RabbitMQ的幂等性和集群负载均衡
Posted 未来.....
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ的幂等性和集群负载均衡相关的知识,希望对你有一定的参考价值。
RabbitMQ的幂等性和集群负载均衡
1、RabbitMQ的幂等性
假设你买了一样东西,已经付款了,但是返回结果的时候,你的网络异常了,此时钱已经扣了,用户再次点击支付,就会进行二次扣款,返回结果成功了,但是这样合理嘛?肯定不行的,因为你支付了两次,这样不合理,因为你只需要支付1次就可以。
以前我们只需要将数据操作放到事务中,发生错误立即回滚就行,但是再次相应还是可能会出现网络终端或者异常等情况,所以现在就需要保证用户点击一次或者多次所产生的结果一样。
那么此时就可以去这样理解幂等性:
- 对于一个资源,不管你请求一次还是请求多次,对该资源本身造成的影响应该是相同的,不能因为重复相同的请求而对该资源重复造成影响。注意关注的是请求操作对资源本身造成的影响,而不是请求资源返回的结果,这就是幂等性。
上代码:
@Component
public class MyListener
@Autowired
private RedisTemplate redisTemplate;
@RabbitListener(queues = "queue")
public void listener(Message msg, Channel channel) throws Exception
//Boolean absent =
Object o = redisTemplate.opsForValue().get(msg.getMessageProperties().getDeliveryTag());
if(o==null)
//业务代码
try
System.out.println("完成业务功能");
redisTemplate.opsForValue().set(msg.getMessageProperties().getDeliveryTag(), "yth");
channel.basicAck(msg.getMessageProperties().getDeliveryTag(), true);
catch (Exception e)
channel.basicNack(msg.getMessageProperties().getDeliveryTag(),true,true);
else
channel.basicAck(msg.getMessageProperties().getDeliveryTag(),true);
这里只能列出来代码,测试结果是没有办法得到。
2、RabbitMQ集群
2、1为什么要使用集群?
集群是为了解决单机可能出现宕机等引发的不可用的问题,可以有效提高程序的可用性和可靠性以及抗并发的能力。
集群分为两种模式:
- 普通模式:默认的集群模式。
默认集群对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。当rabbit01节点故障后,rabbit02节点无法取到rabbit01节点中还未消费的消息实体。如果做了消息持久化,那么得等rabbit01节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
- 镜像模式:把需要的队列做成镜像队列,存在于多个节点。
镜像集群把需要的队列做成镜像队列,存在与多个节点属于RabbitMQ的HA方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
2、2RabbitMQ普通集群
这里采用了伪集群:一台主机启动多个RabbitMQ服务。
先停止原有的RabbitMQ服务:
service rabbitmq-server stop
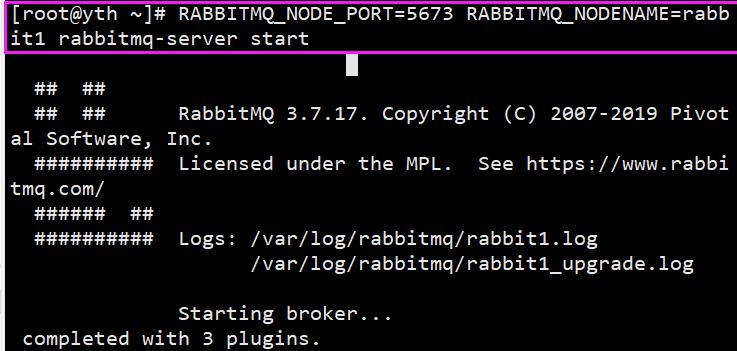
- 开启第一个节点:
RABBITMQ_NODE_PORT=5673 RABBITMQ_NODENAME=rabbit1 rabbitmq-server start
放行15672端口:
firewall-cmd --zone=public --add-port=15672/tcp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --query-port=15672/tcp
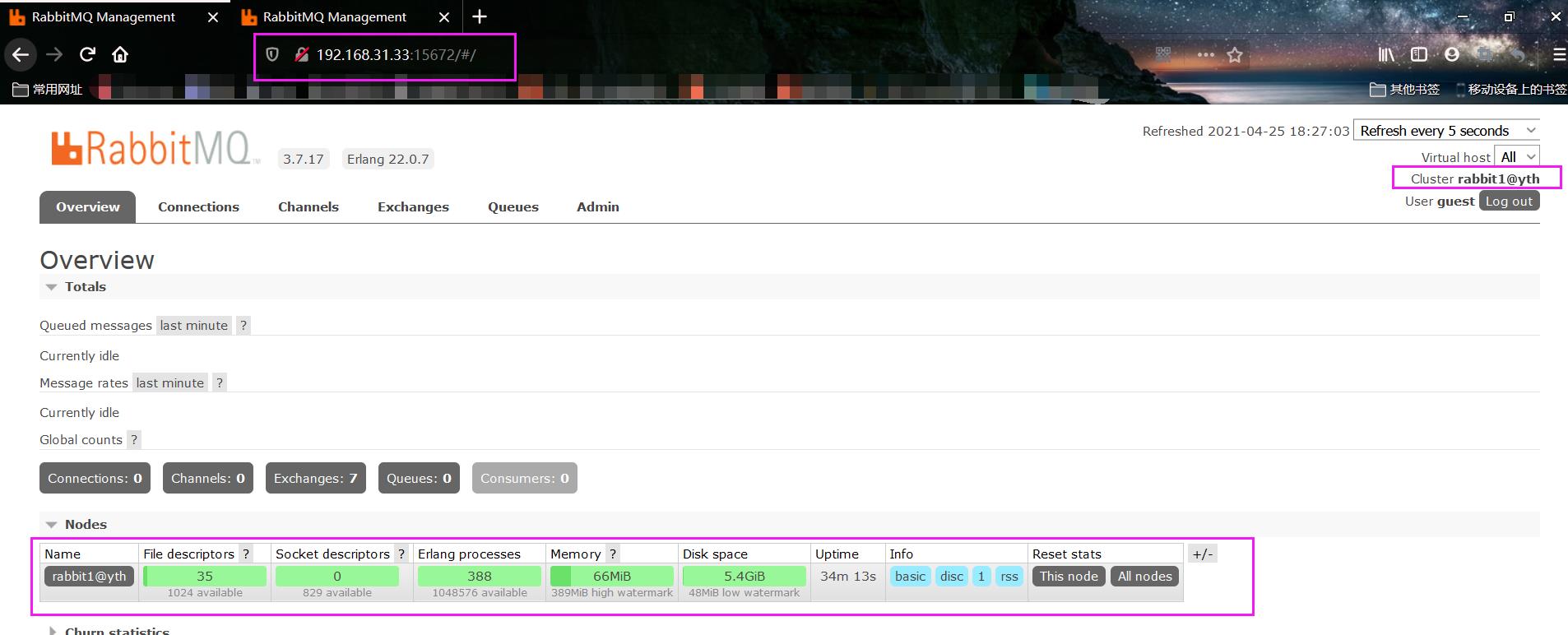
在浏览器登录查看是否可以进入可视化管理界面:
提示:rabbit1是使用的15672端口
- 开启第二个节点:
RABBITMQ_NODE_PORT=5674 RABBITMQ_SERVER_START_ARGS="-rabbitmq_management listener [port,15674]" RABBITMQ_NODENAME=rabbit2 rabbitmq-server start
放行15674端口:
firewall-cmd --zone=public --add-port=15674/tcp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --query-port=15674/tcp
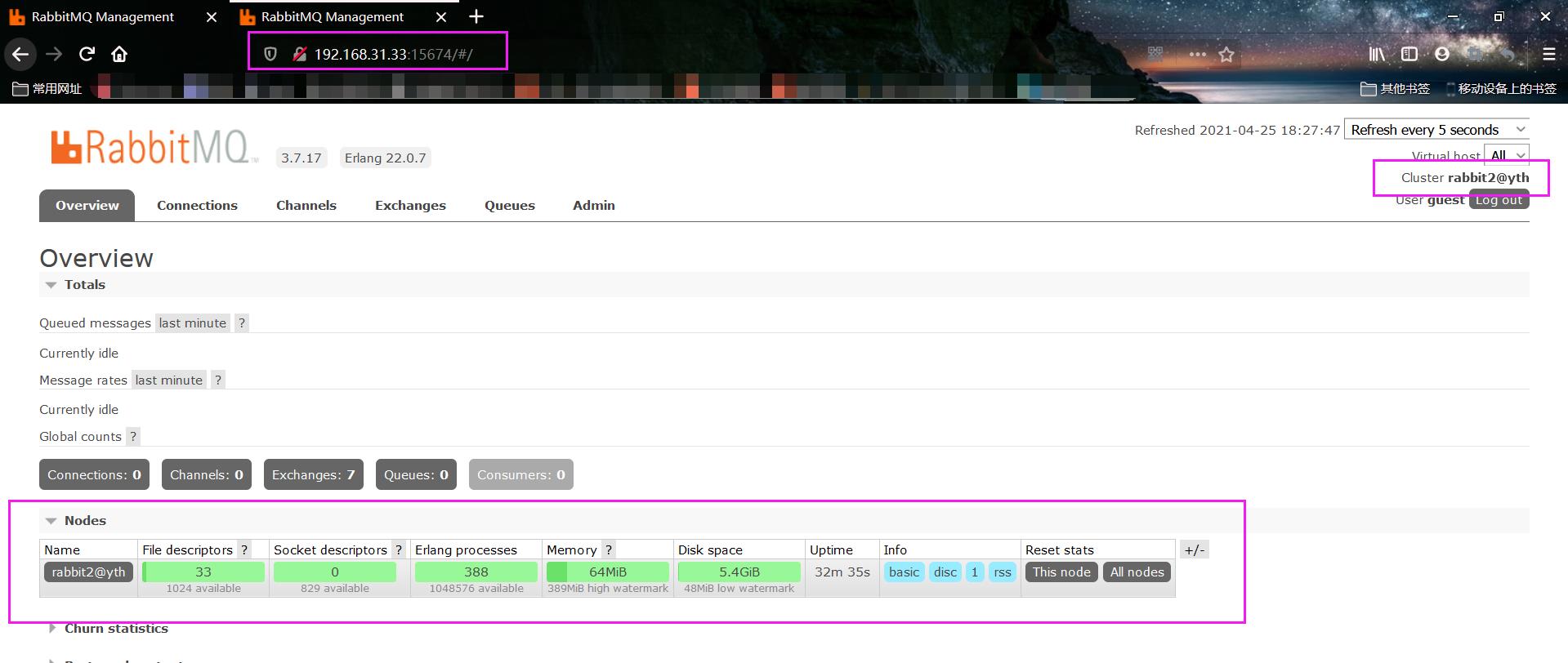
在浏览器登录查看是否可以进入可视化管理界面:
提示:rabbit2是使用的15674端口
- 设置主从关系:
rabbit1作为主节点:
rabbitmqctl -n rabbit1 stop_app
rabbitmqctl -n rabbit1 reset
rabbitmqctl -n rabbit1 start_app
rabbit2作为从节点:
’ '里面是你的主机名
rabbitmqctl -n rabbit2 stop_app
rabbitmqctl -n rabbit2 reset
rabbitmqctl -n rabbit2 join_cluster rabbit1@'yth'
rabbitmqctl -n rabbit2 start_app
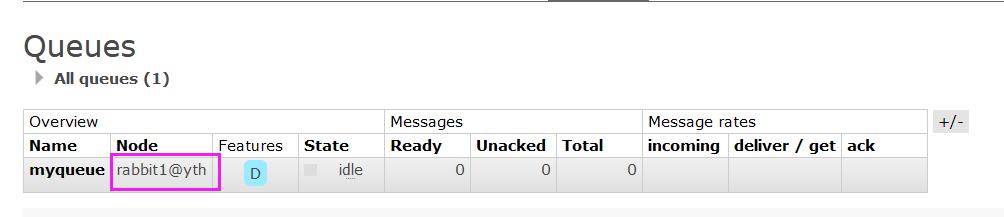
在可视化界面里面查看,发现已经绑定上了。

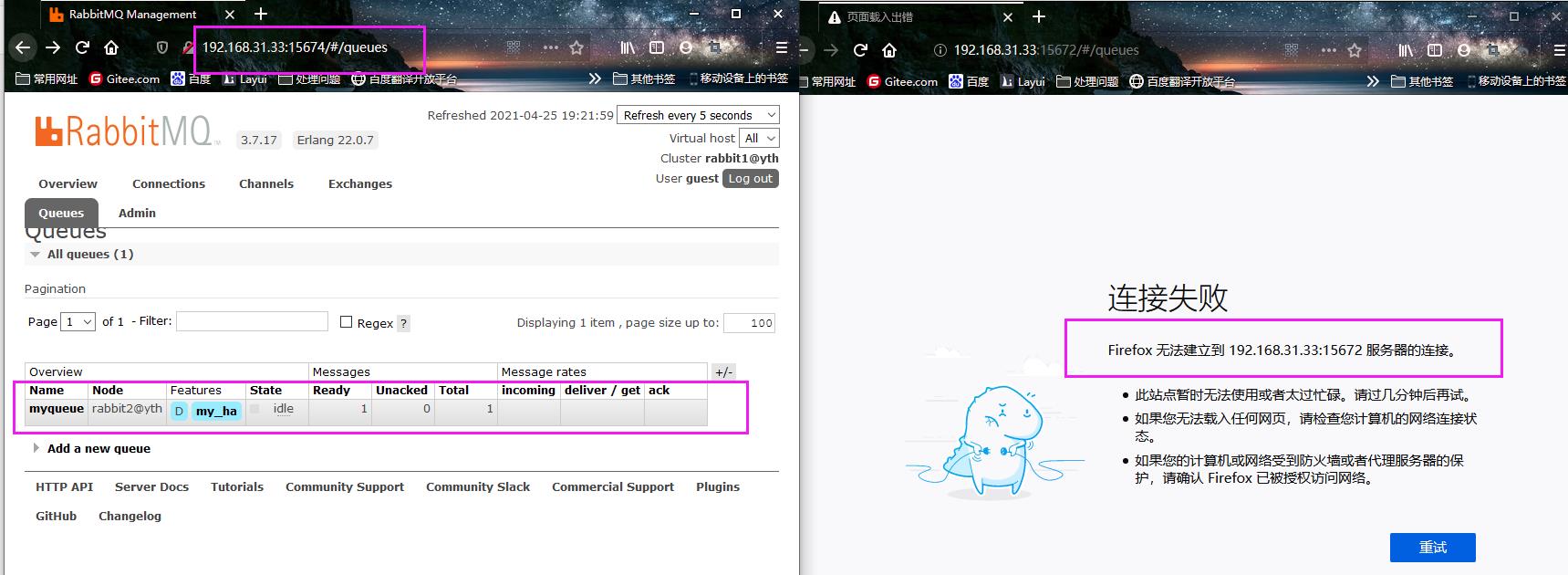
- 在任意一个节点上创建队列,会发现两个节点上都出现这个myqueue。
此时在队列中发布一条信息,主节点上是有信息。

关闭主节点,看看子节点上的信息是否会消失。

发现主节点关闭,子节点也会掉,这样不行,太假了,此时就需要用到镜像集群了。
2、3RabbitMQ镜像集群
-
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。虽然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
-
镜像队列是基于普通的集群模式的,然后再添加一些策略,所以你还是得先配置普通集群,然后才能设置镜像队列,我们就以上面的集群接着做。
- 在普通集群的基础上配置镜像集群
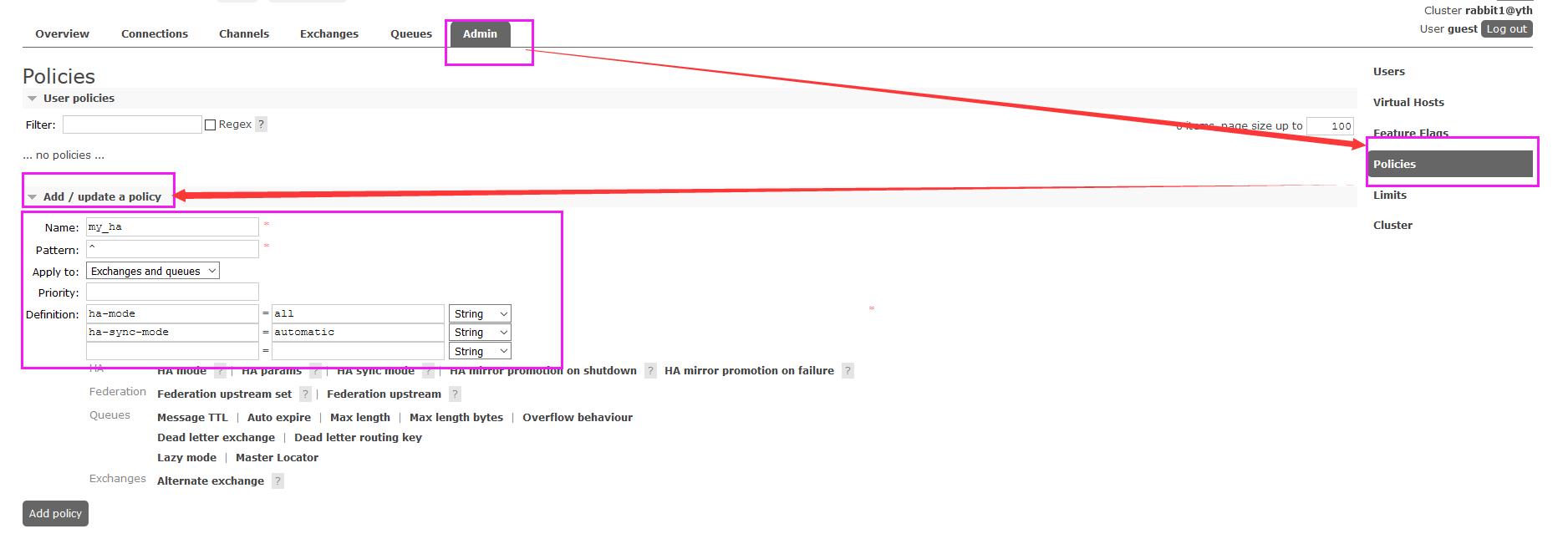
- 如下图:显示蓝色的+1,是正确的,如果是红色的,等待20秒左右,再看看是否变成蓝色,我在设置的时候也出现了这个问题,等待20秒后就变成蓝色的了。

- 再次关闭主节点,查看子节点是否还能获取主节点的信息。
经过测试发现,主节点已经关闭,子节点还可以继续获取信息。
3、负载均衡
此处就不再对负载均衡做简介了,类型和nginx一样。
链接:【csdn下载】
链接:百度云链接
提取码:h7ox
tar -zxvf haproxy-1.6.5.tar.gz -C /usr/local
cd /usr/local/haproxy-1.6.5
make TARGET=linux31 PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
mkdir /etc/haproxy
vim /etc/haproxy/haproxy.cfg
将下面代码块中的内容复制到文件里面
global
log 127.0.0.1 local0 info
maxconn 5120
chroot /usr/local/haproxy
uid 99
gid 99
daemon
quiet
nbproc 20
pidfile /var/run/haproxy.pid
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
contimeout 5s
clitimeout 60s
srvtimeout 15s
#front-end IP for consumers and producters
listen rabbitmq_cluster
# haproxy暴漏的端口号
bind 0.0.0.0:5672
mode tcp
#balance url_param userid
#balance url_param session_id check_post 64
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
balance roundrobin
# haproxy代理的rabbit服务
server node1 127.0.0.1:5673 check inter 5000 rise 2 fall 2
server node2 127.0.0.1:5674 check inter 5000 rise 2 fall 2
listen stats
# haproxy的图形化界面这里是你的LinuxIP地址
bind 192.168.31.33:8100
mode http
option httplog
stats enable
stats uri /rabbitmq-stats
stats refresh 5s
开启Haproxy:
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
//查看haproxy进程状态
ps -ef | grep haproxy
如果开启报错:请再次使用vim /etc/haproxy/haproxy.cfg文件,看看第一行是不是缺少字母了。
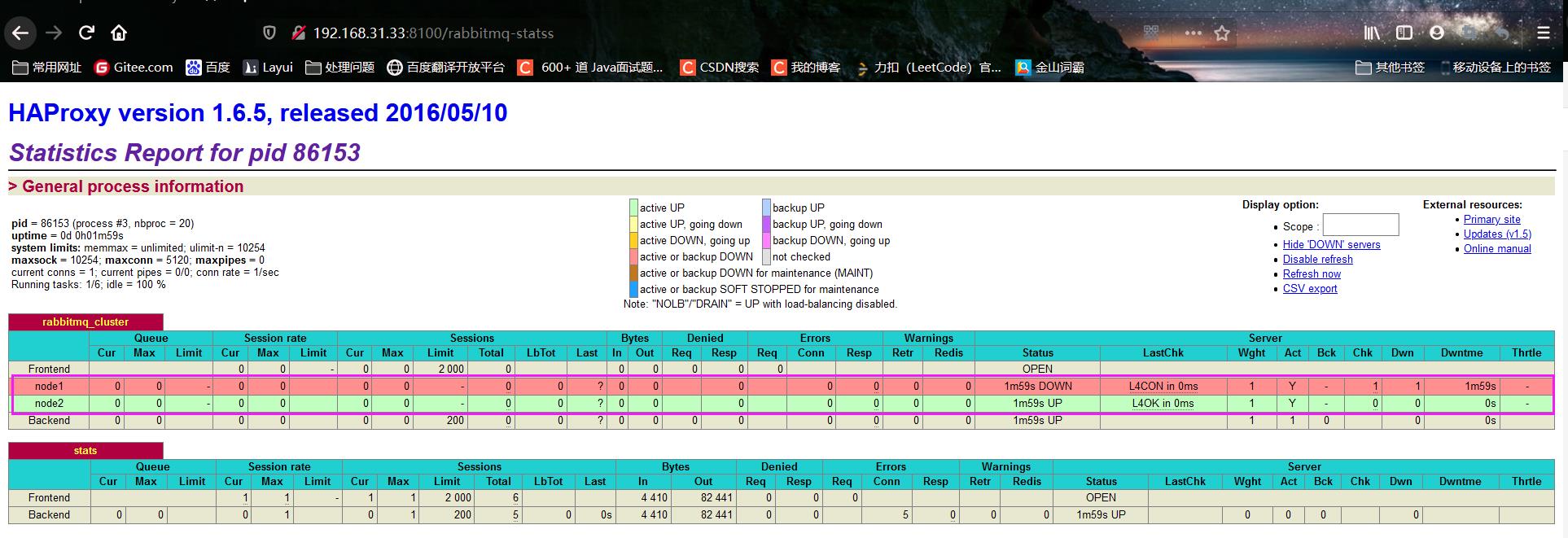
访问以下地址对mq节点进行监控:
http://192.168.213.181:8100/rabbitmq-statss
此时我的节点一是关闭,节点2是开启的,信息无误。
以上是关于RabbitMQ的幂等性和集群负载均衡的主要内容,如果未能解决你的问题,请参考以下文章