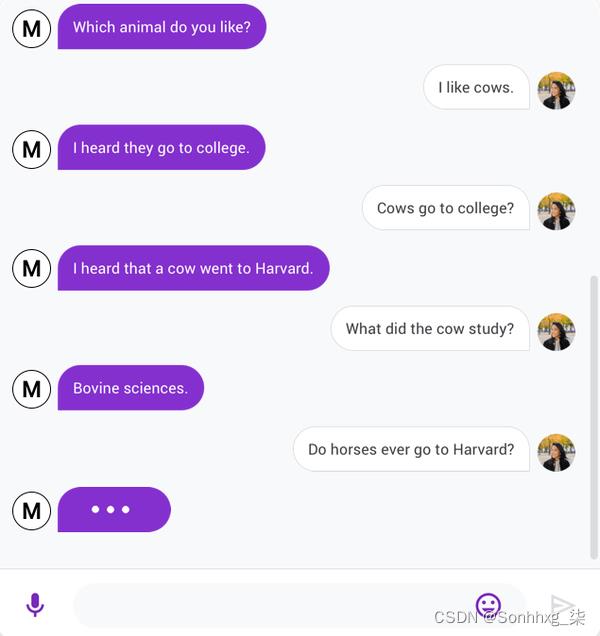
图 5-2。左边的 Meena 给右边的人讲一个老生常谈的笑话(由 Daniel Adiwardana 和 Thang Luong 提供)
在本章中,我们将使用 GPT-2 来说明文本生成如何适用于语言模型,并探讨不同的解码策略如何影响生成的文本。
生成连贯文本的挑战
到目前为止,在本书中,我们一直专注于通过预训练和监督微调的组合来处理 NLP 任务。正如我们所见,对于序列或标记分类等任务特定的头部,生成预测相当简单;该模型会产生一些 logits,我们要么取最大值来获得预测的类,要么应用一个 softmax 函数来获得每个类的预测概率。相比之下,将模型的概率输出转换为文本需要一种解码方法,这引入了一些文本生成特有的挑战:
-
解码是迭代完成的,因此比简单地通过模型的前向传递传递一次输入涉及更多的计算。
-
生成文本的质量和多样性取决于解码方法和相关超参数的选择。
为了理解这个解码过程是如何工作的,让我们首先检查 GPT-2 是如何被预训练并随后应用于生成文本的。
与其他自回归或因果语言模型一样,GPT-2 经过预训练以估计概率 P(𝐲|𝐱)一系列标记的 𝐲=y1,y2,...yt出现在文本中,给定一些初始提示或上下文序列 𝐱=x1,x2,...xk. 因为获得足够的训练数据来估计是不切实际的 P(𝐲|𝐱)直接地,通常使用概率链规则将其分解为条件 概率的乘积:
P(y1,...,yt|𝐱)=∏t=1NP(yt|y<t,𝐱)在哪里y<t是序列的简写符号 y1,...,yt-1. 正是从这些条件概率中,我们得到直觉,自回归语言建模相当于在给定句子中前面的单词的情况下预测每个单词;这正是前面等式右边的概率所描述的。请注意,此预训练目标与 BERT 完全不同,BERT 同时利用过去 和未来的上下文来预测掩码标记。
到目前为止,您可能已经猜到我们如何调整下一个令牌预测任务来生成任意长度的文本序列。如图 5-3所示 ,我们从“Transformers are the”这样的提示开始,并使用模型来预测下一个标记。一旦我们确定了下一个标记,我们将其附加到提示符中,然后使用新的输入序列生成另一个标记。我们这样做,直到我们达到一个特殊的序列结束标记或预定义的最大长度。

图 5-3。通过在每一步向输入添加一个新词来从输入序列生成文本
笔记
这个过程的核心是一个解码方法,它决定在每个时间步选择哪个令牌。由于语言模型头产生一个logitzt,i每个步骤的词汇表中的每个标记,我们可以得到下一个可能的标记的概率分布wi通过采用softmax:
P(yt=wi|y<t,𝐱)=softmax(zt,i)大多数解码方法的目标是通过选择一个𝐲^这样:
𝐲^=argmax𝐲P(𝐲|𝐱)发现𝐲^直接将涉及使用语言模型评估每个可能的序列。由于不存在可以在合理时间内完成此操作的算法,因此我们改用近似值。在本章中,我们将探讨其中的一些近似值,并逐步建立更智能、更复杂的算法,这些算法可用于生成高质量的文本。
贪婪搜索解码
从模型的连续输出中获取离散标记的最简单解码方法是在每个时间步贪婪地选择概率最高的标记:
y^t=argmax yt P(yt|y<t,𝐱)要了解贪婪搜索是如何工作的,让我们从加载具有语言建模头的 15 亿参数版本的 GPT-2 开始:3
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "gpt2-xl"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)现在让我们生成一些文本!尽管  Transformers 为
Transformers 为generate() GPT-2 等自回归模型提供了功能,但我们将自己实现这种解码方法,以了解幕后情况。为了热身,我们将采用与图 5-3相同的迭代方法:我们将使用“Transformers are the”作为输入提示,并运行八个时间步长的解码。在每个时间步,我们为提示中的最后一个标记挑选模型的 logits,并用 softmax 包装它们以获得概率分布。然后我们选择概率最高的下一个标记,将其添加到输入序列中,然后再次运行该过程。以下代码完成了这项工作,并且还在每个时间步存储了五个最可能的标记,因此我们可以可视化备选方案:
import pandas as pd
input_txt = "Transformers are the"
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
iterations = []
n_steps = 8
choices_per_step = 5
with torch.no_grad():
for _ in range(n_steps):
iteration = dict()
iteration["Input"] = tokenizer.decode(input_ids[0])
output = model(input_ids=input_ids)
# Select logits of the first batch and the last token and apply softmax
next_token_logits = output.logits[0, -1, :]
next_token_probs = torch.softmax(next_token_logits, dim=-1)
sorted_ids = torch.argsort(next_token_probs, dim=-1, descending=True)
# Store tokens with highest probabilities
for choice_idx in range(choices_per_step):
token_id = sorted_ids[choice_idx]
token_prob = next_token_probs[token_id].cpu().numpy()
token_choice = (
f"tokenizer.decode(token_id) (100 * token_prob:.2f%)"
)
iteration[f"Choice choice_idx+1"] = token_choice
# Append predicted next token to input
input_ids = torch.cat([input_ids, sorted_ids[None, 0, None]], dim=-1)
iterations.append(iteration)
pd.DataFrame(iterations)| Input | Choice 1 | Choice 2 | Choice 3 | Choice 4 | Choice 5 | |
|---|---|---|---|---|---|---|
| 0 | Transformers are the | most (8.53%) | only (4.96%) | best (4.65%) | Transformers (4.37%) | ultimate (2.16%) |
| 1 | Transformers are the most | popular (16.78%) | powerful (5.37%) | common (4.96%) | famous (3.72%) | successful (3.20%) |
| 2 | Transformers are the most popular | toy (10.63%) | toys (7.23%) | Transformers (6.60%) | of (5.46%) | and (3.76%) |
| 3 | Transformers are the most popular toy | line (34.38%) | in (18.20%) | of (11.71%) | brand (6.10%) | line (2.69%) |
| 4 | Transformers are the most popular toy line | in (46.28%) | of (15.09%) | , (4.94%) | on (4.40%) | ever (2.72%) |
| 5 | Transformers are the most popular toy line in | the (65.99%) | history (12.42%) | America (6.91%) | Japan (2.44%) | North (1.40%) |
| 6 | Transformers are the most popular toy line in the | world (69.26%) | United (4.55%) | history (4.29%) | US (4.23%) | U (2.30%) |
| 7 | Transformers are the most popular toy line in the world | , (39.73%) | . (30.64%) | and (9.87%) | with (2.32%) | today (1.74% |
通过这种简单的方法,我们能够生成句子“变形金刚是世界上最受欢迎的玩具系列”。有趣的是,这表明 GPT-2 已经内化了一些关于变形金刚媒体特许经营权的知识,该特许经营权由两家玩具公司(孩之宝和 Takara Tomy)创建。我们还可以在每个步骤中看到其他可能的延续,这表明了文本生成的迭代性质。与序列分类等其他任务不同,其中单个前向传递足以生成预测,对于文本生成,我们需要一次解码一个输出标记。
实现贪心搜索并不太难,但我们会想使用 Transformers 的内置generate()函数  来探索更复杂的解码方法。为了重现我们的简单示例,让我们确保关闭采样(默认情况下它是关闭的,除非您从状态加载检查点的模型的特定配置否则)并指定
来探索更复杂的解码方法。为了重现我们的简单示例,让我们确保关闭采样(默认情况下它是关闭的,除非您从状态加载检查点的模型的特定配置否则)并指定 max_new_tokens新生成令牌的数量:
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output = model.generate(input_ids, max_new_tokens=n_steps, do_sample=False)
print(tokenizer.decode(output[0]))Transformers are the most popular toy line in the world,
现在让我们尝试一些更有趣的事情:我们能重现 OpenAI 的独角兽故事吗?正如我们之前所做的那样,我们将使用标记器对提示进行编码,并且我们将指定一个更大的值max_length来生成更长的文本序列:
max_length = 128
input_txt = """In a shocking finding, scientist discovered \\
a herd of unicorns living in a remote, previously unexplored \\
valley, in the Andes Mountains. Even more surprising to the \\
researchers was the fact that the unicorns spoke perfect English.\\n\\n
"""
input_ids = tokenizer(input_txt, return_tensors="pt")["input_ids"].to(device)
output_greedy = model.generate(input_ids, max_length=max_length,
do_sample=False)
print(tokenizer.decode(output_greedy[0]))In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. The researchers, from the University of California, Davis, and the University of Colorado, Boulder, were conducting a study on the Andean cloud forest, which is home to the rare species of cloud forest trees. The researchers were surprised to find that the unicorns were able to communicate with each other, and even with humans. The researchers were surprised to find that the unicorns were able
好吧,前几句话与 OpenAI 的例子完全不同,有趣的是不同的大学被认为是这个发现的功劳!我们还可以看到贪婪搜索解码的主要缺点之一:它往往会产生重复的输出序列,这在新闻文章中肯定是不可取的。这是贪心搜索算法的常见问题,它可能无法为您提供最佳解决方案;在解码的上下文中,他们可能会错过总体概率较高的词序列,因为高概率词恰好在低概率词之前。
幸运的是,我们可以做得更好——让我们研究一种称为束搜索解码的流行方法。
笔记
尽管贪婪搜索解码很少用于需要多样性的文本生成任务,但它对于生成短序列(如算术)很有用,其中首选确定性和事实正确的输出。4对于这些任务,您可以通过在格式中提供几个以行分隔的示例
"5 + 8 => 13 \\n 7 + 2 => 9 \\n 1 + 0 =>"作为输入提示来调节 GPT-2。
波束搜索解码
波束搜索不是在每一步解码具有最高概率的令牌,而是跟踪最可能的下一个令牌,其中b被称为波束或 部分假设的数量。通过考虑现有集合的所有可能的下一个标记扩展并选择 b个最可能的扩展来选择下一组波束。重复该过程,直到我们达到最大长度或 EOS 令牌,并通过根据其对数概率对b束进行排序来选择最可能的序列。波束搜索的示例 如图 5-4所示。
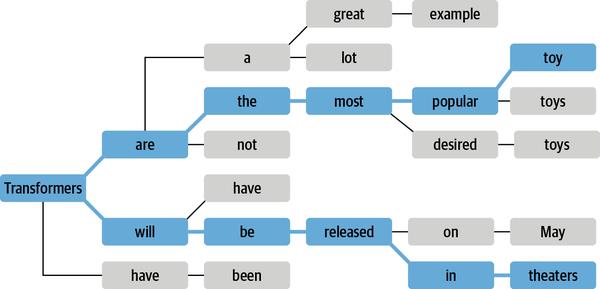
图 5-4。使用两个光束进行光束搜索
为什么我们使用对数概率而不是概率本身对序列进行评分?计算一个序列的总概率P(y1,y2,...,yt|𝐱)涉及计算条件概率的 乘积P(yt|y<t,𝐱)是一个原因。由于每个条件概率通常是范围内的一个小数 [0,1], 采用他们的产品可能会导致总体概率很容易下溢。这意味着计算机不能再精确地表示计算结果。例如,假设我们有一个序列t=1024代币,并慷慨地假设每个代币的概率为 0.5。这个序列的总概率是一个非常小的数字:
0.5 ** 10245.562684646268003e-309
当我们遇到下溢时,这会导致数值不稳定。我们可以通过计算相关项,即对数概率来避免这种情况。如果我们将对数应用于联合概率和条件概率,那么在对数乘积规则的帮助下,我们得到:
logP(y1,...yt|𝐱)=∑t=1NlogP(yt|y<t,𝐱)换句话说,我们之前看到的概率的乘积变成了对数概率的总和,这不太可能遇到数值不稳定性。例如,计算与之前相同示例的对数概率给出:
import numpy as np
sum([np.log(0.5)] * 1024)-709.7827128933695
这是一个我们可以轻松处理的数字,而且这种方法仍然适用于小得多的数字。由于我们只想比较相对概率,我们可以直接用对数概率来做这件事。
让我们计算并比较贪婪搜索和波束搜索生成的文本的对数概率,看看波束搜索是否可以提高整体概率。由于 Transformers 模型在给定输入标记的情况下返回下一个标记的未归一化 logits,因此我们首先需要对 logits 进行归一化,以便为序列中的每个标记创建整个词汇表的概率分布。然后,我们只需要选择序列中存在的标记概率。以下函数实现了这些步骤:
import torch.nn.functional as F
def log_probs_from_logits(logits, labels):
logp = F.log_softmax(logits, dim=-1)
logp_label = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1)
return logp_label这为我们提供了单个标记的对数概率,因此要获得序列的总对数概率,我们只需对每个标记的对数概率求和:
def sequence_logprob(model, labels, input_len=0):
with torch.no_grad():
output = model(labels)
log_probs = log_probs_from_logits(
output.logits[:, :-1, :], labels[:, 1:])
seq_log_prob = torch.sum(log_probs[:, input_len:])
return seq_log_prob.cpu().numpy()请注意,我们忽略了输入序列的对数概率,因为它们不是由模型生成的。我们还可以看到对齐 logits 和标签很重要;由于模型预测下一个标记,我们没有得到第一个标签的 logit,并且我们不需要最后一个 logit,因为我们没有它的基本事实标记。
让我们先用这些函数来计算贪婪解码器在 OpenAI 提示下的序列对数概率:
logp = sequence_logprob(model, output_greedy, input_len=len(input_ids[0]))
print(tokenizer.decode(output_greedy[0]))
print(f"\\nlog-prob: logp:.2f")In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. The researchers, from the University of California, Davis, and the University of Colorado, Boulder, were conducting a study on the Andean cloud forest, which is home to the rare species of cloud forest trees. The researchers were surprised to find that the unicorns were able to communicate with each other, and even with humans. The researchers were surprised to find that the unicorns were able log-prob: -87.43
现在让我们将其与使用波束搜索生成的序列进行比较。要使用该功能激活光束搜索,generate()我们只需要使用num_beams参数指定光束的数量。我们选择的光束越多,结果可能就越好;然而,生成过程变得慢得多,因为我们为每个光束生成并行序列:
output_beam = model.generate(input_ids, max_length=max_length, num_beams=5,
do_sample=False)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\\nlog-prob: logp:.2f")In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. The discovery of the unicorns was made by a team of scientists from the University of California, Santa Cruz, and the National Geographic Society. The scientists were conducting a study of the Andes Mountains when they discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English log-prob: -55.23
我们可以看到,与简单的贪心解码相比,使用波束搜索获得了更好的对数概率(越高越好)。但是,我们可以看到,beam search 也存在重复文本的问题。解决此问题的一种方法是使用跟踪已看到哪些n- gram 的参数no_repeat_ngram_size施加n- gram 惩罚, 如果它会产生先前看到的n- gram ,则将下一个令牌概率设置为零:
output_beam = model.generate(input_ids, max_length=max_length, num_beams=5,
do_sample=False, no_repeat_ngram_size=2)
logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"\\nlog-prob: logp:.2f")In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. The discovery was made by a team of scientists from the University of California, Santa Cruz, and the National Geographic Society. According to a press release, the scientists were conducting a survey of the area when they came across the herd. They were surprised to find that they were able to converse with the animals in English, even though they had never seen a unicorn in person before. The researchers were log-prob: -93.12
这还不错!我们已经设法停止重复,我们可以看到尽管得分较低,但文本仍然连贯。带有n- gram 惩罚的Beam search是一种在关注高概率标记(使用beam search)和减少重复(使用n- gram 惩罚)之间进行权衡的好方法,它通常用于诸如摘要或机器翻译,其中事实正确性很重要。当事实正确性不如生成输出的多样性重要时,例如在开放域闲聊或故事生成中,另一个减少重复同时提高多样性的替代方法是使用抽样。让我们通过检查一些最常见的采样方法来完成我们对文本生成的探索。
抽样方法
最简单的抽样方法是在每个时间步从模型输出在整个词汇表上的概率分布中随机抽样:
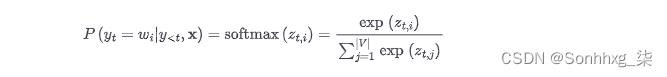
在哪里|V|表示词汇的基数。我们可以通过添加温度参数T轻松控制输出的多样性,该参数在采用 softmax 之前重新调整 logits:
通过调整T,我们可以控制概率分布的形状。5什么时候T≪1,分布在原点附近达到峰值,稀有令牌被抑制。另一方面,当T≫1,分布趋于平缓,每个代币变得同样可能。温度对令牌概率的影响如图 5-5所示。
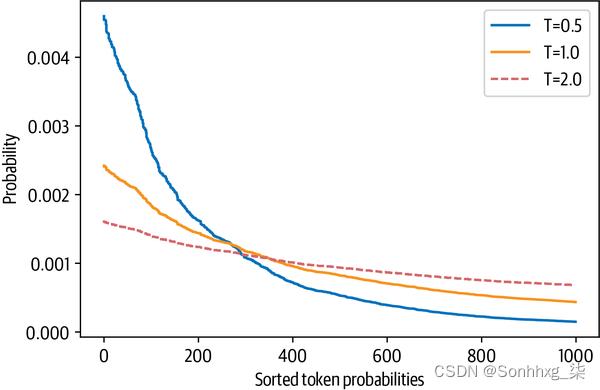
图 5-5。三个选定温度的随机生成令牌概率分布
要了解我们如何使用温度来影响生成的文本,让我们以T=2通过在函数中设置 temperature参数generate()(我们将top_k在下一节解释参数的含义):
output_temp = model.generate(input_ids, max_length=max_length, do_sample=True,
temperature=2.0, top_k=0)
print(tokenizer.decode(output_temp[0]))In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. While the station aren protagonist receive Pengala nostalgiates tidbitRegarding Jenny loclonju AgreementCON irrational �rite Continent seaf A jer Turner Dorbecue WILL Pumpkin mere Thatvernuildagain YoAniamond disse * Runewitingkusstemprop);b zo coachinginventorymodules deflation press Vaticanpres Wrestling chargesThingsctureddong Ty physician PET KimBi66 graz Oz at aff da temporou MD6 radi iter
我们可以清楚地看到,高温产生了大部分乱码;通过强调稀有标记,我们使模型创建了奇怪的语法和相当多的虚构词!让我们看看如果我们降低温度会发生什么:
output_temp = model.generate(input_ids, max_length=max_length, do_sample=True,
temperature=0.5, top_k=0)
print(tokenizer.decode(output_temp[0]))In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. The scientists were searching for the source of the mysterious sound, which was making the animals laugh and cry. The unicorns were living in a remote valley in the Andes mountains 'When we first heard the noise of the animals, we thought it was a lion or a tiger,' said Luis Guzman, a researcher from the University of Buenos Aires, Argentina. 'But when
这明显更加连贯,甚至包括另一所大学的引用被认为是这一发现!我们可以从温度中吸取的主要教训是,它允许我们控制样本的质量,但始终需要在一致性(低温)和多样性(高温)之间进行权衡,我们必须根据用例进行调整手。
调整连贯性和多样性之间权衡的另一种方法是截断词汇的分布。这允许我们随温度自由调整多样性,但在更有限的范围内排除在上下文中过于陌生的词(即低概率词)。有两种主要方法可以做到这一点:top- k和nucleus(或top- p)采样。让我们来看看。
Top-k 和核采样
Top - k和核(top- p)采样是使用温度的两种流行的替代方案或扩展。在这两种情况下,基本思想是限制我们在每个时间步可以采样的可能标记的数量。为了了解它是如何工作的,让我们首先可视化模型输出的累积概率分布T=1如图 5-6 所示。
让我们梳理一下这些图,因为它们包含大量信息。在上图中,我们可以看到令牌概率的直方图。它周围有一个高峰10-8和第二个较小的山峰10-4,随后急剧下降,只有少数令牌出现,概率介于 10-2和10-1. 看这张图,我们可以看到选择最高概率的代币的概率(孤立的柱子在10-1) 是十分之一。
图 5-6。下一个令牌预测的概率分布(上)和下降令牌概率的累积分布(下)
在下图中,我们按概率降序对标记进行了排序,并计算了前 10,000 个标记的累积总和(GPT-2 的词汇表中总共有 50,257 个标记)。曲线表示选择任何前面标记的概率。例如,大约有 96% 的机会以最高的概率选择 1,000 个令牌中的任何一个。我们看到概率迅速上升到 90% 以上,但只有在几千个令牌之后才饱和到接近 100%。该图显示,有 100 分之一的机会不会选择任何甚至不在前 2,000 名中的代币。
尽管这些数字乍一看可能看起来很小,但它们变得很重要,因为我们在生成文本时对每个标记进行一次采样。因此,即使只有 100 分之一或 1000 次的机会,如果我们进行数百次采样,也有很大的机会在某个时候挑选出不太可能的标记——并且在采样时选择这样的标记会严重影响生成文本的质量。出于这个原因,我们通常希望避免这些非常不可能的标记。这就是 top- k和 top- p采样发挥作用的地方。
top- k采样背后的想法是通过仅从具有最高概率的k个令牌中采样来避免低概率选择。这对分布的长尾进行了固定切割,并确保我们仅从可能的选择中采样。回到图 5-6,top - k采样等价于定义一条垂直线并从左侧的标记进行采样。同样,该函数generate() 提供了一个简单的方法来实现top_k这一点:
output_topk = model.generate(input_ids, max_length=max_length, do_sample=True,
top_k=50)
print(tokenizer.decode(output_topk[0]))In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. The wild unicorns roam the Andes Mountains in the region of Cajamarca, on the border with Argentina (Picture: Alamy/Ecole Nationale Supérieure d'Histoire Naturelle) The researchers came across about 50 of the animals in the valley. They had lived in such a remote and isolated area at that location for nearly a thousand years that
这可以说是迄今为止我们生成的最人性化的文本。但是我们如何选择k呢?k的值 是手动选择的,并且对于序列中的每个选择都是相同的,与实际输出分布无关。通过查看一些文本质量指标,我们可以找到一个好的k值,我们将在下一章中探讨这些指标——但固定的截止值可能不太令人满意。
另一种方法是使用动态截止。对于核或 top- p采样,我们没有选择固定的截止值,而是设置了何时截止的条件。这种情况是达到选择中的一定概率质量的时候。假设我们将该值设置为 95%。然后,我们按概率对所有标记进行降序排序,并从列表顶部一个接一个地添加标记,直到所选标记的概率总和为 95%。回到图 5-6,p的值 在概率累积和图上定义一条水平线,我们仅从该线下方的标记中采样。根据输出分布,这可能只是一个(非常可能)令牌或一百个(更可能)令牌。在这一点上,您可能并不惊讶该generate()函数还提供了一个参数来激活 top- p采样。让我们试一试:
output_topp = model.generate(input_ids, max_length=max_length, do_sample=True,
top_p=0.90)
print(tokenizer.decode(output_topp[0]))In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. The scientists studied the DNA of the animals and came to the conclusion that the herd are descendants of a prehistoric herd that lived in Argentina about 50,000 years ago. According to the scientific analysis, the first humans who migrated to South America migrated into the Andes Mountains from South Africa and Australia, after the last ice age had ended. Since their migration, the animals have been adapting to
Top- p抽样也产生了一个连贯的故事,这一次是关于从澳大利亚到南美的迁移的新转折。您甚至可以将这两种采样方法结合起来,以获得两全其美的效果。设置top_k=50并top_p=0.9对应于从最多 50 个代币池中选择概率质量为 90% 的代币的规则。
笔记
当我们使用采样时,我们也可以应用束搜索。与其贪婪地选择下一批候选令牌,我们可以对它们进行采样并以相同的方式构建光束。
哪种解码方法最好?
不幸的是,没有普遍“最佳”的解码方法。哪种方法最好取决于您为其生成文本的任务的性质。如果您希望您的模型执行诸如算术之类的精确任务或为特定问题提供答案,那么您应该降低温度或使用确定性方法(如贪婪搜索与光束搜索相结合)以确保获得最可能的答案。如果您希望模型生成更长的文本,甚至有点创意,那么您应该切换到采样方法并提高温度或使用 top- k和核采样的混合。
结论
在本章中,我们研究了文本生成,这是一项与我们之前遇到的 NLU 任务非常不同的任务。生成文本需要每个生成的令牌至少一次前向传递,如果我们使用束搜索,则需要更多。这使得文本生成对计算的要求很高,并且需要正确的基础设施来大规模运行文本生成模型。此外,将模型的输出概率转换为离散标记的良好解码策略可以提高文本质量。找到最佳解码策略需要对生成的文本进行一些实验和主观评估。
然而,在实践中,我们不想仅仅根据直觉做出这些决定!与其他 NLP 任务一样,我们应该选择一个模型性能指标来反映我们想要解决的问题。不出所料,选择范围很广,我们将在下一章中遇到最常见的选择,在那里我们将了解如何训练和评估文本摘要模型。或者,如果你迫不及待想学习如何从头开始训练 GPT 类型的模型,你可以直接跳到第 10 章,在那里我们收集了大量的代码数据集,然后在其上训练自回归语言模型。
以上是关于:文本生成的主要内容,如果未能解决你的问题,请参考以下文章