flink笔记13 [Table API和SQL] 查询表输出表查看执行计划
Posted Aurora1217
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flink笔记13 [Table API和SQL] 查询表输出表查看执行计划相关的知识,希望对你有一定的参考价值。
查询表、输出表、查看执行计划
1.查询表
Flink给我们提供了两种查询方式:Table API和 Flink SQL
查询表具体操作有很多,可以参考官方文档:Table API & SQL
完整实例:
(1)Table API查询
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.scala.StreamTableEnvironment, tableConversions
case class sensorReading(id:String,timestamp:Long,temperature:Double)
object select
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputstream = env.socketTextStream("localhost",7777)
val datastream = inputstream
.map(
data =>
var arr = data.split(",")
sensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
)
val tableEnv = StreamTableEnvironment.create(env)
val dataTable = tableEnv.fromDataStream(datastream)
// 调用table api进行转换
val resultTable = dataTable
.select("id, temperature")
.filter("id == 'sensor_2'")
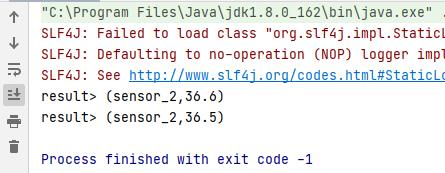
resultTable.toAppendStream[(String,Double)].print("result")
env.execute("select test")

(2) SQL 查询
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.scala.StreamTableEnvironment, tableConversions
import org.apache.flink.types.Row
case class sensorReading(id:String,timestamp:Long,temperature:Double)
object select
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputstream = env.socketTextStream("localhost",7777)
val datastream = inputstream
.map(
data =>
var arr = data.split(",")
sensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
)
val tableEnv = StreamTableEnvironment.create(env)
val dataTable = tableEnv.fromDataStream(datastream)
tableEnv.createTemporaryView("dataTable",dataTable)
val resultTable = tableEnv.sqlQuery(
"""
|select id,count(id) as count_sensor
|from dataTable
|group by id
|""".stripMargin)
// resultTable.toRetractStream[(String,Double)].print() 两种都行
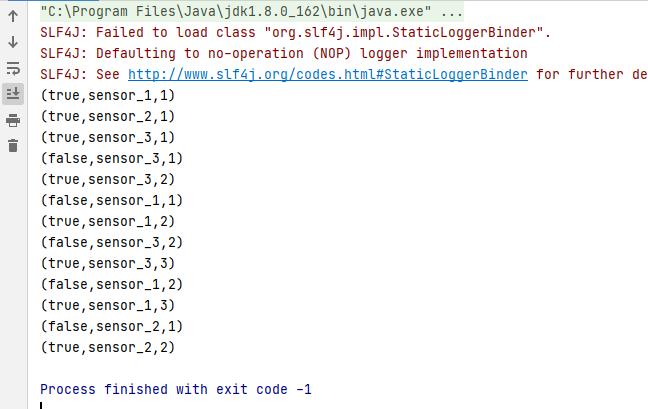
resultTable.toRetractStream[Row].print()
env.execute("select test")
2.输出表
(1)将表转换为 DataStream,然后打印
转换有两种转换模式:追加(Append)模式和撤回(Retract)模式
Append普通查询,Retract在有聚合操作之后使用

从这张图理解,如果有聚合操作,就需要Retract
当第二个mary的点击数据插入时,就需要将第一条数据撤回(删除delete),然后再插入一条Mary 2,就只能用Retract而不能使用Append
具体实例见查询表的两个例子
(2)输出到文件
//创建一个表,输出到这个表里
tableEnv
.connect(new FileSystem().path("src/main/resources/outputtable.txt"))
.withFormat(new Csv())
.withSchema(
new Schema()
.field("id",DataTypes.STRING())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("outPutTable")
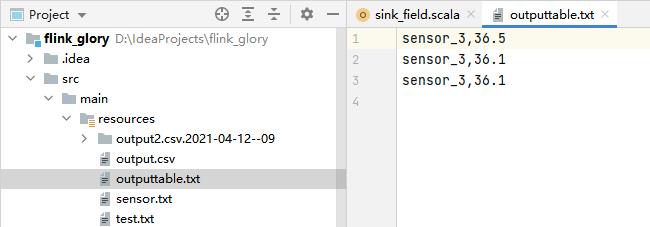
resultTable.insertInto("outPutTable")具体实例:
sensor.txt
sensor_1,1619492175,36.1
sensor_2,1619492176,36.6
sensor_3,1619492177,36.5
sensor_3,1619492178,36.1
sensor_1,1619492179,36.8
sensor_3,1619492180,36.1
sensor_1,1619492209,36.5
sensor_2,1619492209,36.5实验代码:
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.descriptors.Csv, FileSystem, Schema
case class sensorReading(id:String,timestamp:Long,temperature:Double)
object sink_field
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputStream = env.readTextFile("src/main/resources/sensor.txt")
val dataStream = inputStream
.map(
data =>
val arr = data.split(",")
sensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
)
val tableEnv = StreamTableEnvironment.create(env)
val dataTable = tableEnv.fromDataStream(dataStream)
val resultTable = dataTable
.select("id,temperature")
.filter("id == 'sensor_3'")
tableEnv
.connect(new FileSystem().path("src/main/resources/outputtable.txt"))
.withFormat(new Csv())
.withSchema(
new Schema()
.field("id",DataTypes.STRING())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("outPutTable")
resultTable.insertInto("outPutTable")
env.execute("sink field test")
实验结果:
(3)输出到kafka
//建一个表,输出到这个表里
tableEnv
.connect(
new Kafka()
.version("0.11")
.topic("tablesinkkafka")
.property("zookeeper.connect","192.168.100.3:2181")
.property("bootstrap.servers","192.168.100.3:9092")
)
.withFormat(new Csv())
.withSchema(
new Schema()
.field("id",DataTypes.STRING())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("tableoutputkafka")
resultTable.insertInto("tableoutputkafka")具体实例:
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment, createTypeInformation
import org.apache.flink.table.api.DataTypes
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.descriptors.Csv, Kafka, Schema
case class sensorReading(id:String,timestamp:Long,temperature:Double)
object sink_kafka
def main(args: Array[String]): Unit =
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputStream = env.readTextFile("src/main/resources/sensor.txt")
val dataStream = inputStream
.map(
data =>
val arr = data.split(",")
sensorReading(arr(0),arr(1).toLong,arr(2).toDouble)
)
val tableEnv = StreamTableEnvironment.create(env)
val dataTable = tableEnv.fromDataStream(dataStream)
val resultTable = dataTable
.select("id,temperature")
.filter("id == 'sensor_3'")
tableEnv
.connect(
new Kafka()
.version("0.11")
.topic("tablesinkkafka")
.property("zookeeper.connect","192.168.100.3:2181")
.property("bootstrap.servers","192.168.100.3:9092")
)
.withFormat(new Csv())
.withSchema(
new Schema()
.field("id",DataTypes.STRING())
.field("temperature",DataTypes.DOUBLE())
)
.createTemporaryTable("tableoutputkafka")
resultTable.insertInto("tableoutputkafka")
env.execute("sink field test")
实验结果:
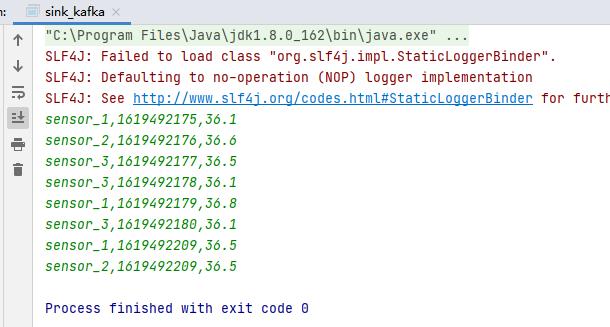

附启动及关闭zookeeper和kafka消费者的方法
[root@master ~]# cd /home/hadoop/softs/zookeeper-3.5.6/
[root@master zookeeper-3.5.6]# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/softs/zookeeper-3.5.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@master zookeeper-3.5.6]# jps
6889 QuorumPeerMain
6921 Jps
[root@master zookeeper-3.5.6]# cd ../kafka_2.11-0.11.0.3/
[root@master kafka_2.11-0.11.0.3]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
[root@master kafka_2.11-0.11.0.3]# jps
6889 QuorumPeerMain
7166 Kafka
7231 Jps
[root@master kafka_2.11-0.11.0.3]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.3:9092 --topic tablesinkkafka
sensor_3,36.5
sensor_3,36.1
sensor_3,36.1
^CProcessed a total of 3 messages
[root@master kafka_2.11-0.11.0.3]# ./bin/kafka-server-stop.sh
[root@master kafka_2.11-0.11.0.3]# cd ..
[root@master softs]# cd zookeeper-3.5.6/
[root@master zookeeper-3.5.6]# ./bin/zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /home/hadoop/softs/zookeeper-3.5.6/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED3.查看执行计划
Table API 提供了一种机制来解释计算表的逻辑和优化查询计划
tableEnvironment.explain(table)返回一个字符串,描述三个计划:优化的逻辑查询计划、优化后的逻辑查询计划、实际执行计划
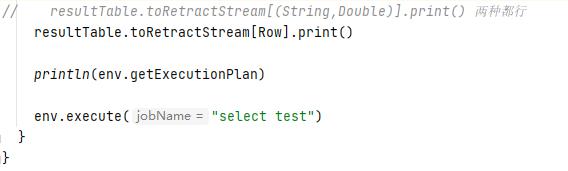
[实例]:修改查询表的SQL查询代码,在下图的位置加入以下代码:

得到结果:

流处理查看执行计划:
Flink官网提供了Flink作业可视化工具Flink plan visualizer
在代码里添加如下一行,然后运行
println(env.getExecutionPlan)运行出来会打印一行json,然后把json复制到网址里https://flink.apache.org/visualizer/查看结果
[实例]:修改查询表的SQL查询代码,在下图的位置加入以下代码:
实验结果:

将第一行的json复制到https://flink.apache.org/visualizer/网址(打开该网址,可以看到有粘贴的地方)
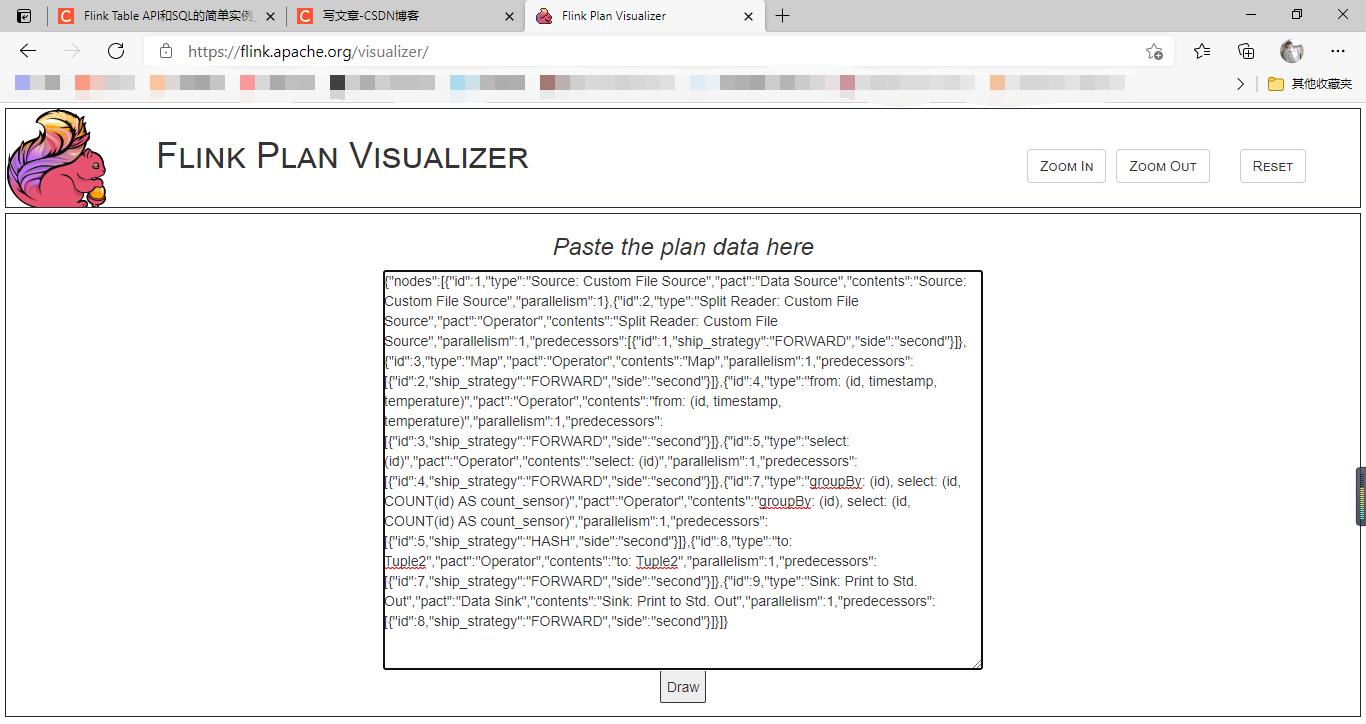
结果:

以上是关于flink笔记13 [Table API和SQL] 查询表输出表查看执行计划的主要内容,如果未能解决你的问题,请参考以下文章